异构系统中的Web服务器软件框架研究
2020-06-09尤国华
尤国华,刘 媛,高 东
北京化工大学 信息科学与技术学院,北京100029
1 引言
2018年3月统计显示,Facebook的用户已经超过了2.17亿,而且还在不断增加。为了满足庞大用户群的互联网需求,数据中心必须提供更强大的处理和存储能力。为提升数据中心的性能,传统的方法是增加数据中心的服务器节点,甚至建立更多的数据中心,因此也会带来更高的购置成本和使用成本(如耗电量和机房空间等)。为了满足需求并且降低成本,提升单台服务器的性能成为重要而迫切的任务[1]。
近年,随着CPU 主频遇到天花板,多核+协处理器的异构模型已经成为服务器端架构的主流。协处理器,如GPU、MIC等,可以极大提升服务器端的处理能力,弥补CPU 在某些计算方面的劣势。相比GPU,MIC 协处理器更适合于云计算这样的高吞吐量场景。GPU 基于单指令多数据(Single Instruction Multiple Data,SIMD),属于数据并行。针对云计算场景,如果想充分利用GPU的性能,batch size 就不能太小,但这会引起延迟的增加,从而降低服务质量(Quality of Service,QoS)。而且,对于一些复杂的分支逻辑,GPU会产生“分支退化”的问题[2]。MIC协处理器每个核心与CPU核心类似,适宜于逻辑运算和流水线并行;MIC协处理器的核心虽然主频低,但数量多,适用于云计算这样的计算场景[3]。图1为MIC协处理器Intel Xeon Phi 5110p的示意图,5110p具有57个物理核心(每个物理核心有4个硬件线程),每个核心的主频为1.05 GHz。
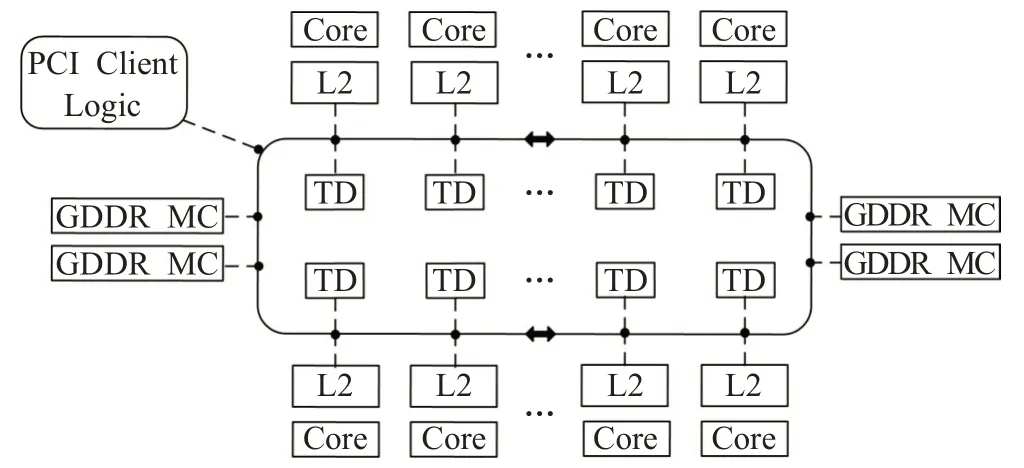
图1 Intel Xeon Phi 5110p结构示意图
虽然MIC 协处理器的加入从硬件方面提升了web服务器的性能,但一些常用web服务器软件,如Apache、nginx等,均不能充分发挥多核CPU+MIC协处理器的性能优势。因此,若要充分利用多核CPU+MIC协处理器的异构系统的性能,必须要研究与之匹配的web服务器软件体系[4]。
虽然以前的研究者对如何发挥GPU、MIC等协处理器的性能进行了不少的研究[5-9],如Agrawal 等[10]针对CPU+GPU 的异构系统提出了Rhythm 的web 软件框架。Rhythm 依据请求之间的相似性,将请求的处理过程划分成不同的阶段,并将部分处理阶段分配至GPU执行。根据他们的实验结果,Rhythm 可以有效地使用GPU处理用户请求。但Rhythm适用于处理逻辑比较简单的请求,对于复杂些的请求,由于GPU 的固有特性,可能导致“分支退化”。Fjälling 等[11]使用batching 技术充分利用GPU 的SIMD 特性来优化web 应用程序,与CPU相比可提升2到3倍的性能。但他们的工作主要集中在优化特定的web应用程序,缺乏通用性和扩展性。
