一种基于互联网语料的人才政策分析方法
2020-05-15崔焱
崔 焱
(1.中国社会科学院大学(研究生院) 人口与劳动经济研究所,北京 100028; 2.中化环境控股有限公司,北京 100070)
0 引言
人才在社会发展中发挥着重要作用。研究人才政策有助于了解各地人才政策趋势,分析人才政策与社会发展之间的关系,并考虑人才政策的得失,从而制定更加合理的人才政策。
人才政策研究需要获取大量人才政策文件,以对人才政策进行综合分析和评价[1-5]。这种研究方法的问题在于,它需要获取尽可能多的人才政策文件,并且需要大量的人工分析工作,工作量大,主观性强。为避免上述问题,大量的人才政策文献重点考虑多省份人才政策[2-6],或者研究单一省份人才政策的特点[[7-12],或者比较多个省份人才政策的差异[4-11]。
对于人才政策的研究方法,一般采用总结法[1-3],该方法需要研究人员对人才政策文件进行总结,存在分析复杂度高、主观性强的缺点;少量文献采用数学分析的研究方法[7-8],这种方法对预处理后的人才政策文件,使用统计等数学方法分析人才政策数据,这种方法客观性好,但仍需要人工对人才数据进行预处理和总结。
本文提出了一种基于互联网语料的人才政策分析方法。本方法首先使用计算机爬虫程序,获取尽可能多的发布在互联网上的人才政策文件,然后通过关键词分割,提取人才政策中的关键词,最后通过TF-IDF等技术,对人才政策的关键词进行分析。本方法尽量避免研究人员对政策文件的处理和总结,从而避免人为性倾向带来的主观性问题。本方法具有较好的计算机处理能力,可自动更新人才政策文件数据,快速输出分析结果,具有时效性高、分析地域广、客观性强的优势。
1 人才政策数据分析方法
1.1 人才政策文件获取
人才政策文件的获取方式是计算机爬虫程序。首先确定爬虫程序需要采集的数据源,数据源由人工确定。数据源为全国不同省市的人才政策网站,或者发布人才政策的网站板块,人工将这些网站或者网站板块记录下来,整理为合适的数据格式后作为数据源。然后设计爬虫程序,爬虫程序需要读取数据源,对数据源的网站或网站模块中的人才政策文件进行持续抓取和定期更新。爬虫程序使用Python语言实现,可在1小时内完成全部人才政策文件的抓取,并可根据需求定期更新。
爬虫程序除了抓取人才政策文件的标题和正文,还可记录其发布时间和发布地点。发布时间和发布地点分别可以从时间和空间维度上分析人才政策,综合使用各种维度参数可更加深入解析人才政策文件,本文主要分析人才政策文件的标题和正文。
1.2 人才政策文件处理
人才政策文件包含标题、正文、发布时间、发布地点等参数,发布时间和发布省份可以直接使用,而标题和正文则需要理解其内容含义。为了更加深入分析人才政策文件内容,需要对人才政策标题和正文进行解析。
首先通过分词工具,将人才政策文件正文切割为一个个有实际含义的词语。具体过程为,使用分词工具Jieba,对人才政策文件正文分词,分词后可以得到对应的词语及其词性。词性表示一个词语在句子中是名词、动词等,本文重点考虑名词和部分动词,其他词性的词语被排除掉。
经过词性过滤得到的词语中,仍然包含大量与人才政策无关的词语,比如“文件”“公告”,这些词语中一部分词语的出现频度非常高,对人才政策文件的分析带来很大干扰。对这些词语,可通过设置停用词在分词阶段去掉,也可以在分词完成后人工剔除,本文使用的后一种方法。
1.3 基于TF-IDF的关键词权重计算
本文使用TF-IDF(Term Frequency-Inverse Document Frequency)提取关键词。TF-IDF是信息检索中常用的关键词加权算法,是提取文本关键词的常用方法。TF-IDF算法实现简单,计算复杂度低。
