Loop Closure Detection of Visual SLAM Based on Point and Line Features
2020-05-21ChanganLiuRuiyingChengandLijuanZhao
Chang’an Liu,Ruiying Cheng and Lijuan Zhao
(School of Control and Computer Engineering,North China Electric Power University,Beijing 102206, China)
Abstract: For traditional loop closure detection algorithm, only using the vectorization of point features to build visual dictionary is likely to cause perceptual ambiguity. In addition, when scene lacks texture information, the number of point features extracted from it will be small and cannot describe the image effectively. Therefore, this paper proposes a loop closure detection algorithm which combines point and line features. To better recognize scenes with hybrid features, the building process of traditional dictionary tree is improved in the paper. The features with different flag bits were clustered separately to construct a mixed dictionary tree and word vectors that can represent the hybrid features, which can better describe structure and texture information of scene. To ensure that the similarity score between images is more reasonable, different similarity coefficients were set in different scenes, and the candidate frame with the highest similarity score was selected as the candidate closed loop. Experiments show that the point-line comprehensive feature was superior to the single feature in the structured scene and the strong texture scene, the recall rate of the proposed algorithm was higher than the state-of-the-art methods when the accuracy is 100%, and the algorithm can be applied to more diverse environments.
Keywords: loop closure detection; SLAM; visual dictionary; point and line features
1 Introduction
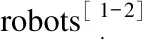
With the development of machine vision, it has become one of the most important technologies in the study of SLAM to use the information of environment acquired by vision sensors and image processing technology for place recognition and map construction.
At present, in the research of visual SLAM closed-loop detection method, cameras are used as sensors to obtain the environmental information of the scene, and the image matching method is employed to transform the visual closed-loop detection problem into sequential image matching problem. By computing the similarity between the current image and the historical image, the current image will be considered as the candidate loop for further processing when the similarity exceeds the threshold.
Currently, the algorithms about loop closure detection in visual SLAM are mainly based on point features. Cummins et al.[3]established a visual dictionary by using Scale-Invariant Feature Transform (SIFT) and Chow-Liu tree to build a scene appearance model in FAB-MAP. Galvez-López and Tardos[4]proposed DBoW and utilized FAST and BRIEF to extract key points and build binary descriptor which is used for k-means++ clustering to construct dictionary tree. Moreover, direct index and reverse index were used to speed up query and matching. In addition to point features, there are many other features, such as line feature, which can express structure information in environment and is more robust to changes of lighting, visual angle, and other environmental factors. Wang et al.[5]used the line segment extracted from ceiling images to compute the robot’s motion, and the ceiling was utilized as the positive reference to determine the robot’s global direction.Zhang et al.[6-7]constructed a closed-loop system based on line features and good results were obtained in both indoor and outdoor environments.
Point is a popular and widely used feature in visual SLAM. Point features perform well in strong texture scenes. However, when the scene lacks texture information or the blurred effect of the camera is caused by the rapid moving robot, the number of point features will be very small and inferior to line features in common man-made structured environment. Line features can reproduce structured scenes well, but its ability to represent texture information is weak. In high similar scenes like ceilings, line features are less capable of recognizing scenes. Furthermore, owing to the lack of point features, a group of meaningful visual words cannot be generated to describe images correctly, as shown in Fig.1, but they can provide additional peculiarity to find correct matching in a database. Therefore, a loop closure detection algorithm based on point and line features is proposed in this paper to receive better performance in different environments.
