基于视网膜大细胞通路计算模型和深度学习的
2020-06-03
(1.南华大学,衡阳,421001;2.军事医学研究院军事认知与脑科学研究所,北京,100850)
1 引言
随着无人机相关技术的快速发展,民用小型无人机已经被应用于生产和生活中的方方面面,为人类社会带来极大便利.然而由于无人机有灵活度高、隐蔽性强、成本低廉等特点,无人机或被不法分子用于恐怖袭击、偷拍隐私等活动,因此无人机预警探测在公共安全领域具有重要现实意义.
当前,目标检测领域分为静态目标检测和视频目标检测两个方向.静态目标检测算法通常分为双阶段和单阶段两种类型.双阶段类型的经典方法有R-CNN[1],Fast R-CNN[2],Faster R-CNN[3].相较于传统手工特征提取方法,例如尺度不变特征变换[4](Scale-invariant feature transform, SIFT)、方向梯度直方图[5](Histogram of oriented gradient, HOG),基于深度学习的特征提取方法更加准确和有效.与双阶段检测模型相比,单阶段算法检测速度快但精度偏低,主流方法有YOLO(You Only Look Once)[6-8]系列和SSD(Single Shot MultiBox Detector,SSD)[9].相较于静态目标检测,视频目标检测在训练过程中能利用某段时间内相邻帧间的时空信息避免大量无效的特征提取,减少重复信息的同时充分保留和利用有效信息是视频目标检测的一个主要方向.代表性方法包括Han等[10]提出的Seq-NMS算法,根据连续帧之间的检测框的重合度建立时空图;Zhu等[11]提出的基于光流的特征聚合算法FGFA,该算法通过利用视频帧间的时空信息达到视频检测的效果;Kang等[12]在静态图像检测的基础上利用上下文信息抑制和动态信息传播等机制提出T-CNN模型,从而实现视频目标检测效果;而STSN[13],STMN[14]在不使用光流算法的情况下,直接学习对齐和聚合特征;Wang等[15]提出的MANet则是利用FlowNet预测的光流在相邻帧之间传播特征;Luo等[16]提出的STCA检测算法,该算法通过对上下文时空信息进行增强、自动学习特征增强策略来弥补Seq-NMS的缺陷;Deng等[17]提出的RDN则是学习局部范围内不同帧之间候选框的相关性来增强特征;Chen等[18]提出的MEGA算法是通过局部和全局的特征聚合达到较高的检测性能.
近年来,以深度学习为代表的智能视觉感知算法已经可以实现标准场景下的无人机检测.例如,崔艳鹏等[19]在YOLO-v3的基础上,通过改进模型网络结构提出一种实时的无人机检测算法,但该算法在准确率和召回率与其对比算法还存在较大差距.Sun等[20]提出一种基于TIB-Net的无人机检测算法,通过在迭代骨干网络中引入循环通路机制获取低层特征信息,在有效提取小目标特征的同时缩小模型结构,但是该算法在检测速度方面尚难以达到实时性.梁栋等[21]提出一种将检测与跟踪相结合的无人机检测算法,引入KCF(Kernel Correlation Filter, KCF)跟踪算法抑制检测的漏检率.Fernandes等[22]通过融合跟踪机制和残差网络,提出一种在检测模块前通过一个跟踪模块判断是否存在无人机的目标检测网络.另外马旗等[23]通过利用残差结构和多尺度预测网络提出Dual-YOLO-v3算法,但该算法严重受到采集系统的约束,在复杂背景下的图像配准变得十分困难.王靖宇等[24]通过提取无人机在多尺度层次上的视觉特征来检测远距离小型无人机.Rozantsev等[25]利用运动补偿机制来弥补视频中小目标的位置偏移问题.还有余科锋[26]通过利用动态阈值的CFAR图像分割提取特征的方法,用来检测红外视频中的无人机.
