基于遮挡标记的目标检测算法
2020-06-04帖军宋威尹帆郑禄杨欣
帖军,宋威,尹帆,郑禄,杨欣
(中南民族大学 计算机科学学院,湖北省制造企业智能管理工程技术研究中心,武汉430074)
目标检测是计算机视觉领域的基本问题,近几年来也在智能监控[1]、智能分类[2,3]及产品检测[4]等应用领域取得了很大的发展.然而自然条件下的目标检测任务仍然存在许多挑战,其中遮挡因素极大影响了检测效果.因为遮挡会造成图像中检测目标的局部特征损失,影响目标特征的完整性[5-7],从而在检测过程中,影响实际的检测精度.
为了实现效率高且精度高的目标检测,深度学习模型已经广泛运用于目标检测领域.文献[8]提出的YOLO V1目标检测模型,采用卷积神经网络(Convolutional Neural Networks, CNN)提取图像各个部分的特征,直接回归目标信息,实现目标检测.文献[9]提出的YOLO9000模型,引入Faster R-CNN[10]中的Anchor Box到YOLO V1中,并结合全卷积网络,使模型在识别精度和速度等方面均有提升.文献[11]提出的Focal Loss对正负样本分别加权,解决了目标检测中正负样本比例失衡的问题,进一步提高了检测精度.文献[12]和[13]提出的YOLO V3模型采用多尺度预测的方式,并结合Resnet[14]单元,改善了图像中大小目标的检测精度差.但在实际检测中,普遍存在的遮挡情况仍会影响检测精度.熊俊涛等人[15]提出采用Faster R-CNN网络分别构建甜椒和柑橘检测系统,但其目标检测框过大,易导致检测的精度不够.彭红星等人[16]以苹果、荔枝、脐橙、皇帝柑4种水果为研究对象,提出了一种改进的水果检测模型,将SSD[17]模型中的VGG16主干模型替换为ResNet-101模型,并运用迁移学习方法和随机梯度下降算法优化训练模型,一定程度上提高了自然环境下多类水果的检测精度.BARGOTI等人[18]为了使检测模型在不同果园之间均能取得高检测精度,使用多个果园数据集,通过迁移学习来训练模型.
以上研究大多基于深度学习的网络模型更注重于目标物体的检测,却缺乏对具体遮挡信息的描述和分析,不能对遮挡目标信息进行更加详细的解析,因而在遮挡目标普遍存在的场景下检测精度不高.
本文基于YOLO V3目标检测模型,提出遮挡标记方法与损失补偿机制,通过在图像数据集添加遮挡标记,并在模型训练过程中将损失函数与遮挡标记信息结合,以增强模型对遮挡目标的敏感性,提高模型对遮挡目标的检测精度.
1 目标检测
本文基于目标的卷积特征,在YOLO V3模型框架下对图像进行检测,算法总体架构如图1所示.
采用图像增强技术对原始图像进行预处理(图1(a)),使用卷积神经网络提取图像中的目标特征(图1(b)),通过YOLO模型获得不同尺度下图中目标位置(图1(c)),最后综合多尺度下的目标框信息获取检测结果(图1(d)).

图1 检测原理图
1.1 图像预处理
自然环境中,阳光、阴影的变化可能会使不同图像中的相同物体产生巨大的特征差异,影响模型对目标特征的提取.对比度是描述图像的重要特征,为了避免低频背景的干扰,本文选用自适应对比度增强[19]算法(Adaptive Contrast Enhancement,ACE).
一张图可以分为低频和高频两个部分,低频部分通过图像的平滑模糊而得,高频部分由原图减去低频部分而得.ACE算法的目标是通过增强代表细节的高频部分,即将图像高频部分乘以某个增益值,重组得到增强后的图像来实现对比度增强,公式如下:
f(i,j)=mx(i,j)+C[x(i,j)-mx(i,j)],
其中x(i,j)和mx(i,j)分别表示图像在(i,j)处的像素值和以(i,j)为中心的固定大小正方形区域内的像素均值,C为大于1的常量,表示增益的系数.图2展示了部分经过预处理后的图像.

