云环境中基于目标检测的密文图像检索方案
2020-06-09陈享,何亨,李鹏,金瑜,聂雷
陈 享,何 亨,李 鹏,金 瑜,聂 雷
1.武汉科技大学 计算机科学与技术学院,武汉430065
2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,武汉430065
1 引言
随着大数据[1]和云计算技术[2]时代的到来,企业和个人用户拥有大量的图像文件需要存储,由于将这些图像文件存储在自己本地会占用大量磁盘空间,云端存储[3]被越来越广泛地采用。然而,云服务器被认为是“诚实但好奇”的[4],即云服务器虽然能够正确执行客观的协议与功能,但是会主动探测存储在其上的敏感数据。因此为了保护企业和个人用户的隐私,对其存储在云端的图像文件先要进行加密处理[5]。由于加密后的图像文件不再具有明文可检索的特性,所以如何在加密的图像文件中检索出高相似度的图像内容,同时保证检索的效率和精确度成为一个亟待解决的难题。
由于相似度计算方法是信息检索中的关键技术之一,而图像自身不适合进行相似度计算,所以首先需要利用一个可计算的方式来表示图像,即提取图像特征的方法。传统方法有基于颜色直方图特征[6]提取、纹理特征[7]提取、形状特征[8]提取,虽然上述三种图像特征的提取方法有着简单易实现的优点,但是其局限性也非常明显,即都不能有效应用于所有类型图像的相似度匹配中,从而导致相似匹配的图像精确度比较低。目前较为流行的方法是基于SIFT算法来提取图像特征[9],其比较依赖于局部区域像素的梯度方向。当图像的像素梯度变化不明显时,有可能使得找到的像素梯度变化的主方向不准确,而特征向量的提取及匹配都依赖于主方向,即使不大角度偏差也会造成较大误差,从而匹配不准确。现在仍有许多学者对SIFT算法研究并加以改进[10],也有利用类似于SIFT算法的Fisher vector算法[11-12]提取图形特征,取得了不错的效果。此外,还有学者利用像素梯度的变化来提取图像特征[13]。近年来,随着深度学习的发展,出现了更精确、更可靠的方法来对图像进行特征提取和分类,例如使用卷积神经网络(CNN)[14]。在CNN的基础上,进一步发展有了R-CNN、Fast R-CNN[15]和Faster R-CNN[16]等一系列的目标检测模型,其中较为完善的是Faster R-CNN模型。但因为Faster R-CNN提取的图像特征feature maps 是一个64×36 的二维数组,每个图像拥有1 024 个feature maps,所以直接用1 024个feature maps 表示图像造成数据过多过大,计算消耗会较大,需要做进一步的数据压缩处理。
可搜索加密技术[17-18]是信息安全领域研究的热点之一。Song等人[4]提出了利用对称密钥来对关键词加密,把文件密文内容和加密关键词进行对比,以确认关键词是否存在并统计其出现次数,但并不提供文件的索引,在文件内容较多时,检索效率很低。Goh[19]提出了利用布隆过滤器为文件构建索引。然而,上述方法都不能抵抗离线关键词猜测攻击。Boneh等人[20]首次提出非对称关键词可搜索加密的方法,并通过构建安全信道来抵抗离线关键词猜测攻击。Beak 等人[18]提出无安全信道方案,让发送方、接收方和存储服务器同时拥有加密关键词的公钥,发送发和接收方还同时拥有存储服务器指定的解密私钥,由于私钥不被外部知道,所以能够抵抗离线关键词猜测攻击,但不能抵抗在线关键词猜测攻击,并且该方案忽略了云服务器不完全可信这一隐患。因此,密钥不能被外部和服务器知道,同时也要保证关键词不可被猜测出,基于这两种限制条件,本文采用多重线性映射[21-23]技术对关键词进行加密,既能保证关键词的私密性,也能防止关键词陷门创建过于简单[24]而导致安全信息泄露。对于密文图像检索,朱旭东等人[13]提出相关方案并给出了详细的安全性证明,检索精确度也较高,但是检索效率方面没有进行优化;Yuan 等人[12]的方案利用K-means聚类方法将图像集合分类,将图像索引构建为树的结构,提高了检索效率,但检索精确度不是很高。因此在保证检索安全的情况下,如何提高检索精确度和检索效率,也是密文图像检索领域的研究热点。
