大规模用户参与的开放式设计决策方法
2020-05-08谈莉斌唐敦兵陈蔚芳
谈莉斌,唐敦兵,陈蔚芳,王 棋
(1.南京航空航天大学 机电学院,江苏 南京 210016; 2.安徽工业大学 机械工程学院,安徽 马鞍山 243002)
0 引言
随着消费者的需求个性化越来越强,变化越来越快,传统的以生产者为主导地位的设计方式已经不能适应当今时代的需要。企业在用户参与产品设计的过程中,可准确把握用户需求,亦可获得用户的海量创新资源。如何让用户参与到产品设计中,使其个性化需求能够真正得到满足,已成为目前研究的热点之一。
近年来,研究人员提出了很多设计方法,致力于将客户需求映射到产品模型中。如Murat[1]提出一种在概念设计阶段将客户需求映射到产品模型的方法,并用于Airbus A350设计案例中;Feng Zhou[2]提出一种用户体验设计方法;Jitesh H[3]提出一种大量设计人员协同创新的设计方法;吉祥[4]提出基于本体和粗糙集的产品设计知识推送技术;涂建伟[5]提出一种面向产品创新设计的知识检索模型与实现方法等。可以设想,这些新的产品设计方法有可能改变产品开发的模式[6]。
为了使客户更深入地融入设计过程中,一些学者提出了参与式设计的概念。Elizabeth等[7]研究了参与式设计中,传统的设计者和用户角色的变化,并指出用户将成为协同设计者,而研究人员的工作从映射客户需求转变为帮助用户完成设计方案。Bφdker S[8]研究了参与式设计所必须的技术,包括研讨环境、组织形式、支持协同设计的产品模型等。
随着互联网与其他行业的深度融合,出现了一些基于互联网的群体产品创新方法。如Thinkcycle网站[9],该网站提供了一个用户参与设计过程的网络交互平台。Jakiela等[10]提出另一种基于网络的交互方法,使大规模用户可以在线参与产品开发过程。
虽然群体创新和参与式设计越来越受到重视,但现有的大多数研究侧重于新的设计模式提出。在这些模式中,普通用户被假设为可以轻易提出产品的完整方案。事实上,对于不具有专业设计知识的普通用户来说,很难利用现有的产品设计方法完成产品方案。因为设计是一个迭代的过程,即使专业的设计工程师也不能轻易决定产品的解决方案。对于只是利用业余时间做一些有趣事情的普通用户而言,这几乎是不可能完成的。因此,如何实现普通用户在设计过程中的真正参与,是一个亟待解决的问题。
在互联网交互环境下,用户参与产品设计过程更加容易,这将导致参与设计的用户可以达到较大规模。当大规模用户直接参与产品设计过程时,用户与用户之间的交流规模也会急剧增大。用户间交互的效率将直接影响产品设计周期长短,因此需要一种用户交互辅助机制,使得用户间实现高效交互。此外,由于参与设计用户数量的庞大,用户与用户间交互、用户方案的群体决策等过程,需要通过数据化手段实现计算机辅助管理。
