基于上下文语义的社交网络用户人格预测
2020-06-04王江晴陈思敏刘晶孙翀毕建权
王江晴,陈思敏,刘晶,孙翀,毕建权
(中南民族大学 计算机科学学院,湖北省制造企业智能管理工程技术研究中心,武汉 430074)
随着社交网络用户日益增多,网络用户行为已经成为社交网络领域重要的研究内容.人格是一种心理结构,旨在从一些稳定和可衡量的个体特征方面解释各种各样的人类行为[1].人格特质作为体现用户行为的重要因素,影响着人们的行为选择和习惯偏好,对社交网络用户的人格特质预测有许多重要的实际应用和研究价值.例如,在个性化推荐背景下,相似人格特质的人喜爱的产品也会高度相似[2];在心理问诊方面,心理疾病与人格特质存在一定的内在联系.在心理学领域,用来衡量一个人人格的最主流的模型是大五人格模型[3],大五人格模型从外向性(EXT)、神经质(NEU)、宜人性(AGR)、责任心(CON)以及开放性(OPN)等五个维度来分析和描述一个人的人格特质.
已有相关研究从社交网络文本中挖掘出一个人的人格特质与行为活动之间的潜在关系,验证了利用社交网络文本识别与预测用户大五人格的可行性[4-6].基于文本的用户大五人格预测主要工作有用户文本特征提取和分类模型构造.
大部分大五人格研究者使用到的文本特征提取方法有LIWC(Linguistic Inquiry and Word Count)、词袋模型[7]、TF-IDF[8]等.这些方法提取到的文本特征仅仅停留在词集的层面,很少对文本语义做研究.而文本的语义信息往往才是全面描述当前用户所要表达信息的载体,因此,我们认为分析文本潜在语义信息,从文本语义层面出发研究用户的大五人格,能更准确地挖掘出用户的人格信息.然而这些文本特征提取方法没有考虑社交短文本的上下文语义信息,使得对语义特征的提取不够精准,可能忽略掉很多文本关键信息,所以我们针对特征提取方法TF-IDF,引入上下文词语的共现关系来提取更多的语义信息.
在自然语言处理(NLP)研究工作中,与传统的机器学习方法相比,近几年广泛利用分布式表示[9]和深度学习的方法来分析和挖掘文本信息,其效果突出.深度学习的模型在基于文本的大五人格分类和预测工作中也逐渐被应用.MAJUMDER等[10]提出了一种使用CNN从意识流文章中提取人格特质的方法,提高了人格预测模型的精确度.WEI等[7]使用了社交网络的异质信息包括文本、用户头像、表情符号、用户交互信息来预测大五人格,其中文本信息特征的提取,结合了词袋聚类、LIWC和CNN等方法,对关键词只统计了词频,没有考虑上下文语义的有关信息,使得特征权重分配不佳.还有一些研究者使用了RNN[11,12]及其变种等方法作为预测模型,其结果与CNN相差不大.由于RNN模型计算步骤之间有前后依赖关系,并行程度不高,而CNN的所有卷积都可以并行执行,相比RNN并行程度更高,效率更快,而且容易捕捉到一些全局的结构信息,关键性短语在句子编码过程中能保持含义不变性,因此本文采用基于文本的卷积神经网络模型(Text-CNN),结合上下文语义特征向量来对用户文本进行训练以预测用户的大五人格.实验结果证明引入上下文语义信息后的模型在预测准确率上有一定的提高.
1 模型描述
1.1 结合上下文语义信息的社交文本特征提取
主流的文本特征提取方法TF-IDF没有考虑特征词之间的语义联系,使得提取的特征词表示文本语义强度不佳,为解决该问题,本文在TF-IDF计算过程中加入了上下文语义信息.
用户文本集表示为D={dj|j=1,2,…,N},N是用户文本集中的文本总数,词汇表表示为V={ti|i=1,2,…,M},M是词汇表中的特征词总数,统计用户文本集中的所有单词得到词汇表.
