基于双重数据增强策略的音频分类方法
2020-05-12张晓龙
周 迅,张晓龙
(1.武汉科技大学计算机科学与技术学院,湖北 武汉,430065;2.武汉科技大学大数据科学与工程研究院,湖北 武汉,430065;3.武汉科技大学智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉,430065)
声音在人类接收的信息中占有很大比重。随着科技的发展,使用数字格式的音频信息量急剧增加,计算机听觉技术也应运而生,并且有着越来越广泛的应用领域,如环境辨识[1]、音频监控系统[2]、机器人控制[3]、生物识别、听力辅助装置、智能家居[4]等。
音频分类属于计算机听觉技术的重要组成部分,而音频特征提取对提高分类精度至关重要,表征效果不佳的音频特征将直接导致后续分类精度降低。传统的音频特征提取方法比较多,如梅尔频率倒谱系数(MFCC)[5-6]、矩阵分解[7-8]、字典学习以及基于小波变换的特征提取[9]等方法。
近年来,深度学习相关技术取得较大进展,研究者尝试使用神经网络对传统音频特征进行计算以得到音频的高层特征[10-11],这些高层特征的表达能力往往更强,可以为后续的分类工作提供帮助。但神经网络训练过程对于数据量的要求比较高,过少的数据难以达到令人满意的拟合效果,特别是对于一些样本数较少但标签类别数量较大的数据集,其最终识别精度可能很差,此时可以采用数据增强的方法对数据量进行扩充。常用的音频数据增强方法包括音频旋转、调音、变调、加噪等,这些方法在一定程度上可以提高分类精度,但对于原始数据量过少、类别数过多的数据集,还需要更加有效的数据增强方法。
为此,本文提出一种基于双重数据增强策略的音频分类方法,其在传统的音频数据增强之后再次进行谱图数据增强,以增加数据的多样性,提高特征提取模型的泛化能力,并对最终分类精度产生积极影响。双重数据增强策略总体上可分为三步:一是对完成预处理的音频数据采用传统方法进行数据增强;二是将第一次增强后的数据转化为语谱图;三是对得到的语谱图使用随机均值替换方法进行谱图增强,即第二次数据增强。双重数据增强后还需进行卷积神经网络和随机森林分类器[12-13]两个训练过程,以完成整个音频分类流程。
1 方法介绍
本文方法大体可分为4个步骤,分别为数据预处理、数据增强、获取高层特征和分类器训练,框架结构如图1所示,其核心内容为双重数据增强(Double Data Augmentation,DDA)、神经网络模型(Inception_Resnet_V2)训练、随机森林(Random Forest,RF)分类器训练,故命名为DDA-IRRF。
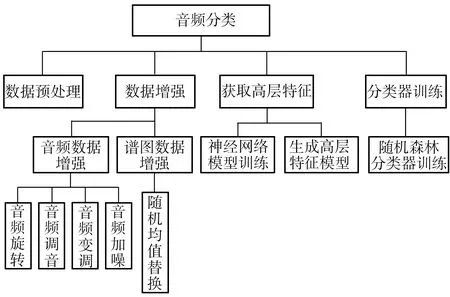
图1 DDA-IRRF方法的框架结构
1.1 语谱图
在DDA-IRRF方法中,音频数据经过了两次特征提取,第一次提取到的音频特征形式为语谱图二维数据[14]。语谱图的横轴为时间轴、纵轴为频率轴,坐标点的灰度值表示单位时间与单位频率内的声音强度。语谱图的生成需要经过预加重、分帧、加窗、短时傅里叶变换、梅尔滤波、取对数等一系列过程。
