从信息学的角度分析复杂网络链路预测
2020-05-09乐孜纯武玉坤
王 慧,乐孜纯,龚 轩,武玉坤,左 浩
1(浙江工业大学 计算机科学与技术学院,杭州 310023)2(江西理工大学 应用科学学院,江西 赣州 341000)3(浙江工业大学 理学院,杭州 310023)
1 引 言
网络数据挖掘作为一项主流的、重要的数据挖掘技术,主要包括社区检测、结构网络分析、网络可视化.其中最有趣的一个研究方向是链路预测LP,LP在计算机领域已有一些研究成果,它处理的是信息科学中最基本的问题—缺失信息,虚假信息,新增信息,关键链路的预测.该问题从已观察到的网络结构、节点属性、图结构特征入手,预测存在但未被观察到,错过或者未来可能会出现或消失的链路,这是一个有意义的研究方向.他们采用的主要技术和方法是机器学习、基于图的深度学习和Markov链.2000年Sarukkai[1]等人提出了利用Markov链进行概率链路预测,将强大的概率模型应用于Web路径分析和链路预测.2003年,Popescul等人[2]提出了一种结构逻辑回归(SLR)方法,利用引文信息、正文标题、摘要、作者姓名和所属单位,以及会议和期刊的名称等外部信息预测文献之间的引用关系.2004年Zhu等人[3]使用Markov模型进行链路预测,以帮助新用户浏览网站,提出了一种转移概率矩阵压缩算法进一步提高了链路预测的效率.此外,应用节点属性的预测方法也有很多,例如Lin[4]通过节点的属性特征确定节点间的相似性,认为属性越相似的节点越可能产生链接.2018年Zhang[5]等人基于图的深度学习来研究链路预测问题.研究成果表明应用节点属性,图结构特征等外部信息的确可以得到很好的预测效果.虽然各领域的专家们提出了许多的链路预测方法,但是结合这些方法的综述文章却非常少.
尽管在2010年至2018年间吕琳媛周涛等研究人员相继提出了一些关于复杂网络链路预测的综述文章,但是这些文章主要强调从物理学角度的贡献.例如:2010年9月吕琳媛[6,7]在电子科技大学学报发表了一篇综述文章,该篇文章介绍了基于最大似然估计的链路预测,基于相似性的链路预测和基于概率模型的链路预测.同年,吕琳媛,周涛[8]在Physica A发表了一篇名为《Link Prediction in Complex Networks:A Survey》的文章,文章综述了链路预测的研究进展及常用的算法,提出了基于随机游走的方法和最大似然方法,介绍了三种典型应用,网络重构、网络演化机制和标记分类.随后2015年5月张斌和马费成[9]在中国图书馆学报发表了一篇名为《科学知识网络中的链路预测研究述评》,该篇文章以“科学知识网络中的链路预测”为主要对象,对链路预测的类型、研究思路和方法进行了综述.2016年Cubero[10]在ACM Computing Surveys期刊发表了一篇《A Survey of Link Prediction in Complex Network》的综述文章,该篇文章把当前的链路预测技术分为四类,分别为基于相似性的方法、基于概率和统计的方法、计算方法、预处理的方法,并对每种方法的复杂度和精确度进行了详细的分析.以上这些文章主要采用网络拓扑结构作为输入特征,计算简单,复杂度低,在物理学的视角分析复杂网络链路预测,强调物理学家近年来的研究成果.
2016年4月吕琳媛,任晓龙和周涛[11]在中国计算机学会通讯发表了一篇综述文章,该篇文章除了介绍了物理学的研究方法外,还介绍了信息学中的链路预测方法即基于机器学习的方法,该方法包括三部分:基于概率图模型的链路预测、基于特征分类的链路预测和基于矩阵分解的链路预测.这篇文章虽然涉及到了一些信息学中的链路预测方法,但是没有涉及当前最新的基于图特征的深度学习链路预测技术.到目前为止,从信息学的角度分析复杂网络链路预测的综述少之又少,本文试图从信息学的视角全面分析在计算机领域许多经典的和最新的链路预测技术,并对这些链路预测技术进行了系统的分类,把分层的思想引入分类模型的创建,将分类模型分为三层,输入层,处理层和输出层,其中:输入层包括输入元数据(网络结构,属性特征,标签,中心性,角色,社区和语义信息).处理层包括常用的监督,半监督,无监督和强化学习技术.输出层包括边,子图和全图信息.
本文的组织结构如下:下一节介绍了常用的链路预测方法,提出了一种新的链路预测分类模型,对计算机领域常用的、经典的、最新的链路预测算法进行了分类,对其复杂性、输入特征和开源实现进行了详细的分析.第三节分析了链路预测未来的发展方向.第四节给出了结论.
2 常用的链路预测方法
2.1 分层模型
从信息学的角度分析复杂网络链路预测,这是一个典型的二分类问题,令x,y∈V为图G(V,E)中的节点,l(x,y)为节点对实例(x,y)的标签,如果节点之间存在链接,那么这对节点标记为正链接,否则,这对节点标记为负链接.
