融合口碑和地理位置的竞争关系量化模型*
2020-05-13李艾鲜乔少杰元昌安
李艾鲜,乔少杰,韩 楠,元昌安,黄 萍,彭 京,周 凯
1.成都信息工程大学 网络空间安全学院,成都 610225
2.成都信息工程大学 软件工程学院,成都 610225
3.成都信息工程大学 软件自动生成与智能服务四川省重点实验室,成都 610225
4.成都信息工程大学 管理学院,成都 610103
5.南宁师范大学,南宁 530001
6.四川省公安厅,成都 610014
1 引言
识别竞争对手、量化竞争关系是帮助企业、商家保持核心竞争力的重要方法[1]。现有研究通过专利挖掘[2-3]、用户评论[4-5]挖掘等方法识别竞争对手,鲜有竞争关系量化研究。翟东伟[6]构建主题-机构模型对专利机构的主题和竞争关系进行分析。Rodriguez 等人[7]提出了一种基于图形核的度量方法识别竞争对手。陈元等人[8]从Web 用户评论中构建企业竞争情报挖掘模型获取企业产品竞争情报。聂卉等人[9]通过Word2Vec 结合依存语法分析在线评论进行领域特征词典构建和用户观点抽取。上述工作仅实现了竞争情报的挖掘和竞争对手的识别,不能反映出实体间竞争关系的强弱。Yang 等人[10]提出主题因子图模型来量化推断企业间的竞争关系,但采用半监督学习方法,其实用性有限。上述研究均未考虑地理位置对竞争关系的影响,显然存在局限。
研究动机:口碑传播已被证明对消费者的购买决策起着重要的作用[11]。通过融合消费者口碑与地理位置信息进一步改进现有竞争关系挖掘方法,提升模型的实用性、客观性和准确性。电商企业可以将本文提出的新方法应用于评论特征抽取、评论内容中的企业竞争对手识别,将竞争关系发现与量化输出相结合,克服传统的竞争关系挖掘方法不考虑地理位置信息影响的缺点。融合消费者口碑和实体空间位置两大因素,科学地量化实体间竞争关系。
2 理论基础
本文中定义的实体包括但不限于企业、商店、餐厅等。首先给出竞争关系网络的定义。
定义1(竞争关系网络)网络G=(V,E,S,L),V是实体的集合,E⊆V×V表示实体间的关系,S表示该实体所有消费者的评论,L代表实体的地理位置。
定义2(实体主题模型)实体的全部消费者评论集合θd的主题模型是单词{P(w|θd)}的多项分布。一个餐厅ei的所有消费者评论是从餐厅的主题模型θd中抽样形成的。
定义3(困惑度[12])用来度量一个概率分布或概率模型预测结果的好坏程度,定义如下所示:

其中,p(w)表示LDA(latent Dirichlet allocation)模型中任意一个词w的概率,定义为:

式(2)中,w代表词,z代表主题,d代表文档,N表示测试集中出现的所有词的数量(不排重)。p(z|d)表示从文档d抽取主题z的概率值,p(w|z)表示从主题z中抽取词w的概率值。因为LDA 是词袋模型,困惑度是语料库的极大似然估计,即所有词的概率乘积,因此对于未知分布的数据集,其困惑度的值越小,说明主题模型越好,记录该条件下LDA 主题模型取得的主题数量为K(K为最优值)。
定义4(空间相邻关系)当两个实体在地理空间中的最短路径小于或等于给定阈值ξ时,称两个实体空间相邻,用neighbor表示,定义如下:
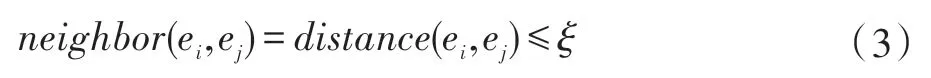
当空间中两个实体满足式(3)时,说明空间中的实体对象ei和ej相邻。
3 竞争关系量化
本文基于消费者口碑(用户评论)和地理位置信息设计了LTM(location &topical model)模型,量化实体间竞争关系,辅助实体进行商业决策。
3.1 消费者口碑主题提取
消费者口碑是由消费者评论文本构成的文档数据,LDA 模型将主题视为词汇的概率分布,文档是主题的随机混合[13]。本文通过LDA 主题模型提取实体消费者评论的主题与主题词。根据主题模型提出的主题和主题词分布,综合咨询专家意见和评价,建立“主题-特征”规则。依次对所有口碑评论进行规则匹配,统计规则匹配频率计算口碑相似度。
本文把实体i记为ei,其对应的所有消费者口碑评论视为一篇文档。假设有n个实体,那么对应n篇文档。假设有K个主题,则实体i的文本中的第j个词汇wij可以表示为:
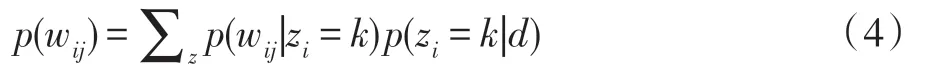
式中,d为n篇文档的集合,zi是潜在变量,代表第j个词汇标签wij取自该主题,p(wij|zi)是词汇wij属于主题zi的概率,p(zi|d)表示给定主题zi属于当前文本的概率。
主题提取先统计d中出现过的词汇(不计重)W,制作词汇表,现假设K个主题形成D个文本,以W个唯一性词汇表示,记φk=p(wij|zi=k)为主题zi下W个词汇的多项分布,其中wij是W个唯一性词汇表中的词汇。记θn=p(zi|d)为文档d在K个主题上的多项分布。于是,文档d中词汇w的概率可表示为:

LDA 模型在上作Dirichlet(α)的先验概率假设,在上同样作Dirichlet(β)的先验假设,得到LDA 模型各层参数之间依赖关系的数学表述[14]如下:
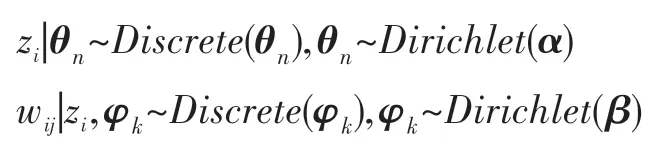
LDA 主题提取模型需要给定数据集和主题的数量K,根据定义3 采用困惑度来确定K的取值。
3.2 消费者口碑相似度量化
在消费者口碑中,竞争关系越大的实体,其消费者的评论相似度越高。某商店消费者评论出现频率最高的词汇是“好喝”“干净”“服务”,其中“好喝”是针对奶茶口味,“干净”是针对设备,“服务”是针对店铺环境的。相似评论说明:在A 商店消费的消费者,有很大可能会在与A 相似度高的B 商店消费。因此需要对消费者口碑进行相似度量化。
根据主题模型建立“主题-特征”规则。依次对n篇文档利用式(6)进行规则匹配。

“主题-特征”在本文档中出现则为匹配成功,否则为失败。以某一餐厅的评论为例,存在规则“foodnice”,则在该餐厅的所有用户口碑评论中搜索“foodnice”是否同时存在,若存在则匹配成功,score=1;反之失败,score=0 。为了得每个实体的规则匹配分数,设计打分函数Sei:

式(7)为统计匹配成功的频率,式中ei代表第i个实体用户评论数据,作为函数的输入;R代表规则数量;D代表规则数量;ni表示ei中词的数量;scored代表第i个实体匹配规则r后得到的分数。匹配完D个规则后,实体i获得一个分数score。

式(8)用于计算用户评论相似度。simij表示实体i与j的相似度。sim值越小,说明实体相似度越大。
算法1消费者口碑量化算法

算法1 的基本思想为:LDA 主题提取过程(第1行~第10 行),从参数为α的Dirichlet 分布中抽样生成第i个文档ni的主题分布θn;从参数为β的Dirichlet 分布中抽样生成第k个主题的词分布φk;对于每一个词wij及其所属主题zi,首先从多项式分布θn中抽样得到zi=p(zi|θn),然后从多项式分布φk中抽样得到wij=p(wij|zi,φk);求口碑相似度(第11 行~第15 行)。算法中的采样方法为Gibbs 采样[15]。参数说明如表1 所示。