以深度学习为核心的智能算法能够在简单环境下实现目标检测效果,但由于这些算法特征提取单一,当无人机在建筑物遮挡、形变等复杂背景下,外观信息受到背景的严重干扰,这些算法检测效果远不及生物视觉系统对于环境变化的适应性和精确性,在复杂环境下,生物视觉系统可以有效应对环境变换从而快速捕捉目标位置.80年代初,Underleider等[27]通过对猴脑的损伤研究,认为大脑视皮层中存在两条视觉通路:腹部流(ventral stream)和背部流(Dorsal stream),其中腹部流主要负责物体识别,而背部流主要处理物体的空间位置信息.Poggio等[28]根据腹部流视觉信息处理过程提出HMAX模型,该模型模拟一个层级的前馈结构实现了前馈信息的传递.Serre等[29]在HMAX模型上根据生物结构和实验数据构造了一个标准模型,首次将生物视觉和计算机视觉进行联系.Mutch等[30]通过添加图像层来改进Serre的模型,在1998年,Rybak等[31]提出Rybak模型,该模型主要针对于物体识别和场景感知,以及之后对Serre理论延申和发展的一些科学成果相继发表[32-35].2010年,Benoit等[36]利用人类视网膜的信息传导机制建立视网膜模型,并将该模型应用到图像处理和计算机视觉领域,取得了显著的效果.受人类视网膜信息处理机制启发,通过细胞间的时空滤波变换提取无人机在复杂背景下的运动信息.该类脑算法不仅能高效地提取视频中目标的运动特征,而且相较于深度学习模型运算量更小.
本文通过引入仿视网膜算法,在此基础上进行模拟和改进,借助大细胞通路模型提取时空运动信息,并将其与YOLO-v3输出的目标置信度图进行融合,从而得到融合视网膜时空运动信息的无人机目标检测算法——Rtn-YOLO,并基于Anti-UAV2020数据集对Rtn-YOLO和业内主流的YOLO-v3方法进行了性能评估和对比.
本文的组织结构如下:第1部分是基于YOLO算法和视网膜算法的模型加工,第2部分是Rtn-YOLO算法的详细介绍,第3部分是实验结果和算法评估,第4部分是对于论文的讨论和总结.
2 基于YOLO的目标检测算法和视网膜信息加工模型
2.1 基于YOLO模型的无人机检测算法
YOLO-v3是由YOLO算法改进后以Darknet-53为骨干网络的单阶段目标检测算法,通过将图片分为等分的S×S个网格用于目标位置的定位,再借助K-Means算法对MC COCO数据集进行聚类,获得9个长宽不一的先验框,利用卷积神经网络让网格对每个物体类别预测一个条件概率值同时生成B个先验框,每个先验框预测5个值(其中前4个值表示先验框的位置,第5个表示这个先验框含有物体的概率),然后得到3个大小不同的特征图以及对其分配先验框,最后使用先验框后处理以及非极大抑制(Non-Maximum Suppression,NMS)得到预测框.
2.2 视网膜信息加工模型
视网膜是将光信号转换为神经系统中的电信号的重要部分.视网膜生物结构主要由外丛状层(Outer Plexiform layer)和内丛状层(Inner Plexiform layer)两部分组成,细胞层上主要包含光感受器细胞(Photoreceptor cells,Fph)、水平细胞(Horizontal cells, Fh)、双极细胞(Bipolar cells, BipON/BipOFF)、无长突细胞(Amacrine cells, A)和神经节细胞(Ganglion cells)五种类型的神经细胞.
在外丛状中,光感受器细胞可作为一个亮度调节器的功能(Cph)的功能,同时将其感受到的光信号传递给水平细胞和双极细胞,构成一个突触三联(The ynaptic triad)[37],水平细胞之间的缝隙连接(Gap junctions)是一个低通时空滤波器.根据Benoit[36]等人的观点,外丛状层的细胞相互作用可以看作是光感受器网络和水平细胞网络两个低通时空滤波器之差,该时空不分离的滤波器在低时间频率时有空间带通效果,低空间频率时有时间带通效果.
