基于概念图谱与BiGRU-Att模型的突发事件演化关系抽取
2020-05-12顾进广
余 蓓,刘 宇,顾进广
(1.武汉科技大学计算机科学与技术学院,湖北 武汉,430065;2.武汉科技大学智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉,430065;3.武汉科技大学大数据科学与工程研究院,湖北 武汉,430065)
鉴于突发事件的不确定性和破坏性,国家急需建立与突发事件和应急响应相关的知识库,从而能更全面地了解突发事件,普及应急响应知识,提高应急响应速度[1-2]。抽取突发事件演化关系是构建突发事件知识库的重要一环,其主要任务是抽取突发事件描述文本中致灾因子、承灾载体和影响因子之间的关系[3]。下面是几个突发事件的描述文本示例:
例1唐山大地震后,大雨滂沱,人员伤亡严重。
例2由于震前当地政府和群众采取了积极防震抗震的措施,从而大大减轻了损失。
在例1中,存在{〈地震,伤亡,直接因果关系〉,〈大雨,伤亡,促进关系〉,〈地震,大雨,无关系〉,…}等演化关系对;在例2中,存在{〈措施,损失,抑制关系〉,…}等演化关系对。
抽取突发事件演化关系对于防灾救灾有着重要的意义,但目前的研究主要关注于句子本身的信息,即仅利用深度学习方法对句子自身的特征进行学习,而忽视了突发事件的背景知识。然而,人类在识别语句中的实体关系时,不仅仅根据句子本身的信息做出判断,还会结合实体自身的背景知识(如实体的概念信息等)进行辅助判断。关注当前语境下实体的概念信息有助于更准确地判断实体间的关系。
针对现有方法大多未考虑实体自身的背景知识导致部分关系分类错误的问题,本文提出一种基于概念图谱(Concept Graph)和BiGRU-Att(Attention-based Bidirectional Gated Recurrent Unit)模型的方法来抽取突发事件演化关系。该方法的主要特点在于:①引入概念图谱与概念化算法来获得实体最符合当前语境的概念特征集合,通过加入概念特征来增加背景知识,提高关系抽取的准确性;②用BiGRU-Att模型对加入了概念特征的文本进行关系抽取。本文最后通过与其他关系抽取方法进行对比实验,来验证所提方法的有效性。
1 相关工作
关系抽取是信息抽取任务中的关键子任务之一,对构建知识库有着重要作用。关系抽取可分为两类:有监督的实体关系抽取和无监督的实体关系抽取。本文将突发事件演化关系的抽取转化为有监督的实体关系四分类问题。
有监督的实体关系抽取方法主要分为三大体系:基于特征向量的方法、基于核函数的方法和基于深度学习的方法。传统的基于特征向量的方法[4-5]依赖于构建者对句法、语法等信息的选择,通用性不强,且忽略了文本中的上下文信息。基于核函数的方法则能更好地利用上下文信息。Zelenko等[6]利用浅层解析树核以及支持向量机(SVM)进行关系抽取。Bunescu等[7]提出了基于子序列核函数的方法,并且在多个语料上验证了其有效性。然而基于核函数的方法的召回率太低,且存在训练和预测速度太慢的问题。近年来,基于深度学习的方法被广泛应用于实体关系抽取领域,该类方法通过神经网络来学习句子深层次的特征序列并用于关系分类。Zeng等[8]通过基于卷积神经网络(Convolutional Neural Network, CNN)的模型来提取词汇和句子特征进行关系分类,该模型较好地利用了句中的实体信息,但未能解决长距离依赖信息的问题。