本文把当前信息学中的链路预测方法按分层模型进行划分(如图1所示).该模型分为三层,输入层,处理层和输出层.
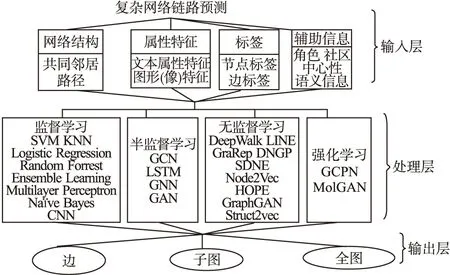
图1 复杂网络链路预测分层模型 Fig.1 Link prediction hierarchical model for complex networks
2.1.1 第一层输入层
特征选取和特征输入是分类问题中的首要问题,因此选择输入层作为分层模型的第一层,目前研究较多的输入特征主要包括基于节点与边的属性特征、图形(像)特征、基于节点所处网络的拓扑特征和辅助特征.下面分别介绍常用的4种不同类型的输入特征.
1)网络结构
对于输入的元数据其中有部分是采用基于网络的拓扑结构信息,Liben-Nowell和Kleinberg[12]讨论了基于图的结构特点,在他们的工作之后,提出了许多基于拓扑的度量方法.根据这些度量的特征可以分为基于共同邻居的度量和基于路径的度量.
2013年王等人[13]发表了一篇名为《Similarity index based on the information of neighbor nodes for link prediction of complex network》的文章,该篇文章提出了一种基于共同邻居节点对边的贡献的新指标,并证明了该指标具有较好的预测能力,具有较低的复杂度,特别是对于聚类系数较低的网络,具有较好的预测效率.
2009年吕琳媛和周涛[14]等人提出了一种局部路径指标来评估两个节点之间存在链接的可能性.与公共邻域CN和Katz指标相比,局部路径指数具有较高的有效性和效率.
2)属性特征
许多研究表明,使用节点和链接的文本或图形属性(如用户的年龄、兴趣、照片等)作为输入特征可以显著提高链路预测的性能.
李等人[15]提出了一种基于图核的学习方法使用年龄、受教育程度、关键词作为输入特征,取得了较好的预测效果.
Scellato[16]等人在基于位置的社交网络中考虑了社会特征、地点特征和全局特征,利用监督的学习框架进行链路预测.
3)标签
标签特征包括节点标签和边标签.2007年Raghavan和Albert[17]等人提出了一种基于网络的简单标签传播算法用于解决链路预测问题,它以节点标签作为输入的元数据,每个节点都初始化为唯一的标签,假设一个网络中的节点X有K个邻居,X的每个邻居都有一个标签,来显示它们各自的属性归属于哪个社区.算法规定每个节点都选择加入那个所有直接邻居中标签数据最多的那个社区.最终,在同一个社区中包含了相同标签的节点群.该标签传播算法具有较低的时间复杂度,能较好的捕捉网络的动态演化,对链路预测有重要的指导意义.
4)辅助信息
·角色
一个实体的角色是指该实体与其他实体之间关系的集合.用图论的方法来描述的话,即顶点V的角色是所有与V相连的边组成的集合.一般来说,自同构的顶点具有相同的角色,并且具有着最大的角色相似性.角色相似性描述的是如果两个顶点和相似的顶点有相似数目的关系.
2013年伍杰华[18]提出了差分化社会网络节点角色的链路预测模型,采用Clauset-Newman-Moore算法挖掘社会网络结构属性,同时引入节点连接度和社区理论,差分处理社区内外节点和不同社区的贡献,可以提高社会网络中的链路预测精度,有效的解决量化邻接节点贡献权重的问题.
·社区
以社区信息作为输入元数据能够帮助我们分析网络结构、预测网络行为,发现潜在的规律,并更好的理解和解释网络的功能.通过社区的划分能够使得同一社区的节点关系紧密,不同社区的节点关系稀疏.
2012年Soundarajan[19]发表了一篇名为《Using community information to improve the precision of link prediction methods》文章,该篇文章考虑了几种基于相似性的度量方法,用社区信息作为输入元数据补充了相似性的计算,实验结果表明,利用社区信息可以改善链路预测的性能和准确性.
同年,Rebaza[20]等人发表了一篇文章,该篇文章结合了局部相似性和社区信息,提高了链路预测的精度.实验结果表明,该方法是可行的,它的性能优于CN、AA、JC、RA和PA.能有效地应用于有向和非对称大规模网络.
2013年伍杰华[21]发表了一篇名为《基于划分社区和差分共邻节点贡献的链路预测》的文章,该篇文章通过改进基于节点相似度的朴素贝叶斯模型,引入GN和CMN两种经典的划分社区算法,挖掘社区属性预测节点的影响,给予共邻节点不同的连接度和社区的贡献度,并计算其贡献权重,实验表明,有较高的预测精度.
·中心性
本篇文章考虑了节点在网络中的影响力,利用节点的度中心性、介数中心性、紧密中心性和特征向量中心性作为输入的元数据来进行复杂网络链路预测.
