基于序列到序列模型的代码片段推荐*
2020-05-13黄志球
闫 鑫,周 宇+,黄志球
1.南京航空航天大学 计算机科学与技术学院,南京 210016
2.南京航空航天大学 高安全系统的软件开发与验证技术工信部重点实验室,南京 210016
1 引言
在当前开源的软件生态环境下,海量代码及多种相关代码描述信息可以公开、免费地获取,而且软件数量及规模正在迅速扩大,这也就为代码复用奠定了基础。Gabel 等人[1]对超过6 000 个开源项目的约4.2 亿行代码进行了统计和研究,发现软件通常缺少唯一性(uniqueness),即程序代码经常是重复的,这也为代码复用提供了理论支撑。有效的代码复用可以提高开发者的开发效率,降低开发成本。
在实际软件开发过程中,代码推荐是一种常用的实现代码复用的方法。为了实现一个特有的代码功能,开发者通常会通过给定一个用户查询,从代码库中检索和复用已有的代码。
当前存在有很多的代码推荐方法[2-3],这些方法通常是基于信息检索技术来实现。McMillan 等人[4]提出了Portfolio。它通过关键字匹配和佩奇排名(Page-Rank)返回一个函数链。Lv 等人[5]提出了CodeHow,通过一个拓展的布尔模型把文本相似度和应用编程接口匹配相结合,来实现代码检索和推荐。
基于信息检索的代码检索和推荐方法存在的一个根本的问题在于自然语言查询的高层级的意图与代码的低层级的实现细节不匹配[6]。它们两者之间或许并没有共同的词汇、同义词、近义词和语言结构,只是存在一定的语义相关性,而基于信息检索的方法并不能解决这个问题。
针对上述问题,本文提出了一种基于序列到序列模型的代码片段推荐方法,该方法不再是直接计算自然语言查询和代码之间的相似度,而是首先训练一个自然语言查询生成模型用于实现代码到对应的自然语言查询的生成。然后,通过计算用户输入的自然语言查询与代码片段对应的生成查询之间的相似度,检索并推荐相关度高的代码片段给开发人员。自然语言查询之间的相似度不再存在语义差的问题,这也就解决了自然语言查询与代码之间语义差的问题。
本文从StackOverflow 问答网站上提取数据并构建语料库,确保数据是真实的自然语言查询和相匹配的代码片段。通过计算推荐结果的平均倒数排名(mean reciprocal rank,MRR)来验证方法的有效性。实验结果表明,基于序列到序列模型的代码推荐方法DeepCR 能有效提高代码推荐效果,优于现有研究工作,能够很好地完成代码推荐任务,为开发人员输入的自然语言查询提供精准的代码推荐。
本文工作的主要贡献在于以下两方面:
(1)利用程序静态分析技术,设计启发式规则,对Stack Overflow 问答网站上积累的庞大数据进行了清洗和筛选,构建了一个干净的代码库,用于代码片段推荐的研究工作;
(2)结合深度神经网络技术和程序静态分析技术,训练自然语言查询生成模型,为代码片段生成自然语言查询,执行生成的查询与用户输入的查询之间的相似度计算,进而提出一种基于序列到序列模型的代码片段推荐方法DeepCR,致力于解决自然语言查询与代码片段之间语义差的问题。
2 相关工作
