军用软件测试领域的命名实体识别技术研究
2020-05-13韩鑫鑫贲可荣
韩鑫鑫,贲可荣,张 献
海军工程大学 电子工程学院,武汉 430033
1 引言
军事上,随着软件在武器装备中所占比例的增加,其质量的高低严重影响了军用装备的可靠性,软件测试作为保证软件质量的重要环节,逐渐受到军事领域专家的重视。但软件测试较为复杂,如何整合软件测试相关知识,并智能化地为部队提供软件测试辅助决策,成为了亟待解决的问题。知识图谱作为一种新兴技术,它能够将复杂、海量的数据整合到一起,通过挖掘到的关系将数据相互联系起来,有着强大的数据描述能力和丰富的语义关系。国内,Li等人[1]就通过构建API 警告知识图谱解决API(application program interface)警告问题,Xie 等人[2-3]构建了软件知识图谱辅助软件知识应用。由此可见,构建软件测试知识图谱,也是解决上述军用软件质量问题的一种有效手段。图1 和图2 展示了配置项测试知识图谱的部分本体概念和相关实体,将它们结合成一套高质量的知识体系,例如查询A 级软件配置项测试依据哪些质量特性、需要输入输出哪些文档等类似问题,相比较人工查询文档和互联网,知识图谱瞬间就能得出精准答案,大大提高了效率。实体质量的好坏直接决定了知识图谱的质量好坏,基于对实体提取的需求,本文重点研究命名实体识别技术,提取软件测试领域相关实体。

Fig.1 Configuration item testing concept map图1 配置项测试概念图
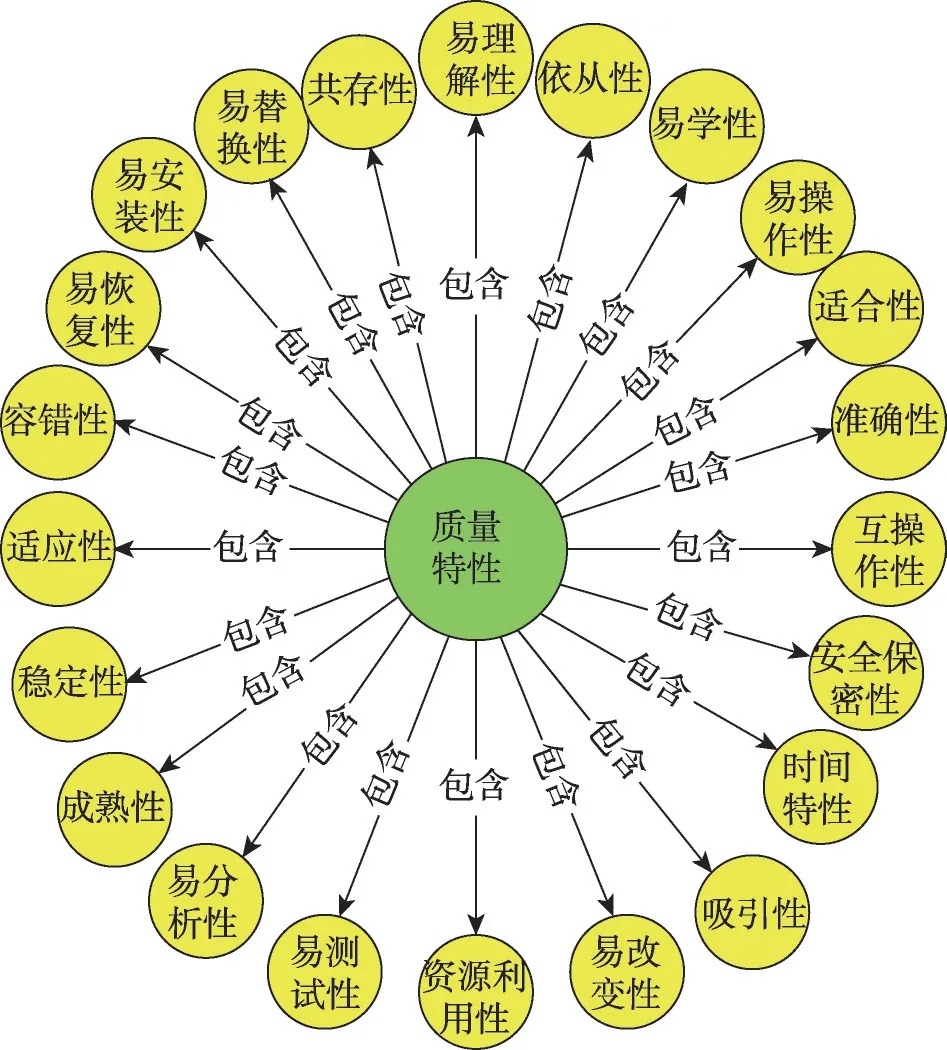
Fig.2 Quality characteristic entity map图2 质量特性实体图
命名实体识别(named entity recognition,NER)[4]是识别文本中命名实体以及将它们分类为预定义类别(例如人、位置、组织等)的任务,用作各种自然语言应用的基础,例如问答、文本摘要、机器翻译等,它作为构建知识图谱的重要阶段,关系到最终整个知识图谱的质量好坏。自然语言学习会议(Conference on Natural Language Learning,CoNLL)提出命名实体识别的主要任务是识别人名、地名、机构名和其他命名实体[5],而软件测试命名实体识别作为特定领域的命名实体识别,不同于通用领域,实体识别对象及方法都会有很大区别,在研究时遇到了以下问题:
(1)前人没有做过类似工作,软件测试的本体、实体、属性等概念没有统一标准,缺少数据集;
