数字信号相似度方法研究及GPU并行加速
2020-06-05朱静静谢晓尧刘志杰
朱静静,谢晓尧*,刘志杰,王 培
(1.贵州师范大学 信息与计算科学重点实验室,贵州 贵阳 550001;2.中国科学院国家天文台,北京 100101)
0 引言
近年来,随着社会经济和科技的迅猛发展,我们正处于大数据时代,而这些大数据都是具有时间属性的时间序列,相似性度量在其中得到了广泛的应用。时间序列是由多项与时间顺序有关的数据记录组成的元素的有序集合[1],它存在于金融收益、网络安全、气象研究、天文研究等[2],相似性度量是指将两个数据对象的相似度进行比较,是衡量数据对象间相似程度的指标,常常应用于数据分析和数据挖掘过程中,对于模式识别、信息检索、聚类、分类、序列模式、神经网络等研究中起着非常重要的作用,具有很高的研究价值[3]。对数据进行深入研究,从而更好地理解数据信息间的关系以及更方便有效地提取出潜在的隐藏价值。
计算相似度的方法较多,例如各种距离测度法、相对误差距离法、余弦相似度度量法、相关系数法、最大相异系数法、特征值相似比法[4-5]。经典的时间序列相似性度量方法总体分为两种:锁步度量(lock-step measures)和弹性度量(elastic measures)[6]。锁步度量是两个时间序列进行点对点或一对一的比较[7],最常见的是欧氏距离[8],Keogh等人和FALOUTSOSC等人分别提出利用欧氏距离[9][10]进行相似性度量的方法。弹性度量是两个时间序列进行一对多或一对零的比较,常见的有动态时间规整和基于编辑距离的度量[11]。
信号相似度评估结果可为噪声信号来源判定、仿真信号置信度评价等应用提供一种判断依据[12]。数字信号处理中,计算信号相似度的方法有很多,如按定义计算;通过快速傅里叶变换;互相关的库函数等。互相关是对两个序列相似性的一种度量,是一个信号相对于另一个信号位移的函数,称为滑动点积。互相关常用于在长信号中寻找较短信号的已知功能,这种相似性度量方式在模式识别、电子断层扫描、密码分析等领域中都有应用,互相关在含有周期成分的信号中提取特定频率成分信息;图像匹配;线性定位和相关测速以及计算信号时延等都有着至关重要的应用意义。
近年来,提高数据处理效率一直是计算机研究领域的热点,为了有效提高大规模计算的处理速度与性能,中央处理器(Central Processing Unit,CPU)+图形处理器(Graphics Processing Unit,GPU)的异构并行计算架构得到了进一步应用与发展。