(a)原始图像 (b)处理后的图像
1.2 检测模型
目标检测框架如图3所示,预处理后的图像作为卷积神经网络的输入,网络提取图像的目标特征信息;特征图输入到检测网络中,提取目标框信息并判断目标的类别,通过过滤,得到最终目标框.
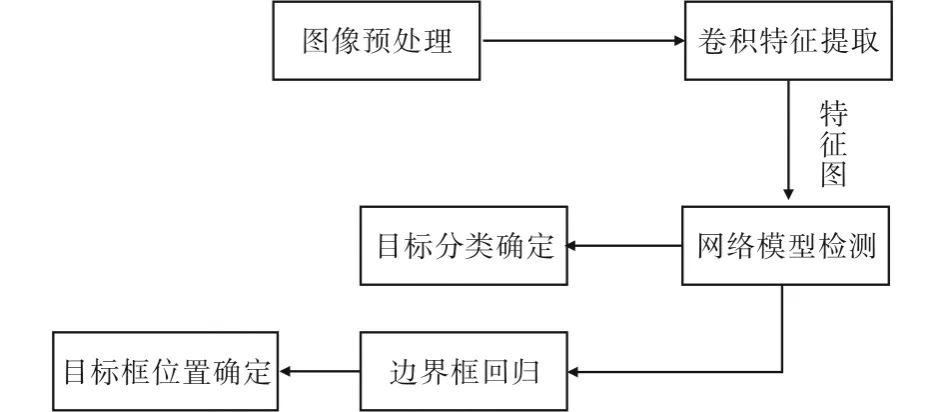
图3 检测框架
本文选用主流的YOLO V3作为目标检测模型,如图4,我们对输入特征图进行了5次降采样,并分别在最后3次降采样中输出检测结果,包括目标框的中心位置坐标、宽高、置信度及类别.分别在13×13,26×26,52×52三个尺度上对Anchor Box进行回归,最后通过对预测框的Confidence设定阈值,过滤掉低分的预测框,然后利用非极大值抑制(Non Maximum Suppression, NMS)处理预测框,完成目标检测任务.
1.3 遮挡标记与补偿机制
自然场景下,果树中枝干、叶片与水果实体之间的遮挡、重叠,都会影响模型对水果目标的实际检测效果,甚至导致漏检、错检.对于被遮挡目标的图像特征损失,本文提出遮挡标记和遮挡补偿机制,通过给不同遮挡场景下的水果目标添加不同的遮挡标记,并在模型训练过程中结合损失函数与遮挡补偿机制,增强模型对遮挡目标的敏感性,从而提高模型对遮挡目标的检测精度.
1.3.1 遮挡标记格式
本文针对自然场景下水果目标会出现的遮挡情况提出3种遮挡标记方式(表1).
(1)互遮挡标记
当目标与目标之间存在遮挡情况(如图5(a)),则向目标添加互遮挡标记occ_mutual,作为数据集的标记信息.
(2)背景遮挡标记
当目标与背景之间存在遮挡情况(如图5(b)),则向目标添加背景遮挡标记occ_background(i),作为数据集的标记信息.其中,i为背景遮挡级别,i根据目标物被背景物遮挡的区域的占比来确定.本文将背景遮挡级别定为3个等级,数据集标注时,当目标被背景物遮挡区域的占比在30%~40%时,确定i为3;占比20%~30%时,i为2;占比在10%~20%时,i为1.
(3)复合遮挡标记
当目标之间的遮挡和目标与背景之间的遮挡同时存在(如图5(c)),则向目标添加复合遮挡标记occ_complex(i),作为数据集的标记信息.其中,i与背景遮挡标记中的i类似.

图4 模型结构图

(a)互遮挡目标 (b)背景遮挡目标 (c)复合遮挡目标
1.3.2 遮挡补偿系数
本文对于不同遮挡情况提出遮挡补偿系数,以处理图片中不同的遮挡标记信息.
对于同一张图片中的所有标注框,讨论其中第k个标注框:
(1)若存在互遮挡标记occ_mutual,则由标注信息计算互遮挡系数occ_mut(k):
其中,GTk表示当前图片所有标注框的第k个,cross_area(k)表示当前图片所有标注框与第k个标注框的相交面积和,union_area表示当前图片所有标注框的合并面积和,n为当前图片中标注框总数.