处理音频信号时需要平稳的信号段,但原始音频信号无法满足该条件。可以进行分帧处理,在每一帧上认为音频信号是平稳的。分帧后,帧的首尾连接处会出现不连贯的问题,需要对每一帧进行加窗处理,如式(1)所示:
Y(n)=X(n)W(n)
(1)
式中:Y为处理后的信号;X为源信号;W为窗函数;n为每帧采样点数。
式(1)在频域上的形式为:
(2)
可选的窗函数比较多,本文采用汉宁窗,其属于升余弦窗,在保证频率分辨率较高的同时频谱泄漏较少,窗函数如式(3)所示:
(3)
式中:M为窗函数长度。
为了同时保有音频在时域和频域上的特征,在分帧加窗后需要进行短时傅里叶变换,变换公式为:
(4)
式中:STFT(k)表示短时傅里叶变换的离散形式;k=0,1,2,…,M-1。
1.2 双重数据增强
1.2.1 第一次数据增强
在数据预处理之后即可进行第一次数据增强。这里采用一般的音频增强方法,即对原始音频数据集使用旋转、调音、变调、加噪4种方法产生更多新的数据,完成后音频数据量为原来的8倍。具体操作如下:
(1)音频旋转:将音频文件中30%靠后的数据截取至音频文件的首部进行拼接,生成一组新数据;
(2)音频调音:将音频数据的音量分别增大为原来的1.5倍和减小为原来的0.7倍,生成两组新数据;
(3)音频变调:通过改变频率将音频数据的音调增大为原来的2倍和减小为原来的0.5倍,生成两组新数据;
(4)音频加噪:在音频数据中加入随机噪音数据,重复两次生成两组新数据。
1.2.2 第二次数据增强
对第一次增强后的音频数据进行频谱分析,包括分帧、加窗、傅里叶变换、梅尔滤波、取对数运算,得到音频文件对应的语谱图。在此过程中,帧长设为 25 ms,帧移设为10 ms,梅尔谱带的个数设为76。经过转化,采样率为44 100 Hz的5 s时长音频会得到498×76大小的语谱图,4 s时长音频会得到398×76大小的语谱图。
将音频数据转化为语谱图数据后,进行第二次数据增强。本文使用随机均值替换法产生新的语谱图数据,实现数据增强,完成后数据量为第一次数据增强后的4倍。具体操作步骤如下:
(1)随机选取行列:通过随机方式选取每个语谱图中30%的行与30%的列;
(2)均值替换:计算每个语谱图中二维数据的平均值,用均值替换掉随机选取的行列数据,可得到新的语谱图数据;
(3)数据保存:对每个语谱图重复3次步骤(1)和(2)的操作,得到3组新的语谱图数据,加入到原数据集中,即完成第二次数据增强。
语谱图数据增强效果如图2所示。图中黑色区域只代表原图被屏蔽替换的区域,其具体的灰度值为该语谱图的平均值,为便于观察,该图展示的仅为实验中真实语谱图的局部区域。
1.3 卷积神经网络模型
得到双重增强的二维数据集后,需要使用卷积神经网络对其进行二次特征提取,才能得到表达能力更强的音频高层特征。