内丛状层中的信息传递有两条通路:大细胞通路(Magnocellular pathway)和小细胞通路(Parvocellular pathway),在无长突细胞的介导下,双极细胞将其信号传递给轴突形成视神经的神经节细胞.
图1展示了基于视网膜小细胞通路模型的算法结构示意图,小细胞通路的小型神经节细胞(Midget ganglion cells)直接与双极细胞相连,接收来自外丛状层的两极输出的轮廓信息,同时作为一个局部增强器(CgP)用来增强轮廓数据和外观纹理等信息的提取.
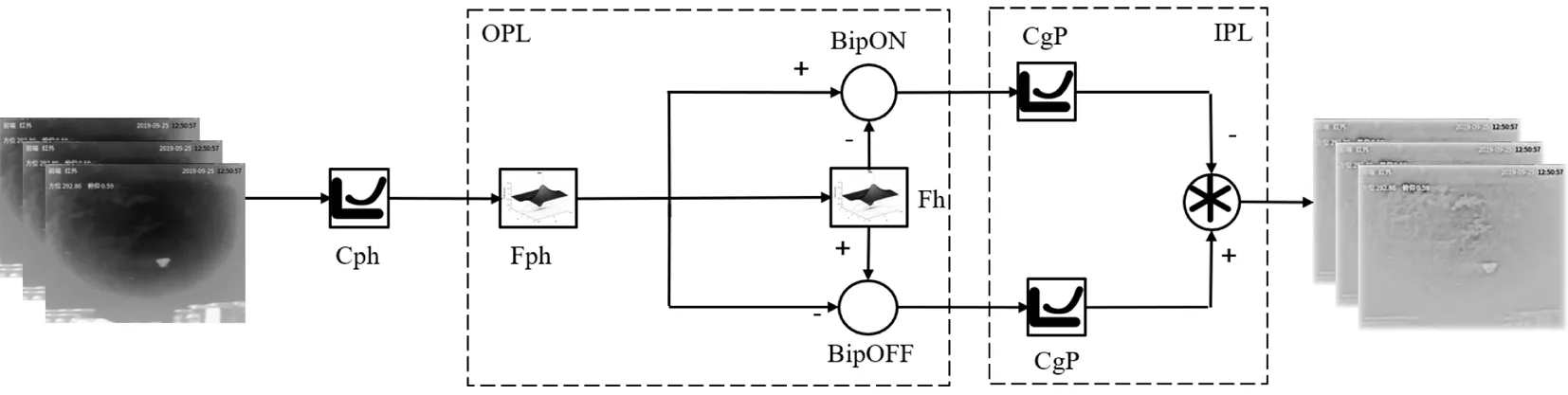
图1 视网膜小细胞通路算法结构示意图
大细胞通路主要负责提取物体的运动信息,算法结构图如图2所示,其中无长突细胞看作是一个高通时间滤波器.在无长突细胞的介导下,小型和大型阳伞神经节细胞收集多个弥漫性双极细胞的信号,此类神经节细胞既可以作为像小细胞通路中的局部增强器(CgM),也可以作为一个空间低通滤波器(FgM).