表1 不同类型标记
(2)若存在背景遮挡标记occ_background(i),则由标注信息获取背景遮挡级别level(k),计算背景遮挡系数occ_back(k):
其中,level(k)表示第k个标注框的实际遮挡级别,info(k)表示实际标记信息occ_background(i)中的i.
(3)若存在复合遮挡标记occ_complex(i),则由标注信息计算复合遮挡系数occ_comp(k):
其中,α1和α2分别为互遮挡补偿系数和背景遮挡补偿系数的权值,count(labels)表示数据集中所有图片的对应标签计数,all_labels表示所有类型标签.
1.3.3 遮挡补偿机制
本文提出遮挡补偿机制,来补偿图像在遮挡条件下的信息损失,并提出将遮挡目标的补偿与损失函数融合,损失函数定义为:
Loss=Losscoord+LossIOU.
(1)对于坐标预测损失Losscoord.
模型对于目标框的坐标损失定义:
Losscoord=
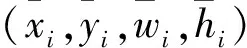
(2)对于IOU损失LossIOU.
考虑遮挡条件对于模型预测结果的影响,本文将遮挡补偿系数η引入目标框的IOU损失中,检测框与标注框的交并比IOU的定义为:
其中RT为标注框,RP为预测框.
目标框的IOU损失定义为:

其中,index(i)表示在当前图片的标注框中,当前Grid Cell对应框的索引;type(i)表示当前Grid Cell对应框的标记类型.
2 实验结果及分析
本实验采用64位Windows 7操作系统,硬件配置为Intel(R)Core(TM)i5-8500处理器,显卡为NVIDIA GeForce GTX1060,内存为6GB,使用Python语言和Tensorflow框架构建YOLO V3模型,使用OpenCV库对原始图像进行预处理.
实验结果评价主要以图像中检测框的精确率为依据,即:
其中,TruePositive表示真正例样本个数,FalsePositive表示假正例样本个数.
2.1 实验数据集
本实验的图片数据是结合人工采集和网络爬虫所获取.我们采集了“苹果”、“橘子”、“梨子”、“桃子”四类图片.考虑到模型的检测精度会受到训练数据集完整性的影响,我们将收集的图片在颜色、亮度和角度等方面进行了调整并扩充数据集以提高数据集的完整性,最终将图片总数扩充到600张,其中520张用于训练,80张用于测试.
2.2 总体分析
实验设定IOU的阈值为0.5,即若预测框与实际框的交并比大于等于0.5,认定该检测结果为真正例;若交并比小于0.5,则认定该检测结果为假正例.
表2展示了本文提出的结合遮挡补偿机制的目标检测模型与传统YOLO V3模型对4组数据集的检测精度值.

表2 不同水果的检测精度
可以看出,本文模型对4类数据集的检测精度均高于传统YOLO V3模型,其中对苹果数据集的增益最大,精度提高了6.1%,表明本场景下模型对苹果目标最敏感,最适于苹果检测.
总体来说,对于环境较为复杂的果园场景,本文模型对水果目标的检测精度有明显的提高.
2.3 定性对比
以下按照不同的遮挡目标类型分布进行划分,图6~图8给出了模型在不同遮挡条件下的检测精度.
(1)互遮挡场景

图6 互遮挡场景下检测图
由图6可看出,模型对苹果的检测精度提升最大,对其他种类的水果也有较大提升,说明使用互遮挡标记对遮挡场景进行描述,能明显减小水果间相互遮挡所带来的干扰,增强模型对于水果目标的敏感度,提高检测精度.
(2)背景遮挡场景

图7 背景遮挡场景下检测图
由图7可看出,模型对各种水果的检测精度总体有一定的提升,说明使用背景遮挡标记对遮挡场景进行描述,能对检测精度产生一定增益.
增益不是非常明显说明背景遮挡标记及其遮挡级别的定义还有不足之处,遮挡级别的模糊标记或者级别的粒度划分不当都可能产生检测误差.因此如何更确切地描述背景遮挡目标将是未来的研究方向.
(3)复合遮挡场景

图8 复合遮挡场景下检测图
由图8可看出,模型对各种水果的检测精度均有明显增益.
总体来说,在不同遮挡场景中,本文模型的检测精度相较于传统YOLO V3模型有明显提升,说明本文提出的遮挡标记和遮挡补偿机制对自然环境下目标检测精度的提升是有意义的.模型对各类水果的实际检测情况见图9.

(a)原始图像 (b)YOLO V3 (c)本文方法
3 结论
本文对于在自然条件下目标检测的遮挡问题,提出了遮挡标记方法与遮挡补偿机制.通过对数据集中的被遮挡样本进行标记,得到具有遮挡标记的数据集.对带有遮挡标记的数据进行特殊处理,并在模型训练过程中结合遮挡补偿机制,使模型的损失函数得到优化.实验结果表明:基于遮挡标记的目标检测方法相较于传统的YOLO V3模型,平均检测精度有明显提高.但是,如何将遮挡标记推广到一般目标检测数据集中,仍然需要研究.将数据集标注格式应用于一般数据集,提高人工标注的效率和精度,将是未来主要的研究方向.