顾名思义,TF-IDF是两部分概念的叠加。TF表示词频,表示词在给定文档中的出现次数,这里的文档指的是计算TF时的目标文档集合,可能是一个文档,也可能是多个文档。IDF表示逆文档频率。TF-IDF是词频TF和逆文档频率IDF的乘积。一般来说,词语在文档中的TF-IDF值越大,则词语在文档中的重要性越高。因此,计算文档中每个词的TF-IDF值,将词按照TF-IDF值从大到小排序,可得到文档的关键词。下面详细说明词频TF和逆文档频率IDF的定义及其计算过程。
计算词频TF。用TF(w, d)表示词w在文档d中出现的次数。TF(w, d)值越大,说明词w在文档d中的出现次数越高。但考虑到不同文档或文档集合的大小和总词数不同,在需要跨文档和文档集合使用TF值时,一般将其归一化,见公式(1)。本文计算单一省份人才政策文件中词的TF值时,未进行归一化,这是因为多个省份数据比较时,本文比较的是关键词的排序,而非TF-IDF值,两者排序是一致的。
(1)
计算逆文档频率IDF。用IDF(w)表示词w的逆文档频率,逆文档频率表示词在不同文档中的出现程度。词在不同文档中的出现次数越多,则该词的IDF值越低,该词在语料库中的重要性也越低。语料库为文档的语句基础,是大量文档的集合。需要注意的是,一个词反复出现时,一般认为其重要性高,这与IDF含义并不矛盾,IDF表示的是词在整个语料库而非单一文档中的重要性,如果词在语料中的不同文档中均出现,则该词被认为是一个通用词,难以凸显其在特定文档中的作用。本文计算IDF使用的语料库是爬虫程序抓取的全部人才政策文件,文件数量为9359个。逆文档频率IDF的计算公式如下:
(2)
如果一个词在不同文档中越常见,则公式(2)的分母就越大,逆文档频率IDF值就越小。为避免所有文档均不包含词w导致的分母为0,公式中给分母加1。log函数表示对得到的值取对数。计算TF-IDF。TF-IDF的计算见公式(3):
TF-IDF(w,d)=TF(w,d)*IDF(w)
(3)
由公式可知,TF-IDF与一个词在文档中的出现次数正相关,与该词在语料库不同文档中的出现次数负相关。提取人才政策文件中的关键词就是计算出文档中过滤后词的TF-IDF值,然后将词按照TF-IDF降序排列,取排序靠前的词即可。
1.4 数据分析
本文从以下角度对人才政策文件进行研究。不同省份人才政策文件数量和该省份GDP之间的关系;广东省人才政策特点;人才政策文件标题关键词详细分析,对人才政策文件的标题,提取关键词,计算TF-IDF,分析不同省份人才政策文件关键词的差异;人才政策文件内容关键词简要分析。
2 人才政策数据分析
2.1 不同省份人才政策文件数量和GDP之间的关系
计算不同省份的人才政策文件数量,结合国家统计局公布的2019年全国GDP数据,汇总得到不同省份人才政策文件数量和GDP关系表,见表1。需要说明的是,表1没有吉林、甘肃等多个省份的数据,这是因为这些省份的人才政策文件数据源未进行配置,本文后续数据分析均不涉及这些省份。
对比表1中不同省份的人才政策文件数量和2019年GDP排名的关系,得到图1关系图,横轴为省份2019年GDP排名,纵轴为GDP排名对应省份的人才政策文件数量。由图1可以看出,不同省份的人才政策文件数量和GDP排名整体呈正相关,这说明GDP越高的省份,其人才政策文件数量越多,一定程度上说明经济越发达的省份,越重视人才政策,可以推测良好且广泛的人才政策,对经济长远发展有利。需要注意的是,山东省GDP全国排名靠前,但人才政策文件数量偏少,一方面是因为配置的人才政策文件数据源存在一定程度的缺失,另一方面是因为山东省政务信息化相对GDP前几名的省份可能存在一定不足,导致发布到互联网上的人才政策文件偏少。