Table 1 Parameters and description of algorithm 1表1 算法1 参数及说明
时间复杂性分析:算法1时间复杂度为O(K×N),其中K表示主题数量,N表示文档的总数。
3.3 地理位置相似度量化
本节设计了符合地理位置属性在实际生活中对竞争关系影响特点的相似度量化函数。dis是距离矩阵,disij表示餐厅i与餐厅j之间的距离。算法的核心是将具有相似距离关系的餐厅聚集到一起,并赋予它们相同的影响因子α,最终由实体距离影响力量化函数M(disij)输出实体距离影响力量化结果。
根据定义4,以存在相邻关系的实体i、j的相邻关系neighbor(ei,ej)作为聚类的初始值,使用KNN(Knearest neighbor)算法对实体的经度纬度进行聚类得到n个簇,记为C,C={C1,C2,…,Cn}。实际生活中,距离的远近将影响实竞争关系的强弱。把地理位置具有相似的点聚集到一起,同一个簇内,在地理位置属性上存在相似关系。不同的簇则相似性较弱。在互联网中,相距较远的实体也可能存在竞争关系。以美团为例,理发店A 和理发店B 相距5 km,但其主营业务一样,任然存在竞争关系。单纯地考虑距离来评价竞争关系会夸大距离对结果的影响,这显然是不合理的,因此本文引入地理位置属性影响因子α={α1,α2,…,αn},定义如下:

式中,Ci为簇i内点的数量,n表示簇的数量。α的作用包括:(1)调整距离对竞争关系的影响,强化簇内竞争关系,弱化簇间竞争关系;(2)给相似点赋相同的权重值,简化参数。
由实体距离影响力量化函数:

输出实体距离影响力量化结果,式(10)中disij表示一个二维矩阵,矩阵的行代表实体ei,矩阵的列代表实体ej,矩阵第i行第j列存放ei到ej的距离。M(disij)值越小,说明竞争关系越强。
3.4 LTM 模型
在图G=(V,E,S,L)中,矩阵E中的值表示竞争关系的强弱。本文提出竞争关系量化函数φij,融合3.1节及3.2 节消费者口碑量化结果simij、实体地理位置属性影响力量化结果M(disij),其公式为:

Eij表示实体i与实体j竞争关系归一化结果:

竞争关系量化算法参数说明如表2 所示。

Table 2 Parameters and description of algorithm 2表2 算法2 参数及说明
算法2竞争关系量化算法

算法2 工作原理:计算竞争关系量化值φij(第1行~第5 行);查找φij中的最大值(第6 行),查找φij中的最小值(第7 行);对竞争关系量化结果进行归一化处理(第8 行~第12 行)。
时间复杂性分析:通过分析算法2,可知其时间复杂度为O(N2),N表示实体数量。
4 实验结果与分析
实验使用的数据为美国肯塔基州北部的城市Louisville地区Yelp网站上的餐厅数据,包含2 375个餐厅ID 及其地理位置属性和66 156 条用户评论。实验硬件平台为:Intel®CoreTMi5-4200M CPU 2.50 GHz,操作系统平台为Windows 10。
4.1 主题提取与相似度计算
在主题提取阶段,通过多次迭代得到困惑度变化曲线,并确定最佳主题数。实验中发现输入相同主题数,困惑度会有细微的波动。因此同一主题数采用多次实验取均值得到一条稳定的困惑度曲线。
如图1 所示,当主题数量为60 时,困惑度曲线稳定收敛,说明该条件下模型对于实验数据集中的有效信息拟合较好,因此最佳的主题数取值为60。