为了充分利用多核CPU+MIC 协处理器的性能,本文提出了一种新的web 服务器软件框架。该框架通过将部分动态请求卸载至MIC协处理器执行,从而可以在CPU 和MIC 上并行处理动态请求,进而提升服务器的性能。此外,新框架也能保持多核CPU 和MIC 协处理器之间的负载均衡。
2 新的软件框架
为充分利用MIC协处理器的计算性能,新框架将一部分到达web服务器的动态请求卸载至MIC协处理器,由MIC 协处理器和多核CPU 并行处理动态请求,从而提升web服务器处理动态请求的效率。同时,新框架也可以在CPU 各核心之间,以及CPU 与MIC 处理器之间达到负载均衡。
2.1 软件框架描述
新的软件框架基于分阶段事件驱动模型(Staged Event Driven Architecture,SEDA),将web 服务器中请求的处理过程分为Receiver,Reader,Parser,Scheduler,Handler 和Writer 六个阶段,分别对应于建立连接,读动态请求,分析动态请求,动态请求的调度,动态请求的处理和写响应六个处理过程。每个阶段都由一个服务线程池,一个任务队列和任务处理逻辑构成。其中,Receiver,Reader,Parser,Scheduler 和Writer 五个阶段只部署在主机,而Handler 分别部署在主机和MIC 协处理器上。新服务器软件框架的处理过如图2所示。
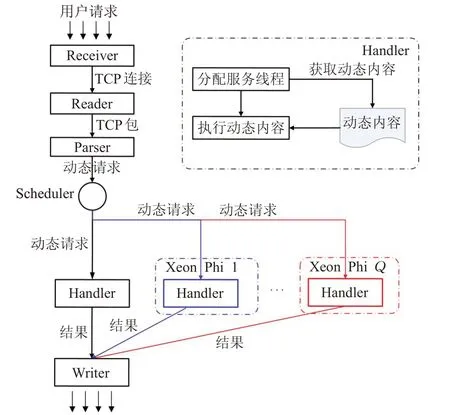
图2 新模型的处理流程
当用户请求到达服务器,Receiver 通过epoll[12]技术获取连接文件符lfd,对用户端建立连接,然后将lfd送至Reader的任务队列中,Reader从lfd中读取TCP包,然后将包中内容送至Parser 的任务队列中,Parser 解析TCP包,并从中抽取出请求。请求被送至Scheduler 的请求队列中,由Scheduler 调度请求至CPU 或MIC 协处理器。Scheduler 中内置有请求调度算法,由该算法保证CPU与MIC协处理器之间的负载均衡。
经过Scheduler 的调度,请求被分配至运行在CPU或MIC协处理器上的Handler的请求队列中,当Handler中有可用的服务线程时,一个服务线程会被分配给该请求。然后,服务线程解析该请求,并获取要请求的文件名和参数。根据文件名从Cache或内存中,甚至磁盘中载入该文件中的代码,然后根据从请求中解析出来的参数由服务线程在CPU 或MIC 协处理器上执行该代码。代码执行后的结果results 通过TCP 协议发送至Writer的结果队列中,然后由Writer以HTML的格式发送至网络,这就是响应。