卷积神经网络属于前馈神经网络,在提取特征上具有很好的表现,能够挖掘出数据的内在结构规律。本文使用Google研究团队推出的卷积神经网络模型Inception_Resnet_V2(见图3)[15]来完成音频高层特征的提取工作。其中,Stem模块采用多次卷积操作与两次池化操作,是进入Inception结构的预处理过程,可以防止瓶颈问题。Inception_resnet模块则主要完成特征维度上的提取工作,引入的残差结构可有效防止梯度下降问题。Inception_resnet模块后面对应的Reduction模块采用了并行结构,主要作用仍是防止瓶颈问题。Inception_Resnet_V2模型的最后一层采用的是Softmax分类器。

图2 语谱图数据增强
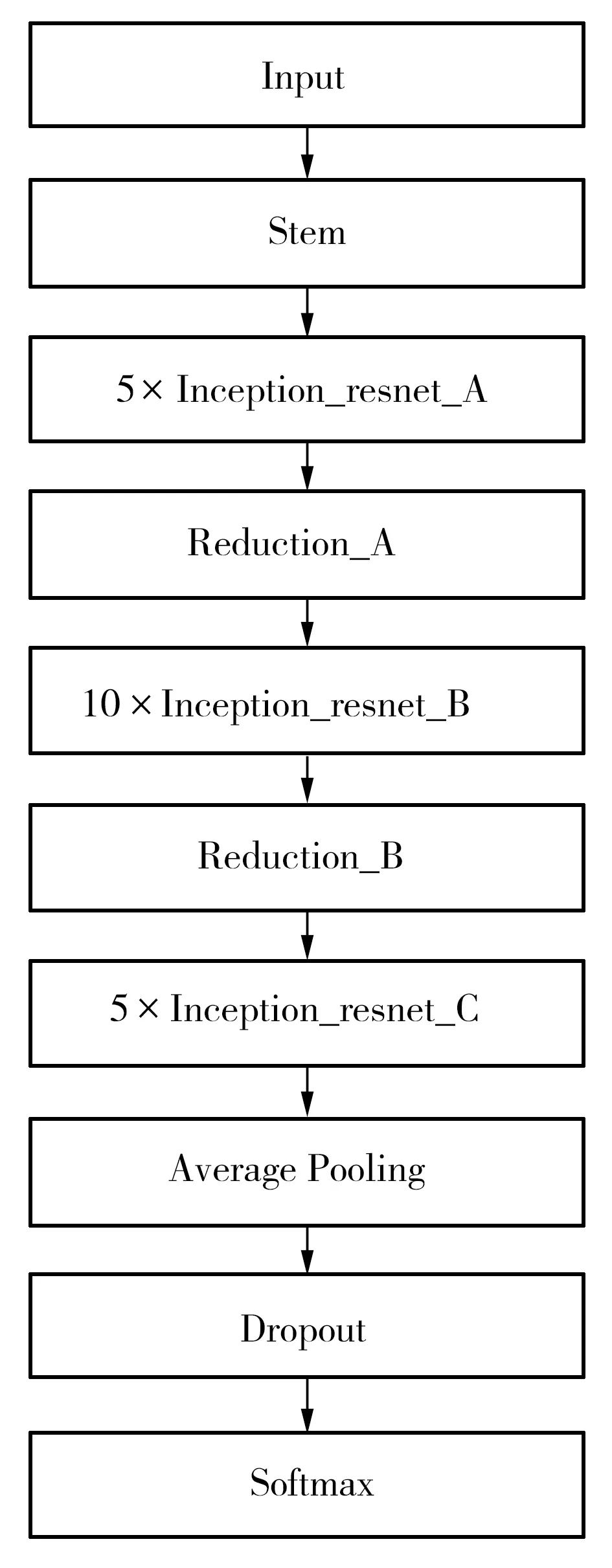
图3 Inception_Resnet_V2模型结构
1.4 随机森林分类器
在提取到音频高层特征后,采用随机森林分类器替换Softmax完成最后的分类预测。这是因为,神经网络模型提取到的音频高层特征的维度较高,随机森林算法在处理高维度数据时表现很好,不用单独进行特征选择。另外,本文方法有较多参数,容易导致算法产生过拟合现象,而随机森林在对抗过拟合方面具有很大优势。
1.5 DDA-IRRF方法流程
DDA-IRRF方法的基本流程如图4所示(不包括前期对数据的预处理工作)。输入为训练数据集与数据集标签;音频数据集分别经过音频增强和谱图增强,音频增强后的数据量变为原始数据的8倍,谱图增强后数据量再次提升,最终的数据量变为原始数据的32倍。然后,将增强数据及数据标签输入到Inception_Resnet_V2模型(去除Softmax层)进行训练,得到音频高层特征提取模型,将提取到的高层特征与原始标签输入到随机森林模型进行训练,得到随机森林分类器并完成分类任务。

图4 DDA-IRRF方法流程
2 实验
2.1 数据集
实验过程涉及3个数据集,均为wav文件格式的单声道音频数据,分别为常用的ESC-50、UrbanSound8K数据集及实验室自采数据集。
实验前需要对数据集进行预处理,其中首先要对实验室自采数据集进行分段,将每个数据文件按照5 s时长进行分割,为避免无效数据,舍弃最后的多余数据,而其他两个数据集均为已完成分段的数据。
3个数据集经过预处理后的基本情况如表1所示。ESC-50为环境声音数据集,根据发声物大致可分为5个大类,分别为自然环境声、动物发声、人类发声、家庭常见声以及城市常见声,又可以具体细分为50个不同种类,其中每个种类包括40个音频文件,每个音频文件时长为5 s,总计有2000个wav文件;UrbanSound8K为城市环境声音数据集,包括10个不同种类,总计有8732个 wav文件,与ESC-50数据集不同的是每个音频文件时长为4 s;实验室自采数据集包含8个人的语音数据,每人有12个时长为5 s的音频文件,总计96个样本。将数据集打乱后进行随机划分,得到训练集与测试集,其中训练集进行双重增强,测试集直接计算其语谱图二维数据,留待分类模型训练完毕后进行算法测试。