2016年陈嘉颖[22]等人在基于局部相似性链路预测算法的基础上,充分利用了节点度中心性、紧密中心性和介数中心性的信息,提出了考虑节点重要性的CN、AA、RA链路预测相似性指标.实验结果表明,改进的算法预测精度均高于共同邻居算法.
·语义信息
语义信息指通过领悟实体的运动状态及其变化方式的逻辑含义,由此获得的信息.
Iill[23,24]等人提出了一种使用抽象语义信息研究标题和事件特征,以改进作者合作网络中的链路预测问题,取得了较好的预测性能.
2017年Guo[25]等人研究了在低维向量空间中针对知识图的链路预测问题,提出了SSE方法,它的核心思想是充分利用附加的语义信息作为输入特征,使属于同一语义类别的实体将在嵌入空间中彼此靠近.采用拉普拉斯特征映射和局部线性嵌入两种学习算法进行建模,较好的解决了数据的稀疏性问题,结果表明,该方法优于TransE和SME等链路预测方法.
2.1.2 第二层处理层
模型的第二层特征处理层,用信息学的方法和思路进行复杂网络链路预测,我们把该层主要分为无监督学习、监督学习、半监督学习和强化学习的方法.
1)无监督学习
传统的无监督的学习技术,从无标注数据集中挖掘相互之间的隐含关系,主要采用网络的拓扑结构提取特征,使用这些无监督的方法能够发现网络中两个节点建立关系的概率.虽然无监督的方法复杂度较低,计算简单.但是,无监督的方法适合排序,如果要进行链路预测任务,指标阈值较难设定,特别对于权重网络,使用无监督的方法,预测性能在某些情况下会衰减.在针对节点分类等任务时,区分性较差.
本文介绍的无监督学习方法主要包括DeepWalk,LINE,GraRep,DNGR,SDNE,Struct2vec,Node2Vec,HOPE,GraphGAN,下面分别进行介绍:
·DeepWalk
Perozzi[26]等人提出了一种学习网络中顶点潜在表示的新方法DeepWalk.DeepWalk概括了语言建模从单词序列到图形的无监督特征学习方面的最新进展.其主要思路就是利用构造节点在网络上的随机游走路径,来学习潜在的表示.DeepWalk可以按需生成随机游走.由于Skip-gram模型也针对每个样本进行优化,因此随机游走和Skip-gram的组合使DeepWalk成为在线算法.其次,DeepWalk是可扩展的,生成随机游走和优化Skip-gram模型的过程都是高效且并行化的.再次,DeepWalk引入了深度学习图形的范例.
·LINE
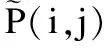
·GraRep
GraRep[27]通过将图形邻接矩阵提升到不同的幂来利用不同尺度的节点共现信息.将奇异值分解(SVD)应用于邻接矩阵的幂,以获得节点的低维表示.它的缺点是扩展性较差.
·DNGR
DNGR[28]结合了随机游走和深度自动编码器.该模型由3部分组成:随机游走、正点互信息(PPMI)计算和叠加去噪的自动编码器.在输入图上使用随机游走模型来产生概率共现矩阵,类似于HOPE中的相似矩阵.矩阵被转换成一个PPMI矩阵,并将其输入到一个叠加去噪自动编码器中,以获得嵌入.输入PPMI矩阵可以确保自动编码器模型能够捕获更高阶的近似度.此外,使用叠加去噪自动编码器模型能够捕获更高阶的近似度,以及捕获链接预测任务所需的底层结构.
DNGR 与 SDNE 区别主要在于相似性向量的定义不同,DNGR 将两个节点由随机游走得到的共同路径作为衡量其相似性的指标,而 SDNE 直接用一阶关系作为相似性的输入.
·SDNE
2016年,王等人[29]提出一种结构化的深度网络嵌入方法SDNE,来保留网络的一阶和二阶相似性,同时处理好稀疏性的问题,利用一阶近似描述局部信息,使用二阶近似由无监督组件捕获全局网络结构,对稀疏网络具有较强的鲁棒性.结果表明该方法具有较好的重建效果.特别是在多标签分类和链路预测领域获得了实质性的进展.
SDNE将节点的相似性向量Si直接作为模型的输入,通过自动编码器对这个向量进行降维压缩,得到其向量化后的结果Zi.其损失函数定义为:
其中Si是一个|V|维的输入向量,而Zi的维数必然远小于前者.它的建模思路和矩阵分解是一致的,只是在降维时用的不是矩阵分解,而是自动编码器.
·Stuct2vec
2017年Ribeiro等人[30]提出了一种新的、灵活的Struct2vec框架,用于学习节点结构标识的潜在表示.Struct2vec使用层次结构度量节点对的结构相似性,并构造多层图对结构相似性进行编码,为节点生成上下文结构,利用上下文来学习节点的潜在表示.实验表明,Struct2vec在捕捉结构特征方面非常出色,优于DeepWalk和Node2Vec.