田生伟等[9]利用双向长短时记忆(Bidirectional Long Short Term Memory, BiLSTM)网络来抽取维吾尔语文本中的事件因果关系,总体效果较好,但该方法将句子中所有词语视为一样,没有考虑各个词语的不同重要程度。为了解决该问题,闻畅等[3]将注意力机制(Attention Mechanism)引入到BiLSTM模型中,利用其计算注意力概率以突出关键词汇在文本中的重要程度。但LSTM网络用遗忘门、输入门和输出门这三个门结构来解决长距离依赖信息的问题,导致该模型参数过多且计算复杂。
概念图谱是知识图谱的一种,可以更好地帮助机器来理解自然语言。概念图谱中包含了实体(如“大雨”)、概念(如“天气”)以及他们之间的类属关系(又称isA关系,如“大雨isA天气”)。由于概念图谱包含了大量常识性的概念,近年来已在意图识别、短文本分类等领域取得了较好的使用效果。Xu等[10]利用概念图谱对用户的输入进行更高层次的概念抽象,并应用于意图识别。Huang等[11]提出的概念化算法结合了概念图谱,利用文本中词语及与其对应的概念集合之间的相关性,得到该词符合语境的概念特征,提高了短文本的分类效果。
考虑到概念图谱已有效应用于多个自然语言处理领域,且人类在判断文本中实体对之间的关系时也会考虑实体的概念知识,故本文将概念图谱引入关系抽取任务中,参照文献[11]中的概念化算法获取符合当前语境的概念特征,通过加入概念特征来增加背景知识,提高关系抽取的准确性。同时,本文还采用了与LSTM网络相比结构更简单、参数更少的门控循环单元(Gated Recurrent Unit, GRU) 网络[12]来进行特征学习,将Attention机制引入双向GRU网络(BiGRU),构建BiGRU-Att模型进行关系抽取。
2 本文方法的系统框架
本文提出的基于概念图谱与BiGRU-Att模型的突发事件演化关系抽取方法的框架结构如图1所示,共分为3个部分:概念特征抽取、特征拓展和BiGRU-Att模型的训练。将突发事件数据集分为训练集和测试集,使用jieba分词工具对数据集处理后作为模型输入。
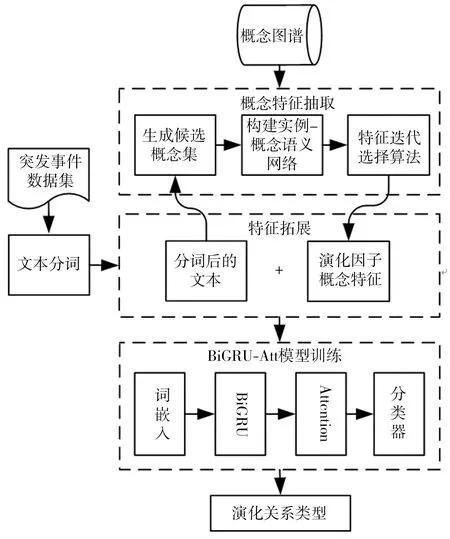
图1 基于概念图谱与BiGRU-Att模型的演化关系抽取方法的框架结构
Fig.1 Framework of evolution relationship extraction based on concept graph and BiGRU-Att model
概念特征抽取:基于概念图谱构建实例-概念语义网络,利用该网络进行特征选择计算,得到符合当前语境的概念排序。
特征拓展:根据突发事件的特点,选取突发事件中致灾因子、承灾载体和影响因子的概念特征,与分词后的文本拼接,作为BiGRU-Att模型的输入。
BiGRU-Att模型训练:用训练集来完成模型的训练,用测试集来验证模型的关系抽取效果。首先将特征拓展后的文本经过词嵌入转换为词向量,然后用BiGRU学习文本深层次的语义特征,并通过Attention机制来突出重要特征,最后通过分类器进行演化关系分类。
3 概念特征抽取
本文引入概念图谱,结合概念化算法[11],利用实例、概念间的相互关系,迭代出最符合当前语境的概念排序。概念特征抽取主要分为3个阶段:①基于概念图谱生成候选概念集合;②利用候选概念集合与实例集合构建实例-概念语义网络;③基于构建的语义网络进行特征选择计算,得到实例在当前语境下对应的最可能的概念排序。
3.1 候选概念集
为了描述候选概念集的生成,首先明确以下概念特征抽取的相关定义。