表1 不同省份人才政策文件数量和2019年GDP关系

图1 人才政策文件数量与2019年GDP排名关系
图1中,横轴为2019年省份GDP排名,纵轴为GDP排名对应的省份的政策文件数量。
不同省份人才政策文件数量和2019年GDP值的关系,得到图2的关系图,横轴为GDP值(单位:万亿),纵轴GDP值对应的省份的人才政策文件数量。由图2也可看出,不同省份GDP值和人才政策文件数量基本上呈现正相关。

图2 不同省份人才政策文件数量与GDP关系
综上分析,人才政策与经济发展整体呈正相关。经济越发达的省份,越需要大量人才保持其经济长久稳定发展,因此也越需要良好且广泛的人才政策来稳定人才队伍和吸引新人才。
2.2 广东省人才政策特点
广东省人才政策文件数量和2019年GDP均全国排名第一,具有良好的典型性,本节分析广东省的人才政策文件关键词特点。
分析广东省政策文件的标题关键词,人工过滤不相关的关键词后,TF-IDF值排名前20的关键词分别是就业、社会保障、高层次、技能、改革、卫生、创业、科学技术、医药、乡村、公立医院、博士后、博士、体育、医院、领军、毕业生、军人、创新、制造业。在前20个关键词中,与医疗卫生相关的词有4个,分别是卫生、医药、公立医院、医院,一定程度说明广东省较多的人才政策与医药卫生相关,对医药卫生方面的人才尤其重视。体现高技能人才的关键词有高层次、博士后、博士、领军,一定程序上说明广东省有较多的人才政策与高层次人才相关,符合广东省高科技产业发展良好的情况。
分析广东省政策文件的正文关键词,人工过滤不相关的关键词后,TF-IDF值排名前20的关键词是卫生、医院、医疗、体育、公立医院、教师、技能、中医、创业、科技、药品、社会保障、学校、健康、商务、安全、文化、农业、教育、乡村。前20个关键词中,与医疗卫生相关的词有7个,分别是卫生、医院、医疗、公立医院、中医、药品、健康,说明广东省人才政策文件内容较多内容的涉及医疗卫生方面。
2.3 人才政策文件标题关键词分析
关键词词频TF分析。对全部人才政策文件的标题进行分词,计算词频TF,人工挑选高频且与人才政策相关性较高的关键词。最终确定关键词如下(按照词频TF从高到低排序):人才、创新、创业、引进、高层次、改革、规划、科技、技术、人力资源、社会保障、经济、教育、毕业生、质量、高校、奖励、健康、人才培养、优秀、人才队伍、补贴、领军、高技能、文化、医疗、英才、高新、选拔、医药、科学、住房、大学、职业技能、资助、互联网、电子、激励、金融、电子商务、转型、升级、引进人才、优惠、基地、博士、专家、振兴、评选、海外、新型、优秀人才、科学技术、高端、博士后、科研、补助、评价、知识、高新技术、成果、优化、投资、拔尖、留学、户口、居住。
关键词TF-IDF分析。通过TF-IDF计算关键词权重,最终得到排名前15的关键词为:高层次,创业,规划,改革,引进,英才,毕业生,社会保障,人力资源,高技能,创新,人才,科技,选拔,人才队伍,关键词TF-IDF的计算过程如表2所示。排名第一的关键词是高层次,与人才政策相关性很高。关键词人才的出现次数虽然最高,但其IDF值非常低,最终导致其排名相对靠后。

表2 人才政策文件标题的前15个关键词
不同省份人才政策标题关键词对比。首先对比广东省和江苏省的人才政策标题的前10个关键词,广东省人才政策关键词TF-IDF计算过程见表3,江苏省人才政策关键词TF-IDF计算过程见表4。对比可知,高技能和高层次这两个关键词在两省的重要性都非常高,说明这两个经济发展较好的省份,均重视高技能和高层次人才,这与其产业发展密切相关。广东省的社会保障关键词排名第2,体现了广东省对人才保障政策的关注。
对比黑龙江(见表5)和广东(见表6)、江苏(见表4)的人才政策关键词,黑龙江省的创业、大学、毕业生等关键词的TF-IDF值非常高,这与广东和江苏区别明显,说明黑龙江省在高校毕业生上有较多政策,体现了其对高校毕业生的重视。