·Node2Vec
2016年Aditya[31]提出了一种学习网络节点连续特征表示的算法框架Node2Vec.它是一种自动学习节点特征的嵌入方法,主要用于社交网络中的链路预测任务.在Node2Vec中,学习了一种将节点映射到低维特征空间的方法,这种方法可以最大限度地保留节点的网络邻域.Node2Vec引入了 biased-random walks,用来刻画每次随机游走是偏深度探索(DFS)还是广度探索(BFS),分别侧重社区结构和节点重要性的信息,有效的探索了不同的邻域.由于 node2vec 有 p 和 q 两个超参数,所以它是一个比较灵活的模型框架.
2018年Li[32]等人提出了一种新的网络嵌入方法TDL2Vec用于预测作者合作网络中消失的链接问题,它是对Node2Vec算法的扩展.该篇文章将消失链接的预测问题看作是一个二分类问题,并将支持向量机SVM作为嵌入后的分类器,实验结果表明,TDL2Vec具有较好的性能.
同年,Shawn[33]等人比较了三种网络的嵌入方法Graphlets,Node2Vce和struc2vec,Graphlet比其他两种方法结果更加的精确,计数更加的迅速,特别是在节点分类和链路预测领域.
实验结果表明,图形将继续在网络科学领域留下自己的印记,通过图理论进行链路预测将成为未来的发展发向.这也进一步证实,后面我们将要提到的基于图形的深度学习方法对链路预测问题具有重要的意义.
·HOPE

·GraphGAN
2018年Wang[35]等人创新性的提出了一种新的图形表示学习框架GraphGAN,它是一个在网络生成学习中将生成模型和判别模型加以结合的框架.对于给定的顶点,生成器拟合Ptrue,判别器尝试去判别两个点之间是否有边,实验在5个数据集上进行了测试,结果表明GraphGAN比DeepWalk,LINE,Node2Vec和Struc2vec准确性都更高.特别是在链路预测领域获得了较佳的性能.
2)监督学习
随着机器学习技术的迅猛发展,一些计算机领域的专家们使用监督学习技术来进行复杂网络链路预测.监督学习技术通过对有标记的数据集进行训练,预测未知的数据.它能够根据输入特征自动学习出分类模型,在一定程度上克服了传统的无监督学习方法的缺陷.
迄今为止,在计算机领域产生了许多基于监督学习的研究成果.例如:2011年哈桑(Hasan)等人[36]提取合著网络中科学家研究领域的关键词作为输入特征,用监督学习中一些常用的分类算法(如决策树、K近邻法、多层感知器、支持向量机、径向基网络)对缺失的连边进行较为精准的预测,其中以支持向量机方法表现最佳.2012年Pujari和Kanawati[37]提出了一种监督的社会选择算法,他们使用这些数据来学习与每个计算特征相关联的权重特征,然后使用这些权重在加权/监督计算社会选择算法预测新链接.随后,刘等人[38]提出了一种基于监督学习的框架,利用多种信息构造出丰富多样的基于路径的特征进行链路预测,该方法证实可以高效的学习动态社交网络.2014年Raf[39]等人提出通过监督学习中的集成学习结合RF方法预测加权合作网络,实验结果表明,该方法准确性较高.2019年赵素芬[40]提出了利用网络的拓扑结构,学者的研究兴趣,学者的学术地位作为输入特征,使用了8种经典的机器学习算法(K近邻、logistic回归、决策树DT、支持向量机SVM、朴素贝叶斯、多层前馈神经网络MLP、集成学习随机森林和Adaboost)进行了合作关系的预测,并进行了预测性能的比较.该项研究表明,在基本的机器学习模型中,多层感知机表现最好,因为它的隐藏层可以捕捉特征之间的非线性关系,并在较高层次进行抽象,所以能较好的拟合训练数据,训练出精度高的模型.而朴素贝叶斯表现最差,因为它假定了特征之间的条件独立性,在本问题中很难确定,因而影响了分类效果.其他几种算法逻辑回归、决策树和SVM性能基本一致,KNN优于朴素贝叶斯.2018年Aouay[41]等人提出了通过组合特征作为分类输入数据,利用多个监督的学习算法生成链路预测器(决策树、KNN、朴素贝叶斯、径向基函数和随机森林),取得了较好的效果.结果表明,随机森林、KNN和PCA 表现突出,提高了预测精度.
目前常用的监督学习方法有SVM,KNN,Logistic Regression,Random Forrest,Ensemble Learning,Multilayer Perceptron和Naïve Bayes.下面分别对这些监督学习算法进行详述:
·SVM
SVM(Support vector machine)使用一个核函数,将非线性问题变换为线性问题,它的核心思想就是找到能够最大化样本间隔的决策边界,使得两类样本尽量落在面的两边.它的优点是在面对过拟合问题时,SVM有极强的稳健性,特别是在高维空间中.缺点是选择正确的核函数需要一定的技巧,不适用于较大的数据集.
李等人[15]提出了一种基于SVM图核的机器学习方法,利用网络结构,随机游走路径,节点特征在二部图中进行链路预测,将一个推荐问题转化为一个链路预测问题,该方法其性能的优劣很大程度上依赖于核函数的选择.
Ichise[23,24]等人在基于监督学习的框架下采用SVM,decision trees,利用网络的结构,语义信息和基于事件的特征研究作者合作网络中的链路预测问题,通过在一特定的网络中,去分析所构造的预测器的算法结构,可以获悉哪些属性是有价值的信息,对链路预测问题最有帮助.