基于已有的相关研究成果,本文提出一种云环境中基于目标检测的密文图像检索方案(Encrypted Image Retrieval scheme based on Object detection in cloud computing,EIRO)。EIRO 先采用基于深度学习的目标检测模型Faster R-CNN 来精确提取图像的内容,包括图像的关键词集合和1 024个64×36的二维数组feature maps,将每个feature maps 求取平均值,一个平均值代表一个feature maps,这样1 024 个二维数组feature maps就转换为1 024维的特征向量,用其作为图像的特征向量。将具有相同关键词集合的图像和其特征向量加密后存放在同一文件夹中,再利用多重线性映射将关键词加密并构建文件夹的安全索引。用户检索时,先利用Faster R-CNN提取待检索图像的关键词集合和特性向量,根据关键词集合构建陷门,检索出相应的文件夹,实现图像集合粗分类的检索,再将其特征向量与该文件夹中所有图像的特征向量进行精确匹配,实现图像的细分类,最后将检索到的结果排序返回给用户。EIRO 不仅能够利用粗分类与细分类两步走的策略有效提高检索效率和精确度,同时具有很高的安全性,可以抵抗关键词猜测攻击,从而能够有效应用于云环境中。
2 问题描述
2.1 系统与安全模型
在云环境中基于目标检测的密文图像检索系统中,存在3种实体。云服务器(Cloud Server,CS),存储大量图像文件并提供大部分计算资源的环境;数据拥有者(Data Owner,DO),任何在云服务器中存储并分享图像文件的企业或者个人用户;数据使用者(Data User,DU),任何在云服务器中根据已有图像搜索相似图像文件的企业或者个人用户。

图1 系统结构图
图1 给出系统结构图。首先,DO 提取出图像的关键词集合和特征向量,将具有相同关键词集合的图像和其特征向量加密后放在同一文件夹中,其中特征向量加密后得到其索引,接着构建关键词集合的安全索引,最后将包含密文图像和特征向量索引的文件夹,以及关键词安全索引一起上传到CS。然后,当检索密文图像时,被授权的DU 生成待检索图像的关键词陷门和特征向量陷门并发送到CS,CS 进行查询后,将匹配到的密文图像排序返回给DU。
本文认为CS 具有“诚实但好奇”的属性,它能够完全按照DO 和DU 发送的请求正确地执行相应的操作,但它会窥视存储在其中的重要图像内容,同时也会窥探关键词集合信息并根据与陷门函数之间的关联来推断密文图像内容。
2.2 设计目标
为了确保CS 中用户图像数据的隐私性,同时保证图像检索的安全性、高效性和准确性,EIRO主要实现以下安全和性能目标:
密文图像检索:在存储大量密文图像的CS中,能够根据已有图像检索出包含有相似内容的密文图像。
隐私保护:图像、索引和陷门均采用密文形式,不会将有关明文信息泄露给CS和其他攻击者。
检索高效:先根据关键词集合对图像集合粗分类匹配,再根据特征向量对图像细分类匹配,通过两步匹配方式,同时大量的计算任务利用云服务器的强大计算能力处理,实现高效的检索。
检索精确:利用基于深度学习的目标检测模型Faster R-CNN 来精确提取图像的内容,包括图像的关键词集合和特征向量,实现两步匹配方式,得到尽可能精确的检索结果。
2.3 预备知识
2.3.1 Faster R-CNN模型