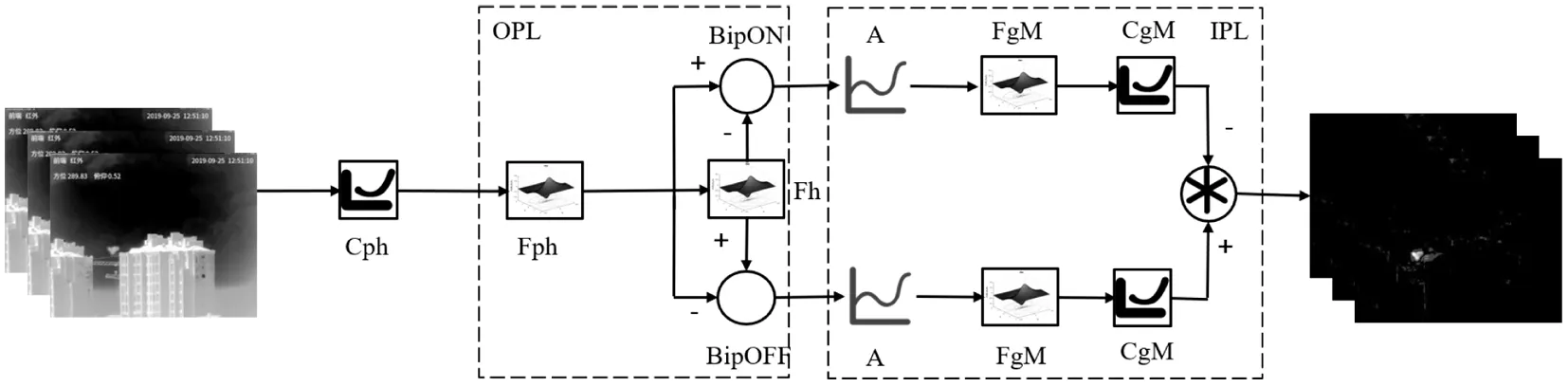
图2 视网膜大细胞通路算法结构示意图
3 面向无人机目标检测的Rtn-YOLO算法
3.1 Rtn-YOLO算法结构
图3展示了Rtn-YOLO算法结构框架.该算法对输入的视频流分别通过两支流特征提取器提取外观和运动等特征.YOLO-v3算法以深度神经网络为核心,该算法对输入图像的尺寸大小要求不固定(32的整数倍),若以416×416为例,图像经过网络的3次(8倍,16倍,32倍)下采样之后,形成的特征图分别为(52,52),(26,26),(13,13),将3个特征图进行特征合并之后进行先验框后处理,提取物体的静态信息特征.视网膜大细胞通路对物体的外观信息敏感,视频中的物体在相邻帧有相对运动时,图像经过视网膜中光感受器细胞、水平细胞、双极细胞、无长突细胞和神经节细胞的信息处理后,能够快速清晰地捕捉到运动物体的轨迹特征的同时抑制静态背景,然后其与YOLO-v3算法模型中的网络结构提取出的外观信息相结合,通过融合图像与YOLO-v3预处理的结果进行筛选匹配后,获取最终无人机视频目标检测结果.
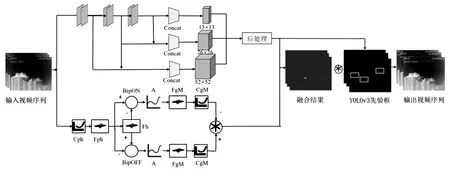
图3 面向无人机检测的Rtn-YOLO算法结构流程图
3.2 深度学习提取外观信息与视网膜算法提取外观信息的融合
现有其他算法在净空等简单背景下的无人机检测精确度较高,Rtn-YOLO算法着重解决在复杂背景下的无人机视频目标检测面临的问题,依据视网膜大细胞通路的对运动信息提取的优势,采用大细胞通路与YOLO-v3模型融合的方式,解决现有算法对无人机在遮挡、形变、瞬移等情况下失效的问题.Rtn-YOLO算法利用人类视网膜对运动信息的敏感性提取视频上下文信息,通过大细胞通路提取物体的运动特征抑制静态背景噪声.为了充分利用大细胞通路提取的运动信息,降低算法的漏检率和虚警率,首先降低先验框置信分的交并比(Intersection over Union,IoU)阈值,使YOLO-v3尽可能多地获得图像中潜在无人机的先验框,然后保留置信分较高的先验框,再筛选出图像像素最大的先验框,最后选取置信分最高的的检测框.算法流程图见表1.