表3 广东省人才政策文件标题的前10个关键词

表4 江苏省人才政策文件标题的前10个关键词
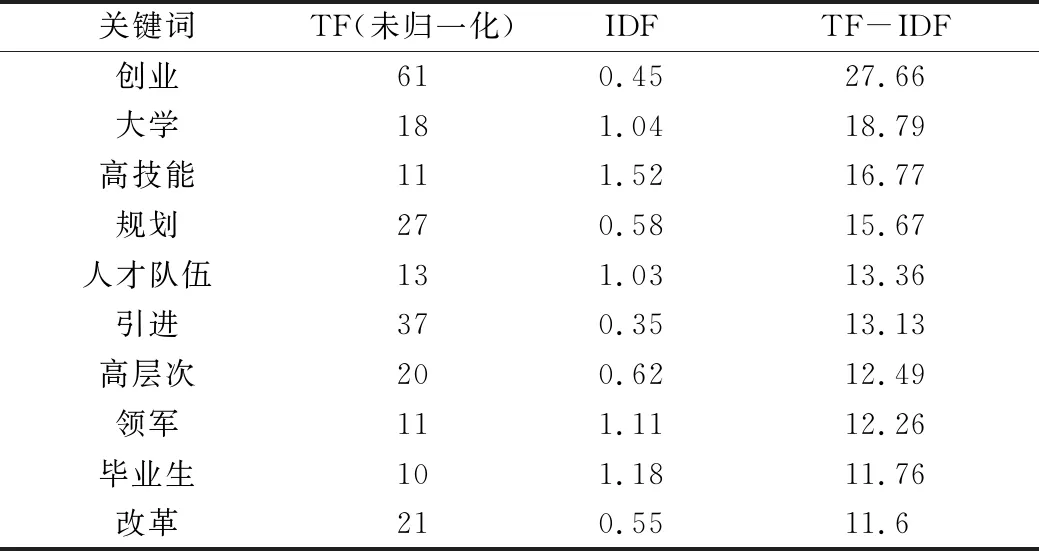
表5 黑龙江省人才政策文件标题的前10个关键词

表6 广东省人才政策文件内容的前10个关键词
整体来看,不同省份人才政策标题有明显不同,但难以直接总结其区别。
2.4 人才政策文件内容关键词简要分析
本部分简要说明不同省份人才政策文件正文的关键词。分析广东省政策文件的正文关键词,人工过滤不相关的关键词后,TF-IDF值排名前10的关键词是医疗、创业、科技、补贴、人力资源、社会保障、健康、文化、教育、改革。在前10个关键词中,与医疗卫生相关的词有2个,分别是医疗、健康,进一步说明广东省对医疗卫生人才关注度较高。与人才保障相关的关键词有3个,分别是补贴、社会保障、健康,一定程度体现了广东省在人才保障方面投入较多的政策支持。
3 总结与展望
针对人才政策研究,本文提出了一种基于互联网语料的人才政策分析方法。该方法使用计算机爬虫程序自动获取互联网上各省市人才政策文件,然后对获取到的人才政策文件的标题和正文,使用中文分词和自然语言处理技术分析其关键词,进而客观分析区域人才政策文件的主题。本文使用该方法,分析了全国人才政策的特点,详细分析了以广东省为代表多个省份的人才政策数量和特点,并比较了不同省份人才政策数量和内容上的差异。研究结果表明,不同省份人才政策与当地经济发展之间存在一定的相关性。本方法具有时效性高、分析地域广、客观性强的优点。
人才政策文件包含发布时间这一参数,发布时间可用于分析人才政策的变化,结合地域参数还可分析不同省份人才政策变迁情况,后续将进行相关研究。