为解决上述问题,本文提出一种基于大规模用户参与的开放式设计方法。用户可以通过互联网随时参与设计过程,并且不必提出完整方案。设计平台将大量用户初始的模糊化、碎片化的方案数字化,建立用户相似度量空间,并根据相似空间寻找某一用户的相似用户。通过相似用户的交互反应,如接受、拒绝或改进,校正用户在相似空间中的向量参数,同时帮助用户逐渐完善自己的方案。对于最终不完整的用户方案,通过协同过滤实现预测,并补充完整。对于处理后最终完整的大量用户方案,通过粗糙集理论,实现产品方案的群体决策。由于整体设计过程的数字化,相似度空间建立、用户推荐迭代、完整方案预测、群体决策构成的整体设计决策过程,都可以由计算机按照对应算法自动执行,因此可以实现大规模用户的参与。最后,以某洗衣机的具体设计过程,证明了该方法的可行性。
1 基于相似度推荐的用户交互过程
1.1 用户方案的数字化
随着自然语言处理(Natural Language Processing,NLP)技术的发展[11-12],在网络交互环境中,用户以文字、语音等形式提交的设计方案,可以被处理为一组数据。
在某个抽油烟机的参与设计案例中,其中4个用户初步提的文字方案如下:
(1)用户A:“烹饪是件无聊的事情,我想增加一个听音乐的解决方案。但是抽油烟机一般都很吵,我想让它静一点。清洁也是一件无聊的事情,我想增加自清洁的功能。”
(2)用户B:“噪音是无法忍受的。如果抽油烟机声音可以很小,我就能在做饭的时候听一些最喜欢的歌曲。”用户C:“以前的旧油烟机,总是有一些油烟溢出。我希望新的油烟机能加强吸力。”
(3)用户D:“清洁抽油烟机是一项繁琐的工作,如果有自清洁的功能,肯定令人惊喜。”
根据DS Zhu等[13]的研究,本文将用户的需求强度分为5个等级:喜欢、同意、中立、忍受、厌恶。本文按照5个等级将对应的用户需求强度数字化为:2,1,0,-1,-2。根据用户语气的强烈程度,以及用户主动提出或被动接受等特征,赋予每个用户子方案对应的值。从而,上述4个用户的方案可以数字化为表1。
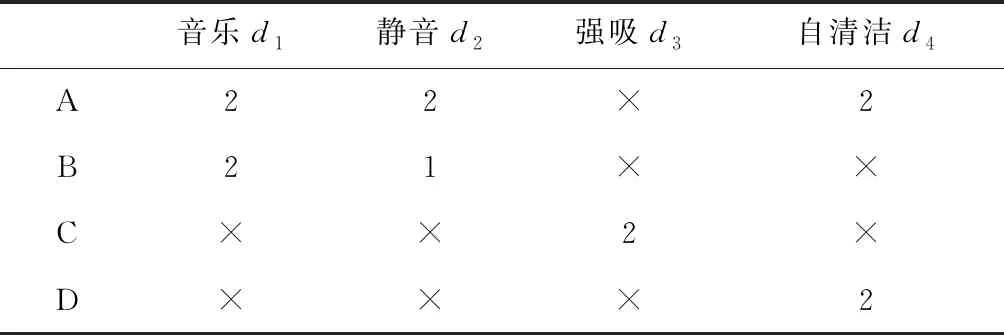
表1 4位用户方案数字化结果
表1中:4位用户数字化后的方案构成一个4维的向量空间。每位用户的初始方案在该向量空间下的坐标分别为M1,M2,M3,M4:
(1)
(2)
(3)
(4)
1.2 用户方案相似程度衡量
根据4位用户提交的文本,用户在该产品局部方案中有相似的意见,但意见接近程度不完全相同。Valcarce D等[14]论述了3种衡量用户之间相似程度的计算方法,分别是欧式距离、皮尔逊相关系数和余弦相似度。由于余弦相似度的计算对误差不敏感,在文本相似性计算中有大量应用,因此本文采用余弦相似度作为计算两用户方案相似程度的方法。式(5)定义了相似度S来度量两个参与者之间的相似程度:
-1≤s≤1。
(5)
式中:S的值趋于1,则表示两用户观点趋于接近;相反地,S趋于-1,表示两用户观点趋于对立。
用户A和用户B在音乐和降噪观点的相似程度计算如下:
ua=(2,2)T,
(6)
ub=(2,1)T,
(7)
(8)
用户A和用户B的余弦相似度为0.949,表明两用户在音乐和降噪观点上非常接近。结合文本内容判断,证明了余弦相似度可正确表征两用户间的观点相似程度。
1.3 基于相似度推荐的迭代过程
研究发现,用户更容易接受观点相近用户的其他观点[15]。因此,可以推荐用户A方案中自清洁的功能给用户B。用户B收到推荐后,可以选择接受、忽略或拒绝,从而增加了用户B关于自清洁功能的观点值。此时,用户B在相似空间中由2维向量变为3维向量。根据用户B新生成的3维向量,再次计算用户B与具有相同维度的其他用户之间的相似程度。选择相似度较高的其他用户方案中,用户B未提出的功能推荐给用户B。推广到一般的情况,相似推荐的过程如下:①计算用户余弦相似度;②按照相似度值确定候选集,并排序产生推荐集;③为用户产生推荐。相似推荐为迭代过程,持续至用户结束参与设计。
推荐过程的结束条件与产品设计过程管理有关,如用户参与周期结束、用户方案完整度达到阈值、用户对相似推荐长时间无回应等均可设置为推荐结束的条件。因此,设计平台停止某用户相似推荐的条件与设计目标相关、且并不唯一,需要根据某产品具体设计过程设置相应的推荐结束算法。
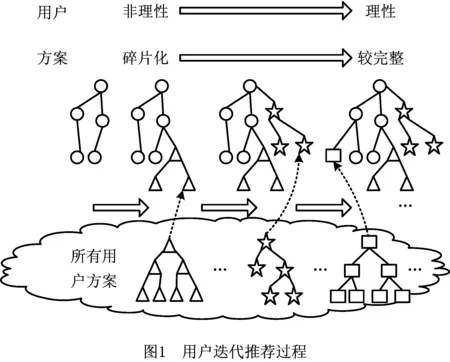
在用户参与的初始阶段,用户提出的方案一般为产品总体方案的某一部分。因此,用户数据具有极端稀疏性。这导致两用户之间初始相似度的值,并不能正确反应两用户关于产品总体方案的观点相似性。通过多次迭代的相似推荐与用户反馈,用户关于产品方案的认知由非理性转向逐渐理性。用户方案也由初始的碎片化逐渐完整,如图1所示。此时,用户方案较为准确地映射了用户关于产品的观点,置信度较高。且在此过程中,用户只需对推荐的其他方案做出反馈,不需要投入大量的时间和精力整理方案,因此便于用户利用业余时间参与产品设计。
2 用户方案的数据处理
在迭代推荐与反馈后,大多数参与用户完成了自己的方案。由于非强制性特征,这些方案一般来说不是100%完整的。此外,不同用户方案中,关于产品的侧重点可能不同,观点也可能对立。如何将这些方案统一为被用户接受的一个或多个产品,是亟待解决的问题。
2.1 用户方案的矩阵表达
在本文中,用户总体方案以式(9)中矩阵的形式表达。每一个行向量代表一个用户的最终提交方案,其中行向量的第一个元素为用户编号,矩阵行的个数为所有参与用户的数量m。矩阵每一列代表一个产品子方案,列的个数为所有不同子方案个数n加1。wij(-2≤wij≤2)的值代表用户i关于子方案j的观点。因此,所有用户方案用m×(n+1)阶矩阵V*表达。