本文以500 m口径球面射电望远镜 (Five-hundred-meter Aperture Spherical Telescope, FAST) 19波束接收机的数据进行实验,实现了CPU上的4种计算信号相似度的方法,并进行对比和分析,针对大规模数据采用互相关函数定义的方式计算相似度耗时较长,提出了2种利用CPU与GPU异构的并行架构方法提高大规模数据计算效率。FAST望远镜19波束接收机数据计算各波束间或者某些信号之间的相似性,可以检测、识别甚至提取一些特定成分的信息,同时,在信号线性定位以及计算信号时延等方面都有重要的研究价值。
1 相似度
时间序列是将研究数据的变化过程按时间先后顺序记录下来而形成的序列[13],时间序列相似性的定义由Agrawal等人在1993年提出[14],数字信号的相似性度量是计算时间序列间的相似性。
在信号处理中经常要研究两个信号的相似性,或一个信号经过一段延迟后自身的相似性,相关函数广泛应用于信号中隐含周期性的检测, 确定未知参数的线性系统的频域响应, 噪声中信号中的检测、提取等[15]。信号x(n)和y(n)的互相关函数的定义为:

(1)
该式表示Rxy(m)在时刻m时的值,等于将x(n)保持不动而y(n)左移m个抽样周期后两序列对应相乘再相加的结果[16],它是描述随机信号x(n)和y(n)在任意两个不同时刻t1,t2的取值之间的相似程度。
当y(n)=x(n)时,上面定义的互相关函数变成自相关函数,即:

(2)
Rxx(m)反映了信号x(n)和其自身经过一段延迟后的x(n+m)的相似程度[16]。自相关函数表达了同一过程不同时刻的相互依赖关系,而互相关函数表示不同过程的某一时刻的相互依赖关系。
信号x(n)和y(n)的线性卷积的定义为:

(3)
为了和(1)式的互相关函数比较,将(3)式中的m和n互换,则
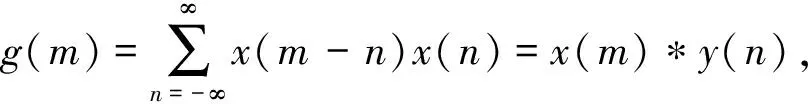
(4)
而信号x(n)和y(n)互相关函数:

(5)
故相关与卷积的时域关系为:Rxy(m)=x(-m)*y(n)。
(6)
相关函数和线性卷积在计算形式上非常相似,它们的区别在于计算x(n)和y(n)的互相关时,两个序列均不需要翻转,只是将y(n)在时间轴上移动后对应相乘再相加;而计算卷积时,需要先将一个序列翻转后再移动。二者所表示的物理意义是截然不同的,线性卷积表示LSI系统的输入、输出和单位抽样响应之间的一个基本关系,而相关反映的只是两个信号之间的相似程度,与系统无关[16]。
2 GPU、Pycuda和scikit-cuda