(2)识别过程中,传统深度学习的字符级特征提取方法还有待提高,没有完全利用字与词之间的关系,且实际上每个字对于词的特征贡献都不一样,但普通方法都未进行处理,导致整个识别方法在本领域的准确率不是很高。
本文主要针对构建知识图谱的命名实体识别阶段展开深入研究,并做出如下主要贡献:
(1)考虑到目前尚无针对军用软件测试领域命名实体识别以及知识图谱的研究,本文对该方向进行了学习和探讨,自行收集和整理了软件测试相关知识的数据集,确立实体类型分类,并进行了标注。
(2)本文在前人研究的基础上,提出了一个CWA-BiLSTM-CRF(character and word attention-bidirectional long short term memory-conditional random field)识别框架,该框架通过字词融合训练来提取字符级特征,并加入注意力机制衡量字符贡献语义的权重,能够充分利用语义信息,提取出更好的字符级特征。经实验表明,识别效果优于原始方法。
2 相关工作
早期的实体识别方法一般采用基于词典和规则的方法,最具代表性的就是Collins 等人[6]提出的DLCoTrain 方法,对三种基本类别的分类准确率超过了91%;国内军事上,冯蕴天等人[7]则是用词典和规则对识别结果进行校正,但这些方法都需要太多人工干预进行规则构造,且移植性较差。后来许多学者开始关注基于机器学习的实体识别方法,常用的机器学习方法有条件随机场(conditional random fields,CRF)[8]、隐马尔科夫模型(hidden Markov model,HMM)[9]、支持向量机(support vector machine,SVM)[10]、决策树(decision tree,DT)[11]、最大熵(maximum entropy,ME)[12]等,其中条件随机场是主流的选择,它将文本标注变为序列标注问题,但是传统机器学习方法比较依赖特征工程,此时深度学习强大的学习和自我调整能力就逐渐受到人们的欢迎。
国外对于深度学习的命名实体识别研究已经较为成熟,Kuru 等人[13]将句子分割成字,通过双向长短期记忆网络(bi-directional long short term memory,BiLSTM)+CRF 的组合解码出每个字的标签概率,实现命名实体识别,但该方法没有考虑词级信息。