(9)
矩阵中“*”表示行向量对应的用户未对该子方案发表意见。
2.2 欠关注子方案的舍弃
用户提出的方案中,一些子方案项被大多数用户忽略,表现为在矩阵V*中一些列向量有较多的“*”出现,或较多用户关于该项的观点值接近于0。考虑到产品的设计与生产成本,此类子方案需被舍弃。因此,本文定义子方案的权重衡量参数ξ*如下:
(10)
式中:h(0≤h≤m)为子方案对应的列向量中,具有准确值的wij的个数。当用户方案中,“*”出现的次数越多,或wij的值越接近于0时,ξ*的值越小。而“*”的出现和wij的值接近于0都说明了用户对该子方案不关注。在设计过程中,可以定义ξ*的阈值,当*ξj小于该阈值时,矩阵j列对应的子方案全部舍弃。
2.3 不确定子方案的预测
欠关注子方案舍弃后,仍有一些wij的值未确定。造成不确定值出现的原因很多,但并不等于用户对该子方案没有观点值。在之前的迭代交互过程中,随着用户方案维度的增加,用户观点的完整度逐渐提高,从而用户方案对用户真实观点的映射准确率逐渐提高。此时,利用多维度已知值对少维度不确定值预测具有较高的置信度。本文提出一种预测缺失子方案值计算方法,如式(11)所示:
(11)
式中:x为用户序列号,Six为用户i和用户x之间的余弦相似度,Six的定义见式(5)。相似的意见(Six>0)和相反的意见(Six<0)都会影响用户x的观点。因此,所有用户关于该子方案的平均值,可以近似预测用户x的缺失子方案值wxj(*)。
经过对低权重子方案的舍弃,以及缺失子方案值的预测,得到了一个完整的方案数值矩阵,该矩阵包含大多数用户感兴趣的子方案。
3 产品最终方案的群体决策
所有用户关于产品最终方案存在对立观点,表现为产品的某个子方案存在正反两方面的观点值。此时,为了满足用户需求,需要设计两种型号产品。当有两个子方案存在正反值时,则需要4种型号产品。以此类推,最终需要设计的产品型号数量巨大。从设计与制造成本角度考虑,显然是不可实现的。因此首先需要评估每一个子方案中,支持与反对观点的分布,以决定是否有必要分解为正反两种子方案。其次需要评估每一个子方案在总方案中的权重,通过权重排序决定产品子方案分解的取舍。
目前,有一些广泛应用的群体决策方法,大多基于经典的层次分析法(Analytic Hierarchy Process, AHP)[16]。如J. M. Moreno-Jiménez[17]提出一致性共识矩阵,使用层次分析法寻求群体决策中的一致性。此类方法多适用于中小决策群体,当决策者数量较多,需要计算机自动处理时,这些方法就无法适用。
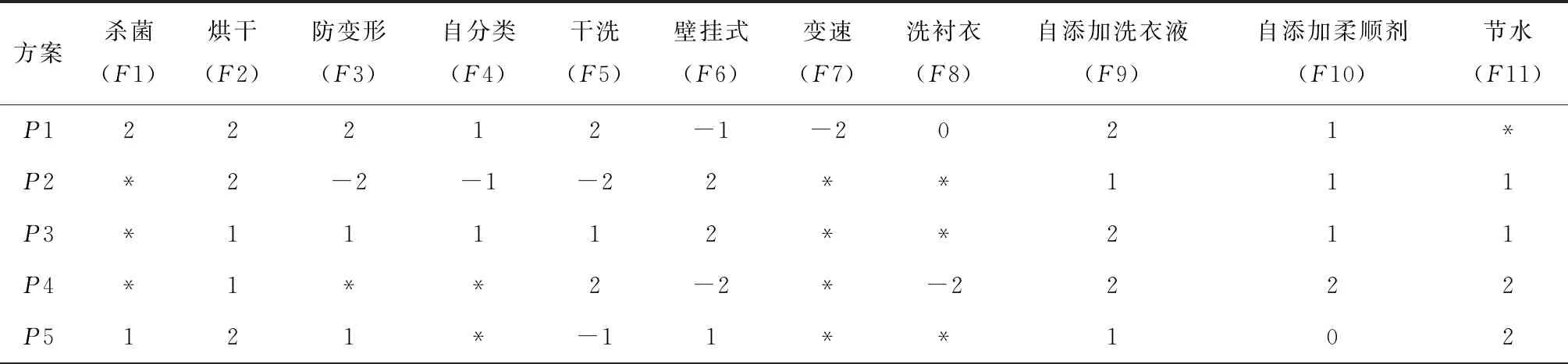
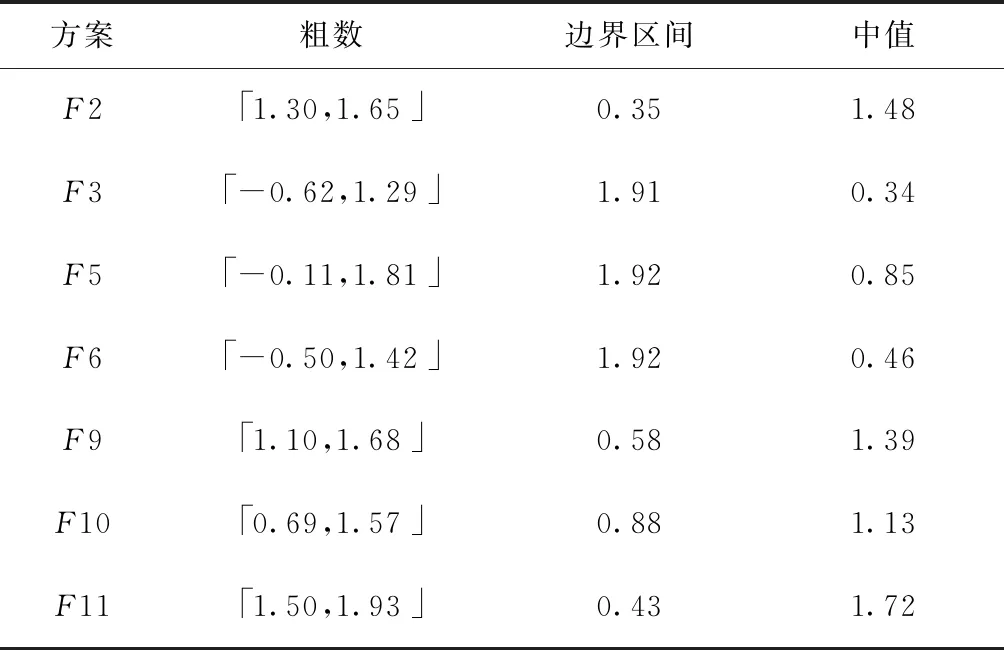
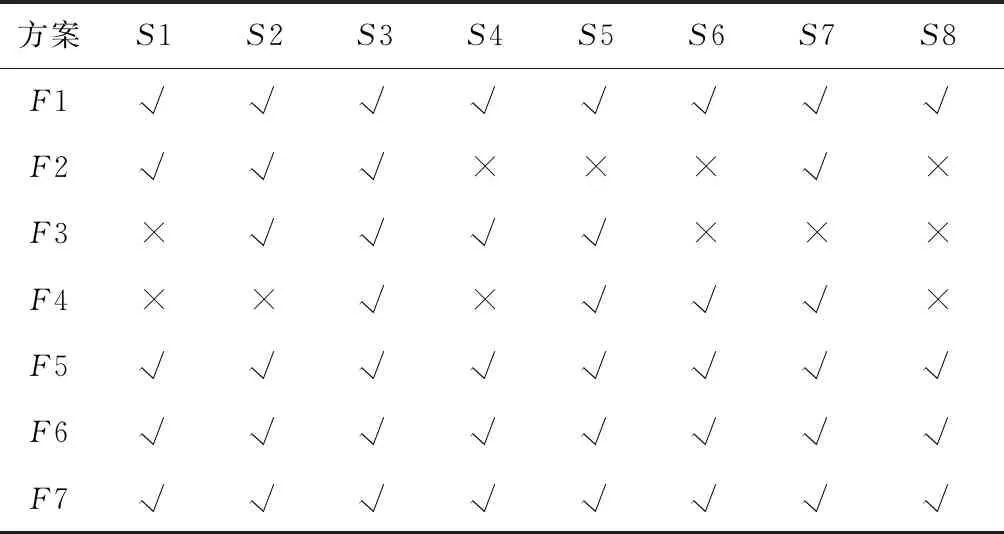