当前,存在很多传统的基于信息检索的代码推荐方法。Ohloh、Krugle 和Sando[7]都是代码推荐引擎,可以根据自然语言查询中出现的关键字或者正则表达式来推荐代码片段。Linstead 等人[3]提出了Sourcerer。它是一个基于Lucene 的用于大规模代码库的代码推荐工具。它通过把代码的文本信息和结构信息相结合来实现代码推荐。SNIFF[8]则整合了代码片段中包含的Java APIs 的注解信息,执行与自然语言查询的相似度计算过程,进而实现代码片段的推荐。这些传统的信息检索方法存在的一个基本问题是自然语言查询的高层级的意图与代码的低层级的实现细节不匹配。
近年来,研究者也提出了一些基于深度神经网络技术的代码推荐方法。Gu 等人[9]提出了DeepCS,通过神经网络模型将代码和自然语言描述映射到高维度向量中,使得代码片段和其对应的自然语言查询具有相似的向量呈现,通过计算两者之间的余弦相似度来实现代码推荐。Yao 等人[10]提出了CoaCor。它结合强化学习相关技术训练一个代码注解模型,为代码生成注解,并结合DeepCS 中所提出方法的基本框架训练代码检索模型,综合计算两者之间的相似度得分,进而实现代码推荐任务。
3 代码推荐方法DeepCR
本章将对所提出的代码推荐方法DeepCR 进行详细介绍。DeepCR 的整体架构图如图1 所示。DeepCR 致力于根据开发人员输入的自然语言查询,推荐Java 相关的代码片段。DeepCR 由三个核心模块组成:数据准备、自然语言查询生成模型训练以及基于序列到序列模型的代码片段推荐。
3.1 数据准备
考虑到代码推荐的应用场景中开发人员输入的均为自然语言查询,且考虑到一些问答网站上的问题都是真实的自然语言查询,为了保证所收集的数据的真实性和可靠性,本文选择从Stack Overflow 上收集数据。数据准备过程包括数据收集和清洗、代码信息提取和代码标识符替换。
3.1.1 数据收集和清洗
Stack Overflow 问答网站上包含超过1 790 万个问题,考虑到本文所提出的方法DeepCR 是针对Java编程语言相关的代码推荐,因此只将标签中包含Java的问题集合作为数据候选集,问题总量超过150 万。
只做到这一步,所提取的数据候选集的质量依旧参差不齐。图2 展示了一个来自于Stack Overflow问答网站的问题示例。如图2 所示,每个用户的自然语言查询都对应着一系列的标签,以及不定数量的答案,而每个答案的主体部分则可能包含着不定数量的代码片段。
为了构建一个干净的数据集,需要针对每个自然语言查询,提取和筛选出与自然语言查询匹配的代码片段,构建高质量数据集。因此,本文利用程序静态分析技术,尤其是抽象语法树解析技术,设计启发式规则,对数据候选集进行清洗和筛选,具体体现在以下几方面。
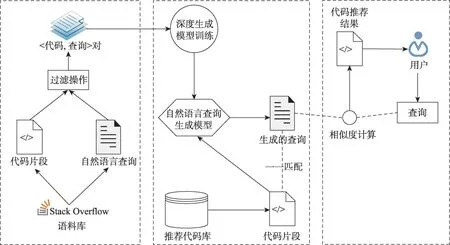
Fig.1 Overall framework of DeepCR图1 DeepCR 的整体架构
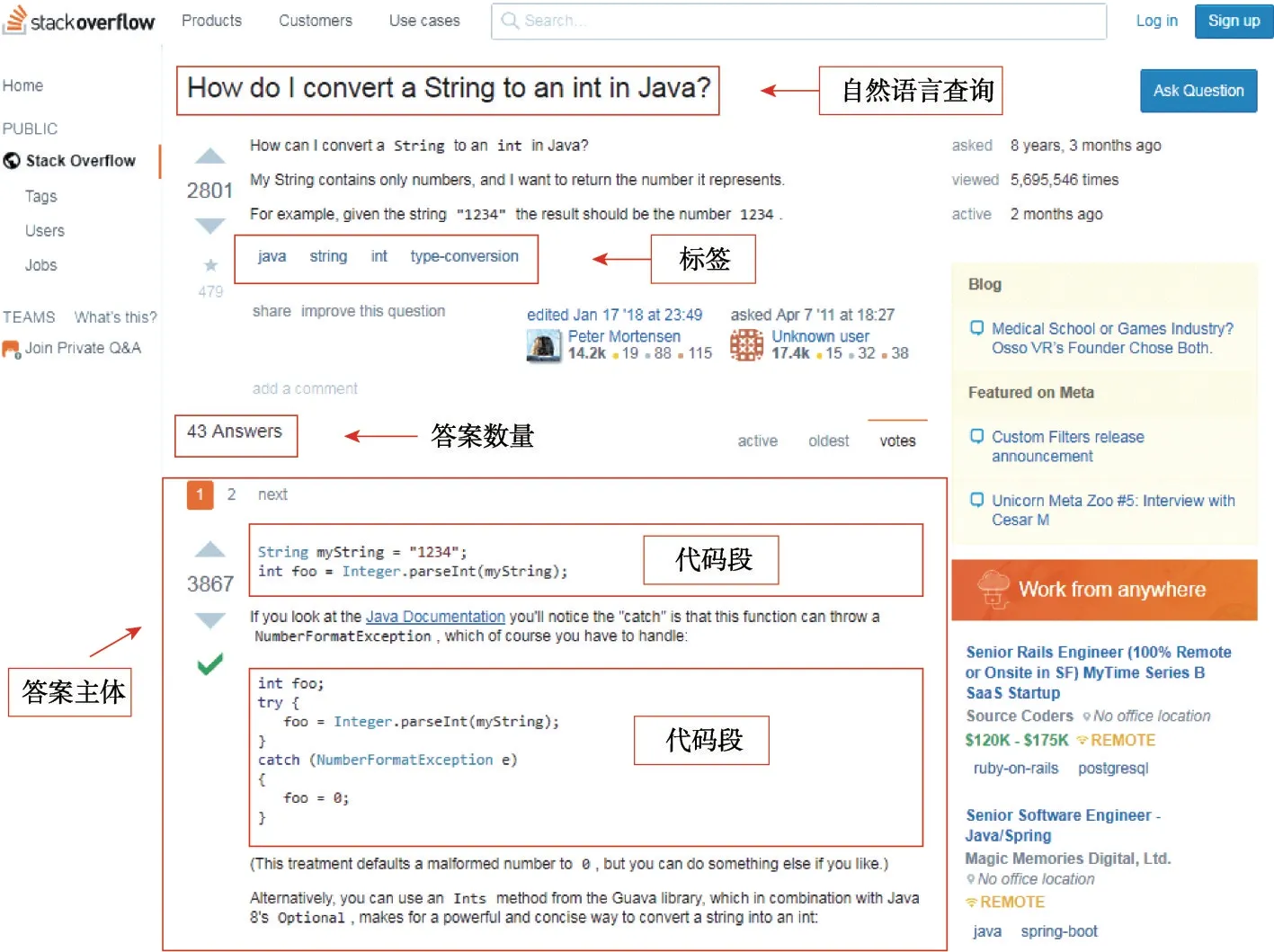