·KNN
KNN根据一个距离函数(可以是欧式距离,曼哈顿距离,汉明距离),搜寻最相似的训练样本来预测新样本的观察值.它的优点是理论简单,易实现,新数据可直接加入不必重新训练.缺点是它是内存密集型算法,处理高维数据时的效果并不理想.同时还需要高效的距离函数来计算相似度.样本不平衡时,预测偏差较大,对于样本容量大的数据集计算量大.
Manisha[37]等人利用网络的拓扑结构特征,将KNN,NaiveBayes技术应用于复杂网络链路预测中,提出了一种新的基于监督的秩聚合的方法,虽然能够聚合尽可能多的特征,但在时间复杂度方面有一定的局限性.
·Logistic Regression
逻辑回归能够对连续值进行预测,通过拟合一个逻辑函数来预测一个事件发生的概率.它的优点是计算代价不高,易于理解和实现.缺点是容易产生欠拟合,分类精度不高.
王等人[42]采用逻辑回归模型使用网络结构和基于内容的相似性度量预测合作关系,取得了较好的预测效果.
Chiang[43]等人在符号网络中,使用逻辑回归预测器进行链路预测,不仅实现了准确的符号预测,而且对于降低假阳性率是非常有效的.
Jure[44]等人也使用逻辑回归模型在符号网络中进行链路预测,选取节点的度作为特征,实现了在符号网络中高精度的预测效果.
·Random Forrest
随机森林是一个树型分类器,它采用多棵树对样本进行训练,然后通过投票或加权平均的方式输出结果.它的优点是能够实现较高的精度,不用担心过拟合问题,无需事先做特征选择,每次只用随机选取的几个特征来训练树.缺点是在某些噪音较大的分类或回归问题上会过拟合.
Scellato等人[16]使用地理位置特征,社会特征和全局特征,运用Naïve Bayes和random forests在基于地理位置的社交网络中进行预测,实现了较高的预测精度.
·Multilayer Perceptron
多层感知机也叫人工神经网络,它的一个重要特点就是多层,除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构.MLP层与层之间是全连接的,它的最底层是输入层,中间是隐藏层,最后是输出层.MLP的优点是可以学习非线性模型,能够进行实时学习.缺点是要求调整一系列超参数,比如隐藏神经元,隐藏层的个数以及迭代的次数.其次,MLP对特征缩放比较敏感.
Andrej[45]等人利用多层感知器进行时间序列预测,在反向传播算法中,权值通常用小的随机值初始化,适当的权值初始化将使权值接近一个好的解决方案,从而减少训练时间.实验结果表明,采用适当的权值初始化,可以获得较好的预测性能.
·Ensemble Learning
集成学习通过构建并结合多个学习器来完成学习任务,通常能够获得比单一学习器更优越的泛化性能.Mitchell指出[46]集成学习技术可以结合各种方法,扬长补短发挥最优性能.
2017年4月吕伟民等人提出结合链路预测与机器学习进行科研合作推荐,运用监督学习方法通过集成学习中的随机森林算法训练分类[47],并利用遍历算法求取分类结果的最优权重组合,选取TOP排名靠前的结果作为合作推荐,取得了较好的效果.
Pachaury[48]等人提出了一种新颖的链路预测方法来寻找社交网络中缺失的链接,该方法从网络图中提取拓扑特征,用于训练集成学习模型随机森林分类器,训练后的模型用于预测缺失的链接,对两个网络数据进行实验评估,实验结果表明该方法预测精度高,能揭示社交网络的隐藏链接.
·Naïve Bayes
朴素贝叶斯是一种简单的概率分类器,它的核心思想是对于给定的待分类项,求解在该项出现的条件下各个类别出现的概率,值越大,该分类项即属于此类别.优点:该算法易于实现,且对于大型数据集非常有用.支持增量式运算即可以实时的对新增的样本进行训练.缺点:由于使用了样本属性独立性的假设,所以如果样本属性有关联时其效果较差.
Valverde[49]等人提出了一种利用重叠结构信息建立朴素贝叶斯模型的新方法,比较了四个著名的在线社交网络的16项指标,结果表明,该方法有助于提高链路预测精度.
随后,Sa[50]等人在权重网络中利用网络的拓扑结构特征,采用Naïve Bayes方法证明使用权重信息可以提高监督链路预测的效果.
·CNN
卷积神经网络CNN由纽约大学的Yann Le Cun于1998年提出,它能够自动提取特征,挖掘数据局部特性.
2017年,Niepert[51]等人指出许多重要的问题比如链路预测问题,能够概括为从图形数据中学习的过程,研究了一个通用的基于卷积神经网络CNN的学习框架,用于学习任意图形的表示,这些图可以是无向的,有向的,离散的或连续的节点和边缘属性.在输入的局部连通区域上,提出了一种局部数据提取的通用方法,该方法取得了较高的效率.