本文类似的研究中,Pawlak[18]提出了经典的粗糙集理论来解决分类问题中的不一致问题。Lian-Yin Zhai[19]提出了基于粗糙集理论的近似概念,可以扩展处理不一致信息的归类问题,如下所述。设U是一个包含在信息表中注册的所有对象的域,Y是U的任意对象。域U中定义了一组n个元素的类,R={C1,C2,…,Cn}。如果该类以C1 (12) 式中Ci的上近似可表示为: (13) Ci的边界区间为: Bnd(Ci)=∪{Y∈U/R(Y)≠Ci} ={Y∈U/R(Y)>Ci}∪{Y∈U/R(Y) (14) Ci的下近似限为: (15) Ci的上近似限为: (16) 式中:ML为下近似限包含的对象数,MU为上近似限包含的对象数。 因此,类Ci可以用由其下近似限和上近似限定义的粗数RN表示: (17) 对应的粗数边界大小定义为: (18) 文献[19]提出的方法可以实现数域中类的权重计算与排序,与本文应用有类似之处,可以通过借鉴该方法提出本文群体决策的解决办法。 在形如矩阵(9)的产品最终方案数值矩阵中,一个列向量代表某一个子方案的所有用户观点集合。本文将文献[19]提出的粗数定义推广到矩阵领域。设F是一个列向量,F中定义了一组n个数的类(C1,C2,…,Cn)。列向量F的下限和上限可以定义为: (19) (20) 其中ki为数组F中Ci的数量。 则列向量F的粗数定义如下: (21) 式中F的边界区间定义如下: (22) F的边界区间大小表征了F中数值的聚集或分散程度,在本文中即为用户方案的统一或对立程度。F的边界区间越大,对立程度越高;F的边界区间越小,则方案的统一程度就越高。 产品最终方案数值矩阵中,存在多个列向量Fi(0 (23) 式中MR(F)的值越大,则该列向量权重越大。从而在决策是否将某个子方案分解时,优先等级越高。 最终,通过产品决策矩阵中列向量的粗数边界区间与粗数平均值的定义,实现了产品子方案的优先级排序,与子方案正反观点分布的评估。 根据之前的粗数及相关参数计算,总结产品总体方案的群体决策过程如下: (1)计算产品每个子方案(式(9)中矩阵列向量)的粗数、边界区间、粗数中值。 1)确定子方案中的类; 5)计算子方案的粗数RN(F)、边界区间RBnd(F)、粗数中值MR(F)。 (2)根据每个子方案的粗数中值,将每个子方案的重要性排序。 (3)根据每个子方案的边界区间,确定子方案中用户观点的对立程度。 (4)在设计产品系列时,优先将重要性高、有对立观点的子方案分解。 本文的决策过程均基于数据化的用户方案,因此设计平台可以通过编制对应逻辑与运算程序,实现全程计算机处理,从而使大规模用户的群体决策具有可实现性。 本文以洗衣机设计为例说明了在线参与式设计的应用。随着消费者的个性化和多样化,消费者希望在传统洗衣机中加入自己喜爱的特色,而不是选择市场上现有的机型。