Faster R-CNN 是一种基于深度卷积神经网络的目标检测模型,可以精确检测出图像中含有哪些能被识别的内容,由CNN、RPN 和Fast R-CNN 三大模块组成。其中RPN主要用于预测输入图像中可能包含目标的候选区域,Fast R-CNN主要用于分类候选区域,这两个模块共用同一个CNN 来提取特征,提取的特征用feature maps 来表示。图2 给出Faster R-CNN 工作示意图,其中CNN 现在多数用的是ZF[25]、VGG[26]和Resnet50[27]模型,本文选用的是Resnet50。
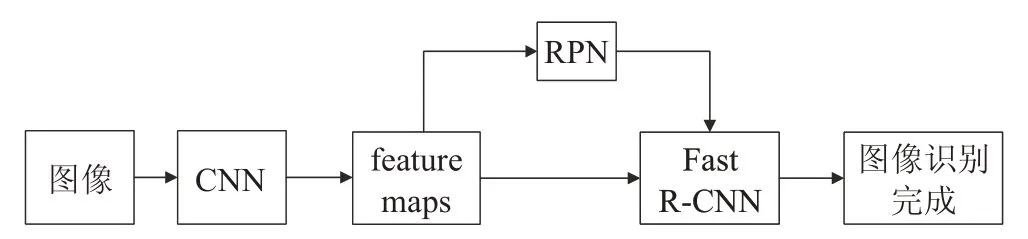
图2 Faster R-CNN工作示意图
2.3.2 双线性映射
这里简要介绍双线性映射,更多细节参考文献[28]。设G0和G1是两个以素数p 为阶的乘法循环群,g 为G0的生成元,则双线性映射e:G0×G0→G1具有下列性质:
(1)双线性:对于任意的u,v ∈G0以及随机选取的a,b ∈Zp,都有e(ua,vb)=e(u,v)ab。
(2)非退化性:e(g,g)≠1。
(3)可计算性:对于任意的u,v ∈G0都存在一种有效的算法计算e(u,v)。
2.3.3 多重线性映射
这里以三重线性映射为例简要介绍多重线性映射,更多细节参考文献[21-23]。设G0,G1,G2是三个以素数p 为阶的乘法循环群,则三重线性映射ei:G0×Gi→Gi+1,i=0,1 具有下列性质:
(1)若g0是G0的生成元,则gi+1=ei(g0,gi)是Gi+1的生成元。
(3)存在一种有效算法计算ei。
3 系统实现与设计
3.1 总体设计
EIRO的系统总体流程图如图3。
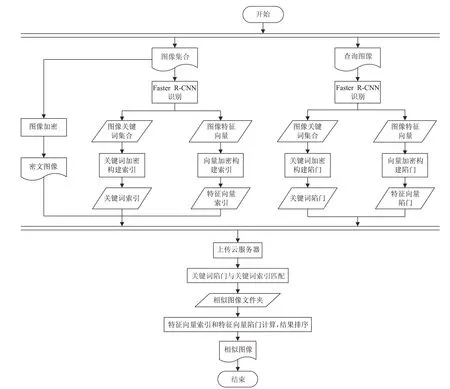
图3 系统总体流程图
首先,DO 把图像集合放入预先训练好的Faster R-CNN模型中进行识别,得到每张图像的内容,即每张图像所具有的关键词集合和1 024个64×36的二维数组feature maps,再把每个feature maps 求平均值得到1 024维特征向量。其中图像的关键词集合可能包含单个或者多个关键词,将具有相同关键词集合的图像分别加密后存放到同一个文件夹中,同时对每张图像的特征向量分别加密构建其特征向量索引,也存放到图像所在文件夹中;再使用三重线性映射分别对关键词集合进行加密构建其安全索引;最后将包含密文图像和特性向量索引的文件夹,以及关键词索引一并上传到CS。然后,当被授权的DU对密文图像进行检索时,将待检索的图像放入同样的Faster R-CNN 模型进行识别,得到图像的关键词集合和feature maps,再利用feature maps提取特征向量,分别对关键词集合和特征向量构建陷门并上传给CS;CS先根据关键词索引和关键词陷门进行粗分类匹配,即找到与待检索图像拥有相同关键词集合的文件夹,再将向量陷门和找到的文件夹中的向量索引进行精确匹配,实现图像的细分类,最后将得到的结果按相似度从高到低排序后返回给DU。
3.2 算法实现
EIRO 算法包括KeyGen、Index_keywords、Trapdoor_keywords、Index_vector、Trapdoor_vector、Test_keywords和Search共7种核心函数,下面具体阐述。
KeyGen(λ)→(PK,SK)。输入安全参数λ,生成具有同素数阶p 的乘法循环群
Index_keywords(PK,dk,w′)→Iw。随机选取t ∈Zp,将关键词集合w′中的每个关键词经过H 映射得到其对应整数,即Zwi=H(wi),并将Zwi累乘,将结果记作w。产生关键词安全索引Iw=<C1=gt,C2=e0(dk,g)tw>。