字词联合识别方法是近几年研究较热的方向,Aguilar[14]、Ma 等人[15]用卷积神经网络(convolutional neural network,CNN)提取字符级特征,Liu等人[16]用BiLSTM 提取字符级特征,然后都对词向量进行预训练,将两者连接后通过BiLSTM+CRF 的组合模型识别出实体;Peters 等人[17]则是先将词向量经过语言模型进行预训练,然后用深度学习模型进行识别,实验证明有较好效果;Minh[18]在识别模型中加入词语形状特征、布朗集群特征等,也取得了一定的效果;Lample等人[19]除了使用BiLSTM+CRF 的组合,还提出了基于转换方法的模型,对四种语言进行检验,效果良好。国内医学领域,Dong 等人[20]用CNN 作为分类器进行电子病历命名实体的识别,取得不错的结果。军事领域方面,王学锋等人[21]立足于BiLSTM+CRF 的组合模型,对句子中的单个字进行标签解码,识别军事实体;朱佳晖等人[22]则是结合词性和字符级特征,通过深度神经网络对军事命名实体进行识别,效果较传统方法都有较大提升。
综合几种方法进行比较,字词结合的深度学习命名实体识别方法较为流行,效果普遍较好,但是该方法还存在着字符级特征提取不完全的情况,为此需对前人的方法进行改进。接下来,本文将分别介绍改进的CWA-BiLSTM-CRF 识别框架、具体的识别步骤以及对于实验结果的分析。
3 CWA-BiLSTM-CRF 识别框架
本文提出了一个CWA-BiLSTM-CRF 识别框架用于解决命名实体识别问题,体现出了良好的识别效果。该框架主要由两部分组成:一是改进的字符级特征提取方法;二是BiLSTM+CRF 实体识别模型。下面分别对两部分的模型进行介绍。
3.1 改进的字符级特征提取方法
本文对提取字符级特征的传统方法进行改进,提取过程如图3 所示。过程共分为四步,下面详细介绍这四个步骤。
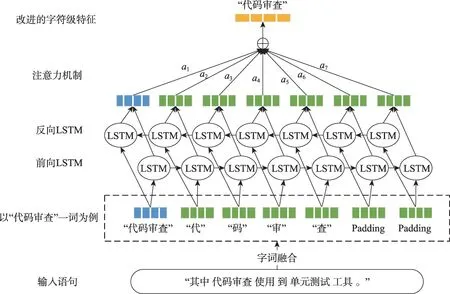
Fig.3 Improved character level feature extraction method图3 改进的字符级特征提取方法
输入层:对于输入的所有文本,首先通过word2id词典(字词融合词典的构造方法下一章将予以说明)获取其字和词的id,再将文本转换为id 的矩阵作为输入。
字词向量构造层:接收到id 的矩阵输入,通过查询id2vector 词典(字词融合词典的构造方法下一章将予以说明)获取每个字词的向量表示。此步骤中,字和词的向量都已经过预训练,词的向量表示为word=(word1,word2,…,wordm),字的向量表示为char=(char1,char2,…,charn)。相比较传统方法,经过预训练的字向量预测效果更好。