表1 无人机检测的Rtn-YOLO算法流程图
4 实验结果
4.1 实验设备
实验所采用的计算机操作系统版本是Ubuntu 16.04.1;Linux内核版本是Linux amax 4.4.0-31-generic;代码运行平台是:Python3.6,Tensorflow1.14.0,GPU:Tesla K80×16.
4.2 红外无人机视频目标检测数据集
Rtn-YOLO算法性能评估采用Anti-UAV2020数据集,图4为所用数据集的红外无人机视频缩略图.

图4 红外无人机视频缩略图
该赛程主要针对基于多模态视频流数据的复杂环境下无人机目标的检测、跟踪、识别等视觉感知与处理任务.该大赛举办的同时公开了160段红外视频序列(https://anti-uav.github.io/submission/),视频中包含多个不同的场景和多种类型的无人机,在每段视频中都含有部分复杂背景,包括云雾、楼宇、快速运动、悬停、遮挡等情况,但数据集中复杂背景图片数量占比较小.在赛程里提供的160段视频,其中有标注信息的100段视频用来对模型进行训练和验证,尚未标注的60段视频用于测试.本算法采用其中的100段已标注好的红外视频,共93247张图片,选取其中的70段视频(65100张图片)用于模型的训练和验证,剩余的30段视频用于模型的测试.训练20次且最终使得模型达到收敛.
图5展示了Rtn-YOLO算法与YOLO-v3算法在复杂背景下的无人机检测效果对比.a,b,c,d代表四个不同的样例,其中第一行是原始图片,图片中的红色框代表无人机的真实位置;第二行是YOLO-v3的检测效果,从图中可以看到,一旦当无人机飞行在楼宇、吊塔等红外复杂背景下,YOLO-v3无法检测到无人机的位置或者误检到其他目标当作是无人机;第三行是Rtn-YOLO算法的检测效果,能正确的检测到在红外环境下的无人机.

图5 Rtn-YOLO算法与YOLO-v3算法在复杂背景下的无人机检测效果对比
4.3 评估结果
算法评估结果如表2所示,YOLO-v3算法在测试集上的检测平均精确率为82.04%,Rtn-YOLO算法检测平均精确率达到86.90%,比基准算法YOLO-v3提升了4.86%.当在YOLO-v3模型中加入视网膜小细胞通路提取的特征时,由于静态背景的噪声对小细胞通路提取的特征影响较大,故而精度降低.

表2 Rtn-YOLO与YOLO-v3检测对比
通过数据分析发现,在Anti-UAV2020数据集中,数据集中无人机处于净空背景下的简单场景图片数居多.由于其复杂背景的图像帧在所有数据集中的占比较小,无人机在遮挡、楼宇中的图片量偏低,为了测试单个视频中的表现情况,从30个测试集中随机抽取10个视频,测试结果如表3所示.在10个复杂背景下的红外无人机视频中,其中6个视频的平均精确率有大幅提升,4个场景较简单视频的略低,表明Rtn-YOLO算法整体比YOLO-v3算法更加稳定,在简单的环境下能够保持与基准算法有同等的平均精确率,对于在复杂背景下时能够弥补其缺陷.