定义1实例。给定一段已分好词的文本X={xi|1≤i≤n},其中xi表示每个词语,n为文本分词后词语的总数,称词语xi为实例。
定义2概念。对于文本X中的实例xi,如果存在cj是xi的父类,则称cj为xi的概念。简单地说,概念就是让相似的实例可以联系在一起。例如,“大雨”、“大风”这些实例可以用“天气”这个概念来表示。
定义3候选概念集。通过概念图谱获取文本X中实例xi对应的集合C={〈cj,fj〉│1≤j≤m},其中频数fj为概念图谱生成过程中统计出的概念cj的通用分数,m是根据需求预先设定的,则称集合C为xi的候选概念集。例如,“大雨”的候选概念集为{〈天气,1155〉,〈情况,309〉,〈气候,234〉,〈湿度,159〉}。
通过概念图谱对文本中的每个实例进行映射,生成对应的候选概念集,作为语义网络构建的基础。这里得到的候选概念集代表的是在大多数情况下实例对应的概念排序。
3.2 实例-概念语义网络
为了能够量化实例与概念间的关系,分析它们在文本中的影响,这里利用候选概念集合与实例集合构建了实例-概念语义网络,即一个表示实例和概念之间语义关系的网络结构,图2是部分语义网络示例。
图2中有两类节点:矩形表示实例节点,例如实例“大雨”、“地震”等;椭圆表示概念节点,例如实例“大雨”对应的候选概念集中的“天气”和“气候”。节点间通过有向加权边或无向加权边相连,其中权值表示节点间的关联强度。
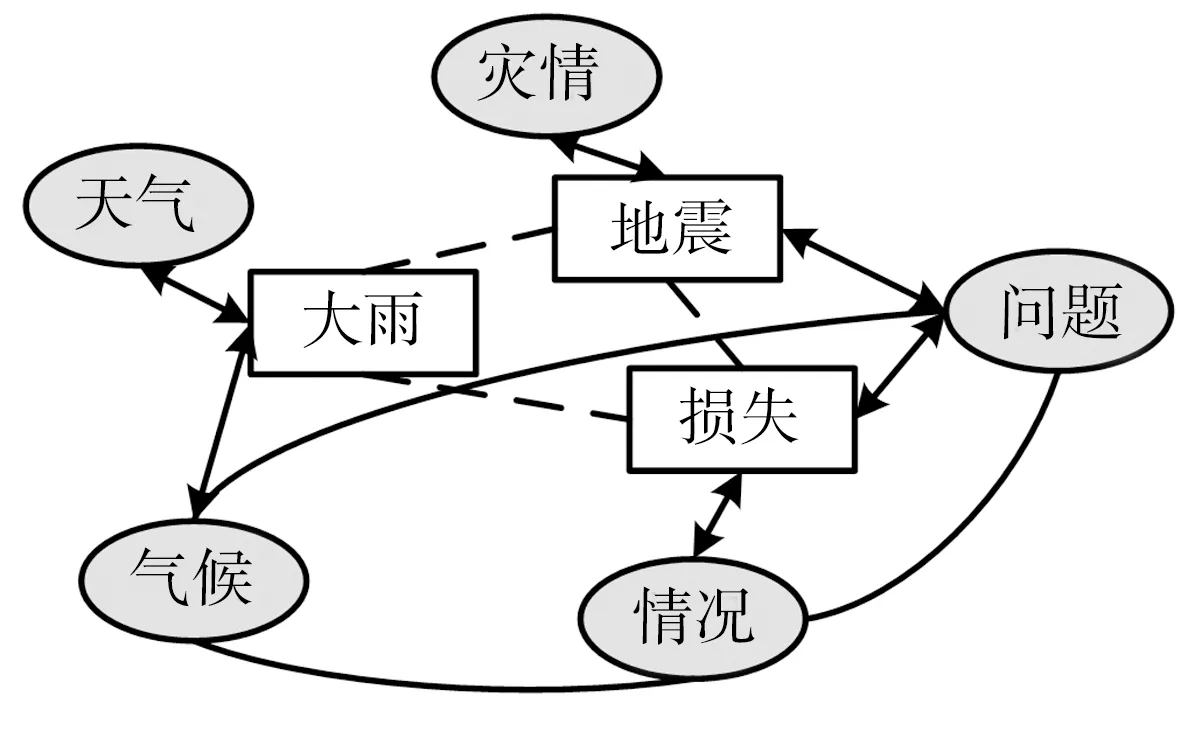
图2 实例-概念语义网络
将实例-概念语义网络表示为图G=(V,E),其中V是图中顶点的集合,E是图中边的集合。整个网络G主要由三部分组成:
(1) 概念-概念子网络(Gcc):表示概念与概念的相互影响力,由图中的椭圆及相连的弧形实线边构成;
(2) 实例-实例子网络(Gww):表示实例与实例的相互影响力,由图中的矩形及相连的虚线边构成;
(3) 实例-概念子网络(Gwc):是将Gcc和Gww两个网络关联到一起的子网络,表示概念与实例间的可能性,由图中的椭圆和矩形及相连的双向实线边构成。
实例-概念语义网络G的关联矩阵如下:
(1)
式中:Mcc表示Gcc中概念间的相关性,通过文本中全部实例对应的候选概念集中每两个概念的共现次数及其相关函数(Correlation Function)[11]得到;Mww表示Gww中实例间的相关性,由文本中每两个实例的共现次数及其相关函数计算得到;Mwc表示Gwc中实例与其对应的候选概念集的关系,它由实例到某个概念的频数fi和互相关函数(Inter Correlation Function)[11]决定;Mcw与Mwc不同,它代表的是概念与其相关的实例间的关系,而且仅由频数fi决定。
3.3 特征迭代选择算法
将3个子网络Gcc、Gww和Gwc结合起来,通过特征迭代选择算法[11]更改实例对应的候选概念集中概念的排序,使其更符合当前语境。
特征迭代选择算法以上一节构建的语义网络为基础来进行计算,迭代过程中会生成两个矩阵:Scorec和Scorew,分别为概念和实例的分数矩阵,代表着概念和实例的排序分数(重要程度)。如图3所示,迭代选择算法每轮包含以下4个步骤:
(1) 实例-概念排序:利用实例的排序分数来影响概念的排序分数,即通过实例的分数Scorew和Mwc计算更新Scorec;
(2) 概念-概念排序:主要思想是如果一个概念与其他大多数概念越相关,则该概念分配到的分数越大,即通过概念的分数Scorec和Mcc计算更新Scorec;