在高级游戏中,每个视频帧需要执行大量的浮点运算,为了满足这一需求且减小经济压力,图形处理器(Graphics Processing Unit,GPU)的设计理念油然而生[17]。GPU最初是一种图形加速器,随着科技的发展,GPU逐渐演化成一个强大的、多用途的、完全可编程的,以及任务和数据并行的处理器,广泛应用于大规模的并行计算;CPU适合处理控制密集型任务,GPU适合处理包含数据并行的计算密集型任务[18],将GPU与CPU结合有效地提高大规模并行计算问题的处理速度与性能。
CUDA(Compute Unified Device Architecture)是由NVIDIA在2007年推出的一种编程模型,旨在支持GPU/CPU应用程序的执行[17],它利用NVIDIA GPU中的并行计算引擎能更有效地解决复杂的并行计算问题。CUDA平台可以通过CUDA加速库、编译器指令、应用编程接口以及行业标准程序语言的扩展(包括C、C++、Fortran、Python)来使用[18]。
PyCUDA是通过Python访问NVIDIA的CUDA并行计算的API,PyCUDA可以充分利用CUDA驱动程序API的全部功能,具体是把CUDA C 程序嵌套在Python脚本中访问CUDA并行计算的API,通过提高代码抽象性来降低编程复杂性和改善编码效率。
PyCUDA对NumPy的数组提供了很好的支持,相对纯C/C++的CUDA程序而言,PyCUDA简化了初始化工作,可以直接将NumPy的数组作为参数传递给GPU核函数使用,并且直接用该数组存储GPU计算之后的结果[19]。
scikit-cuda为CUDA设备或运行时、CUBLAS、CUFFT和CUSOLVER库中的许多函数提供了Python接口,这些库是作为NVIDIA的CUDA编程工具包的一部分发布的。
3 计算信号相似性的方法
计算信号相似性的方法很多,本文主要讨论与分析了按互相关定义计算、傅里叶变换、Python中的Numpy和Scipy库以及CPU+GPU异构并行架构的两种方法计算信号相似度,得到一系列相关系数或相关函数值。Numpy是一种开源的数值计算扩展,可用来存储和处理大型矩阵。Scipy是基于Numpy的一个用于数学、科学、工程领域的常用软件包,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题。
3.1 互相关定义与快速傅里叶变换计算相似度
1)互相关函数定义方法
2)快速傅里叶变换方法