Fig.2 Example of question from Stack Overflow图2 一个来自于Stack Overflow 上的问题示例
(1)答案主体中不包含代码片段。本文的目标是做代码片段推荐,如果与自然语言查询相对应的答案中没有任何的代码片段,显而易见,此类答案不能作为数据集的一部分,则将其滤除。
(2)答案主体中的代码片段不是Java 代码。本文是针对Java 语言做代码片段推荐,不涉及其他编程语言,如Python、C++、SQL,甚至是伪代码等。因此,对不是由Java语言构成的代码片段进行过滤。
(3)答案主体中的代码片段粒度不符合要求。本文的代码推荐的最大粒度是单个Java 方法,但答案主体中包含的代码片段可能是一个完整的Java类、包含两个或更多的Java 方法、构造函数或者静态代码块等。这些代码片段虽然都是Java 代码,但与本文的代码推荐粒度不符,因此此类代码片段也会被滤除。
(4)答案主体中的代码片段包含不属于JDK(Java development kit)的方法调用。当前存在着海量的Jar包,把所有相关的Jar 包中包含的方法调用囊括到一个代码推荐方法中务必会使推荐方法的准确性和可靠性大大降低,而JDK 是Java 软件开发必不可少的软件开发工具包,且功能强大。因此,本文出于代码推荐的准确率和可靠性的考量,针对的是与JDK 相关的代码推荐,对于包含不属于JDK 的方法调用的代码片段也会被滤除。
(5)自然语言查询不是一个具体的编程任务。一个自然语言查询,由于其开放性和自由性,所涉及的可能并不是一个具体的Java 编程任务,而是询问不同点、原因等。例如,“What is the difference between an int and an Integer in Java and C#?”“Why can’t I use a try block around my super() call?”。这类自然语言查询均不涉及一个具体的编程任务,均不可作为有效数据集的一部分而存在,为此人工对数据进行了研究和总结,设计了一些启发式规则,进而实现对此类冗余数据进行过滤和清洗。
3.1.2 代码信息提取
在此步骤中,结合抽象语法树解析技术,并调用Eclipse JDT提供的大量应用编程接口(application programming interfaces,APIs)来实现代码信息的提取。
对于每一个Java 方法,对其做抽象语法树解析,提取方法名、常量、变量名、类型名、方法调用名以及内部方法声明信息。
形式上而言,给定一个Java 方法的抽象语法树,采用深度优先搜索对其做遍历操作。具体地,通过解析抽象语法树的MethodDeclaration 节点来获取方法名和内部方法声明信息;通过解析NumberLiteral、StringLiteral 和CharacterLiteral 节点来获取常量信息;通过解析SimpleType、PrimitiveType、QualifiedType 等节点来获取类型名信息;通过解析MethodInvocation等节点来获取方法调用名信息;通过解析SimpleName节点来获取变量名信息。