Trapdoor_keywords(PK,dk,w″)→Tw。随机选取s ∈Zp,将待检索关键词集合w″中的每个关键词经过H 映射得到其对应整数,同上述关键词索引的产生过程相同,将累乘结果也记作w。产生关键词陷门:
Tw=<A1=e0(dk-s⋅gs,g)w,A2=gs,A3=e0(g,g)sw>
Index_vector(PK,M,S,I)→Iv。将特征向量I 按如下规则分裂为两个向量I′,I″。遍历向量S={0,1}k的每一位,记作S[i],对于向量的每一位I[i],I′[i],I″[i]满足:
规则A:当S[i]=0时,I[i]=I′[i]=I″[i]。
规则B:当S[i]=1时,I′[i]=I[i]+r,I″[i]=I[i]-r。
再使用M 生成特征向量索引Iv=(I′MT,I″M-1)。
Trapdoor_vector(PK,M,S,Q)→Qv。同向量索引的生成过程,将待检索特征向量Q 按如下规则分裂成两个向量Q′,Q″:
规则C:当S[i]=0时,Q[i]=Q′[i]=Q″[i]。
规则D:当S[i]=1时,Q′[i]=Q[i]+r,Q″[i]=Q[i]-r。
再使用M 生成特征向量陷门Qv=(Q′MT,Q″M-1)。
Test_keywords(Iw,Tw)→0 or 1。根据规则e1(C1,A1)⋅e1(C2,A2)=e1(C1,A3)测试关键词索引Iw和关键词陷门Tw是否匹配,若公式成立,则索引与陷门中的关键词相同。下面给出当索引与陷门关键词相同时的公式验证。

Search(Iv,Qv)。根据欧拉公式计算特征向量索引Iv和特征向量陷门Qv之间的相似度为(I′MT-Q′MT)T⋅(I″M-1-Q″M-1)。下面给出公式计算过程。
根据规则A~规则D:
当S[i]=0 时:
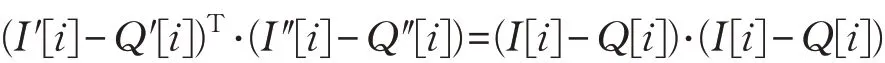
当S[i]=1 时:

即:

因此Iv和Qv之间的欧拉距离可以得出。
3.3 操作步骤
EIRO 的操作步骤分为预处理、图像分类和索引建立以及陷门创建和检索三个部分,下面具体阐述。
3.3.1 预处理
DO 首先训练出适合自己所需存储图像集的Faster R-CNN 模型,然后调用函数KeyGen(λ)生成系统公钥PK 和主密钥SK ,其中PK 公开,SK 由DO秘密保存。
3.3.2 图像分类和索引建立
DO 将自己需要存储的图像集合放入Faster RCNN模型识别,得到图像的内容,即图像的关键词集合和feature maps,利用feature maps 生成1 024 维的特征向量代表图像。例如一张图像中是“一个人在逗鸟”,那么得到关键词集合是“鸟,人”,将所有只包含“鸟,人”的图像存放在一个文件夹下,这时对“鸟,人”的关键词集合w′调用函数Index_keywords(dk,H,w′),就对该文件夹构建了安全索引。需要注意的是,如果图像中只含有“鸟”或者只含有“人”,则会属于不同的分类,并会存放在各自的文件夹下。图像本身就利用dk 对称加密。对于图像的特征向量I 则调用函数Index_vector(I,r,S,M)来加密及构建索引,并和各自图像一起存放在相应文件夹下。最后DO 将包含密文图像和特性向量索引的文件夹,以及关键词索引一并上传到CS。
3.3.3 陷门创建和检索
当DU 向DO 发出请求,要求检索DO 存储在CS 中的图像时,DO 验证DU 的身份,并为通过验证的DU 授予SK 。获得授权的DU,首先将待检索图像放入同一Faster R-CNN模型识别,得到图像的关键词集合w″和feature maps 并生成特征向量Q,然后对w″调用函数Trapdoor_keywords(PK,dk,w″)生成关键词陷门Tw,对Q 调用函数Trapdoor_vector(PK,M,S,Q) 生成查询向量陷门Qv,最后将两个陷门上传给CS。CS 接收到陷门后,首先对Iw和Tw调用函数Test_keywords(Iw,Tw),找到待检索图像所属类别的文件夹,然后对将该文件夹下每一张图像的特征向量索引Iv和Qv分别调用函数Search(Iv,Qv),将得到的结果进行排序,最后将对应的密文图像列表返回给DU。DU利用SK 中的dk 解密自己想要的前N 张图像即可。