一般字符级特征提取只针对词内的字符进行特征提取,但这会损失词内字和词语本身最原始的联系。本方法则是将词向量添加在字向量序列之前,字向量序列后空白的位置用零向量Padding补齐,直至序列长度填满为固定值,得到字词融合向量feature=(wordi,chari1,chari2,…,charin,Padding),其中charin表示第i个词的第n个字向量。字词的融合训练,可以提取到最原始的字符级特征,不会损失字和词之间的初始联系。
BiLSTM 层:BiLSTM 包含了一个前向和后向的长短期记忆网络(long short term memory,LSTM),能够获取丰富的语义特征,解决长距离的语义信息丢失问题,并且很好地弥补了LSTM 只能单向获取语义特征的缺陷。LSTM 通过输入门、遗忘门和输出门来控制信息的取舍。
Ιt表示输入门,Ft表示遗忘门,Ot表示输出门,每个句子的分布式表示为x=[x1,x2,…,xn],xt表示t时刻的输入,ht表示t时刻的输出,Ct表示t时刻细胞单元的状态,w和b分别表示隐藏层权值和偏置,σ表示sigmoid函数,最后输出h可由式(1)计算得到。
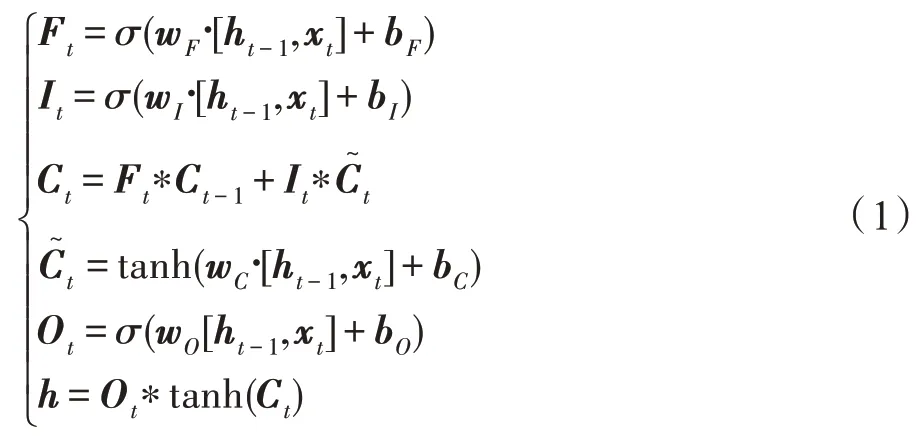
BiLSTM 则是将两个反向的LSTM 组合在一起,将每个时刻的前后LSTM 输出值进行拼接,作为此时刻的状态输出值。有正向LSTM 的输出),反向LSTM 的输出),将两者进行拼接,输出结果hi=。
注意力机制层:每个字对于词的语义贡献是不一样的,但以往字符级特征提取方法都忽略了这一点。本文方法通过注意力机制[23-24],计算BiLSTM 最终隐藏状态与输出结果的余弦值,衡量不同字对特征的重要性,能够使提取的字符级特征更加准确。有最终隐藏状态ht,输出结果,αi表示第i个字的输出权重,则改进的字符级特征h,可由式(2)计算得到。最终得到的字符级特征,将会作为第二部分BiLSTM+CRF 实体识别模型的部分特征输入。
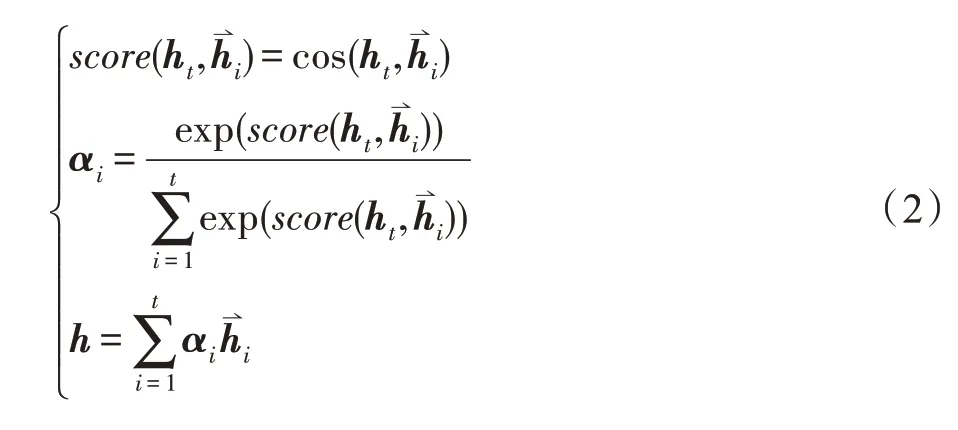
3.2 BiLSTM+CRF 实体识别模型
针对软件测试领域命名实体的特点,本文构建了基于BiLSTM 和CRF 的命名实体识别模型,识别过程如图4所示。模型共分为四层,下面进行详细介绍。
输入层:对于输入的所有文本,首先通过word2id词典获取其字和词的id,并根据固定的截断值将句子长度进行截断,再将文本转换为id 的矩阵作为输入。