表1 实验数据集
2.2 特征提取
首先训练Inception_Resnet_V2卷积神经网络模型用于高层特征提取。由于数据量较大,为避免计算机内存不足,提前完成数据预处理与数据增强工作,实验过程中,batch_size设置为64进行批量化输入。训练迭代次数为60,初始学习率为0.001,为了保证训练效率与训练效果,采用学习率递减方法,每经过一次迭代,将学习率调整为当前学习率的0.96倍。
然后选择不同的输入数据进行训练,得到多个神经网络模型。各组输入数据分别为:①未进行数据增强的ESC-50和UrbanSound8K训练集;②仅进行音频数据增强的ESC-50和UrbanSound8K训练集;③双重数据增强的ESC-50和UrbanSound8K训练集。
完成模型训练后,去掉模型最后的Softmax层,取相邻的Global Average Pooling 2D层的输出作为提取到的音频高层特征,保存为文件。
实验室自采数据集只有96个音频文件,数据过少,不便于进行神经网络模型训练。将自采数据集输入到用双重增强ESC-50数据集训练得到的神经网络模型中,保存得到的音频高层特征。
2.3 音频分类
将各个数据集通过Inception_Resnet_V2得到的音频高层特征及原始标签输入到随机森林分类器进行训练,均采用40棵决策树。训练好后对相应的测试数据集进行分类,统计分类精确度。
2.4 实验结果分析
表2为不用随机森林分类器,而采用Inception_Resnet_V2模型默认的Softmax分类器的实验结果。表3为采用随机森林分类器替换Softmax分类器的实验结果。
表2 神经网络模型的分类精度
Table 2 Classification accuracies by neural network model
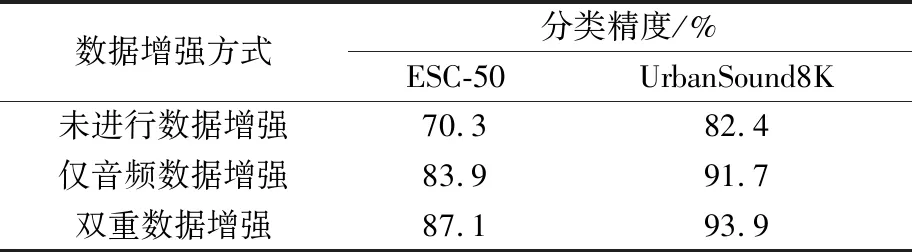
数据增强方式分类精度/%ESC-50UrbanSound8K未进行数据增强70.382.4仅音频数据增强83.991.7双重数据增强87.193.9
表3 神经网络模型+随机森林分类器的分类精度
Table 3 Classification accuracies by neural network model and RF classifier
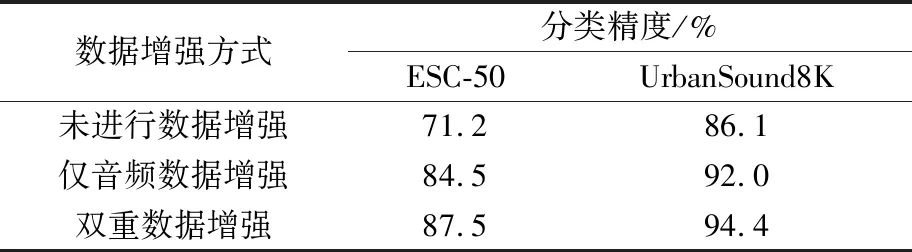
数据增强方式分类精度/%ESC-50UrbanSound8K未进行数据增强71.286.1仅音频数据增强84.592.0双重数据增强87.594.4
对比表2和表3可知,采用随机森林分类器替换Softmax层后,各组数据的分类精度均得到不同程度的提升,体现了随机森林在处理高维特征和避免过拟合方面的优越性。