Fig.1 Curve of perplexity图1 困惑度曲线
根据主题提取结果,经过咨询领域专家,合并相似主题后,得到如表3 所示的规则。

Table 3 Rules table of“Topic-Feature”表3“主题-特征”规则表
通过3.2 节的方法对数据集中的2 375 个餐厅进行打分,本文以其中5 家餐厅为例,结果如表4 所示。根据式(8)计算餐厅之间的相似度,矩阵的行数表示i实体,列数表示j实体,simij表示餐厅i和餐厅j的消费者口碑相似度。
4.2 竞争关系量化
以表4 所述餐厅为例根据定义4 计算餐厅i与餐厅j之间的距离,实验将阈值θ设置为1 000 m,则数据中具有neighbor关系的点有20 个。实验中采用KNN 聚类算法,使用欧氏距离作为度量函数,把地理位置属性相似的餐厅聚为一类,重复20 次,选聚类结果和neighbor关系点重合度最高的结果作为实验的聚类结果。根据聚类结果,由式(9)计算得到α值,其值是簇内的餐厅距离计算的权重,实验中簇与簇之间的α取0.02。
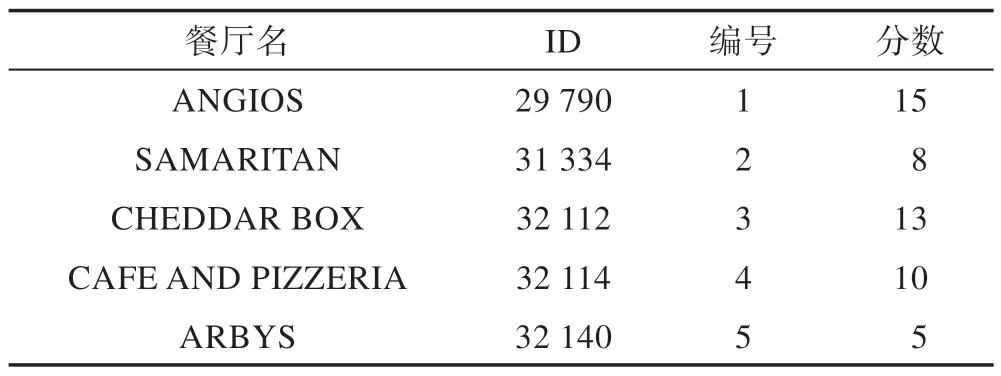
Table 4 Rating score of rules matching表4 规则匹配评分表
根据式(10)计算餐厅竞争关系地理位置属性影响力量化结果M(disij)。根据3.4 节所提方法,得到最终的餐厅间竞争关系量化结果。可视化数据集中前5 个餐厅之间的竞争关系,如图2 所示。
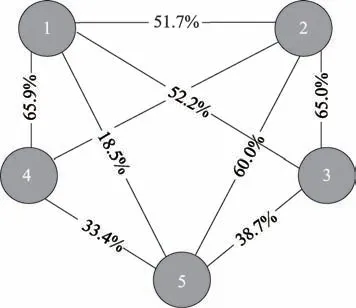
Fig.2 Visualized results of competitive relationship图2 竞争关系量化结果
使用仅考虑口碑对竞争关系影响的TM(topical model)模型进行对比实验,其结果如图3 所示。
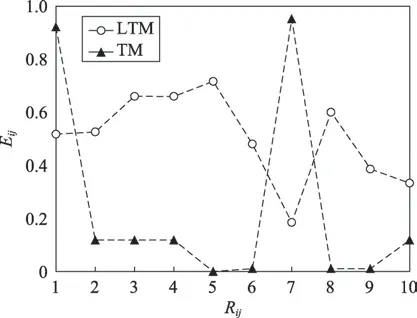
Fig.3 Comparison results of TM and LTM models图3 TM 与LTM 模型对比实验结果
图3 横轴Rij代表餐厅i与餐厅j进行比较,纵轴Eij代表餐厅i与餐厅j的竞争关系量化结果,由于篇幅限制图3 仅给出实验的前10 个量化结果。通过图3 可以发现:(1)TM 模型曲线波动很大,说明仅仅靠用户口碑评论量化竞争关系容易会出现极端情况;(2)以第5 个点和第6 个点为例,餐厅之间的竞争关系几乎为0,这显然不符合日常规律。因此仅仅靠口碑量化竞争关系是不准确的,因为同类餐厅的用户评论用词的重合度容易出现极端情况,不能很好地描述餐厅实际的竞争关系。图3 中LTM 模型在考虑地理位置属性后,对竞争关系的刻画符合实际情况。以Yelp 网站而言,不论餐厅在城市的哪个角度,都不应该出现竞争关系为0 的情况,因为消费者完全可以驱车前往,即使是相距很远的餐厅也应该存在竞争关系。综上,LTM 模型能较好地刻画餐厅之间的竞争关系。
5 结束语
本文考虑消费者口碑和实体地理位置属性,提出LTM 模型,量化表达消费者口碑和地理位置属性对实体竞争关系的影响。未来的研究工作包括:(1)进一步挖掘实体竞争关系影响因素,例如时间属性对竞争关系的影响;(2)现有竞争关系量化算法存在大量重复计算,设计新的算法降低时间复杂度,提升时间效率。