特征矩阵构造层:接收到id 的矩阵输入,通过查询id2vector 词典,获取每个词的向量表示x=[x1,x2,…,xn],再连接词性向量m=[m1,m2,…,mn],与之前提取的字符级特征h=[h1,h2,…,hn]前后拼接,组成词嵌入向量w=(x,m,h),以矩阵的形式输入给下一层深度神经网络。
BiLSTM 层:不同于字符级特征提取方法里的BiLSTM 层,本层在拼接完两个反向LSTM 层的结果之后,根据隐藏层单元数目及标签数目,设置输出权值wh和偏置bh,最终结果可由式(3)计算得到。

其中,hi为两个反向LSTM 层的拼接结果。最后将g的最后一维变换为标签数目,得到每个标签的概率分布。但是此概率分布直接用作最后的识别结果是不合理的,会导致标签输出的组合序列不正确,因此需要添加一个CRF 层来解决这个问题。
CRF输出层:CRF层可以作为BiLSTM 的 解 码层,来解决上层结果中不合理的序列问题。与BiLSTM 连接的CRF 层,主要学习的是标签之间的状态转移矩阵,通过BiLSTM 层的输出矩阵(EmissionScore)和状态转移矩阵(TransitionScore)进行运算,解码出每个标签的最终概率,在条件x的前提下,概率P(y|x)可由式(4)计算得到。
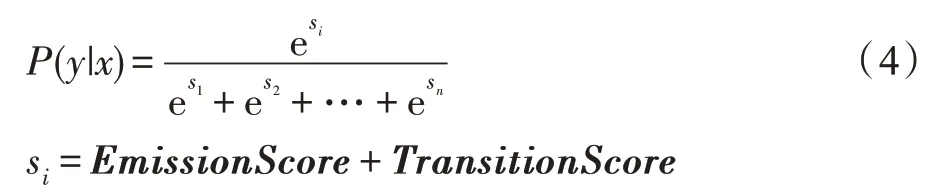
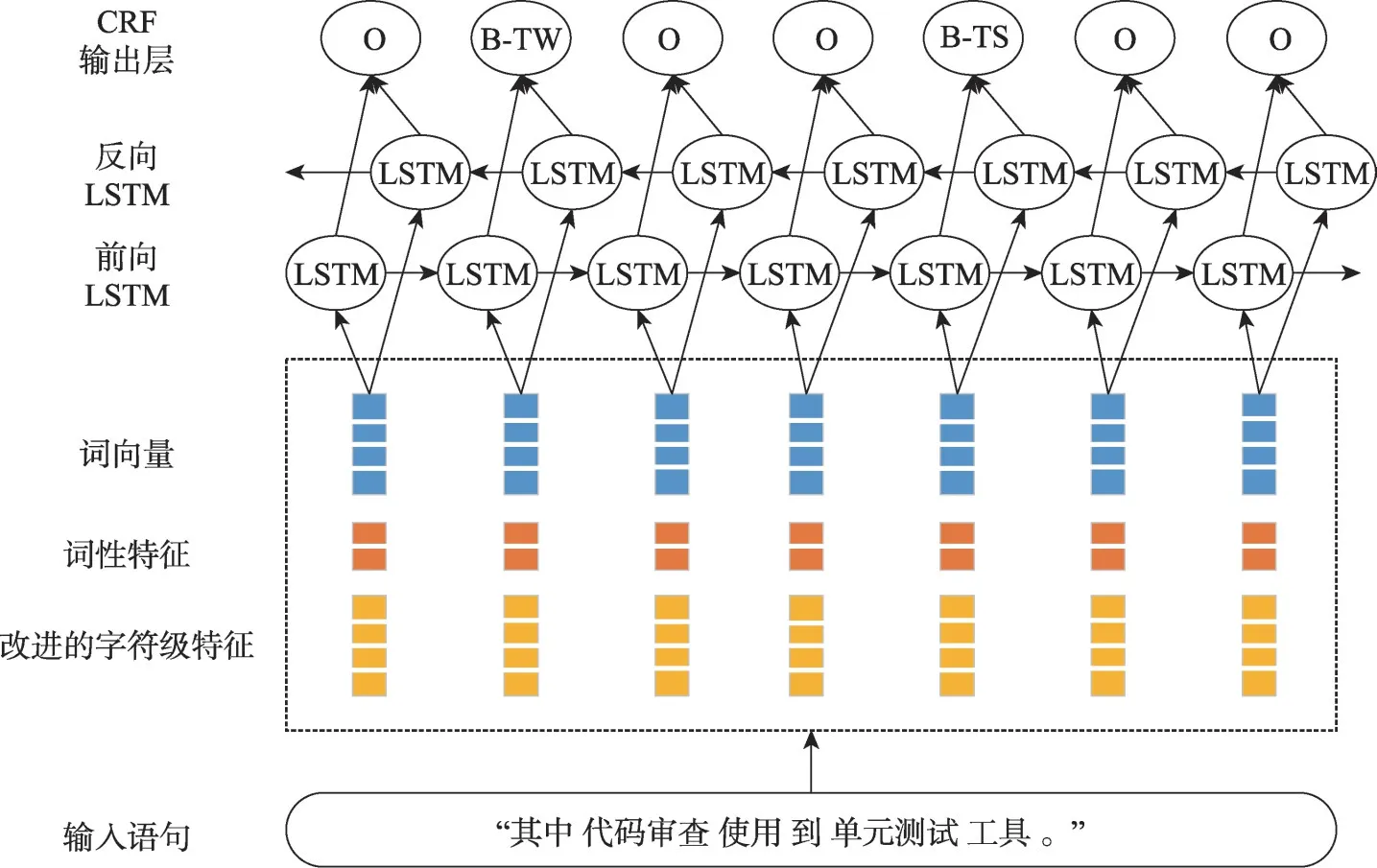
Fig.4 BiLSTM+CRF entity recognition model图4 BiLSTM+CRF 实体识别模型
4 识别方法步骤
4.1 确立和获取军用软件测试命名实体
根据软件测试的需要以及与软件测试领域专家的商讨,初步确立了十种常用实体类型,不同实体类型下又分有不同属性和内容,类型名称、代号和样例如表1 所示。这十类实体通过国军标、海军装备细则以及互联网三种来源进行获取,每个实体都有一个来源属性,根据该属性区分实体是从哪里获取,在运用知识图谱进行知识问答时,可以按照来源属性调整实体推荐的优先级,例如面向海军软件,则可以优先推荐来源于海军装备细则的实体。本文所有实体均是先从国军标和海军装备细则相关文档内获取,保证规范性和权威性。
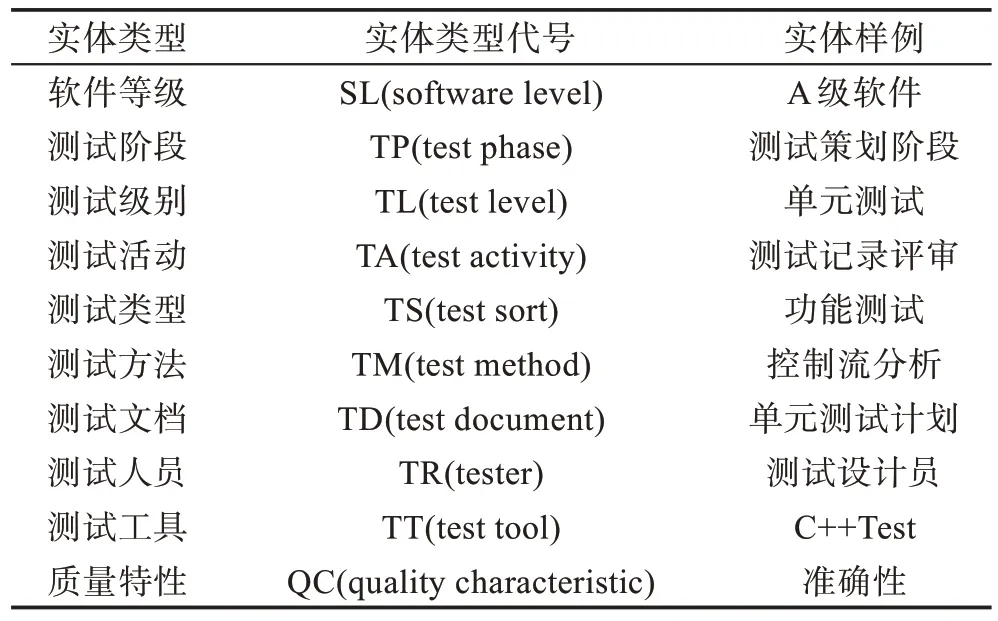
Table 1 Entity type表1 实体类型
现代互联网上资源丰富,部队装备软件越来越趋向于使用开源代码,开源软件出现的频率越来越高,其测试标准不可避免地会与民用软件测试标准接轨。在这样的环境下,软件测试知识图谱不能只关注于军用测试标准,而应将民用测试标准的部分也作为知识图谱的补充内容,做到更加全面。因此,除了国军标和海军装备细则相关文档,还需从互联网关于软件测试的知识中提取出对应实体进行补充。