一组25至30岁的志愿者,通过在线设计平台参与了洗衣机设计过程。通过将用户初始方案数字化后,只有12名用户明确提出了自己的解决方案,如表2所示。表2中:P代表参与设计的用户,F代表子方案。 表2 洗衣机用户初始方案 遍历计算用户之间相似度,并将与该用户相似度最高的另一用户其他子方案推荐至该用户。如用户P1和P6之间关于F9和F10都有提出子方案,则用户P1和P6在以F9和F10为坐标的2维相似空间可数字化为向量: 根据式(5)可计算P1和P6在该相似空间下的相似度: 同样地,可以计算用户P1和其他用户在不同相似空间的相似度,并产生相似推荐集。根据推荐集,优先推荐相似度最高的用户其他子方案至用户P1,根据P1的反馈帮助用户完善自己的子方案。在经过迭代相似推荐阶段之后,12位参与者的最终解决方案如表3所示。 根据式(10),可以计算表3中每个子方案的取舍权重,以F1为例: 表3 洗衣机用户最终方案 续表3 表4 子方案取舍权重 舍弃后的产品子方案中,有一些用户未提供的不确定项。这些不确定项可以通过式(11)的计算方法实现预测。以用户P6关于子方案F2(烘干)的预测为例。 (24) 式中:S16=0,S26=0.82,S36=0.50,S46=0.67,S56=0.82,S76=0.35,S86=0.56,S10,6=0,S11,6=0.63,S12,6=0.48。则w62的最终值为 0.67×1+0.82×2+0.35×1+0.56×2+ 0×2+0.63×2+0.48×2)=0.81。 对其他不确定项进行类似的预测计算后,形成最终的决策矩阵V: V= 决策矩阵V中,每个子方案的优先排序可以通过计算对应的粗数实现。以F2为例,F2中有4个类,“0.81”、“0.97”、“1”和“2”。类“1”的粗数计算如下: 则子方案F2的下近似限为: =(0.839 7×1+0.947 6×1+0.962 9×3+ 1.567 9×7)/12=1.30; F2的上近似限为: =(1.634 1×1+1.634 1×1+1.7×3+ 2×7)/12=1.65; F2的粗数为: F2的边界区间为: =1.65-1.30=0.35; F2的粗数中值为: 其他产品子方案作相似计算后,汇总为表5。 表5 子方案取舍权重 边界区间的大小表征了用户群体关于该子方案项的观点统一程度。区间小于1,表示用户关于该子方案的观点趋于统一;相反地,大于1表示趋于对立。表4中:F2、F9、F10、F11边界区间小于1,表示该4项子方案用户观点集中;F3、F5、F6大于1,表示用户观点在该3项子方案中分歧较大。如果需要满足大多数用户的需求,则需要将该3项子方案分别分解为2个不同的子方案,从而得出系列产品整体方案。 粗数的中值用来衡量子方案的重要程度。