2018年,舒坚[52]等人借助CNN能够自动提取特征的优势,提出一种基于模型分类的多点间链路预测方法,该方法基于混沌时间序列理论确定机会网络的切片时间,采用状态图表征网络的拓扑结构,从状态图的演化过程中提取机会网络的结构特征,实现多点间的链路预测.能较好地辅助研究人员进行网络分析并提供合理的决策支持.
3)半监督学习
有监督的学习算法虽然能够自动对特征进行学习,但是需要大量标记的数据,不能有效的利用未标记的训练样本.然而现实世界的多数数据是未标记的,在一定程度上限制了有监督的学习方法在链路预测领域的应用.
与传统的有监督的学习方法相比,半监督的学习方法能够减少数据样本进行标记的代价,只使用少量已标记的数据结合未标记的数据样本就可以达到较好的预测效果.半监督的学习方法适合于拥有大量隐性特征的网络,可以利用少部分的显式特征,推测隐藏信息.
特别是最近几年,随着基于图的深度学习技术的发展,复杂网络可以抽像成图的结构,通过对复杂网络结构特征的分析,可以选择基于图的半监督学习方法预测用户隐含的特征.因此,诞生了许多半监督学习进行链路预测的研究成果.下面分别进行详述:
·GCN
2017年Tomas[53]等人提出了一种基于卷积神经网络的半监督学习方法GCN,作为最近几年兴起的一种基于图结构的神经网络,因为其独特的计算能力,而受到大量学者的关注与研究.传统的深度学习模型LSTM和CNN在欧几里得空间数据上取得了不错的成绩,但是以非欧几里得空间数据进行处理却存在一定的局限性.针对该问题,研究者们引入了图论中抽象意义上的图来表示非欧几里得结构化数据,并利用图卷积网络对图数据进行处理,以深入发掘其特征和规律.
GCN能够同时对图结构和节点特征进行编码,它使用了基于一阶近似的有效逐层传播规则图上的谱卷积,是一种高效的半监督学习方法.它在图形边缘的数量上线性扩展,并学习了编码局部图结构和节点特征的隐层表示.在引文网和知识图数据集上的大量实验表明,该方法有显著的优势.因为 GCN 在网络结构的基础上,又考虑了节点的属性信息,性能比仅仅考虑结构信息的方法更佳.
2017年,Michael Schlichtkrull[54]等人提出了一种关系图卷积网络(R-GCNs)用于链路预测和实体分类.对于链路预测,采用R-GCN模型解码的性能优于直接优化因子分解模型,在链路预测方面取得了较好的效果.
2018年Harade[55]等人提出了DCNN(Dual Convolution Neural Network)方法,从图中自动、灵活地提取特征,使用端到端的方式结合内外部图结构来提取节点表示,通过在多个化学网络数据集进行预测,证实了该方法的有效性.
·LSTM
Hochreiter & Schmidhuber于1997年提出了长短期记忆网络LSTM,它是一种时间递归的神经网络,适用于预测时间序列中时间间隔和延迟时间较长的事件.它的显著特点是可以拟合时间序列数据,有效的解决梯度消失的问题.
2018年陈等人[56]提出一种图卷积网络GC-LSTM,嵌入式长短时记忆网络(LSTM),用于端到端动态网络链路预测.LSTM负责网络快照的时间特征学习,GCN用于网络快照的结构学习.目前的动态网络链路预测方法只能处理删除的链接,而GC-LSTM可以同时预测添加和删除的链接,通过大量的实验表明,GC-LSTM算法在预测精度,添加/删除链路和关键链路等方面的性能优于 CN,LINE等方法.
·GNN
图神经网络GNN是图数据最原始的半监督深度学习方法.为了编码图的结构信息,每个节点可以由低维状态向量表示.
2018年张等人[57]提出一种利用图从局部子图学习高阶启发式的新方法GNN用于解决链路预测问题,通过提取每个目标周围的局部子图链接,学习一个映射子图模式到链接存在的函数.自动学习适合当前网络的“启发式”.实验表明,通过比较各种启发式算法,潜在特征方法和网络嵌入方法,GNN显示了良好的性能.它不仅适用于链路预测领域,而且还适用于知识图补全和推荐系统.
·GAN
生成式对抗网络GAN是一种深度学习模型,它由两部分组成即生成网络G和判别网络D,G和D通过不断的博弈,使得G能够从一段随机数中生成清晰逼真的图片.GAN的优点是相比其他生成模型,它只用到了反向传播,而不需要复杂的马尔科夫链,它可以产生比其他模型更加清晰真实的样本.GAN的缺点是不适合处理离散形式的数据,比如文本.
2019年Lei[58]等人提出了一种新的非线性模型GCN-GAN模型处理具有挑战性的加权时间链路预测任务.该模型充分利用了图卷积网络GCN,长短时记忆LSTM以及GAN,利用GCN研究该算法的局部拓扑特征,处理加权动态网络中的时序链路预测问题,然后使用LSTM对每个快照进行特征描述动态网络的演化过程.为了验证模型的有效性,对四个不同的数据集进行了广泛的实验,实验结果表明在加权动态网络中该模型优于ED,SVD,NMF,GrNMF,AM-NMF和LSTM方法,具有较强的处理数据稀疏性的能力.