由于软件测试领域现在还没有相关的开源数据集,所有训练文本语料均是自行获得和整理,因此命名实体需要进行人工标注。本文采用简单高效的BIO 标注方式对实体进行标注,B-前缀为开头的标注表示实体的第一个单词,I-前缀为开头的标注表示实体的中间及结尾部分,O 表示非实体。以测试类型为例,B-TS 表示测试类型实体的开始,I-TS 表示测试类型实体的中间及结尾。在标注完成之后,对数据集中的命名实体进行分析,统计得到标注的实体总数达到5 132 个,其中以测试类型、测试文档、测试工具、测试方法四类实体的标注数量居多。
4.2 构建字词融合词典
本文首先对字和词进行预训练,构建字词融合词典,经实验证明使用效果优于单一的词典。本文识别框架使用的字词融合词典共有三个,分别是id2word 词典、word2id 词典和id2vector 词典,每个词典在深度学习模型里均会用到。
获取到原始文本语料之后,通过结巴(jieba)分词工具,将语料进行分词、分字以及词性标注。本文使用word2vec[25]对分词和分字后的语料进行预训练,生成初始字向量和词向量,向量维数一般在100~200 之间。预训练后,对每个词和字进行编号,生成唯一的id,若存在字和词是一致的情况,则选择语义更为丰富的词向量进行id 编号。将对应的字词和id 存入id2word 和word2id 词典,id2word 词典 可以通过id 查询到字词,word2id 词典可以通过字词查询到id。最后将每个字词的id 和对应的字词向量存入id2vector词典,该词典可以通过id 查询出对应的字词向量。
4.3 命名实体识别
在上述准备步骤完成之后,将已分好词的文本及已标注的文本作为命名实体识别模型的输入,开始命名实体识别过程。
第一步,将分词文本输入给第一层改进的字符级特征提取模型,模型会自动识别词语内的单字,并通过融合词典将文本转换为可识别的字词向量,交由BiLSTM 网络训练出改进的字符级特征。
第二步,将词向量、词性向量和改进的字符级特征首尾拼接成词嵌入向量,作为第二层BiLSTM+CRF 模型的输入,模型最终会分配给每个实体类别一个分数,通过分数高低判断该词语属于哪种实体类别。
整个过程采用批处理的方式,批处理方式能够提高训练效率,缩短训练时间,但批处理的规模不能过大,否则会导致模型学习效果不佳。另外,为防止过拟合现象的发生,本文在模型训练过程中加入了Dropout[26]机制,该机制已证明能够有效解决过拟合问题,提高了模型识别的效果。