图3 给出了一个代码片段示例,图4 则给出了代码片段对应的抽象语法树示例。出于空间的考虑,只展示代码片段对应的抽象语法树到语句层级。
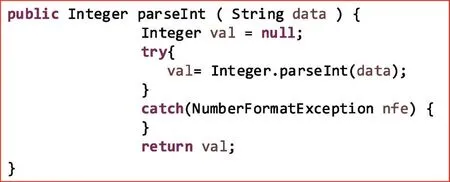
Fig.3 Example of code snippet图3 一个代码片段实例
通过调用相关API,抽象语法树中的节点可以被精确定位,并且代码信息可以轻松地获取到,并将所提取的信息与对应的代码片段形成映射,一一对应,至此代码信息提取工作完成。
3.1.3 代码标识符替换
由于标识符命名的开放性,当代码片段的量级达到一定程度时,则代码片段的词汇表的数量会很自然地超出一个合理的词汇表的大小。因此,合理的词汇表压缩方法是极其有必要的。
为了合理地对词汇表进行压缩,采用了一种标识符替换方法来把代码的词汇表大小压缩到一个合理的范围内。具体而言,利用从Java 方法中提取到的代码信息将代码片段中的一些标识符替换为一些特定的词汇。首先,计算所有代码片段中每个词汇的出现频次,并选取出现频次最高的30 000 个词汇作为代码片段的初始词汇表;其次,根据初始词汇表以及提取到的代码信息对代码片段执行标识符替换操作。标识符替换操作可以被分为6 类,具体包括方法名替换、常量替换、变量名替换、类型名替换、方法调用名替换以及内部方法声明替换。相应地,引入了一些特定的词汇作为替代词汇,标识符替换类别和引入的特定词汇如表1 所示,其中k是一个从0 开始计数的正整数。

Table 1 Categories and rules of identifier replacement表1 标识符替换类别及替换规则
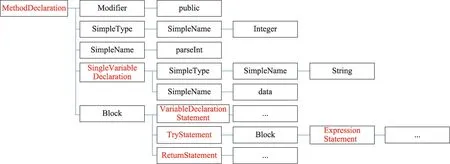
Fig.4 Example of abstract syntax tree for code snippet图4 一个代码片段的抽象语法树示例
具体而言,考虑到对每一个Java 方法而言,只存在唯一的一个方法名,因此引入一个固定的词汇METHODNAME 作为方法名的替代词汇。考虑到去区分不同的字符串常量、字符常量和数字常量意义不大,因此,分别引入特定的词汇STRINGLITERAL、CHARACTERLITERAL 和NUMBERLITERAL 来 作为字符串常量、字符常量和数字常量的替换词汇。至于其他的特定词汇都包含一个变量k,用来表示当前Java方法中出现的特定类别的第k个标识符。
举例而言,图5 展示了一个经过标识符替换操作的代码片段示例。变量vari和alist由于出现频次过低,不存在于初始词汇表中,因此执行变量名替换操作,即用SIMPLENAME_k的形式替换变量vari和alist,k为从1 开始计数的正整数。因此,vari和alist被分别替换为SIMPLENAME_1 和SIMPLENAME_2。

Fig.5 Example of identifier replacement图5 一个标识符替换示例
经过标识符替换操作后,超出初始词汇表的标识符均会被替换为表1 中引入的特定词汇。进而,所有代码片段的词汇表大小就会被压缩到一个合理的范围内。最终,用于后续自然语言查询生成模型训练的代码片段的词汇表以及数据集也会被确定,构建一个<代码,查询>对的数据集。