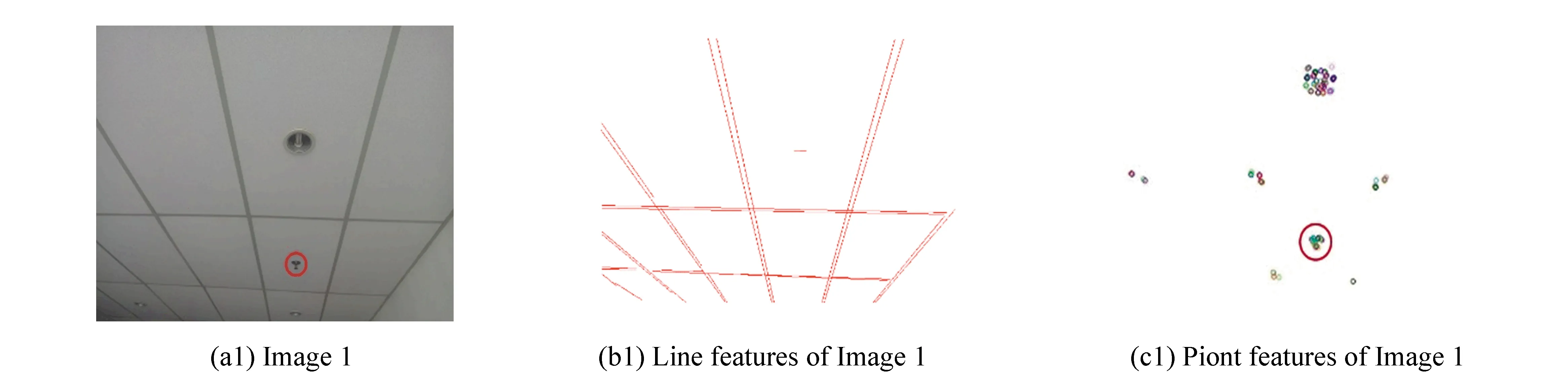

Fig.1 Extract line and point features from two high similar ceiling images captured at different locations
Here are the main contributions of this paper. Instead of building independent vocabulary trees for different feature types, a single vocabulary tree is constructed, which can combine different feature types and create mixed visual words to describe an image. In addition, different term frequency-inverted document frequency (TF-IDF) is computed for different type features. The approach based on hybrid feature can display texture and structured information of the scene at the same time, which also makes the closed-loop detection more robust in different environments.
2 Place Representations
Oriented FAST and Rotated BRIEF (ORB) point feature descriptors and Line Band Descriptor (LBD) line feature descriptors are used in this paper, both of which are 256-bit descriptors, thus the construction of visual dictionary and the process of loop detection are simplified.
2.1 Point Feature Extraction and Description
The technologies of point feature extraction, matching, and representation have become relatively mature in recent years. Point features are composed of two parts: key points and the descriptors. There are two kinds of description methods for point features: non-binary descriptor and binary descriptor. The most classical non-binary descriptor SIFT has strong robustness against illumination, scale, rotation, and other changes, but it has large computation cost and is poor in real-time. The speed of ORB extraction in the same image is two orders of magnitude faster than SIFT. ORB algorithm calculates the centroidCby using moment and determines the directionθof FAST key points, which are corner-like points and are detected by comparing the gray intensity of some pixels in a Bresenham circle of radius 3. Through drawing a square patchSbaround each FAST key point and rotating the angleθto obtain new point pairs in the neighborhood of feature points, the binary descriptor can be computed. For a key pointpin an image, its corresponding BRIEF descriptor vectorB(p) of lengthLbis

2.2 Line Segment Extraction and Description
In this paper, line segments of the input image are extracted by Line Segment Detector (LSD)[8]. The input image was scaled to 80% of the original size by Gaussian subsampling, and the total number of pixels is 64% of the original size. Through subsampling, the aliasing and quantization artifacts in the image could be alleviated and even solved. Then a 2×2 mask was utilized to calculate the gradient of each pixel, and the gradient was macroscopically sorted using pseudo-sorting. Generally, regions with high gradient amplitude have strong edges, and pixel in the middle of edge usually has the highest gradient amplitude. When the gradient is less than the threshold, pixel will be discarded and will not be used to create line-support regions (LSR), which is generated by region growing algorithm. Unused points were used as seeds to check unused pixels in their neighborhood. If the difference between the level-line direction of a pixel and the LSR angle is within the toleranceT, the pixel can be included in the LSR until no pixel can be added to LSR. Lastly, count the number of aligned point in the rectangle and compute Number of False Alarms (NFA) to verify whether the LSR can be recognized as a line. LSD has the advantages of fast speed and it needs not to change the parameters.

g'=(gT·d⊥,gT·dL)≜(g'd⊥,g'dL)T
(2)
wheregis the pixel gradient in the image coordinate system, andg' is the pixel gradient in the local coordinate system.
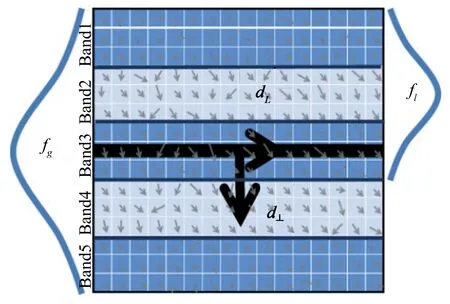
Fig.2 Diagram of LSR
Then, global Gaussian functionfgwas applied to each row of LSR. For each band, a local Gaussian functionflwas utilized to the rows of its nearest neighbor bands, which can reduce the effect of pixel gradient far from the line segment on Sdescriptors and reduce boundary effects. Based on gradients of adjacent band, each bandBjdescriptorBDjcan be computed. Connecting all the descriptors of the bands, the LBD descriptor can be obtained as follows:
LBD=(BDT1,BDT2,…,BDTm)T
(3)
The local gradients of each line in bandBjas well as their adjacent bands were summed separately, and the sum of each line was put together to form the following band description matrixBDMj:
(4)
where
(5)
whereγ=fg(k)fl(k) is the Gaussian coefficient,

(6)
In this paper, 32 pairs of vectors are extracted from LBD in a certain order, and an 8-bit binary string can be obtained by bitwise comparison. When the 32 binary strings were connected, a 256-dimensional binary vector was acquired. Similar to ORB descriptors, Hamming distance can be used to calculate the distance between LBD descriptors.