首先计算文本中每个特征词的TF-IDF[8]值,表示为:
tf-idfi,j=tfi,j·idfi,
其中,tf-idfi,j表示单词ti在文本dj中的TF-IDF值,其中tfi,j表示为:
其中,tfi,j表示单词ti在文本dj中的词频.ni,j是单词ti在文本dj中出现的次数,nj是词汇表中所有单词在文本dj中出现的次数之和.idfi表示为:
其中,idfi表示单词ti的逆向文本频率,j:ti∈dj是包含单词ti的文本个数.
然后统计词汇表中特征词ta与特征词tb(b≠a)同时出现在用户文本集的文本条数,如果文本条数不小于2,则ta与tb是一对共现词对[13],记为ta,b,此时的文本条数代表ta,b的出现频率,记为fta,b.根据fta,b计算单词的上下文语义值,公式为:
其中,swa,j表示文本dj中单词ta的上下文语义值,tf-idfb是文本dj中单词tb的TF-IDF值.
最后由单词的上下文语义值和TF-IDF值计算出文本dj中每个词的权值,公式为:
twi,j=α·tf-idfi+(1-α)·swi,j,
其中,twi,j表示文本dj中单词ti的权值,α为权重.
结合上下文语义信息的词权值计算的时间复杂度分析如下:首先,计算特征词的TF-IDF值的时间复杂度为O(n);其次,计算特征词-特征词共现词对矩阵的时间复杂度为O(n2);然后,计算单词的上下文语义值的时间复杂度为O(n);最后,计算文本中每个词的最终权值的时间复杂度为O(1).综上,结合上下文语义信息的词权值计算的时间复杂度为O(n2).
1.2 基于Text-CNN的人格预测模型
上下文语义信息是人工提取的特征,与深度学习预测模型自动提取的特征相比,特征之间表达的含义不同,在预测模型中加入上下文语义特征,人格相关潜在特征得以丰富,从而达到优化预测效果的目的.为验证在预测模型中加入上下文语义信息是否能提高大五人格预测的准确率,我们选取Text-CNN作为人格预测模型,模型架构如图1所示,将卷积和池化操作得到的抽象特征向量与1.1节结合了上下文语义的特征向量连接后,送到全连接层以及输出层进行人格分类.
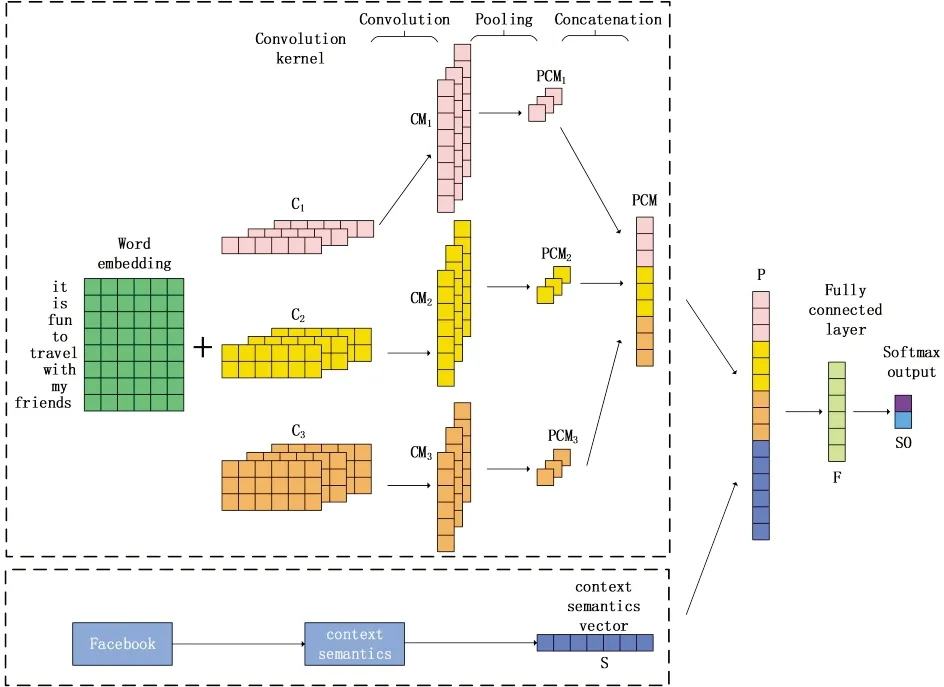
图1 Text-CNN+context semantics模型架构
模型使用到的变量定义如表1所示.