快速傅里叶变换(Fast Fourier Transformation , FFT)和逆变换(Inverse Fast Fourier Transformation,IFFT)计算互相关函数。对于N点有限长信号,通过FFT将信号的时域信息转换为频域信息,把X(n)信号频域的共轭乘以Y(n)信号的频域得到两个信号的互相关函数的频域信息,然后把频域恢复到时域,此时得到的数据信息范围是[0 ~N-1, -(N-1) ~ 0],而直接时域计算得到的数据范围是[-(N-1) ~N-1],所以需要利用fftshift函数对fft处理后得到的结果的顺序进行调整。
3.2 Python中的Numpy与Scipy库计算相似度
Python中的numpy.correlate()和scipy.signal.correlate()两个函数计算互相关,一维的数据可以直接计算二者的相似度,但是实际处理的数据往往都是多维数据,需要对这些数据降维,对于二维数据,为了计算出完整的相关系数序列,需要用到一些“不存在”的点,这就需要对这些数据进行补零操作,即对超出原始数据存储区的部分取值为零。前端和末端的数据并没有完全“嵌入”到原始数据的全部信息,会受到补零操作的影响,这些数据往往是不可用的。
3.3 CPU+GPU异构并行计算相似度
按定义计算信号相关的方法计算复杂度约O(N2),当数据量大时,耗时较多,由于没有进行补零等操作,定义法计算的结果精度较高,采用CPU+GPU的异构并行计算方式提高数据处理效率。
1)利用PyCUDA计算
Python是一种广泛使用的解释型、高级编程、通用型的编程脚本语言,PyCUDA是把CUDA C 程序嵌套在Python程序中,利用GPU+CPU即把串行处理数据放在CPU上运行,把可以并行处理的数据放在GPU上运行,提高按定义计算信号相似度的处理效率。共享内存(Shared memory)是片上内存,带宽仅次于寄存器的存储器,速度快于一般的全局内存(Global memory)和常量内存(Constant memory)等显存,实验中使用共享内存减少线程块中的线程必须访问的数据总量,根据数据规模设置相应的最优的网格和块大小计算相似度,进一步提高数据处理速度。
2)利用scikit-cuda
scikit-cuda为CUDA设备或运行时、CUBLAS、CUFFT和CUSOLVER库中的许多函数提供了Python接口,这些库是作为NVIDIA的CUDA编程工具包的一部分发布的,还提供了在CULA密集型工具包中选择函数的接口,提供了与C类似的低级包装函数和与NumPy和Scipy类似的高级函数。实验中主要用到了skcuda.linala.dot()函数可以自适应的计算两个信号的外积,然后进一步计算相关系数。