4)强化学习
强化学习介于监督与无监督学习之间,记录不同行动的结果并尝试使用机器的历史和经验来做出决定,每一步预测或者行为都有部分反馈信息.
2019年You[59]等人提出了一种基于图卷积网络GCPN的强化学习目标图生成模型,GCPN使用强化学习执行目标导向的模块化图生成任务,以处理不可微的目标和约束.将图生成建模为马尔可夫决策过程,将生成模型作为在图生成环境中运行的强化学习智能体,使用GCN来学习节点特征.实验结果表明,GCPN在多种图生成问题上的有效性,特别是在处理链路预测问题,有较好的性能.
2018年Cao等人提出了MolGAN[60]方法,它也采用了同样的思想,采用生成对抗网络GAN直接对图结构数据进行处理,同时与强化学习RL相结合,生成具有较高有效性的模块化图,MolGAN建议直接生成完整的图,至少缩短5倍的训练时间.
2.1.3 第三层输出层
该层为输出层,把上层处理层通过常用的链路预测算法得到的结果输出,该层输出的是一组低维的表示图形的向量.下面总结了三种输出方式,即边,子图和全图.
第一种方法输出edge 边,预测结果表明两个节点之间是否存在链接,结果适用于链路预测和知识图中的实体/关系预测.在链路预测的应用中,我们也会为每一条边来输出一个特征,并在后续工作中将其作为边的特征来进行一些分类任务.第二种方法会输出子图,包括子结构.第三种是全图,即为一个整图来输出适用于蛋白质、分子这类数量较多的小图.
2.2 复杂性分析
表1 常用预测方法复杂度分析
Table 1 Complexity analysis of common prediction methods

类别方法复杂度监督学习SVMO(n2)KNNO(n∗k)Logistic RegressionO(n∗k+k)Ensemble LearningO(n)Random ForrestO(n∗m∗d)Naïve BayesO(mn)半监督学习GCNO(|E|d2)GNNO(|E|d2)LSTMO(nm+n2+n)无监督学习DeepwalkO(d|V|log|V|)LINEO(d|E|)Struct2vecO(|V|3)GraRepO(|V||E|+d|V|2)SDNEO(dI|V|2)DNGRO(|V|2)Node2vecO(d|V|)HOPEO(d2I|E|)GraphGANO(|V|log|V|)强化学习GCPNO(d∗d)
2.3 常用链路预测方法使用的特征(见表2)
表2 常用预测方法所使用的特征分析
Table 2 Common predictive methods used in feature analysis

类别方 法网络结构属性特征文本属性特征图形(像)特征标签辅助信息角色社区中心性语义无监督的方法DeepWalk[26]√LINE[27]√√√GraRep[27]√DNGR[28]√SDNE[29]√Node2Vec[31][32][33]√√√HOPE[34]√Struct2vec[30]√√GraphGAN[35]√√监督的方法SVM[15][23][24]√√√KNN[37]√LogisticRegression[42][43][44]√√Random Forrest[16]√Ensemble learning[46][47][48]√Multilayer Perceptron[45]√Naïve Bayes[49][50]√√CNN[51][52]√√√半监督的方法GCN[53][54][55]√√√GNN[56]LSTM[57]√√√√GAN[58]√√强化学习GCPN[59]√√√MolGAN[60]√√√
2.4 开源实现
本节提供了常用链路预测方法的实现代码,提供了下载网址,对于较好的再现和比较不同的链路预测方法非常重要.编写代码是一项费时费力的工作,在写这篇综述论文的工作中,我们总结了常用链路预测方法的源代码(如表3所列),为科研人员进一步的研究提供了方便.
2.5 各种链路预测方法实验结果
当前衡量链路预测方法性能的评价指标主要包括:AUC 和Precious值,AUC值从宏观上衡量算法的准确度,AUC值大于0.5的程度衡量了算法在多大程度上比随机选择的方法精确;而Precious只考虑对排前L位的边是否预测准确,Precious值越大预测越准确.表4为常用链路预测方法的实验结果.