2.2 请求调度算法
为了提升web服务器的性能,需要将部分请求分配至MIC协处理器上处理,这可能会导致CPU和MIC之间的负载不均衡,因此请求调度算法既要提高请求处理效率,又要保持CPU之间、CPU与MIC协处理器之间的负载均衡。本软件框架中,请求调度算法部署在Scheduler中,对请求进行分配和调度。
请求同一个页面的动态请求,其执行过程具有相似性[13],因此可归为同一类动态请求。如果服务器中N类动态请求,分别是R1,R2,…,RN。动态请求对处理器的负载冲击主要来自动态请求的数量和动态请求的服务时间,因此可用两者的乘积表示负载,即:

其中,CC(i)是第i 种动态请求的数量,TC(i)是第i 种动态请求的服务时间,而WC(i)表示第i 种动态请求对处理器的负载冲击。
若有P个处理器,而处理器j 上有N 类动态请求,每类动态请求的数量分别为CC(1,j),CC(2,j),…,CC(N,j),每类动态请求在处理器j 上的服务时间分别为TC(1,j),TC(2,j),…,TC(N,j),那么请求在处理器j 上产生的总负载可表示为:

动态请求的服务时间可以通过文献[14]的方法获取,动态请求某时间段的数量可以统计获得。因此,从时间t0到时间tcurrent这段时间内,如果各类动态请求到达的数量分别为CC(1,j),CC(2,j),…,CC(N,j),那么时间tcurrent时处理器j 的负载可表示为:
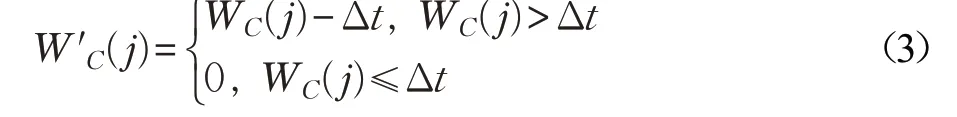
其中,Δt=tcurrent-t0。因为在Δt 时间内,随时间的推移,处理器会处理掉一部分动态请求,因此计算各处理器负载时要减去这段时间,但当Δt 大于各类动态请求产生的负载时长时,表明此段时间内处理器处于空闲状态,因此负载为0。
为充分利用多核处理器中缓存的局部性和NUMA架构的特性[15],同一类动态请求最好分配至同一个处理器上,而且需要同时维护各处理器之间的负载均衡。因此,可以根据各CPU处理器的负载状态W′j(1 ≤j ≤P)和各CPU 上动态请求的种类和数量分配新到的动态请求。若第i 种动态请求到达服务器,各CPU上负载的均值为,而第i 种动态请求在各处理器上的数量分别为CC(i,1),CC(i,2),…,CC(i,P),则可根据下式分配第i 种动态请求:

Lj(1 ≤j ≤P)中若Ll值最大,说明处理器l 上负载越小且第i 种动态请求的数量多,因此将第i 种动态请求分配至处理器l 上,可同时兼顾处理器间的负载均衡和缓存局部性。其中,α β 为公式的修正系数,可根据实际情况进行修正。
同时Scheduler可监测各处理器的负载状态,当CPU处理器平均负载超过λ(设定的阈值)时,新到的动态请求会被分配至MIC协处理器处理。