2.3 Visual Dictionary
Inspired by Ref. [11], this paper constructs a kind of visual dictionary which can integrate two different types of features, and establishes a database of mixed features. Since 32-dimensional ORB descriptors and LBD descriptors are very close in Euro-space, it is easy to cluster the two descriptors into a single visual word by mixing them together directly. Therefore, a label was set at the end of each descriptor to distinguish different feature types when describing the features. In the second layer of the dictionary tree, descriptors were classified by labels, and different types of descriptors were clustered by k-means++ method. The visual dictionary tree with hybrid line and point features is shown in Fig.3.
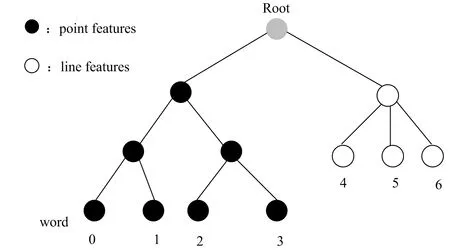
Fig.3 Visual dictionary model with hybrid features
The branch and depth of point features clustering areKp=7,Lp=5, and the line feature clustering areKl=6,Ll=5 in this paper. The degree of discrimination between different words was determined by TF-IDF to judge the weight of wordi, which can be computed by
(7)
Among them,niis the number of wordiin query image,nis the total number of words contained in the image, where different types of features correspond to differentn,Nis the sum total of images contained in the database, andNiis the quantity of images containing the wordiin the database.
The input image was divided into the nearest leaf node by calculating Hamming distance between the descriptor and the node in the visual dictionary. At last, the word vector corresponding to the image can be obtained as follows (w0towkis the word corresponding to the point features in the input image andwk+1townis the word corresponding to the line feature):
V={(w0,ω0),(w1,ω1),…(wk,ωk),…(wn,ωn)}
(8)
3 Loop Closure
3.1 Similarity Score
In order to make the result more reasonable and accurate, the similarity scores of different features of the image were calculated respectively and according to Ref. [11], certain weights were set to sum
S=μS(Va,Vb)p+(1-μ)S(Va,Vb)l
(9)
In Ref. [12], different types of features have the same importance (μ=0.5), but we think that it is necessary to adjust the parameter according to the environment. For example, for scenes with rich line features, the weight of line features is larger. Therefore, the value ofμwas set as 0.15 for the case of few extractable point features, such as the ceiling image, 0.35 for the situation of general indoor environment, and 0.5 for the situation of abundant point features in campus outdoor environment. The value ofμis a weight approximately determined by experiments.
3.2 Loop Closure Candidate and Loop Closure Threshold
After calculating the similarity scores between images, time consistency checking and continuity checking were made to eliminate the mismatches, and finally the candidate loops were determined. Since images with similar time sequence will have similar scores when querying the database, the images with similar time sequence will be divided into a group as one match. The group with the highest score will be selected for the following continuity checking. If a suitable match is detected for consecutive frames before the current frame, which can be considered that there is a key frame, then the frame with the highest score in the current image matching group is selected as the candidate loop closure.
4 Experiment and Analysis
This paper implements a loop closure detection algorithm in Windows10+VS2015. To extract and describe the point features and the line features, Opencv and related tools were utilized, noting that the descriptors are 32-dimension. Then, an improved visual dictionary with hybrid features based on DBOW3 was constructed. In the experiment of loop detection algorithm, the first 20 frames before the current frame were excluded to complete the time consistency detection. In the continuity detection, the frame image with the highest score in the group with the highest similarity score was chosen as the candidate loop closure. The value ofμwas set as 0.35 in this experiment.
Fig.4 shows the images query results in the database of different data dictionaries. In total, 440 images were collected by stereo camera from a building in the North China Electric Power University (NCEPU). The data on the left (220 images) were utilized to establish the database, and the data on the right (220 images) were used as the current input images. To verify the performance of the visual dictionary, the first 5 frames of image similarity were collected.