3.2 自然语言查询生成模型训练
在此步骤中,致力于训练一个基于序列到序列模型的自然语言查询生成模型。序列到序列模型已经被广泛应用于各种神经网络机器翻译(neural machine translation,NMT)任务[11-12]中。
大体而言,序列到序列模型可以简单地分为两个循环神经网络(recurrent neural network,RNN)结构,即一个编码器、一个解码器。编码器负责把输入序列通过非线性变化映射到一个固定维度向量中去,而解码器则是把固定维度的向量映射到相应的目标序列。当输入序列较长时,这个中间向量难以存储足够的信息,就成为序列到序列模型的一个瓶颈。因此,引入注意力机制(attention mechanism)[13]对编码器每个隐藏状态做加权处理,允许解码器随时查阅输入序列中的部分单词或片段,因此不再需要在中间向量中存储所有信息。本文选用长短期记忆网络(long short-term memory,LSTM)——循环神经网络的一种变体,作为序列到序列模型的基本神经单元,模型示意图如图6 所示。
编码器的输入对应于代码片段的向量表示。以编码器为例,输入序列是(x1,x2,…,xm),其对应的输出隐藏状态序列则为(h1,h2,…,hm),而当前隐藏状态ht的更新是根据当前输入xt以及前一隐藏状态ht-1实现,其对应的计算公式如下:

解码器则是给定上下文向量Ct以及先前预测的输出序列(y1,y2,…,yt-1)来预测下一个输出词汇yt出现的概率,最终产生输出序列(y1,y2,…,yn),计算公式如下:
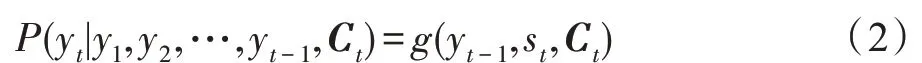
其中,st是解码器在t时刻的隐藏状态,公式如下:

Ct是根据编码层的编码器的隐藏状态作加权,计算公式如下:

其中,hk为编码层输出的隐藏状态,αtk为对应的权重,其计算公式如下:
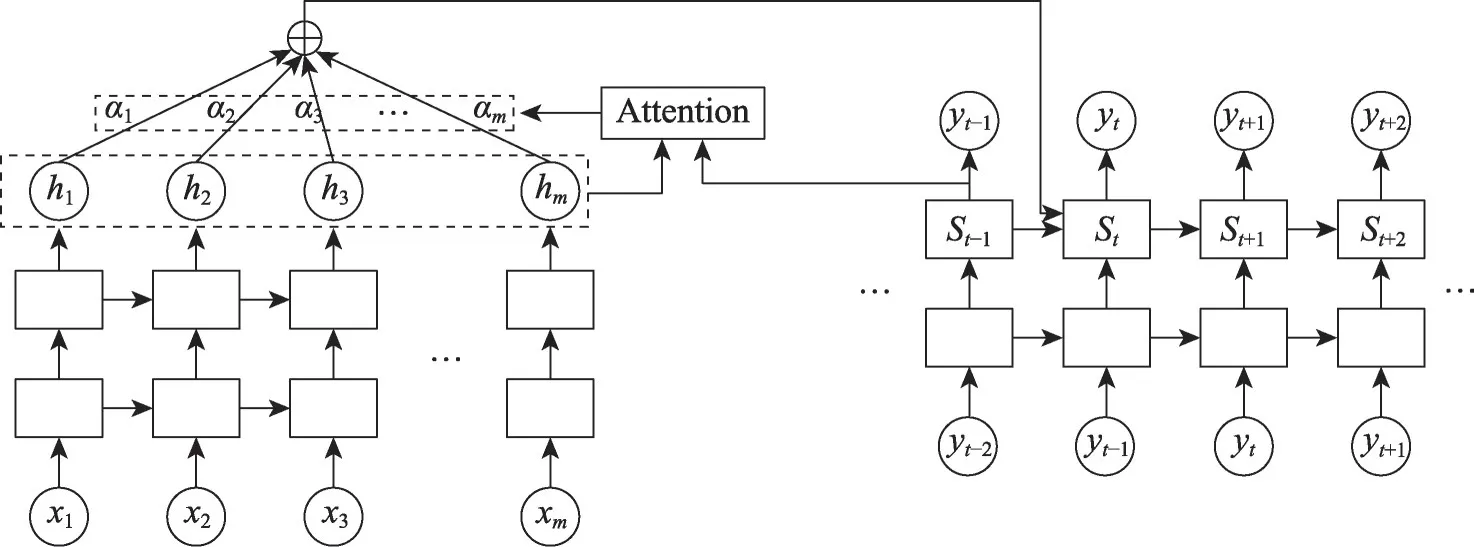
Fig.6 Seq2Seq model with attention mechanism图6 结合注意力机制的序列到序列模型

3.3 基于序列到序列模型的代码片段推荐
DeepCR 通过以下几个模块实现方法层级的代码推荐:
(1)自然语言查询生成。自然语言查询生成模型训练的目的即为对推荐代码库的代码片段生成相匹配的自然语言查询。由此,每个代码片段也就存在了一个与之匹配的由模型生成的自然语言查询。推荐代码库中的元素也就以<代码片段,生成的查询>对的形式存在。
(2)相似度计算。由于推荐代码库中每个代码片段都有了与之对应的生成的查询,因此用户查询与代码之间的相似度可以转化为计算生成的查询与用户查询之间的相似度。在计算相似度之前,结合较为流行的Stanford POS Tagger(词性标注器)[14]对生成的查询和用户查询执行小写化、停止词删除和词干提取等操作,对自然语言查询执行数据预处理操作。在此基础上,本文采用TF-IDF(term frequencyinverse document frequency)[15]来进行两者之间相似度的计算。Lucene 是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的API 库,能够做全文索引和搜寻。在Java 开发环境里Lucene 是一个成熟的免费开放源代码工具,使用Lucene 提供的TF-IDF 算法来进行相似度计算。