4 安全性分析和性能评估
文献[12]先用Fisher 算法提取图像特征向量,再采用K-means 聚类的方法将相似的特征向量分到同一类并构建树状索引,检索时先根据检索特征向量和树状索引找到同一种特征向量所属类别,再将检索特征向量与存储的特征向量逐一匹配,利用L2 范式表示相似度大小。文献[13]利用灰度值变化梯度提取图像特征向量,并未采用分类的方法,直接遍历计算,利用余弦距离来表示特征向量之间的相似度大小。文献[12-13]与EIRO密切相关,都是实现云环境中的密文图像检索,因此将EIRO在密文图像检索时间和检索精确度方面与它们进行对比。此外,文献[18,20]利用双线性映射给出了密文关键词检索的两种方案,在EIRO 中亦存在密文关键词的检索部分,因此将这部分与文献[18,20]在安全性与计算开销方面进行比较。
4.1 安全性分析
下面基于选择密文攻击模型[29],从密文关键词的安全性和密文特征向量的安全性两方面来阐述本文方案的安全性。

表1 密文关键词检索的安全特性比较
假设有两种类型的攻击者企图恢复密钥,一类是恶意用户,另一类是具有好奇属性的CS。对于密文关键词,若恶意用户和CS想通过猜测攻击破解密文关键词,以定位到对应的存放密文图像的文件夹,根据Test_keywords 函数的验证过程可知,必须要拥有对称密钥dk 才可以,然而dk 是由DO 秘密保存的,恶意用户和CS 是无法获取的。在文献[24]中,构建了关键词陷门Tw=H(w)⋅dk 。在选择密文攻击的情况下,根据dk=,利用任意一个已知关键词的相关信息,dk 是可以被求解出来的,即攻击者可以破解出所有关键词以及图像的具体内容。因此,本文方案采用三重线性映射,生成两个映射关系
表1给出EIRO和文献[18,20]在密文关键词检索的安全特性方面的比较。由表1 可见,文献[20]的陷门产生方式能够抵抗离线关键词猜测攻击和在线关键词猜测攻击,但是需要建立安全信道。文献[18]虽然不需要建立安全信道,但需要指定服务器才仅能抵抗离线关键词猜测攻击,并且两者都忽略了服务器“诚实但好奇”的属性,恶意用户或“好奇”的服务器根据两者的陷门是可以分析得到相应的密钥与关键词信息的。EIRO在不需要指定服务器、不需要安全信道的同时能够抵抗离线关键词猜测攻击、在线关键词猜测攻击和服务器攻击,索引与陷门的安全性也很强,能够有效应用于云环境。
对于密文特征向量,本文方案基于随机选取的可逆矩阵M 和{0,1}向量S 来加密。在选择密文攻击的情况下,攻击者即使知道加密前的向量和加密后的向量,根据Index_vector 函数的实现过程,攻击者只有拥有M 或者S 的其中之一时才可以求出另一方,由于M 和S 由DO秘密保存,攻击者是无法得知M 和S 的,从而保证了特征向量的安全性。此外,根据密钥矩阵空间无穷大的特性,以及可逆矩阵的逆的唯一性,在每次初始化选择密钥矩阵时都是随机的,因此攻击者能够产生相同密钥矩阵的可能性为0。若攻击者通过暴力破解S进而来破解M ,此时效率为,k 为特征向量的维度,当k 为一个较大值(例如1 024)的时候,效率是极其低下的,这样就保证了向量加密的安全性。由于文献[12-13]的特征向量都是采用类似的分裂后与可逆矩阵相乘的方式来加密,所以三者在安全性方面相同。
4.2 性能评估
4.2.1 实验环境