当动态请求i 到达服务器时,各CPU处理器平均负载E(W′C)>λ,此时需要将新到的动态请求i 分配至MIC协处理器处理。
假定有Q 个MIC 协处理器,当动态请求i 到达MIC k 协处理器时(此时刻记为t′current),从时间t′0到时间t′current,协处理器MIC k 上分配到的各类动态请求数为CM(1,k),CM(2,k),…,CM(N,k)。每类动态请求在MIC k 上的服务时间分别为TM(1,k),TM(2,k),…,TM(N,k)。那么,请求在协处理器MIC k 产生的总负载可由下列公式计算:
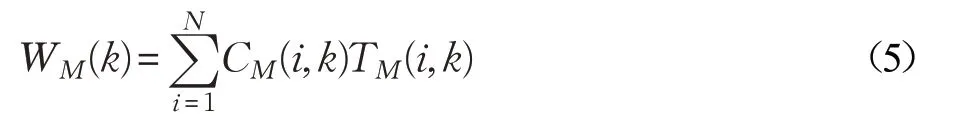
那么时间t′current时MIC k 上的负载可表示为:

其中,Δt′=t′current-t′0。因为在Δt′时间内,随时间的推移,协处理器会处理掉一部分动态请求,因此计算各处理器负载时要减去这段时间,但当Δt′大于各类动态请求产生的负载时长时,表明此段时间内处理器处于空闲状态,因此负载为0。
那么,各MIC上的负载的均值为E(W′M)=(W′M(1)+W′M(2)+…+W′M(Q))/Q,而第i 种动态请求在各处理器上的数量分别为CM(i,1),CM(i,2),…,CM(i,Q),出于负载均衡和缓存局部性的考虑,可由下式分配动态请求i 至那个MIC协处理器。
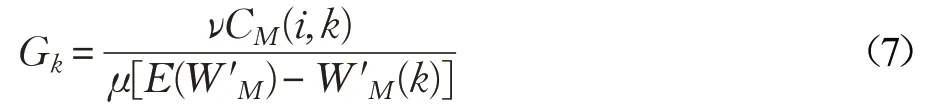
Gk(1 ≤k ≤P)中,若Gr值大,说明MIC r 上负载小且第i 种动态请求的数量多,因此将第i 种动态请求分配至协处理器MIC r 上,可同时兼顾协处理器的负载均衡和缓存局部性。其中,μ,ν 为公式的修正系数,可根据实际情况进行修正。
经过上述步骤,到达Web服务器的动态请求可以被分配至合适的CPU 或MIC 协处理器上,分配的过程同时兼顾了负载均衡和缓存局部性,可以最大化地利用异构系统的计算能力,从而提高了动态请求的处理能力。
调度算法的伪码描述如下:
//用于存储P 个CPU处理器上已分配的N 类请求的数量
array CC[N,P]
//用于存储P 个CPU处理器上N 类请求的服务时间
array TC[N,P]
//用于存储Q 个MIC处理器上N 类请求的服务时间
array TM[N,Q]
//用于存储Q个MIC处理器上已分配的N 类请求的数量
array CM[N,Q]
初始时间为t0
While(true)
{
第i 个请求到达scheduler,此时时间为tcurrent
//当前时间与初始时间的差值
Δt=tcurrent-t0
//用于记录每个CPU的上的历史总负载情况
array WC[P]
array W′C[P]
for(j=0; j <P; j+ +)
{
WC[j]=CC[i,j]TC[i,j]
If(WC[j]≥Δt)
