一种基于图像簇多核学习模型的图像分类方法
2020-06-08嵇朋朋陈育中周刘喜
嵇朋朋,陈育中,周刘喜
(江苏联合职业技术学院南京分院 电气工程系,南京 210019)
在人工智能领域内,自然图像分类一直是研究人员关注的焦点,具有广泛的实际应用价值,如目标物体识别、目标物体跟踪、自然图像检索以及现阶段拍照识图或购物等[1-3]。经过多年的技术创新发展,研究人员提出了大量的图像分类方法,包括特征抽取[4-5]、学习模型优化以及多核学习(Multiple Kernel Learning,MKL)模型[6-9]。MKL模型是对不同数量或类型的核函数(如SPK、PDK等)或图像特征(如外形、纹理、色彩等)进行线性或非线性联合。MKL模型在支持向量机分类器中,利用多个图像特征、核函数优化学习新的分类器。传统的MKL模型[6-7]在特征空间中处理类间距离的合理性上存在弊端,导致无法给出实用的复杂自然图像处理效果。特殊样本MKL模型[9]对每个样本图像簇训练合适的核函数权重,并通过线性方式联合合适的核函数来提高模型的识别力,但存在学习模型耗时的缺点。针对上述问题,基于图像簇MKL模型的图像分类方法,研究将给定样本图像类别中具有相似形状、纹理或颜色特征的样本图像聚类到一个图像簇中,确保图像分类的准确性,并通过实验验证学习模型的判别能力。
1 问题描述
图像簇MKL模型先通过聚类算法对图像进行预处理,并将样本图像聚类成若干个图像簇,最后对多个不同类型核函数进行线性加权联合,其权重大小受核函数的类型、样本图像的属性影响。图1为图像簇MKL模型,将来自同一类别的图像,通过预处理(聚类算法)聚类到几个不同的图像簇中。

(1)


图1 题图像簇MKL模型
(2)
式中:αi=[α1,…,αN]Τ和b是MKL模型中的参数。模型决策函数式(2)可从图像簇MKL的原问题中提炼出来。
2 图像簇MKL模型
2.1 图像簇MKL模型原问题
从样本图像x中抽取M个特征向量(φ1(x),…,φM(x))的{φm(x)即从输入空间映射到特征空间,其中Dm表示第m个特征维度,每个特征相应的权重为wm。式(2)表示多个核函数的线性或非线性联合,经典的MKL模型决策函数可以写成式(3)。
(3)
为最大化正目标样本与负目标样本之间的边界距离,即最大化目标样本分类精度,同时使得目标样本分类误差最小化,可通过求解式(4)得到。
(4)
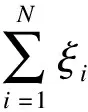
2.2 图像簇MKL模型对偶问题
(5)
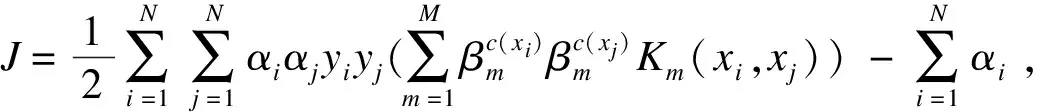
算法1图像簇MKL模型
(2)for 最终的要求没有满足,do;
(3)计算核函数的权值β;
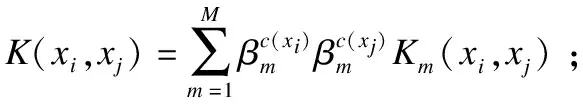
(5)用关于核K(xi,xj)的经典支持向量机(SVM)方法解决α;


(8)end for。
3 实验
3.1 实验设置
对数据库UIUC Sports、Scene15、Caltech-256图像进行预处理,把彩色图像转化为灰度图像。将数据库UIUC Sports、Scene15和Caltech-256中图像分别压缩到不大于400×400,300×300,300×300像素大小。
以文献[6]MKL模型作为参考基准,采用BOW特征表示最终的图像特征,对图像特征设置如下。
(1)局部特征抽取:使用图像局部形状特征描述子SIFT、HOG,图像全局特征描述子Gist,图像纹理描述子LBP,图像目标外观特征描述子SSIM、PHOG。
(2)特征字典训练:在数据库Scene15、UIUC Sports、Caltech-256中,图像局部形状特征描述子SIFT,特征字典长度分别为4096、1024、1024。HOG、LBP、SSIM特征字典长度均分别设置为1024、1024、400。
(3)特征聚合:均采用3层空间金字塔聚合,即每层分别为1×1、2×2、4×4个聚合空间;最终目标样本图像特征维度为特征字典长度×(1×1+2×2+4×4)=1024×21,即21504。
(4)核函数:使用PMK、SPK、PDK等作为基核。
(5)图像簇设置:在实验预处理中,每类图像被聚类为Ng图像簇(Ng=1,…,5)。
3.2 Scene15数据库
数据库Scene15具有15个不同自然场景的图像类别,共4485张图像,每个自然场景图像类内部之间区别很大,不同自然场景中也有相似之处。
图2为数据库Scene15中样本图像。