(3) 概念-实例排序:利用概念的排序分数来影响实例的排序分数,即通过概念的分数Scorec和Mcw计算更新Scorew;
(4) 实例-实例排序:与概念-概念排序类似,如果一个实例与其他大多数实例越相关,则该实例分配到的分数越大,即通过实例的分数Scorew和Mww计算更新Scorew。
当多次连续迭代计算出的平均分数之间没有明显变化时停止迭代,可根据最终得到的Scorec将实例对应的候选概念集重新排序。

图3 特征迭代选择流程
4 特征拓展
当先验知识较准确时,带有先验的分类方法能大大提高分类效果[13]。针对突发事件演化关系的特点,本文方法通过增加演化因子概念特征来提高关系分类的准确性。演化因子及其概念特征定义如下:
定义4演化因子。突发事件演化关系是致灾因子、承灾载体和影响因子三者之间的关系[3],本文统称这三者为演化因子,如例1,“大雨”、“伤亡”等是该突发事件的演化因子。
定义 5演化因子概念特征。在文本X中,实例xi是突发事件的演化因子,将xi的候选概念集C中的概念根据当前语境下与xi的相关度降序排列,取前k名作为xi的演化因子概念特征F,k即为演化因子概念特征的大小。如当概念特征大小k=2时,F={c1,c2}。
在如图3的迭代选择过程,选取迭代停止时的分数矩阵Scorec为最终结果,Scorec中的分数代表实例与概念的相关度。对于文本中的演化因子,将其对应的候选概念集根据Scorec中的分数重新按降序排列,并选择前k个作为演化因子概念特征。将得到的突发事件演化因子的概念特征与分词后的语句拼接,作为BiGRU-Att模型的输入。
5 BiGRU-Att模型
突发事件演化关系的抽取利用BiGRU-Att模型来完成,模型的输入是上一节得到的特征拓展后的文本。BiGRU-Att模型结构见图4,共包括4个部分:
(1)词嵌入层:将词语映射到低维稠密向量;
(2) BiGRU层:利用BiGRU从词嵌入层输出的低维稠密向量获得深层次的特征;
(3) Attention层:对获得的深层次特征进行加权变换,突出重要信息的贡献度;
(4)分类层:利用softmax分类器进行突发事件演化关系抽取。

图4 BiGRU-Att模型结构
5.1 词嵌入层
词嵌入层为BiGRU-Att模型的第一层,主要目的是将词转化为低维稠密向量,用来捕捉句子的语义信息。词嵌入层的输入为集合S={si|1≤i≤n},集合S是特征拓展模块的输出,由分词后的文本和演化因子概念特征组成,其中n为特征拓展后文本中词的个数。
集合S中的每一个词si都会被表示为一个实值向量ei,ei的计算公式如下:
ei=Wwrdvi
(2)
式中:矩阵Wwrd∈Rd|v|,v是固定大小的词汇表,d为词向量的维度,Wwrd是需要学习的参数,vi是输入词的one-hot表示,大小为|v|。由此得到的整个词嵌入层的输出,也就是特征拓展后的文本的词嵌入矩阵E=[e1,e2,…,en]。
5.2 BiGRU层
BiGRU为模型的第二层,用来学习句子深层次的语义信息。GRU是LSTM的一个变种,两者均能够学习文本的序列信息,适用于时序问题。LSTM通过遗忘门、输入门和输出门来习得序列信息,而GRU的结构如图5所示,它取消了LSTM中的细胞状态,只保留了隐藏状态,将LSTM中的输入门和遗忘门用更新门zt来代替,输出门用重置门rt来代替。GRU的更新门决定上个时刻记忆的保留程度,重置门则决定上个时刻记忆的丢弃程度与新的输入。相比于LSTM,GRU的结构更简单、参数更少,减少了计算的复杂性。