4 实验与结果分析
4.1 实验
本文实验平台为GeForce GTX 1080 Ti GPU,Intel(R) Core (TM) i7-6700 CPU@ 3.40 GHz,16 GB 内存和Red Hat Enterprise Linux Server 7.1操作系统。使用 Python和 PyCUDA(Python+ CUDA C)编写程序,集成开发环境为PyCharm,同时环境支持为CUDA Toolkit 9.2。
以FAST望远镜19波束接收机的FITS格式数据进行实验,每个文件是单个波束在一次观测中所记录的数据,由于每个波束的FITS文件约2 G,19波束约38 G数据,且原始数据“SUBINT”数据中的DATA部分数据是五维数组,由于计算速度和计算机内存的需求和限制,需要对数据进行降维、两路偏振合并成一路偏振以及采样等预处理操作,得到一个第一维表示时间,第二维表示频率通道的19波束的二维数组数据。实验中使用的是二维数组的某一频率通道的19波束的部分时间序列数据,分别为5 120×1、10 240×1、15 360×1、20 480×1、25 600×1、30 720×1六个计算规模大小,并对按定义计算信号相似度的方法进行加速。
4.2 结果分析
CPU上的4种方法包括FFT、Python中的2个库函数以及互相关定义法,通过实验发现Python中的2个库函数Numpy.correlate()和Scipy.signal.correlate()两种方法计算的结果基本一样,如图1所示,上面两部分是FAST望远镜19波束某频率通道的部分时间序列经过预处理后的二维数字信号数据,第三部分是这两个数字信号的相似度的可视化表示,可以发现这两个时间序列(数字信号)相似度很低,且两种方法计算的结果基本相同。
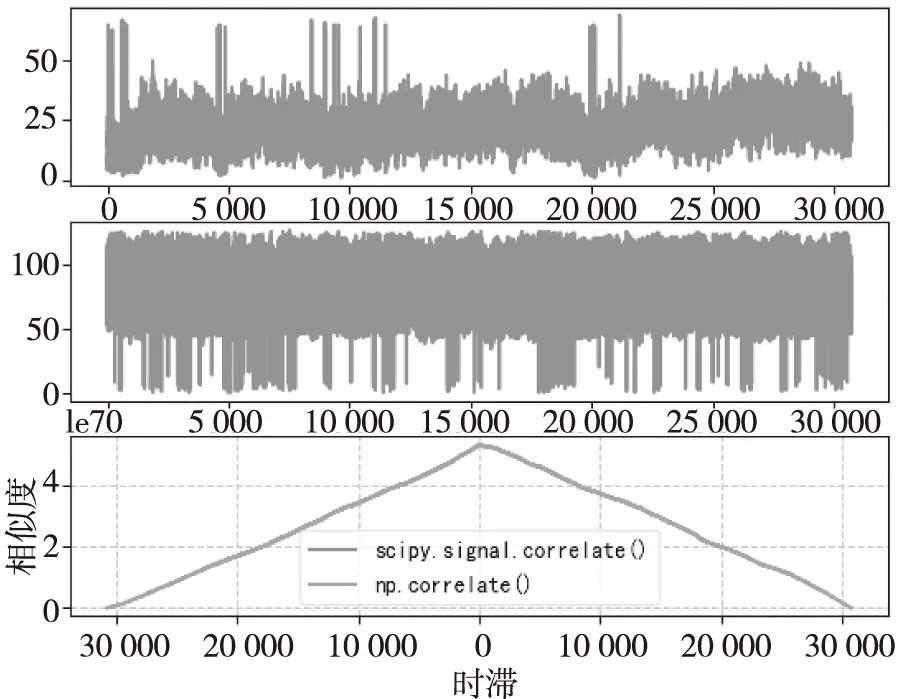
图1 Numpy和Scipy库评估相似度结果Fig.1 The evaluate similarity results of Numpy and Scipy libraries
通过FFT方法和Python中的2个库函数方法计算FAST望远镜19波束接收机的一个时间段的某频率通道的两个信号的相似度,经过预处理后的数据是二维数组,为了得到完整的计算结果,对于N个数据点,在计算过程中都需要对其补充N-1个零。对于FFT的方法是先分别对两个信号进行傅里叶变换,然后第一个信号傅里叶变换的复共轭乘以第二个信号的傅里叶变换值,最后再用fftshift函数调整数据的顺序。