In Fig.4, the scattered points on the upper left corner and the lower right corner are the result of the robot moving forward for a certain distance after a circle. It can be found that the query effect of the hybrid features dictionary was better than the single point and the line features. The number of scattered points in Fig.4(a) and Fig.4(b) was more than that in Fig.4(c), and there were two faults (circle) in Fig.4(a), indicating that the query failed.
By setting different thresholds, the corresponding precision recall curves (PR curves) are drawn in Figs.5-6. Fig.5 shows the performace of three different methods in indoor dataset collected in the hall of a building in NCEPU, whereas Fig.6 presents the performace of three different methods in CityCenter dataset which is an outdoor dataset.

Fig.4 Query results from different visual dictionaries

Fig.5 PR curve of different algorithms in indoor dataset
According to Fig.5, the method based on point visual word was worse than line visual word, because the experimental scene contained abundant line features such as desk, chair, and bookcase, indicating that line feature had better discrimination than point feature.
In Fig.6, the recall of the method based on single line feature was the smallest when the precision is 100%. Unlike indoor scenes, outdoor scenes did not have rich line features. Thus, the discrimination of line visual word was not as good as point visual word.
Hence, it can be concluded that the method with hybrid point-line feature was better than others. By fusing the two features, the algorithm was improved.
The execution time of each part of the algorithms shown in Fig.5 is given in Table 1, in which the time of feature calculation and closed-loop detection in the closed-loop detection algorithm using the hybrid point-line feature was longer than that based on single features. The reason is that two features extraction of the image in the closed-loop detection will inevitably increase the corresponding computing time. Although the detection time was increased, the real-time requirements could still be fulfilled.
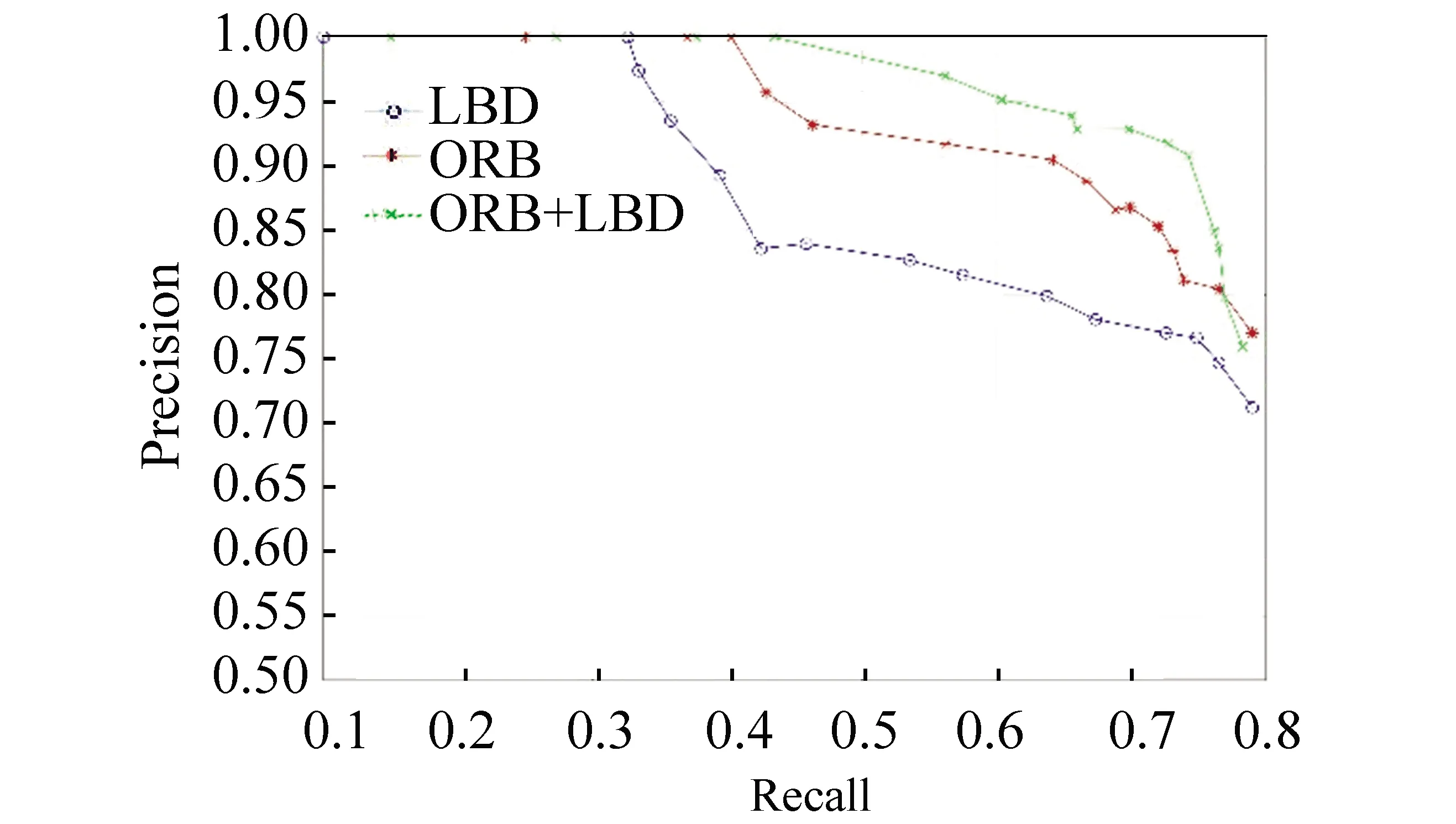