图5 GRU单元结构
BiGRU层的输入为嵌入层输出的矩阵E,因此集合S中第t个词的输入为该词的向量表示et。这里以输入为et来表示GRU的计算过程,公式如下:
zt=σ(Wzet+Uzht-1+bz)
(3)
rt=σ(Wret+Urht-1+br)
(4)
(5)
(6)


(7)
5.3 Attention层
Attention层为模型的第三层,用于对BiGRU习得的深层次特征进行加权变换,突出文本序列中重点词汇信息的作用,从而提高突发事件演化关系抽取的准确性。注意力机制的计算公式如下:
M=tanh(H)
(8)
α=softmax(wTM)
(9)
r′=HαT
(10)
r=tanh(r′)
(11)
式中:H=[h1,h2,…,hn]为上一层BiGRU神经网络层输出的向量;w为训练好的参数向量;α为权重矩阵;softmax为归一化指数函数;tanh为激活函数。Attention层最终的输出为加权变化后的深层次特征r。
5.4 分类器
分类层是模型的最后一层。本文使用的softmax分类器是logistic回归模型在多分类问题上的推广。如图4,将Attention层得到的深层次特征r输入到softmax进行归一化,得到了演化因子对所对应的4种演化关系类别的概率p(y│r),如下式:
p(y│r)=softmax(Wr+br)
(12)

(13)
6 实验
本文将基于概念图谱与BiGRU-Att模型的关系抽取方法应用到突发事件领域的演化关系抽取中,并分别进行两组实验:①对比演化因子概念特征的大小k对关系抽取效果的影响;②验证概念图谱和BiGRU-Att模型对演化关系抽取的有效性。实验流程如图6所示。
6.1 实验数据集与概念图谱
本文选用的数据集为突发事件中文数据集[3]。该数据集是以在中新网和网易新闻网等网站上爬取的932篇突发事件新闻为基础,参照自动内容抽取(ACE)的事件标注标准进行标注的2800条突发事件语料,包含了自然灾害、事故灾害、公共卫生和社会安全4类突发事件。数据集根据突发事件演化关系模型的关系类别分为4类:直接因果关系、促进关系、抑制关系和无关系。将数据集按7∶3的比例随机分为两部分,分别作为训练集和测试集。鉴于实验对象为中文数据集,故概念图谱选用了支持中文的Probase+[14]。

图6 突发事件演化关系抽取实验流程
Fig.6 Experimental process of evolution relationship extraction for emergencies
6.2 实验结果与分析
对于不同模型的分类结果,本文以常用的准确率(precision) 、召回率(recall)和F1值作为评测指标。
首先对比演化因子概念特征的大小k对突发事件演化关系抽取效果的影响。概念特征是演化因子的背景知识,增加背景知识能够提高关系抽取的效果,不同大小的概念特征包含的背景信息不同,所以实验选取k值分别为0、1、2、3,在图1的框架下进行突发事件演化关系抽取,实验结果如图7所示。

图7 演化因子概念特征大小对关系抽取效果的影响
Fig.7 Influence of the size of evolution factor concept feature on relationship extraction