W′C[j]=WC[j]-Δt
Else
W′C[j]=0
}//for
If(E(W′C)>λ)//CPU负载过大
{
//表示每个MIC的上的历史总负载情况
array WM[Q]
array W′M[Q]
for(j=0; j <Q; j++)
{
WM[j]=CM[i,j]TM[i,j]
If(WM[j]≥Δt)
W′M[j]=WM[j]-Δt
Else
W′M[j]=0
}//for
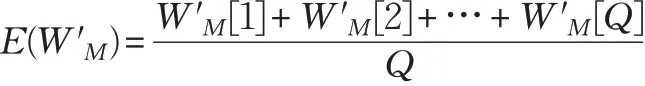
array G[Q]
for(k=0; k <Q; k++)
{
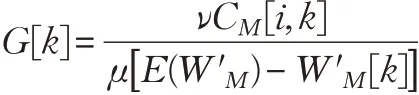
}
//求G[k]中的最大值Gmax(r)
Gmax(r)=Max{G[k]}
将该请求分配至第r 个MIC处理器
CM[i,r]++
}//If
Else
{
array L[P]
for(j=0; j <P; j++)
{

}
//求L[j]中的最大值Lmax(l)
Lmax(l)=Max{L[j]}
该该请求分配至第l 个CPU处理器
CC[i,l]++
}//Else
}//while
3 实验及评估分析
3.1 实验设置
本实验采用如图3 所示拓扑图,多台客户端PC 采用httperf 向服务器Server 发送动态请求。本实验采用一个6 核12 超线程的CPU 和一个MIC 卡作为实验平台,MIC协处理器为Intel Xeon Phi 5110p,具有512位SIMD 指令集,57 个物理核心,每个核心有4 个硬件线程。基于新软件框架开发的服务器程序NSFS(New Software Framework Server)部署在服务器Server 上,用于处理到达服务器的动态请求。作为对比,基于传统的先到先服务(FCFS)算法开发了web 服务器程序uFCFS,部署于两台6 核12 超线程的服务器节点上,其中一台兼作负载均衡器使用,采用轮询的方式向本身和另一台部署uFCFS 的服务器转发动态请求,由uFCFS处理动态请求,并返回响应。
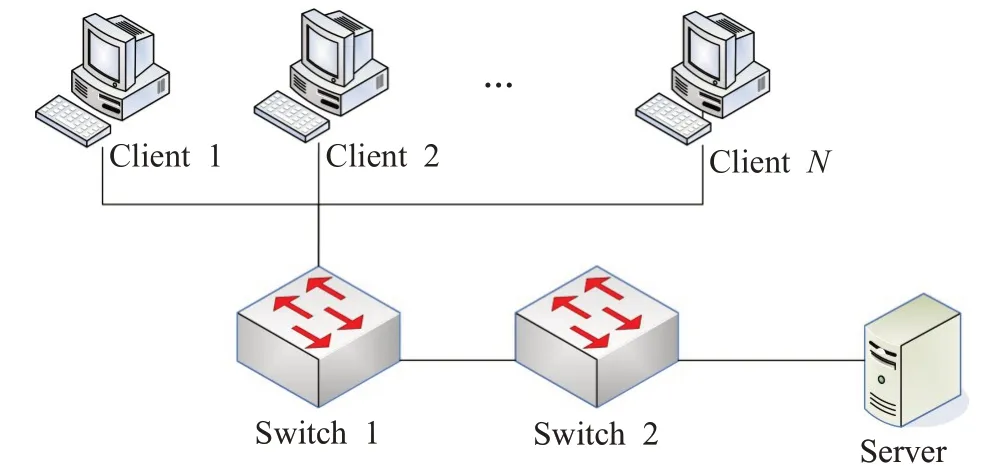
图3 实验拓扑图
本文基于上述两个仿真web 服务器程序NSFS 和uFCFS 进行实验,并主要从吞吐量、平均响应时间对两者进行评估。其中,httperf 的并发数、动态请求的服务时间是可以调整的,本文在调整这些参数的情况下进行了一系列实验,测量吞吐量、平均响应时间随并发数和动态请求服务时间变化的情况。
3.2 结果评估
(1)随并发数的变化
在保持其他实验参数保持不变的前提下,改变httperf 发送动态请求的并发数(从100 至10 000),对两个仿真web 服务器程序NSFS 和uFCFS 进行实验,并分别测量计算两个仿真web 服务器程序的吞吐量和平均响应时间。实验结果如图4所示。