同时,由表3可见,使用音频数据增强可将ESC-50数据集的分类精度提升13.3个百分点,将UrbanSound8K数据集的分类精度提升5.9个百分点;若采用双重数据增强策略,可以在音频数据增强的基础上进一步将ESC-50数据集的分类精度提升3个百分点,将UrbanSound8K数据集的分类精度提升2.4个百分点。上述结果表明,单纯的音频数据增强方法可提升音频分类精度,而双重数据增强策略的分类精度提升效果更佳,且对于样本量较小的数据集,其效果更明显。
本文方法与其他几种方法在ESC-50与UrbanSound8K数据集上的实验结果对比如表4所示。这两个数据集在音频识别研究中比较常用,从文献查阅情况来看,ESC-50数据集的当前最高分类精度为86.5%,是Sailor等[10]使用FBEs+ConvRBM-BANK方法完成的,UrbanSound8K数据集的当前最高分类精度为93%,是Boddapai等[11]使用GoogleNet神经网络模型完成的。本文方法在 ESC-50 数据集上的平均分类精度为87.5%,最高精度可以达到89%,在UrbanSound8K数据集上的平均精度为 94.4%,最高精度可达到96.2%,这表明双重数据增强策略、Inception_Resnet_V2模型、随机森林分类器三者相结合的音频分类方法能有效提高分类精度。
表4 不同方法的分类精度对比
Table 4 Comparison of classification accuracies by different methods

来源方法分类精度/%ESC-50UrbanSound8k文献[10]FBEs+ConvRBM-BANK86.5—文献[11]GoogleNet7393文献[11]AlexNet6592文献[16]EnvNet-v284.978.3文献[17]CNN83.5—本文DDA-IRRF87.594.4
实验室自采数据集由于数据过少无法训练神经网络模型,但通过ESC-50数据集训练好的模型可直接采集到音频高层特征,再将高层特征输入到随机森林分类器进行训练,最终在测试集上也能达到91.7%的分类精度,分类预测结果的混淆矩阵如表5所示。这表明通过ESC-50数据集训练得到的高层特征提取模型在其他音频数据集上也具有很好的分类效果,即采用双重数据增强策略训练得到的神经网络模型的泛化能力很强。
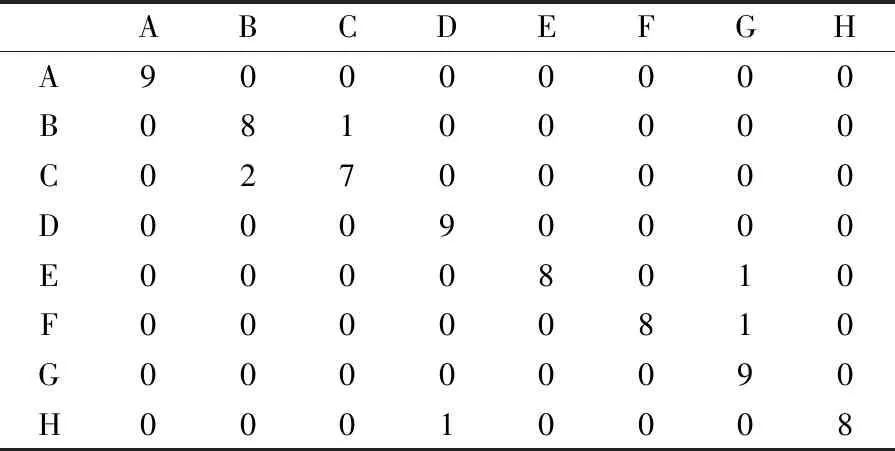
表5 混淆矩阵
3 结语
本文提出了一种基于双重数据增强策略的音频分类方法。以数据增强为突破口,先后使用一般的音频数据增强方法和基于随机均值替换的谱图增强方法,克服了语谱图无法使用传统数据增强方法的弊端,提高了数据的多样性。在双重数据增强后采用Inception_Resnet_V2神经网络模型可提取到表达能力更强的音频数据高层特征,最后使用随机森林分类器替换Inception_Resnet_V2模型的Softmax层,完成音频分类任务。在多个数据集上的实验结果证明该方法可有效提升音频分类精度,并且训练出的特征提取模型具有很好的泛化能力。