图2 Scene15数据库中样本图像
图2为街道、市区及郊区3个不同类别的自然场景样本图像,街道类别中不同街道之间存在差别(街道宽度,两边建筑物等等),但在街道、市区、郊区3个不同类别中都存在共同特征——建筑物。
表1为 Scene15数据库实验结果。

表1 Scene15数据库实验结果 %
由表1可知,图像簇MKL模型能够处理自然场景图像类内之间的差异性和图像类别之间的相似性,其分类精度为88.3%。与使用单一特征文献[10]相比,分类精度提高7.9%。相比文献[11]的分类结果高0.1%,说明图像簇MKL模型能够处理复杂自然图像分类问题,可以捕捉到图像中不同特征信息,并加以优化组合,形成更具判别力的图像特征。图3为图像簇MKL模型分类精度(训练数目为100,其值是各类图像分类精度的平均值)的混淆矩阵,其每一行代表图像簇MKL模型的测试值,每一列代表每一类所对应的真实值。从图3可知,有6类自然场景图像的分类精度高于90%,验证了图像簇MKL模型的性能。

图3 图像簇MKL模型分类精度混淆矩阵
3.3 UIUC Sports数据库
表2为图像簇MKL模型在UIUC Sports数据库上(8类目标物体,共计1579 张图像)的分类。

表2 UIUC Sports 数据库实验结果 %
由表2可知,图像簇MKL模型在UIUC Sports上的分类精度为88.96%,高出文献[10]的分类精度81.77%,比文献[10]的实验结果87.23%高出1.73%。再次验证图像簇MKL模型能够联合多种不同类型的特征描述子(比如颜色、纹理、兴趣点、外形、外观等),并最终得到具有较好判别能力的图像特征向量。图4为图像簇MKL模型在UIUC sports数据库上分类精度(训练数目为70,测试数目为60)的混淆矩阵。
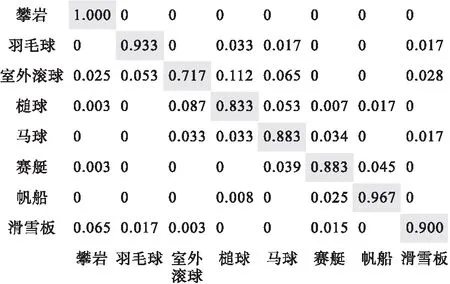
图4 UIUC sports数据库分类精度混合矩阵
图4中每一行代表图像簇MKL模型的测试值,每一列代表每一类所对应的真实值。从图4中可以看出,有4类目标图像分类精度高于90%,还有2类图像分类精度高于87%,进一步凸显了图像簇MKL模型处理目标图像的类内差异性及类间相似性问题的优势。
3.4 Caltech-256数据库
表3为图像簇MKL模型在Caltech-256数据库上(256类目标物体,共计29780张图像)实验结果。

表3 Caltech-256数据库实验结果 %
在表3中,训练数目为30和60时,图像簇MKL模型得到的分类精度分别为45.62%和48.92%,与文献[13]给出的分类精度40.80%和47.90%相比,分别高出4.82%和1.02%,表现出较好的自然图像分类性能。图像簇MKL模型能很好地将不同类型的局部特征联合起来(比如颜色、纹理、兴趣点、外形、外观等),且优化形成具有良好判别力的图像表示特征。显示图像簇MKL模型处理自然图像分类问题的优势。
4 结束语
传统地依靠单一局部特征很难概括自然图像中所有信息,针对其判别能力较低的问题,提出了基于图像簇MKL模型,引入预处理将每类图像聚类成若干个图像簇,通过联合多种不同类型的局部特征,最终形成具有较强判别能力的图像特征向量。实验证明,图像簇MKL模型具备处理自然图像分类问题的优势,即可很好地解决自然图像类内差异性及类间一致性问题。
