一种基于卷积神经网络的自动问答系统
2020-06-06敬思远
杨 骏,敬思远,项 炜
(1.乐山师范学院 计算机科学学院,四川 乐山 614000;2.互联网自然语言智能处理四川省高等学校重点实验室(乐山师范学院),四川 乐山 614000)
0 引言
随着互联网技术的发展,人们需要从网络上获取越来越多的信息。但是,要从浩瀚的数据海洋获取所需的准确信息,有相当大的难度。人们常常通过搜索引擎查找来获取信息,但这种方式存在三个问题[1]:相关结果太多,用户筛选困难;检索技巧要求较高,用户难以提供精准的检索依据;搜索引擎的语义理解能力不足,导致检索结果不够理想。自1965年R.F.Simmons[2]首次提出“自动问答”的概念以来,许多研究人员在这方面做了大量探索,如美国、法国、德国、新加坡等国的研究者在开放领域[3]和各个受限领域[4-6]都进行过不断尝试。因为基于搜索引擎的检索方式存在问题,学者们便开始了对基于知识工程的检索方式的研究。知识工程通常包括知识创建、知识识别、知识存储、知识共享、知识使用、知识学习和知识完善等环节[7]。随着机器学习和深度学习的兴起,卷积神经网络被广泛应用于各领域,如自然语言处理、图形图像处理、音频视频处理等,用于自动问答系统就是其在自然语言处理中的典型应用[8-9]。
本文结合搜索引擎和卷积神经网络等技术,架构一个可以实现交互式和异步请求的自动问答系统,可以应用于开放领域或受限领域,以提高用户信息检索的准确性和检索效率,改善用户体验。
1 相关技术
1.1 中文分词
词或词语,是某种语言中有意义的、能单独用来构造句子的最小单位。中文分词,就是将一个中文句子按照中文语法结构,分解为单个独立的词语的过程。1993—2003年间,中文分词的研究有了长足发展[10]。分词方法主要包括词典分词、理解分词、统计分词和组合分词等[11]。分词的结果并不是稳定不变的,而是会受到训练语料所属领域和未登录词语的影响,所以,跨领域的分词研究也有着重要的意义[12]。中文分词的效果一般采用召回率(Recall),即精确率(Precious)和调和均值(F1-Meature)等指标[10]进行评价。“结巴”(jieba)分词[13]是一个开源的中文分词组件,支持三种分词模式:精确模式、全模式和搜索引擎模式。对于未登录词语,采用了基于汉字成词能力的HMM(Hidden Markov Model,隐马尔科夫模型)和Viterbi算法进行分词。该组件还提供了多语言(Java、C++、Python、Rust、PHP、Go等)和跨平台(iOS、Android等)版本,可以方便地进行语言切换和平台切换。
1.2 AIML
AIML(Artificial Intelligence Markup Language,人工智能标记语言)是聊天机器人ALICE (Artificial Linguistic Internet Computer Entity)采用的知识描述语言,这款机器人最早是在1995年由美国Richard S.Wallace博士开发的[14]。AIML语言完全兼容XML语言,核心知识单元由一个或多个分类(category)组成,每一个分类代表了一个人机交互的会话,包含用户输入、机器回答和上下文环境三部份。不过,由于AIML语言设计之初就是基于西方语种的,因此处理中文时会存在一些问题,文献[14]提出了一种有效的解决办法。
1.3 卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)是一种特殊的前向神经网络,包含输入层、隐藏层和输出层[15-16]。
1.3.1 输入层
输入层通常是一个多维张量,0维张量即标量,一维张量是向量,二维张量是矩阵等。最常见的输入有一维的向量(如字符串或音频数据)和多维张量(如图像位图数据通常是二维矩阵或三维数组)。输入层代表了需要被处理的数据,一般会先进行归一化处理,有利于提高运算效率。
1.3.2 隐藏层
隐藏层是卷积神经网络的核心层,也称为处理层或运算层。隐藏层包括一个或多个卷积层和池化层的序列,以及一个全连接层。卷积层通过内部的卷积核,提取输入数据的特征值;卷积核的参数包括核大小、步长和数据填充,特征值提取后的数据尺寸大小由卷积核的步长决定。池化层将卷积层提取的特征值进行压缩(下采样),不仅可以降低数据的空间尺寸,减少模型参数,降低计算资源消耗,还可以避免过拟合;与卷积层相似,池化层的参数包括池化窗口大小、步长和数据填充。全连接层对池化层的结果进行非线性组合计算,与传统前馈神经网络中的隐藏层作用相同。
1.3.3 输出层
输出层通常使用逻辑函数或像softmax这样的归一化函数得到隐藏层的分类结果。
2 系统架构
文章采用相关技术,构建了一个自动问答系统,其系统架构如图1所示。