由图4 可看出,当动态请求的并发数不断增加时,同时到达web服务器的请求数量增多,所以导致请求排队变长,从而导致uFCFS和NSFS的平均响应时间随并发数的增加而增加。但uFCFS 的平均响应时间在此过程中,增加的幅度要大于NSFS 的幅度,这说明使用NSFS框架的web服务器可以充分利用多核CPU和MIC协处理器的运算能力,其处理请求的能力要强于uFCFS,即基于CPU+MIC协处理器的异构web服务器的性能要强于由两个运算节点组成的web服务器。
uFCFS和NSFS的吞吐量可根据如下公式分析:

当并发数增加时,uFCFS 和NSFS 的平均响应时间均增加,因此根据公式(8)可知,两者的吞吐量变化均不会大。由于NSFS能充分利用MIC协处理器,因此运算能力更强,所以平均响应时间也更短一些,从而其吞吐量要高于uFCFS,分析结果与图4中的实验结果一致。
(2)随服务时间的变化
用户请求的服务时间变化比较大,呈现重尾分布的特点[16],为模拟真实场景,不失一般性,本文实验中的请求服务时间是可以调整的。当增大服务时间时,测量uFCFS 和NSFS 两种服务器的吞吐量和平均响应时间,图5为测得的结果。
根据图5,当服务时间增加时,uFCFS和NSFS 的吞吐量均下降,这是由于随着服务时间增加,两种web 服务器处理动态请求的时间都随之增长,因此导致两种服务器的吞吐量均下降。但是NSFS 的吞吐量一直大于uFCFS,这是因为NSFS 可以整合多核CPU 和MIC协处理器的运算能力,整体性能要优于由两台普通节点构成的uFCFS 服务器。随服务时间增加,uFCFS 和NSFS 的平均响应时间均增加,这是由于服务时间的增加会加重服务器的负载,从而导致排队时间的增加,进而延长了服务器的平均响应时间。而NSFS 的平均响应时间始终低于uFCFS,这也证实了NSFS 的性能要优于uFCFS。
4 结论
本文针对由多核CPU和MIC协处理组成的异构系统,提出了可充分发挥该系统运算性能的动态请求调度算法。该算法基于分阶段事件驱动模型,将动态请求的处理过程分为多个阶段,运算较密集的动态请求处理阶段由多核CPU 和MIC 协处理器并行承担,并通过负载均衡算法保持多核CPU和MIC协处理器之间的负载均衡。基于此模型,本文开发了对应的仿真程序,并进行了相关的仿真实验。实验表明,基于该算法的web服务器的吞吐量、平均响应时间均优于由两个节点构成的采用传统FCFS算法的仿真web服务器。
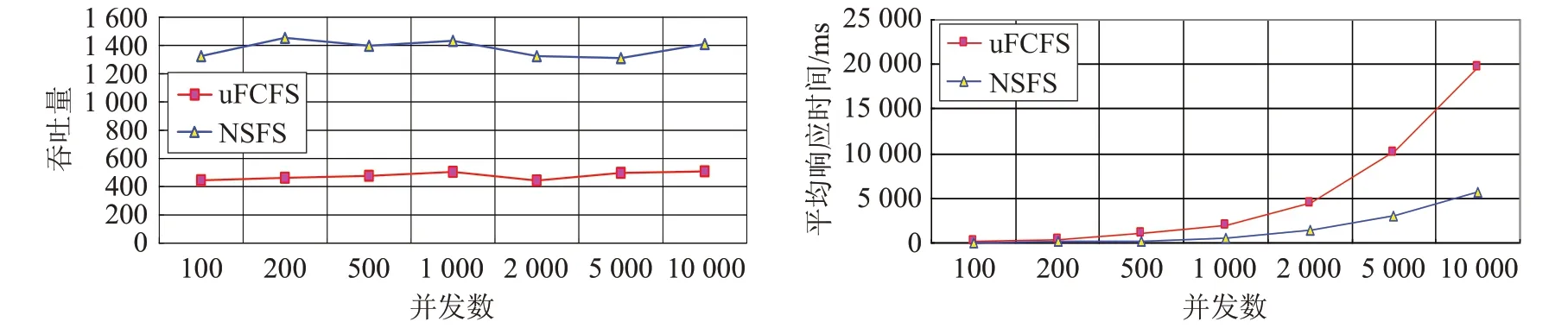
图4 两个仿真程序随并发数变化时的性能对比
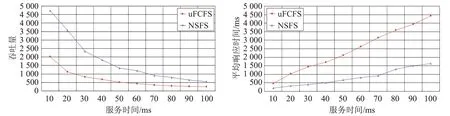
图5 两个仿真程序随服务时间变化时的性能对比