表1 符号表
输入层:输入的句子通过对字典的lookup生成句嵌入,即二维矩阵,每一行表示为单词的词向量.因此,输入是一个数组AW×E.
卷积层:卷积核定义为Cn∈AK×n×E,n= 1,2,3.卷积窗口从句子矩阵最上方开始向下滑动直到句子结尾,每次滑动考虑n个单词,通过卷积计算得到该句子的特征映射CMn∈AK×(W-n+1)×1,激活函数为ReLU.
池化层:对CMn做平均池化操作,得到输出特征向量PCMn∈AK,将所有的PCMn连接得到最终的池化结果PCM∈A(K×n).
结合了上下文语义的特征向量:对于输入的每个句子,其结合了上下文语义信息计算得到的特征向量为sj=(tw1,j,tw2,j,…,twV,j),sj∈AV.将sj与PCM连接作为下一阶段的输入向量P,P的计算公式为:
P=concat(PCM,sj),P∈A(K×n+V).
全连接层:将P与两个全连接层矩阵做运算,得到更深层的特征表示,如图1列向量F.
输出层:使用softmax函数对最后的人格结果进行预测,得到二分类结果如图1列向量SO.损失函数的计算公式如下:
其中,yi′是该人格预测的概率值,yi是人格的实际值.
对于大五人格的五维人格特质,我们训练5个独立的Text-CNN模型,它们的网络结构一致.
2 实验及分析
2.1 数据集
实验采用Facebook中myPersonality应用的公共数据集.myPersonality中包括essay和Facebook用户文本,发表这些文本的用户已经填写了大五人格量表问卷并得到大五人格的评测结果,这些文本已标注用户大五人格类别.我们通过人格识别计算研讨会的共享任务[14]获得Facebook的用户文本数据.其中80%的数据集用于训练,剩下20%用于测试.
2.2 文本预处理
在自然语言处理中,文本分类结果的好坏,一方面取决于分类器的好坏,另一方面与文本前期的预处理工作有很大关系.文本的处理步骤如下:
1)去掉文本中的邮箱地址和网址.这些信息与人格特征关系不大;
2)拼写检查更正.使用pyenchant类库检查单词拼写,找出错误后,根据需要来更正;
3)缩写词还原.如“I′m”还原成“I am”;
4)将单词转化为小写,并引入停用词表删除一些无效字符,以降低词汇表的维度;
5)去除数字和一些标点符号,并保留如“!!!”、“!!!!!!”等标点符号,因为这些重复的符号是用户用来强调情绪的直接表现.同理我们还保留了如“yayayaya”、“freeeeee”、“ahhhhhh”等含重复字母的单词;
6)词形还原.一个单词会有单数、复数和时态等多种不同的形式.我们使用自然语言处理工具(nltk)将文本中的单词还原成原形形式,从而生成最终的词汇表.
2.3 实验参数设置
通过不断调整超参数来降低随机梯度,以使训练的模型最佳.对输入的句嵌入的向量维度、词嵌入的向量维度、卷积核的核宽以及每种卷积核的个数等进行设置.对于训练,每迭代100次进行一次验证,并保存结果.表2展示了实验设置的超参数.
特别地,对于实验参数Batch_size,表示一批训练数据的文本条数,取值范围为{20,30,40,50},选20至50之前,用更大范围的数值训练过模型,发现在20至50区间效果最好,所以在这个区间更细粒度地训练了模型.其中每一种取值测试20组数据,共测试80组,训练五个人格维度模型则为400组.结果如表3所示,展示了每种取值下Text-CNN+context semantics各人格维度模型预测准确率的平均值和最高值.表4展示了未加入上下文语义时Text-CNN模型预测准确率的平均值和最高值.我们将预测准确率最高时的Batch_size取值作为最终生成的模型的Batch_size值,即得到的Text-CNN+context semantics五个人格维度模型的Batch_size取值分别为{20,50,50,20,20},Text-CNN五个人格维度模型的Batch_size取值分别为{40,50,50,50,30}.

