改进的TransH模型在知识表示与推理领域的研究
2020-05-29昌攀曹扬
昌攀,曹扬
(中电科大数据研究院国家工程实验室, 贵州贵阳550081)
0 引言
伴随着大数据时代的到来,各行各业的数据呈现爆炸式的增长,知识图谱(knowledge graph)[1]为高效利用这些海量的数据资源[2-3]提供了一个强大的引擎。知识图谱最早是由谷歌(Goole)公司于2012年提出来的,最初的目的是帮助谷歌提高智能化的搜索,提供一种实体间关系的语义网络,现在主流的知识图谱已经发展成为支撑众多人工智能(artificial intelligence, AI)应用的核心,常见的AI应用包括智能搜索、自动问答[4]、推荐系统[5]、决策支持等。知识图谱中包含着大量的事实三元组,将实体(包括概念、属性值)表示成知识图谱中的节点,节点之间的连接表示关系,以(头实体,关系,尾实体)[表示为(h,r,t)]的形式存储,用网状的结构展示所获取的知识。目前,已经建成的知识图谱包括Yago[6]、DBpedia[7]、FreeBase[8]等。
虽然在过去的十几年中,知识图谱取得了巨大的发展,但是还存在着一些局限,其中知识图谱不能包含所有的知识就是一个重大的局限,知识图谱的不完整性严重制约了AI领域中应用程序的效能,如何通过现有的知识补充、完全知识图谱中所有的知识逐渐成为了知识图谱领域里亟待解决的问题之一。知识图谱补全(knowledge graph completion, KGC)是解决这一问题的重要技术手段。知识图谱补全旨在补全知识图谱中不完整的知识[9],其中最重要的方法就是知识推理。
目前,最常见的知识推理是基于分布式表示的推理。知识图谱分布式表示方法[10]是将网状的语义信息表示成稠密的低维的实值向量,向量之间的距离代表了两个语义对象之间的相似程度,距离越小,代表相应的语义对象相似度越高,反之亦然。BORDES等[11]提出了第一个基于翻译的表示模型——TransE用于知识推理,TransE模型将知识图谱中的实体和关系表示成低维嵌入式向量,将每一种关系看做是嵌入式空间中的一个翻译,对于知识图谱中存在的三元组(h,r,t),基于翻译的模型满足低维表示头实体向量h与关系向量r的和接近尾实体向量t的值,即h+r≈t,否则远离。TransE模型适用于处理一对一的关系,无法很好地处理一对多,多对一和多对多的关系。TransH模型[12]克服了处理一对多,多对一和多对多的关系的弊端,TransH模型将关系当做是在特定的关系超平面上的翻译,使用超平面的法向量wr和关系翻译向量dr表征模型,首先将头、尾实体映射到超平面中,得到映射后的实体h⊥=h-wrThwr,t⊥=t-wrTtwr,然后构造翻译模型,获得h⊥+dr≈t⊥。针对TransE和TransH模型都是将实体和关系映射到同一空间的状况,与现实中实体和关系具有不同的属性和类别的情况相矛盾,TransR和CTransR[13]提出实体空间与关系空间不相同的理论,它们同样都是将知识图谱中三元组实体和关系嵌入到不同的实体空间和关系空间中,然后通过映射Mr将实体从实体空间映射到关系空间中进行hr+r≈tr翻译学习。CTransR不同于TransR之处在于:在特定的关系下,头、尾实体通常映射成不同的模型,仅仅通过单个关系向量还不足以实现从头实体到尾实体的所有翻译学习,CTransR借助分段线性回归的思想,通过对不同的头尾实体对聚类分组个学习每组的关系向量。