由图7可见,当演化因子概念特征大小k为0,即未使用概念特征时,准确率、召回率和F1值均为最低,当k为1、2和3时,准确率、召回率和F1值均得到不同程度的增大,表明演化因子概念特征的加入有效提升了模型的关系抽取效果。准确率、召回率和F1值均在k=2时达到最高,分别为91.0%、89.7%和90.3%,这是因为:k=1时,加入的概念特征过少,模型没有学习到足够的背景知识;k=3时,在概念特征中排名第三的概念又与其对应的演化因子关联过小,引入了带有噪声的背景知识;k=2时,模型即能学习到足够的背景知识,又不会引入过多的噪声,取得了最优的演化关系抽取效果。因此后续实验中均采用大小为2的演化因子概念特征。
为了验证本文设计的抽取框架对突发事件演化关系抽取的有效性,一共采用6种模型来进行对比实验,分别是:①文献[3]提出的BiLSTM-Att模型、②加入概念图谱的BiLSTM-Att模型、③双向循环神经网络(BiRNN)模型、④BiGRU模型、⑤加入了注意力机制的BiGRU模型(即BiGRU-Att)、⑥本文提出的基于概念图谱和BiGRU-Att的关系抽取模型。表1所示为各模型的实验结果。
表1 不同模型的实验结果对比
Table 1 Comparison of experimental results of different models

编号模型准确率/%召回率/%F1值/%1BiLSTM-Att89.887.988.82BiLSTM-Att+概念图谱90.889.189.93BiRNN80.879.880.34BiGRU89.087.488.25BiGRU-Att90.288.789.46BiGRU-Att+概念图谱91.089.790.3
表1中的数据表明本文方法相较于其他5种方法取得了更优的突发事件演化关系抽取效果。如表1所示,BiGRU模型比BiRNN模型的实验结果有大幅提升,这是因为加入门控机制的GRU解决了RNN梯度消失和梯度爆炸问题,得到了更准确的语义信息;而加入注意力机制的BiGRU-Att模型抽取效果又得到了进一步改善,这是由于不同的词汇在文本中的重要程度是不一样的,而注意力机制能够强化重要词汇在文本中的作用;BiGRU-Att的突发事件演化关系抽取效果略优于BiLSTM-Att,这两个模型均加入了注意力机制,区别在于BiGRU比BiLSTM的结构更简单,减少了约三分之一的参数,且更不容易过拟合,因此针对于本文数据集取得了更优解。
另外,对比表1中加入概念图谱前后的BiLSTM-Att(模型1和模型2)和BiGRU-Att(模型5和模型6)的实验结果,可以看出,概念图谱的引入使得突发事件演化关系抽取的准确率、召回率和F1值均有提升,其原因在于原始文本中的语义信息有限,缺少突发事件的背景知识,而引入概念图谱对原始语句进行演化因子概念特征拓展后,弥补了这一空白,使得BiLSTM-Att和BiGRU-Att模型能够学到更多深层次的语义特征,有助于突发事件演化关系分类。
7 结语
本文提出了一种基于概念图谱与BiGRU-Att模型的方法用于抽取突发事件演化关系,以克服现有演化关系抽取模型忽略了背景知识从而导致信息抽取不够准确的问题。该方法将演化关系抽取转化为四分类问题,引入概念图谱对突发事件文本进行背景知识的扩充,将扩充后的文本作为BiGRU-Att模型的输入进行特征学习,最后利用分类器完成演化关系的抽取。与其他模型在同一数据集上的对比实验结果显示,本文方法在准确率、召回率和F1值这3个评价指标上均取得最优值,有助于构建更完备的突发事件知识库。
本文方法仍有改进的空间,在下一步工作中可以考虑引入更多的先验知识来进行演化关系抽取,例如句法和上下文特征,同时还可以考虑将注意力机制进行改进。