表2 实验参数设置

表3 Batch_size取不同值时Text-CNN+context semantics模型预测的准确率

表4 Batch_size取不同值时Text-CNN模型预测的准确率
2.4 评估指标
本文以准确率(Accuracy)来评估实验结果的好坏,其公式为:
2.5 实验结果分析比较
本节将讨论模型训练中的收敛情况,以及5个人格维度上的卷积神经网络模型在引入上下文语义后,预测准确率上的差别.
图2给出了引入上下文语义后,开放型人格(OPN)维度上的Text-CNN+context semantics模型在训练过程中损失率和准确率的变化折线图.以OPN维度上的Text-CNN+context semantics模型为例,可以看出模型随着训练步数的增长,准确率逐渐增加,损失函数逐渐减小,在3000步左右的时候模型趋于收敛.
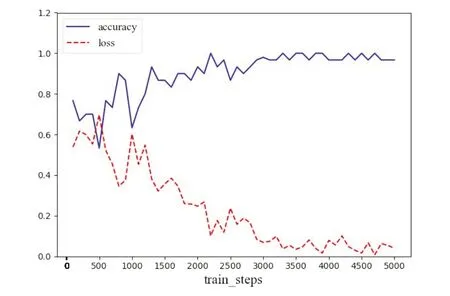
图2 Text-CNN+context semantics/OPN上的损失率和准确率
图3给出了引入上下文语义之前,开放型人格维度上的Text-CNN模型训练过程中损失率和准确率的变化折线图.可以看出Text-CNN模型在训练步数的增长时准确率的增加以及损失函数的减小,在3800步左右的时候趋于收敛.其他4个人格维度上的两种模型对比也有类似结果.经过比较可以看出,Text-CNN+context semantics模型,在参数相同的情况下,模型收敛的速度要快于Text-CNN模型,因为加入上下文语义后,模型学习到有关人格特质的特征速度更快.
WEI[7]和MAJUMDER[10]在预测用户大五人格时均使用了Text-CNN模型,为了验证实验中加入了上下文语义信息的效果,我们与Text-CNN模型进行比较.表5展示了本文方法与Text-CNN模型、文献[8]的SMO算法以及文献[15]的全连接架构在用户大五人格5个维度上的预测准确率.

图3 Text-CNN/OPN上的损失率和准确率
可以看到,在五个人格维度上的准确率,Text-CNN+context semantics模型均比Text-CNN模型要高,Text-CNN+context semantics模型在外向型(OPN)人格维度上的准确率最高达到70.2%,模型预测准确率相对较高的原因在于加入上下文语义后,提取的文本语义特征更加丰富,模型学习到的有关人格特质的特征更多,模型更精准;同时,本文方法预测大五人格准确率仅在神经质型人格(NEU)上的准确率比SMO低1.33%,但整体上的准确率比SMO以及只使用全连接层的神经网络要高.

表5 不同模型准确率对比
3 总结与展望
传统的利用文本信息来分析和预测大五人格的方法中,对于文本特征的提取阶段,未充分考虑上下文语义,语义特征的提取不够精准,会忽略掉很多文本关键信息,本文针对此问题引入短文本上下文的共现词对,结合上下文语义权重向量与Text-CNN模型,得到Text-CNN+context semantics模型来预测用户大五人格,实验结果表明本文的方法在准确率上有所提高.对于加入上下文语义前后,模型最佳时的参数Batch_size在不同人格维度上的取值不同,后续工作会继续增加Batch_size各个取值训练的次数,以探究其原因.未来我们会考虑将提取的上下文语义加入到其他深度学习模型如RNN、长短期记忆网络(LSTM)中,验证上下文语义结合到预测模型中的通用性.