以上的Trans系列方法在模型的训练过程中,构造的负例三元组仅仅是通过正例三元组按照一定的策略替换头、尾实体得来的,并未考虑到替换后的头实体/尾实体与原头实体/尾实体之间的相似度关系,例如:在一个(美国,总统,特朗普)三元组关系替换过程中,将“特朗普”替换成“奥巴马”的错误程度远远低于将“特朗普”替换成“比尔盖茨”的错误程度,受到文献[13]的启发,提出了改进的TransH模型(mTransH),mTransH模型在构造损失函数的过程中,采用单层神经网络的非线性操作来精确刻画实体和关系之间的语义信息,创新性地加入了正、负三元组间的头/尾实体之间的差异度信息,用于校正正、负三元组样本之间的联系,降低负例样本的错误程度,提高模型对实体的辨识度,从而提高知识链接推理的准确率和Hit@10指标。
1 mTransH模型
1.1 相关工作
Trans系列的模型是对知识库中的实体、关系三元组进行分布式表示学习,符号h表示三元组中的头实体,r表示三元组中的关系,t表示三元组中的尾实体,对于分布式表示的头、关系、尾实体使用加粗的符号h,r,t表示,除此之外,使用符号△表示知识库中正例的三元组集合,符号△′表示负例三元组样本集合,E表示实体的集合,R表示关系的集合。
TransE模型将实体集E和关系集R都映射到同一个平面中,经过表示后的向量(h,r,t)∈Rk,并且对于知识库中的正例三元组满足‖h+r-t‖l1/l2值较低,其中l1/l2代表距离计算的范式,尽管TransE模型在知识库中的一对一的推理问题上效果较佳,所需参数较少,但是无法解决自反、一对多、多对一关系的问题。假定对于任意正确的三元组(h,r,t)∈△,经过表示后的实体、关系向量都满足h+r-t=0,可以推理得到以下的一些结论:
① 对于自反关系,存在(h1,r,t1)∈△,同时(t1,r,h1)∈△也是成立的,r是一个自反的关系,它们经过翻译后的向量同时都会满足h1+r-t1=0,t1+r-h1=0,经过运算后,可以得到h1=t1,r=0,这显然与实时的情况不符合,例如三元组(小明,好朋友,小张),反之亦然(小张,好朋友,小明)成立,但表示后的向量“小明”却不应该等于“小张”;
② 对于一对多的关系,对于∀i∈{0,1,…,m},(h,r,ti)∈△,r是一对多的关系,经过翻译后的向量都应该满足h+r-ti=0,经过运算,可以得到t1=t2=…=tm,这种表示后的尾实体向量都相等与事实情形严重不符合;
③ 对于多对一的关系,对于∀i∈{0,1,…,m},(hi,r,t)∈△,r是多对一的关系,经过翻译后的向量都应该满足hi+r-t=0,经过运算,可以得到h1=h2=…=hm,这种表示后的头实体向量都相等与事实情形严重不符合。
综上所述,TransE模型在自反、一对多和多对一的关系上无法很好地反映现实三元组的一些特征,其根本原因是实体和关系集都映射在同一个平面上,经过运算后,出现在多个关系中的同一个实体的表示是相同的情形,TransE和TransH翻译后的向量关系如图1所示。TransH采用了不同的思路对实体、关系集进行表示,借助关系超平面将不同的实体映射到同一个平面中,然后再对知识图谱的三元组进行运算,即使不同的实体,只要能满足在超平面上投影的向量相同就可以进行运算了。

(a) TransE

(b) TransH
1.2 mTransH模型
mTransH模型在构造代价函数的过程中,受到CTransR模型的聚类思想启发,通过计算构造的负例三元组与正例三元组(又叫黄金三元组)之间的替换对象的相似度,然后将相似度转化为差异度(假定:相识度+差异度=1)加入到mTransH代价函数中,让mTransH模型能够比对替换的三元组与正确三元组之间的相似、差异关系,提高模型在辨别正例三元组上及其相似的三元组上的能力,从而提高模型的知识推理准确率和Hits@10的指标。
在mTransH模型中,实体和关系拥有不同的表示,并且每一个关系都对应一个超平面。如图1(b)所示,首先将实体向量h和t沿着超平面的法向量wr投影到关系r所对应的超平面上,其中‖wr‖2=1,投影后的向量可以表示为:
h⊥=h-wrThwr,t⊥=t-wrTtwr。
(1)
经过投影后的向量的得分函数可以表示为:
(2)