关于Faster R-CNN 模型的训练,本文从VOC2007和VOC2012 数据集[16]中随机选取的九大类别物体图像,分别为人、鸟、自行车、飞机、狗、猫、摩托车、马、船,每类图像为200 到300 张,其中也含几类物体自由组合在一张的图像,共约3 500 张。用约300 张不同于训练集的图像进行识别,分类的精确度约为96.5%(注意是分类精确度,并不是指Faster R-CNN中的mAP[16])。观察发现,被错误识别的图像大多数是模糊的远景图像或者图像中只含有非常少部分需识别的物体。因此,若用较为清晰并且完整的图像,识别率会更高。在完成模型的训练和图像的识别后,根据图像的关键词将图像和其特征向量存放在对应文件中。实验中所采用的图像集共约4 500张。
本文实验是在64 位Windows10,Pentium®CPU4560 3.50 GHz的环境中运行。
4.2.2 密文关键词检索对比
EIRO 中密文关键词检索基于Java 语言实现,所用工具包为JPBC2.0密码库[30]。表2将EIRO和文献[18,20]在计算开销方面进行对比,包括关键词安全索引构建时间,关键词陷门产生时间以及关键词索引与陷门匹配时间,其中te0,te1,tG0,tG1,tH分别表示线性映射e0、线性映射e1、群G0的指数运算、群G1的指数运算、哈希运算的时间。表3给出计算开销的仿真结果。

表2 计算开销比较
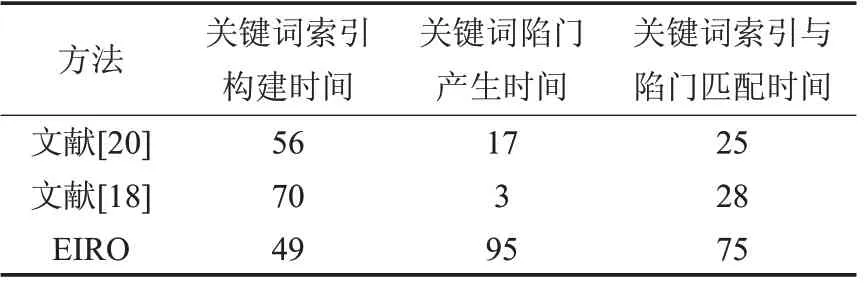
表3 计算开销的仿真结果ms
由表2 和表3 可以看出,相比文献[18,20],对于密文关键词检索,EIRO 的关键词安全索引构建时间是最短的,虽然关键词陷门产生和关键词索引与陷门匹配的开销相对较大,但是对于实际应用是完全可行的。与此同时,由表1 可见,EIRO 具有更好的安全特性。因此,EIRO 有效实现了云计算中密文关键词的检索,同时保持了很高的安全性,以及实际可行的效率。
4.2.3 密文图像检索对比
EIRO中图像特征向量的密文检索基于Matlab2016平台实现,表4给出密文图像检索时间。由表4的结果,对于1 024维的特征向量处理计算当中,EIRO单个特征向量索引与陷门的计算时间最短,这对于EIRO 在单个文件夹中特征向量索引的遍历计算节省很多的时间。因为文献[12-13]并未用关键词集合分类,所以它们没有在单个文件夹中的遍历计算时间。最后EIRO 对约4 500 张图像集的平均检索时间,包括关键词索引与陷门匹配时间和特征向量索引与陷门计算时间,约为2.1 s。若按照文献[13]所采用的完全遍历图像特征向量的检索方式,对同样数量图像集的平均检索时间则高达约63.9 s。文献[12]采用了K-means聚类的方案,其整个密文图像检索时间相对来说最短,约为1.9 s,但EIRO与之检索时间相差较小。

表4 密文图像检索时间
表5给出文献[12-13]和EIRO的图像检索精确度比较。表中显示出文献[13]与EIRO 的精确率较高,但EIRO 的精确率更为显著的突出,高达95.60%,同时可以看出文献[12]的精确率低至56.00%,只有将近一半的精确率。图4 给出一组EIRO 的检索结果。由此可见,EIRO 有效检索出了所有与原图具有较高相似度的图像。因此综合考虑整体检索时间和精确率这两方面,EIRO具有更好的效果。
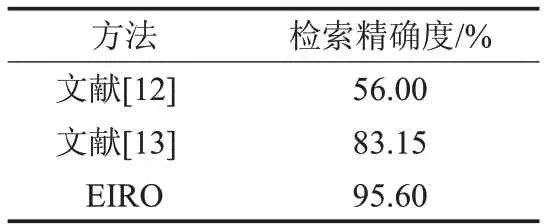
表5 图像检索精确度比较

图4 检索结果图
5 结束语
本文基于近年来广泛研究与应用的深度学习中目标检测方法,提出了一种云环境中的密文图像检索方案EIRO。利用Faster R-CNN模型精确提取图像的关键词集合和特征向量,采用多重线性映射方法对关键词构建安全索引,并实现图像集合粗分类和图像细分类相结合的两步检索策略。EIRO 具有很高的安全性、检索效率及精确度,能够有效应用于云环境中。