表3 基于学习的链路预测方法开源代码实现
Table 3 Open source implementation of link prediction method based on learning

方 法编程语言Github链接DeepWalk[26]pythonhttps://github.com/phanein/deepwalkLINE[27]pythonhttps://github.com/tangjianpku/LINEGraRep[27]pythonhttps://github.com/benedekrozemberczki/GraRepDNGR[28]matlabhttp://github.com/ShelsonCao/DNGRSDNE[29]pythonhttp://github.com/suanrong/SDNENode2vec[31][32][33]pythonhttps://github.com/adocherty/node2vec_linkpredictionHOPE[34]Chttps://github.com/eXascaleInfolab/S-HUNEGraphGAN[35]pythonhttps://github.com/hwwang55/GraphGANStruct2Vec[30]pythonhttps://github.com/leoribeiro/struc2vecLink prediction based on unsupervised method (DeepWalk,LINE,Node2vec,SDNE,Struc2vec)pythonhttps://github.com/shenweichen/GraphEmbeddingGCN[53][54][55]pythonhttps://github.com/tkipf/gcnGNN[56]pythonhttps://github.com/weihua916/powerful-gnnsGAN[58]pythonhttps://github.com/jhayes14/GANLSTM[57]matlabhttps://github.com/huashiyiqike/LSTM-MATLABLink prediction based on supervised method[36]pythonhttps://github.com/alpecli/predligGCPN[59]pythonhttps://github.com/bowenliu16/rl_graph_generationMolGAN[60]pythonhttps://github.com/nicola-decao/MolGAN
表4 各种链路预测方法的实验结果
Table 4 Experimental results of various link prediction methods

类别方 法AUC值precious无监督的方法DeepWalk0.7390.741LINE0.8140.836GraRep0.7320.035DNGR0.7040.793SDNE0.8360.912Node2Vec0.8540.845HOPE0.8810.612Struct2vec0.8100.821GraphGAN0.8590.855监督的方法SVM0.9050.924KNN0.8810.923LogisticRegression0.8300.858Random Forrest0.8330.919Ensemble learning0.9090.748Multilayer Perceptron0.8970.740Naïve Bayes0.8330.951CNN0.9580.901半监督的方法GCN0.9150.912GNN0.9700.951LSTM0.8900.873GAN0.9010.914强化学习GCPN0.9210.855MolGAN0.9010.912
2.6 各种链路预测方法应用建议
表5列出了各种链路预测方法的适用场景.
3 链路预测未来的发展方向
1)可解释性
链路预测必须是可解释的,例如,在医学领域,可解释性对于将计算机实验转化为临床应用至关重要.
2)动态与异构性
目前大多数链路预测方法都是针对静态网络,但是实际的网络是动态变化的,例如,在社交网络中,新人可以随时进入网络,现有的人也可能随时退出网络.在推荐系统中,产品可能有不同的类型,其中输入可能有不同的形式,如文本或图像.因此,应该开发新的方法来处理动态和异构网络的链路预测问题.
3)组合性
许多现有的链路预测方法可以协同工作,如何充分利用每一种方法的优势并将它们结合起来也是一个需要解决的关键问题.
4)跨学科性
链路预测已经引起了各领域专家的关注.跨学科交叉带来了机遇和挑战.领域知识是用来解决具体问题的,但是跨领域知识的集成会使得模型设计更加困难.
4 结束语
本文提供了一个全面、系统的分类方法,涵盖经典的、最新的链路预测技术,链路预测问题,它给出链路预测的通用解决方案.特别是从信息学的角度提出了链路预测分层模型的思想,把当前的链路预测技术分为:基于监督学习的技术,基于半监督学习的技术、基于无监督学习的技术和基于强化学习的技术,并对这些方法的复杂性、优缺点、适应性和输入特征进行了分析和讨论.最后,分析了未来链路预测的发展方向.
虽然,本文对当前链路预测技术进行了细致的划分,但是主要是针对静态网络.下一步工作将考虑以时间为输入特征的动态网络和异构网络的分类.
表5 各种链路预测方法的应用建议
Table 5 Suggestions on the application of various link prediction methods
类别方 法应用建议无监督的方法DeepWalk[26]它是并行的和可扩展的,适用于大型的稀疏网络,广泛应用于网络分类、链路预测和异常检测.LINE[27]它适用任意类型的大型网络,包括无向的,定向的和加权的网络GraRep[27]它的并行性,对于大型网络是非常有效的.DNGR[28]适用于加权网络,该方法给出了矩阵分解的一个新观点.SDNE[29]该方法对稀疏网络具有较好的鲁棒性.Node2Vec[31][32][33]该方法利用SVD优化来实现高效率,对扰动很健壮,适用于不同类型网络.HOPE[34]适合于有向网络,能较好的保持有向网络的非对称传递性.Struct2vec[30]该方法善于捕捉结构方面的特征,能够通过上下文学习节点的潜在表示,灵活性较好,适合于大型网络.GraphGAN[35]链路预测,节点分类和推荐系统中,效果显著,适合不同类型网络.监督的方法SVM[15][23][24]难以实现大规模的训练样本.KNN[37]该方法既适用于数值数据也适用于离散数据,对多维数据处理不好.LogisticRegression[42][43][44]该方法不能用来解决非线性问题.Random Forrest[16]适合处理高维数据.Ensemble learning[46][47][48]在处理高维稀疏数据集上的性能不如SVM.Multilayer Perceptron[45]能够学习任意非线性输入函数.Naïve Bayes[49][50]适用于大型数据集.CNN[51][52]适用于无向的、有向的、离散的或连续的节点和边缘的网络,对非欧几里得空间数据进行处理存在一定的局限性.半监督的方法GCN[53][54][55]不适合于大而密集的数据集的训练,复杂度较高.GNN[56]GNN的深度和宽度受限时,性能较差.LSTM[57]该方法适合处理高度相关的时间序列问题, 对非欧几里得空间数据进行处理存在一定的局限性.GAN[58]不适合处理离散形式的数据和样本.强化学习GCPN[59]训练数据集受限.MolGAN[60]适合小型网络.