CPU上的4种方法计算两个信号的相似度的结果基本一致,如图2所示,按照定义的方式计算的结果只有时滞大于零的部分,而其他3种方法计算的相似度结果是有时滞大于零和小于零两部分,因为计算过程中只有按照定义的方式没有对数据进行补零操作,而其他3种方法都进行了补零操作,这些补零操作从某种程度上影响了相似度的精确度。
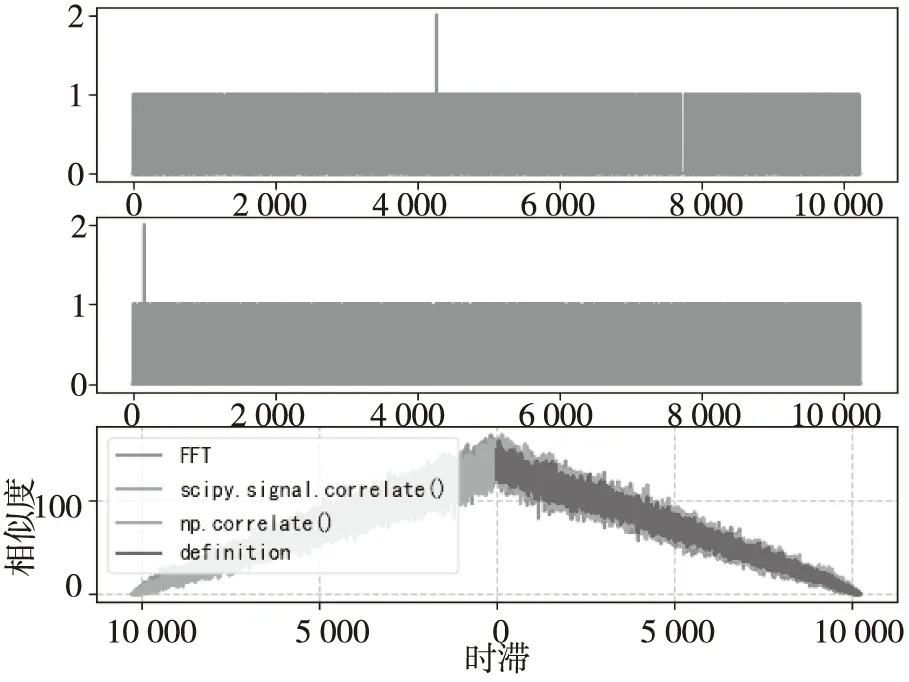
图2 CPU上的4种方法评估相似度结果Fig.2 The evaluate similarity results of four ways on the CPU
在CPU上的4种方法对于不同数据规模所需时间的差异,经过多次实验,选取了一些相对理想的数据,不同方法所需时间如图3所示,很明显的看出计算速度最快的是Scipy.signal.correlate()方法,按照定义方法计算相对耗时,Numpy.correlate()和FFT方法计算效率介于二者之间。虽然按照定义方法计算相似度耗时,但是由于没有进行补零等操作,计算的精确度相对较高。
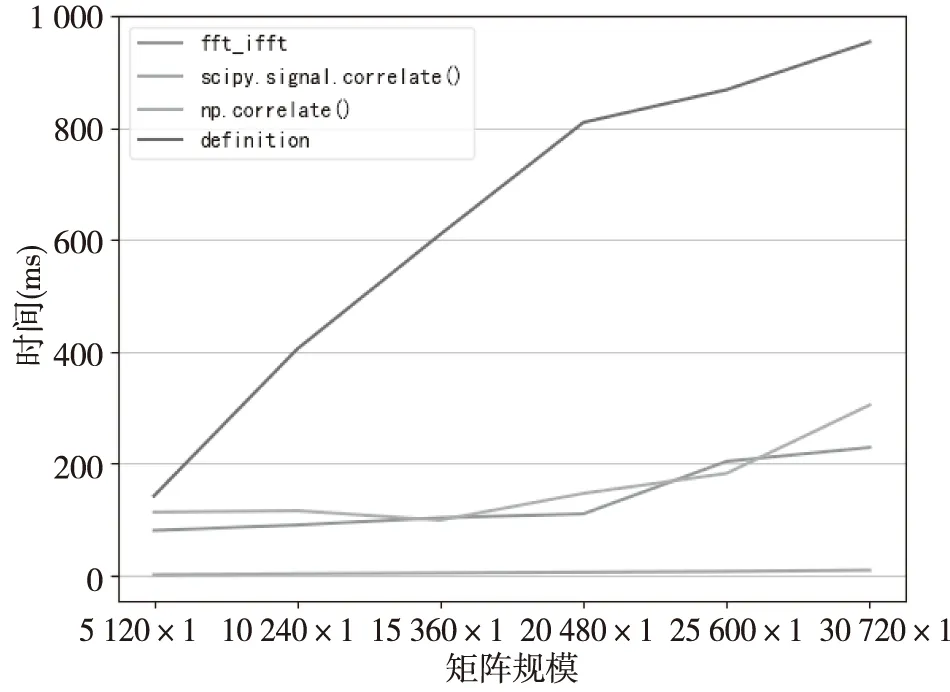
图3 CPU上4种方法计算不同矩阵规模的时间Fig.3 The time of calculate different matrix scales of four methods on the CPU
由于按照相关函数定义的方法计算信号相似度相对耗时,所以采用CPU+GPU异构并行的2种方式提高计算效率,计算结果如图4所示,这两种方法是对按定义计算信号相似度方法的改进,计算的结果只有时滞大于零的数据,且这两个时间序列相似度较高。PyCUDA方法需要根据数据规模调整网格和数据块的大小,不能自适应的计算,而scikit-cuda库中的culinalg.dot()函数自适应计算,降低编程复杂度,数据处理效率更高。
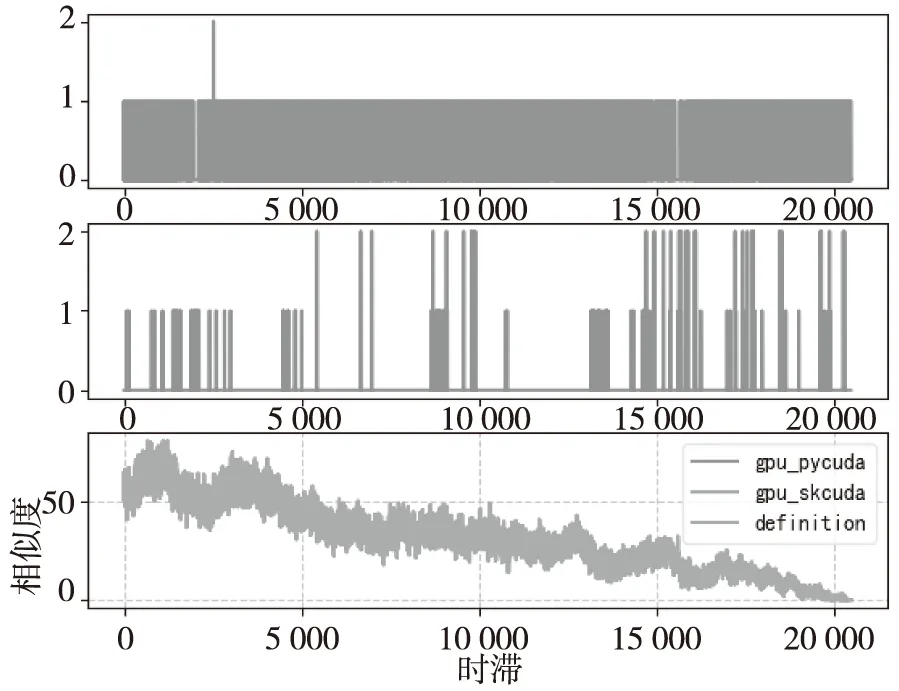
图4 PyCUDA和scikit-cuda库评估相似度结果Fig.4 The evaluated similarity results of PyCUDA and scikit-cuda libraries