5 实验与结果分析
5.1 实验数据
本文提取实体的数据源由三部分组成:一是与软件测试相关的国军标系列标准;二是海军装备细则;三是互联网权威测试网站中的相关文章。经过内容筛选之后,具体如表2 所示。文本总计95 000 字内容,共标注52 982 个词或字,其中实体标注5 132个,非实体标注37 143 个。文本以txt 的格式进行存储,去除无意义的符号,其余正常符号予以保留。
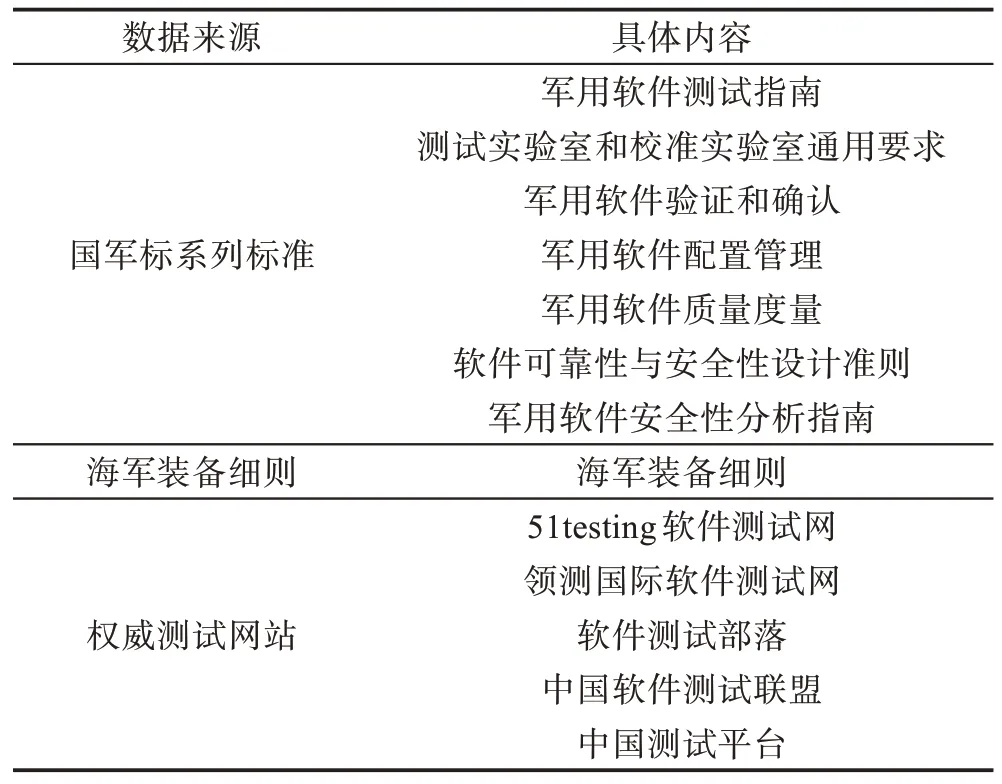
Table 2 Entity data source表2 实体数据来源
5.2 实验环境和评价指标
本文的硬件实验环境包括:Intel®CoreTMi7-7700HQ CPU 2.80 GHz,RAM 8.00 GB,Windows 10操作系统,NVIDIA GTX1060 6G GDDR5 独立显卡。软件实验环境包括:Python 3.6.4,beautifulsoup4 4.6.3,tensorflow 1.5.0,jieba 0.39,gensim 3.6.0,Anaconda3(64-bit)。其中beautifulsoup4 工具用于网络文本爬取,jieba工具用于文本分词。
准确率、召回率和F1 值通常用来评价命名实体识别效果,F1 值能够体现整体测试效果,因此本文主要以F1 值为主要评价指标,可由式(5)计算得到。实验中,对命名实体的边界和类型全部判断正确,才算成功识别出一个实体。

其中,TP(true positive)表示被正确地划分为正例的个数,FP(false positive)表示被错误地划分为正例的个数,FN(false negative)表示被错误地划分为负例的个数。
5.3 结果分析
本文主要做了两部分的实验:实验1 是探究迭代次数和批处理次数对于本文提出方法的影响,并依此确立这两个参数;实验2 是将本文提出方法与其他常用的字词联合识别方法进行比较,验证识别效果。两个实验均采用五折交叉验证法进行验证。
实验1 的结果如图5 所示。由图可知,当批处理次数为10 时,其整体效果为最优。而当批处理次数不变时,F1 值随着迭代次数的增加而升高,到达一定次数时,F1 值会到达一个最大值,而后缓慢变小趋于稳定。由于在迭代次数为50 的时候,本文改进方法有最优F1 值为88.93%,因此根据结果,本文将批处理次数设置为10,迭代次数设置为50,此时的识别效果是最好的。

Fig.5 Effect of iteration and batch number on improved method图5 迭代和批处理次数对本文改进方法的影响