当设计目标为有限总体方案数量时,不能将所有子方案都分解,优先分解最重要的子方案。根据表5数据,只有F3、F5、F6需要分解,分解优先顺序为F5>F6>F3。 根据边界区间和中值,可以确定产品的最终方案。如果设计目标是只需要一种产品,由于粗数中值均大于零,因此最终产品应该包含子方案为{F2,F3,F5,F6,F9,F10,F11}。如果设计目标为两种产品,根据分解优先顺序,两种产品的子方案为{F2,F3,F5,F6,F9,F10,F11}和{F2,F3,F6,F9,F10,F11}。当设计目标是尽可能满足所有用户需求时,产品系列与对应的子方案见表6。表6中:S为最终产品系列,√表示子方案被保留,×表示子方案被删除。 表6 产品系列与子方案 本文提出一种大规模用户参与的开放式设计方法,首先解决了普通用户难以真正参与产品设计的问题;同时针对大规模用户的群体产品决策提出了解决方法。通过用户初始的碎片化方案提出,以及随后的相似推荐与反馈,帮助用户形成较完整的方案,该方案准确映射了用户需求。基于粗糙集理论,提出了大规模用户方案的群体决策方法,实现产品方案的群体决策。从推荐推荐到决策的整体设计过程,计算机都可按照对应算法自动执行,因此可以实现大规模用户的参与。最后,以洗衣机设计实例,展示了完整的设计过程。 本文重点关注开放式用户大规模参与设计的设计过程实现,对于具体环节采用的方法并未深入研究。如用户子方案数值化的判断算法、相似度的计算方法、群体决策方法、相关阈值的确定等。在具体设计过程中,详细方法需要针对性地讨论。此外,本文中用户方案以数列形式映射,未来将结合DSM(design structure matrix)理论[20]、FBS(function behavior structure)理论[21]等,研究更科学的用户方案映射形式。3.1 产品子方案正反分布的评估
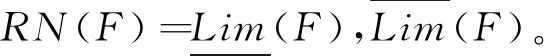
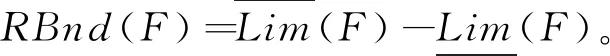
3.2 产品子方案认可度的衡量
3.3 产品方案群体决策过程
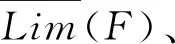
4 产品实例研究

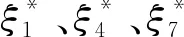


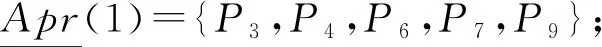
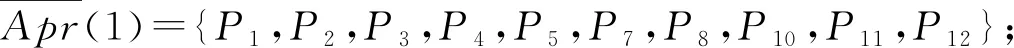
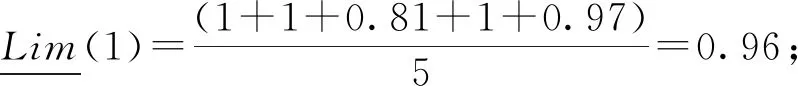
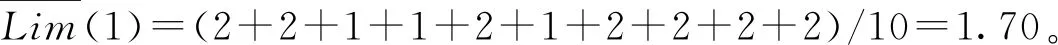


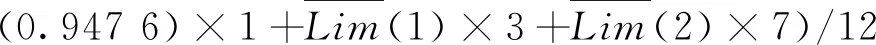
5 结束语