多次实验显示,利用PyCUDA计算矩阵的外积。对于10 240×1规模,最高提速11.8倍,对于20 480×1规模矩阵,最高提速12倍,对于30 720×1规模矩阵,比只用CPU计算耗时,后面计算具体相关函数值通过PCI-E总线传输数据到CPU上进行计算,数据规模不断增大,显存和内存间大量的数据通信耗时较多,带来了较大的时间损耗,这在一定程度上削弱了GPU 快速进行高性能并行计算的能力,整体提速不明显,需要进一步研究。scikit-cuda库函数方式计算信号相似度提速效果较好,如图6所示,30 720×1信号矩阵最高提速7.3倍,并行处理的性能提升并不是线性增长,随着数据规模的增加,受到PCI-E总线带宽的影响和GPU核心数目的限制,加速比会逐渐趋于平缓,实验中只使用了FAST望远镜19波束某一频率通道的部分时间序列数据,数据量逐渐增大时加速比会趋于平缓。
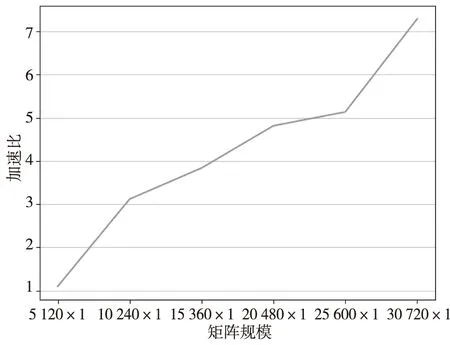
图5 CPU+GPU的scikit-cuda库与CPU定义方法加速比Fig.5 The acceleration ratio of CPU+GPU scikit-cuda library and CPU definition method
CPU与GPU的计算信号相似度方法结果对比如图6所示,可以看出多种方法计算两个数字信号相似度的结果基本一致,按照定义的方式计算的结果较精确,通过CPU+GPU的异构并行的方式显著提高数据的处理效率。
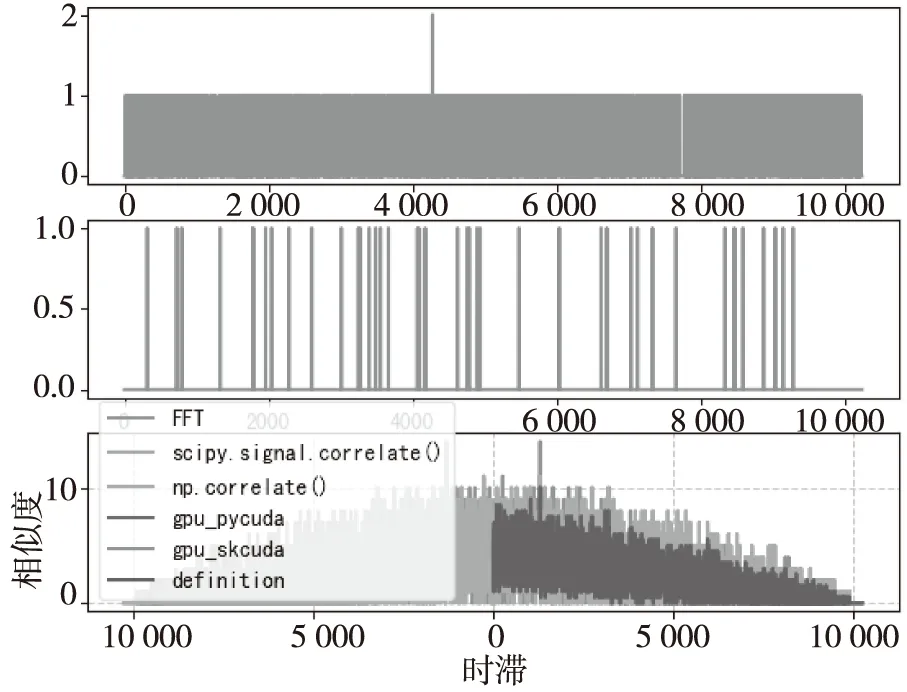
图6 CPU与GPU的计算相似度方法结果对比Fig.6 The comparison of results of the CPU and GPU calculate the similarity methods
5 总结
本文讨论并分析了CPU上的4种计算信号相似度的方法以及结合GPU的异构并行方式计算信号相似度。实验结果表明:CPU的4种方法中Scipy.signal.correlate()方法计算效率最高,按定义计算的精度较高,当数据规模大时,按定义法计算相对耗时,所以采用CPU+GPU的异构并行的2种方式提高数据的处理效率。实验表明:基于定义的方式计算信号相似度,通过PyCUDA实现,整体提速效果不明显,需要进一步深入研究,Scikit-cuda库的使用显著提高了定义方式计算相似度的数据处理效率,在数据处理中具有良好的应用前景。
计算FAST望远镜19波束中各波束间数据的相似性,或者某些信号之间的相似性,可以检测、识别甚至提取一些特定成分的信息,特殊信号线性定位以及计算信号时延等方面值得进一步深入研究。