实验2 所有识别模型的命名实体识别阶段均是采用BiLSTM+CRF 的组合,区别在于字符级特征提取阶段所采用的方法,目前常用的字符级特征提取网络为循环神经网络(recurrent neural network,RNN)、CNN 和BiLSTM 网络,因此选取这三种网络作为对比方法。方法1 是用普通RNN 网络提取字符级特征;方法2 是用CNN 网络提取字符级特征;方法3 是用BiLSTM 网络提取字符级特征;方法4 是采用本文改进的字符级特征提取方法。四种方法的参数保持一致:迭代次数设为50,批处理次数设为10,字、词向量设为150 维,学习速率设为0.001,隐藏层单元数目设为250,dropout参数设为0.5,结果对比如表3 所示。
从实验结果中可以看出,普通RNN 提取字符级特征的效果最差,F1 值只有80.73%。BiLSTM 的召回率高于CNN,但准确率低于CNN,两者的总体效果相差不多。而在使用本文方法后,与CNN 相比,准确率和召回率都有提升,尤其是召回率提高了3.5 个百分点;与BiLSTM 相比,准确率和召回率也都有提升,尤其是准确率提高了3.88 个百分点。以上结果说明本文提出的CWA-BiLSTM-CRF 框架能够更好地提取字符级特征,获取字词语义关系,准确率和召回率较其他主流方法有提升,并具有最优F1值为88.93%,适用于软件测试领域的命名实体识别,符合军用软件准确性的严格要求,有较好的识别能力。

Table 3 Evaluation results of four methods表3 四种方法的评估结果 %
6 总结与展望
本文主要研究了面向军用软件测试领域的命名实体识别任务,考虑到目前尚无针对该领域命名实体识别以及知识图谱的研究,本文首次尝试对该方向进行了学习和探讨,构建了用于命名实体识别的软件测试知识数据集,并在前人研究的基础之上提出了一种改进的识别框架(CWA-BiLSTM-CRF)。该框架充分融合了字词以及上下文之间的语义联系,能挖掘出更具代表性的词嵌入特征。实验分别对RNN、CNN、BiLSTM 以及本文改进的字符级特征提取方法进行了对比,改进后的方法得出的准确率、召回率和F1 值有较大提升,能够用于软件测试领域的命名实体识别任务。
命名实体识别是构建知识图谱的重要步骤,本文最终目的是完成军用软件测试知识图谱,构建智能问答系统,辅助解决软件质量问题。下一阶段主要研究内容包括拓宽实体类型,挖掘实体关系,并对语义推理展开深入研究,完成知识图谱的构建。