损失函数表示了一个三元组正确程度的差异,对于正确的三元组,得分函数打分越低越好,反之亦然。受到文献[14]的启发,可以通过单层神经网络来减轻距离模型中无法精确刻画实体和关系语义联系的问题,将神经网络的引入到得分函数后的得分函数表示为:
(3)
其中,g( )函数为tanh函数。
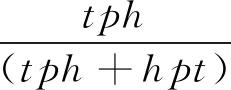
(4)
其中[x]+max(0,x),△表示知识图谱中的正例三元组,△′(h,r,t)表示由相应的正例三元组(h,r,t)替换头/尾实体构造得到的负例三元组,γ>0表示分割正负例三元组样本的间隔值。最小化成本函数的时候,同时也考虑了以下的限制:
∀e∈E,‖e‖≤1,
(5)
∀r∈R,|wrTdr|/‖dr‖2≤ε,
(6)
∀r∈R,‖wr‖2=1。
(7)
将这些限制函数加入到成本函数中,可以得到实际上要训练的成本函数为:
(8)
通过分析式(7),成本函数中只考虑到了正例三元组与负例三元组之间的差异度,没有进一步分析正例三元组与之衍生出来的负例三元组之间的差异度程度关系,为了加入正负例样本之间的差异度计算,对原始的式(7)进行一下的改进工作。
对于由正例三元组(h,r,t)∈△,构造的负例三元组(h′,r,t′)∈△′(h,r,t),为了计算它们之间被替换后的差异度,可以分以下两种情况考虑。
① 对于替换头实体的正负例三元组,可以计算正负例头实体之间的余弦相似度,具体的计算公式为:
(9)
式(8)中的相似度s∈[0,1],假定相似度和差异度之和恒为1,可以得到正负例头实体之间的差异度为:
d=1-s。
(10)
② 对于替换尾实体的正负例三元组与情况①相同,不再赘述;
综上所述,最终加入正负例样本的差异度的mTransH模型的成本函数为:
(11)
mTransH模型主要的改进在于对正负例三元组中的替换规则间产生的样本差异度进行了度量,保证了对头尾实体的替换关系的度量,提高mTransH模型对实体的辨识度,对知识图谱中三元组的推理能力,提高模型的知识链接推理准确率和Hits@10指标。
2 实验结果
实验结果的比对采用的数据集是公开的WN18和FB15K两个数据集[15]。WN18数据集来自于WordNet[16],它是英文词汇的知识图谱;FB15K数据集来自于Freebase[17],它是由Wikipedia的数据构建而成,基于事实的百科知识图谱。WN18和FB15K两个数据集包含的实际实体、关系和三元组的详细信息见表1。

表1 WN18和FB15K数据集的详细信息Tab.1 Details of the WN18 and FB15K data sets
知识图谱的链接预测任务主要是对实体的预测,主要集中在对头或尾实体的预测,当给定(h,r,?)时需要对尾实体进行预测,当给定(?,r,t)时需要对头实体进行预测,预测的步骤是将实体集中的每一个实体替换缺失的实体,通过计算得分函数进行评估,选取得分最小的实体作为预测的实体。
在实际的链接预测过程中,由于替换正确三元组的头/尾实体,然后计算实际的得分进行预测,如果预测得到的正确实体排在前T位,则证明预测是有效的,这种预测方式成为Hits@T,通常Hits@10在实验中比较常见[11],本文也选择了Hits@10和Hits@1作为实验的验证指标。由于替换得到的链接三元组可能真实存在于三元组中(这是由于三元组关系具有一对多、多对一和多对多特性造成的),这样会对链接预测结果产生干扰,于是通常将不做任何处理的链接预测称为“Raw”指标,将替换后的真实存在于知识图谱中的三元组数据进行剔除后的链接预测称为“Filter”指标,当“Raw”和“Filter”中的Hits@10、Hits@1指标越大的时候,表明性能越好。