图1 问答系统架构
系统流程分为输入、处理和输出。输入表示用户输入的问题,处理部分通过对问题进行分词、AIML匹配、搜索引擎检索和答案评分等步骤获得最终答案,并在输出部分将其返回给用户。系统所用资源包括分词表、用于AIML匹配的固定答案,以及搜索引擎和公开的知识图谱等。
3 系统实现
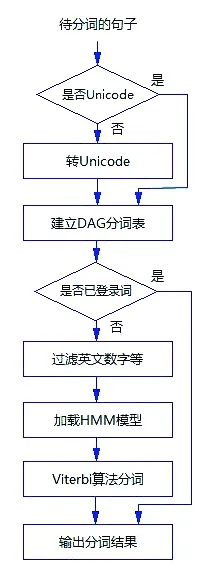
图2 文本分词流程
3.1 文本分词
采用jieba进行分词的工作流程如图2所示。首先加载已登录词典,生成Trie树(也称字典树或单词查找树)模型。待分词句子先经过Unicode处理,然后建立DAG(Directed Acyclic Graph,有向无环图)分词表,计算全局概率,得到基于Trie树的词频最大切分组合,找出句中的已登录词语。对未登录词语,采用基于汉字成词能力的 HMM模型和Viterbi算法,通过动态规划的方法获得分词和标注。
3.2 规则匹配
规则匹配采用AIML语言来实现常用的、不需要联网搜索的问答。主要是AIML语料的构建,每个语料中包括一个或多个AIML分类(category)。一个典型的AIML分类示例如下所示:
该分类表示了一个有上下文的人机对话:
人:乐山怎么样
机:你喜欢乐山美食吗
人:喜欢(不喜欢)
机:很好,我给你推荐几款最美味的(好吧,我猜你可能更喜欢乐山旅游)。
3.3 答案检索
问题无法匹配规则时,需要联网检索答案。除了基于文本的答案外,还有百度知道、百度百科等之类的基于知识图谱的结构化答案。结合这两种方式,可以提供更接近用户希望的答案,实现过程如图3所示。

图3 答案检索流程
3.4 答案评分
对答案集进行评分和筛选,是最重要和最关键的步骤。对答案检索阶段得到的答案集,分别计算每个答案与问题的相关性,选取最好的答案。文献[17-18]基于不同的应用,提出了不同的文本相似度和相关性的计算方法。本文采用A.Severyn[19]在2015年提出的一种基于卷积神经网络的方法计算相关性,对答案进行评分,处理过程如图4所示。

图4 句子相似度卷积计算过程示意[19]
算法描述如下:
算法输入:

算法输出:
最佳答案和评分值(r,p),其中r∈D,0.0p1。处理过程:
a)假设所有模型参数均训练完成(训练过程的处理方法大致相同,这里主要描述评分操作,略过训练过程),包括M,xfeat,分别表示训练得到的相似矩阵参数和全连接层的附加特征参数,其他的如卷积核参数和池化窗口参数等略。
b)初始化变量,最佳答案r←null,最佳答案评分值p←0.0。
c)提取问句q的特征,卷积和池化操作计算得到问句的核心特征为xq。
d)FOR EACHd∈D
卷积和池化层:采用和c)相同的方法计算xd
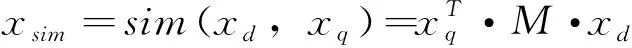
softmax层:px=softmax(xjoin)
IFp p←px r←d END IF NEXT FOR e)返回(r,p)。 图5 系统运行效果 实验硬件环境为Intel Core i7-3630QM处理器,8GB内存,软件环境是Ubuntu16.04操作系统,Python 2.7。经测试,如果用户提出的问题是基于AIML规则的,响应基本没有延时;实验了1 000次网络请求,无论是基于百度搜索引擎、百度百科、百度知道还是Bing搜索引擎,响应延时基本在1~3 s。这个响应有明显延迟,用户体验还不够理想,不过,在要求不严格的环境下,基本也可以应用。系统运行效果如图5所示。 随着互联网技术和人工智能技术的高速发展,计算机将为人们提供更多、更优质的服务,自动问答技术将在各个领域发挥明显的作用,尤其是在传统的人工客服领域。在旅游领域,自动问答系统可以为游客提供更及时、详尽、专业和贴心的服务,这样既能提升城市的服务水平,还能提升城市发展的科技含量。在以后的研究中,需要着重解决两个问题:进一步改善问与答的相似度计算,以求得到更精准的答案;设法解决响应延时的问题,争取提升到毫秒级别,进一步改善用户体验。
3.5 系统测评
4 小结