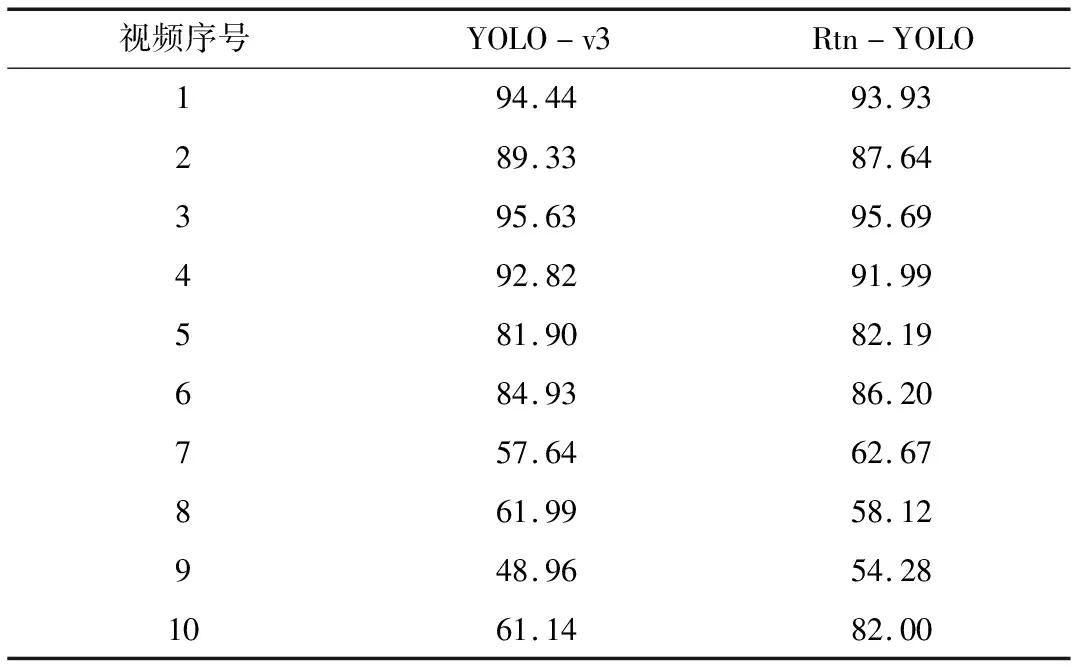
表3 Rtn-YOLO算法在10段红外无人机视频检测结果对比
4.4 消融实验
已有文献表明,信息融合的方式多种多样,最常用有效的方式是将两支信息流取交集[38].本文在YOLO-v3提取的外观信息和大细胞通路提取的运动信息基础上,对在两支信息流的输出结果对应像素取交,该方式不仅能将提取到的双支流信息进行有效的融合,而且能抑制静态背景产生的巨大噪声.为了验证该融合方式在Rtn-YOLO算法上检测结果,通过与其他融合方式进行对比,在将大细胞通路提取的运动信息和YOLO-v3提取的纹理信息整合的过程中,由于信息融合的方式不同导致的检测效果也存在较大差异,从左至右分别是将大细胞通路的输出结果和YOLO-v3的输出分别取和(a),取积(b),取并(c)和取交(d)的结果.从图6数据集的测试结果看,其中取和与取并后的融合图效果存在较大的噪声,不能正确检测到楼宇中无人机的位置,取积与取交后的融合图更加干净,但取积之后的检测效果不如取交的效果好.

图6 Rtn-YOLO算法信息融合方式对比
5 总结与讨论
针对传统无人机检测算法无法检测复杂背景下运动目标的问题,本文通过引入大细胞通路模型提取时空运动信息,并将其与YOLO-v3输出的目标置信度图进行融合,从而提出了融合视网膜时空运动信息的无人机目标检测算法——Rtn-YOLO算法.实验结果表明,算法提高了无人机在复杂背景下的检测的精确率.相比传统YOLO-v3目标检测算法,Rtn-YOLO算法通过人类视网膜机制提取运动信息减少静态背景噪声造成的干扰,该类脑算法是通过对视网膜视觉通路中的细胞进行数学建模,有效提取视频中目标的时空特征,将生物视觉与计算机视觉相互融合,进一步完善深度神经网络在图像特征提取过程中的信息丢失的问题.但该算法仍然存在提升,由于Rtn-YOLO算法检测框对置信分的降低,使得部分检测框的掩码相互重叠,以至于图像中某些检测框包含的像素值并不是它自身,导致结果存在一定偏差,此类问题将在下一步工作中进行优化和解决.