实验的比对选用的是SE[15]、TransE[11]和TransH[12]3个模型进行比对,实验指标使用“Raw”和“Filter”中的Hits@10、Hits@1指标,由于在Hits@1中的“Filter”总是大于“Raw”,所以只选择Hits@1中的“Filter”指标,对于负例三元组的构造均采用伯努利分布概率策略。为了加速mTransH的收敛,使用TransE模型的实体向量表示作为初始化mTransH模型实体向量。
在WN18数据集上,实体维度和关系维度k=100,学习率τ=0.001,γ=1,C=0.062 5,采用随机梯度下降算法作为优化方法;在FB15K数据集上,在Hits@10的实验过程中,选用的实体和关系的维度k=100,学习率τ=0.001,γ=1,C=0.062 5,对于Hits@1而言,选用的实体和关系的维度k=200,学习率τ=0.01,γ=0.5,C=0.062 5,实验采用“bern”(伯努利分布)和“unif”(均匀分布)来替换正例三元组中的头尾实体,取较好的结果作为最终的结果。实验使用的服务器的配置为32核的CPU,每个核心的规格Intel(R) Xeon(R) CPU E5-2620 v4@2.10GHz,内存64 G,无需使用GPU。实验比对的结果如表2所示。
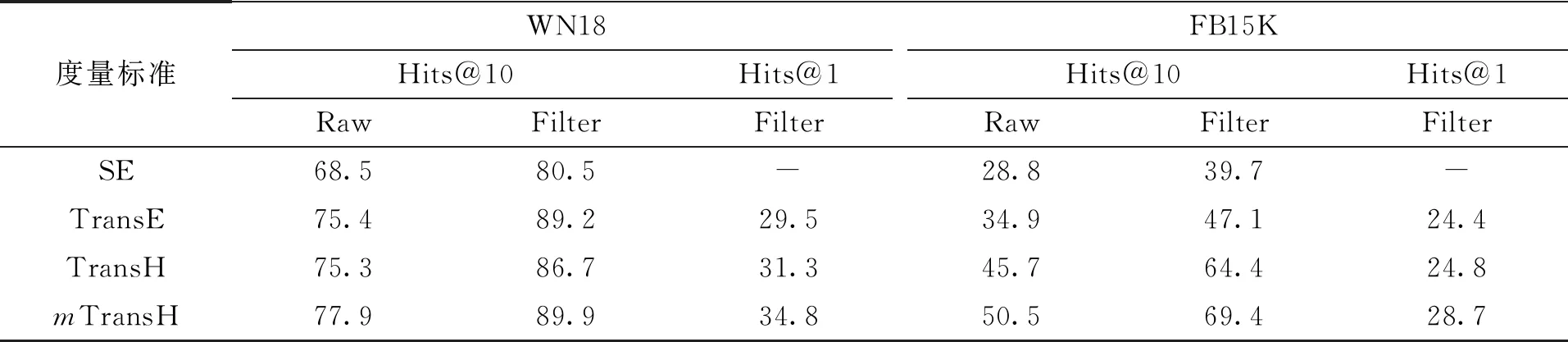
表2 链接预测实验的比对结果Tab.2 Comparison results with linking prediction experiment %
由表2的实验结果可以看出,无论是在WN18数据集,还是在FB15K数据集上,mTransH模型的Hits@10和Hits@1指标均高于SE、TransE和TransH模型,最低高出了2.6 %,最高高出了5 %,达到了较好的实验结果。
对Hits@10指标在FB15K数据集上的关系分类进行研究,得到如表3所示的实验结果。

表3 FB15K数据集的各类关系的Hit@10值Tab.3 Hit@10 value of each type of relationship in FB15K data set %
由表3的实验数据可知,mTransH模型在FB15K数据集上的头实体预测任务中,对于一对一、一对多、多对一和多对多的关系,Hits@10的预测精确度均高于SE、TransE、TransH模型,最少提升了2.9 %,最多可以提升9.8 %;在尾实体的预测任务中,mTransH模型在一对一、一对多、多对一和多对多的关系上,Hits@10的预测精确度均高于SE、TransE、TransH模型,最少提升了1.8 %,最多可以提升7.3 %。
综上所述,mTransH模型相对SE、TransE和TransH模型在知识图谱链接预测的任务中表现比较优秀,提高了链接预测的准确率,证明了mTransH算法在构造的损失函数中,采用单层神经网络的非线性操作来精确刻画实体和关系之间的语义信息,同时创新性地加入了正、负三元组之间的头/尾实体之间的差异度信息,用于校正正、负三元组样本之间的相似度,降低负例样本的错误程度,使模型能够辨别替换的实体间的相似度,提高知识链接推理的准确率。
3 总结与展望
mTransH模型在构造TransH的损失函数中,采用单层神经网络的非线性操作来精确刻画实体和关系之间的语义信息,同时创新性地加入了正、负三元组之间的头/尾实体之间的差异度信息,用于校正正、负三元组样本之间的联系,使模型能够辨别替换的实体间的相似度关系,在知识图谱的链接预测任务中,降低负例样本的错误程度,提高对正例样本的辨识度,从而提高知识推理的链接预测准确率。mTransH模型还存在着一些不足之处,由于mTransH模型是在TransH基础上改进而来,受限于TransH模型的知识表示能力,mTransH模型依旧存在头、尾实体链接预测对一对多和多对一关系敏感的弊端,具有较大的改进潜力。