(3)代码片段推荐。通过上述步骤中相似度计算结果,确定相似度得分最高的生成的查询的列表。由于代码和生成的查询之间存在映射关系,则从推荐代码库中检索相对应的代码片段,并将其呈现给用户,作为代码片段推荐结果。
4 实验评估
4.1 实验设置
本文的实验平台为Intel i7-6700 3.4 GHz处理器、GeForce GTX 1070 Ti 的GPU 以 及32.0 GB RAM 的台式机,搭载Ubuntu 18.04 LTS操作系统,使用JDK1.8版本,并使用Eclipse 作为数据处理的集成开发环境,使用Python3,结合Tensorflow 框架作为自然语言查询生成模型训练和预测的运行环境。
针对自然语言查询生成模型的训练,使用随机梯度下降算法来训练和更新模型参数,LSTM 隐藏状态和词嵌入的维度均设为512,学习速率初始值设为0.99,对应的影响因子设为0.8。为避免过拟合,设置模型参数dropout的值为0.3。
4.1.1 数据准备
从Stack Overflow 官方的数据仓库下载了原始数据,解压后数据集的大小超过70 GB,与Java 相关的问题总数超过150 万。基于3.1 节所述的数据清洗操作,最终获得了48 003 条有效数据,每条数据中问题(即自然语言查询)和答案(即代码片段)一一对应。接着按照9∶1 的比例将数据划分为训练集和测试集,即训练集包含43 203 条,测试集包含4 800 条数据。按照Iyer 等人[16]的方法,从测试集中随机抽取200 条数据用来评估代码片段推荐方法的性能。
4.1.2 评估指标
采用MRR(mean reciprocal rank)[17]和Hit@K[18]来对代码推荐性能进行评估。
对用来评估代码推荐性能的数据集中的每一条数据<代码片段C,查询Q>对,把C作为有效代码片段,并从数据集中随机抽取K个与Q不匹配的代码片段作为无效代码片段。进而,给定查询Q,计算代码片段C在K+1 条候选集中的排序。按照文献[10,16]中采用的方法将K设为49。代码推荐性能则根据整个数据集D={<C1,Q1>,<C2,Q2>,…,<C|D|,Q|D|>} 上的MRR来进行评估:

其中,Ranki表示对于查询Qi,代码片段Ci的排序结果。MRR的值越高,则代码片段推荐性能越好。
还采用Hit@K来评估DeepCR 的代码片段推荐性能。Hit@K(K=1,3,5,10)的计算公式如下:

其中,Id表示对于查询Qi,代码片段Ci是否在前K个推荐结果中,如果在,Id取值为1,否则为0。
多次重复执行此实验,来确保实验结果的真实性和可靠性。
4.2 实验结果
4.2.1 基准实验