Fig.6 PR curve of different algorithms in outdoor dataset
Table 1 Average execution time with different closed-loop detection algorithms

AlgorithmsFeature processingtime(ms/image)Closed-loop detection time(ms/image)ORB13.255 15.511 3LBD56.317 63.200 8Multi71.933 68.394 8
The proposed algorithm was compared with FAB-MAP in different datasets, and then the recall rates of the two algorithms were recorded when the precision is 100% (in Table 2).
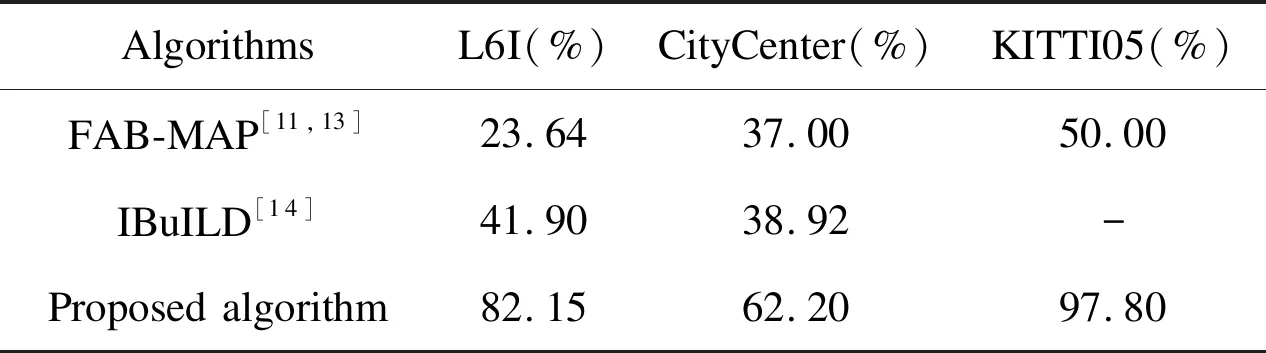
Table 2 Recall at 100% precision of two algorithms
It can be seen in Table 2 that when the precision of loop detection is 100%, the recall rate of the proposed algorithm was significantly higher than those of FAB-MAP and IBuILD in three different environments, which confirms the feasibility and superiority of the proposed algorithm.
5 Conclusions
In this paper, the proposed loop closure detection algorithm can reduce the common perceptual aliasing of BOW method, and can describe texture information as well as structure information. The similarity scores of different features between two images were calculated and summed in the proposed algorithm. Furthermore, by drawing the PR curves of three cases of single feature and hybrid features and comparing the proposed method with state-of-the-art methods in different datasets, it was found that the proposed method had better recall rates at 100% accuracy and it still satisfied the real-time requirement. Finally, experiments in different environments proved that the method based on hybrid feature had a better performance for various environments.
杂志排行

Journal of Harbin Institute of Technology(New Series)的其它文章
- Review: Energy Methods for Multiaxial Fatigue Life Prediction
- Biodegradation of Ammonia Nitrogen Using a Novel Candida sp.Strain N6 Immobilization
- Dynamics Analysis of Fractional-Order Memristive Time-Delay Chaotic System and Circuit Implementation
- An LCC-HVDC Adaptive Emergency Power Support Strategy Based on Unbalanced Power On-Line Estimation
- Aging Behavior and Creep Characteristics of CACB
- Effect of Crowding in Metro Carriages on Travelers’ Disutility:An Evidence from Guangzhou Metro