为了检测DeepCR 在代码推荐性能上的有效性,把DeepCR 与传统的信息检索方法BM25[19]和TF-IDF进行对比。BM25 和TF-IDF 是两个比较具有代表性的计算文本相似度的算法。考虑到代码和自然语言查询之间的语义差,在用传统的信息检索方法计算代码和自然语言查询之间的相似度时,对代码中的标识符做了驼峰式命名法分词、小写化、停止词去除、词干提取等操作。
4.2.2 实验结果
表2 呈现了所提及到的3 种不同的代码推荐方法以MRR 为度量指标重复执行20 次的实验结果。DeepCR 尝试训练自然语言查询生成模型为代码片段生成查询,以此来消除代码和查询之间的语义差。从表2 可以得知,DeepCR 的代码推荐性能优于TFIDF 算法和BM25 算法。具体而言,DeepCR 的MRR得分相较于TF-IDF 算法提升了0.22,相较于BM25算法提升了0.18,由此可见DeepCR 代码推荐方法的有效性。

Table 2 MRR of 3 methods for code recommendation表2 3 种不同代码推荐方法的MRR 得分
表3 呈现了所提及的3 种不同的代码推荐方法以Hit@K(K=1,3,5,10)为度量指标重复执行20 次的实验结果的平均值。从表3 可以得知,BM25 的代码推荐性能略优于TF-IDF算法,而DeepCR的Hit@K得分相较于TF-IDF 和BM25 算法均有明显提升,DeepCR 在Hit@1 的得分达到了38.25%,相较于TF-IDF 和BM25,分别提升了23.17 个百分点和19.12 个百分点,由此可见DeepCR 代码片段推荐方法的有效性。
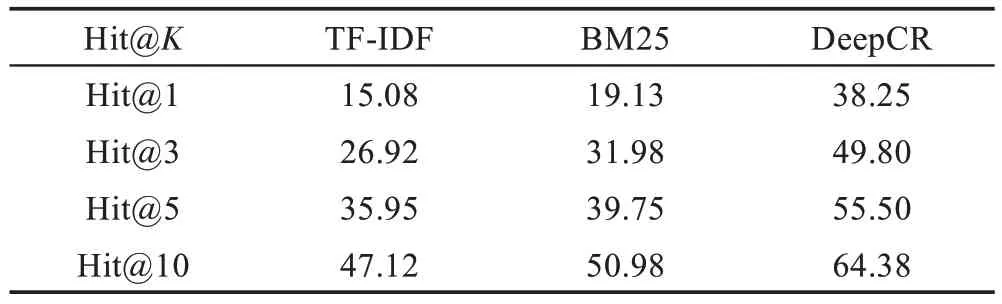
Table 3 Hit@K of 3 methods for code recommendation表3 3 种不同代码推荐方法的Hit@K 得分 %
5 有效性威胁
本文针对的是Java 相关的代码片段推荐工作,而没有拓展到其他编程语言,因此编程语言可能是一个对本文方法有效性产生威胁的一个因素。将来会结合不同编程语言各自的特点,将本文的方法扩展到其他的语言环境。
数据有效性。所提取的数据来源于Stack Overflow问答网站上的数据。由于问答网站对问题以及回答的开放性和自由性,所收集的数据集中存在大量低质量的数据,以至于对自然语言查询生成模型的训练造成威胁。鉴于此,对收集的数据做了一系列清洗和筛选操作,以保证数据质量的可靠性和有效性,尽可能减少存在于最终的数据集中的噪音。
6 结束语
本文提出了一种基于序列到序列模型的代码片段推荐方法DeepCR。该方法结合程序静态分析技术,对代码做抽象语法树解析,提取代码信息,构建训练集;运用序列到序列模型,训练自然语言查询生成模型;根据训练好的查询生成模型,对代码库的代码生成对应的查询;通过计算用户输入的自然语言查询与代码对应的生成查询之间的相似度计算得分,检索并推荐相关度高的代码片段给开发人员。DeepCR 的MRR 和Hit@K得分均明显优于传统的信息检索方法的代码推荐性能,能够有效提高代码推荐效果,为开发人员提供精准的代码片段推荐。
