基于LeNet-5的卷积神经图像识别算法
2020-05-06张万征胡志坤李小龙
张万征,胡志坤,李小龙
(智洋创新科技股份有限公司,山东 淄博 255086)
1 引 言
近年来,各大知名汽车公司都在积极开发先进的驾驶辅助系统(ADAS)[1],并试图将ADAS系统商业化,甚至作为将来自动驾驶的基础。ADAS系统不仅配备了车道保持辅助系统(LKAS)[2],还需要配备具有各种道路交通识别标志的交通标志识别(TSR)系统。而根据欧洲NCAP评级标准,当汽车速度超过设定的速度阈值时,汽车应该能够向驾驶员发出警告。尽管当前应用广泛的数字地图数据也可以知道限速值,但这种方法仅限于地图数据中的道路。因此,在大多数汽车驾驶情况下,需要基于视觉的交通标志识别系统,要求TSR系统需要能识别各种交通标志,以获得更详细的道路信息[3]。近年来,交通标志识别越来越受到国内外研究者的关注。比如清华大学、西安交通大学等高校和科研院所对自动驾驶车辆和交通标志识别进行了大量研究。2008年,国家自然科学基金启动了视听信息认知计算项目,无人驾驶中与车辆相关的可视化计算是其重要的研究内容之一。交通标志图像采集通常来自于驾驶车辆上的摄像设备[4],因此交通标志识别系统在实际应用中需要具有良好的实时性和准确性。自然场景中光照、天气、遮挡和拍摄角度的变化增加了交通标志识别的难度。目前,交通标志分类识别的主要算法有统计分类、模板匹配、稀疏编码、神经网络和遗传算法。其中,基于卷积神经网络的交通标志识别算法以其自学习能力受到国内外研究人员的高度重视。特别是在深度学习结构中,卷积神经网络(CNN)在图像分类问题中得到了广泛的应用。CNN是一种使用小的子区域(接收域)的多层感知器。接收域被平铺以覆盖整个输入图像,然后通过共享相同的权重和偏移量生成特征映射。因此,深度学习可以减少神经网络学习所需的参数数目,提高学习效率。
本文利用LeNet-5对国内各种交通标志进行训练,最后以实时应用为目标,选择合适的轻量级检测算法提取交通标志感兴趣区域,再通过训练模型对交通标志进行识别。
2 基于LeNet-5的交通标志识别算法
2.1 提取交通标志候选
包括本文使用的LeNet-5模型[5]在内,几乎所有用于图像分类的CNN模型都是以物体图像作为输入数据的。通常在图像识别过程中会先对图像进行预处理,选择性搜索常被用作目标检测的预处理。它通过计算不同颜色空间和纹理的相似性来搜索可能包含对象的区域。目的是在健壮性和速度之间进行权衡[6]。上述算法尽管可以取得较好的检测效果,但时间复杂度太高,无法满足实时计算的要求。因此,本文提出了一种简单的区域分割方法,即HSV(Hue,Saturation,Value)阈值运算,色调值的范围设置为0~180,其他值的范围为0~255。在实际应用场景中,交通标志具有鲜明的色彩特征,如人行横道标志是蓝色的,停车标志是红色的。因此,简单的HSV阈值法基本能提取出大部分交通标志的区域。表1显示了包含“停车”和“人行横道”标志的图像的色调、饱和度和值分布。一般来说,停车标志的色调较高(大于160),人行横道标志的色调在100左右。饱和度的值也取决于道路标志本身。本文选择了5个阈值操作的最小和最大H、S和V数。分别采用了停车、急转弯、慢行、人行横道、减速标志提取算法,通过下面的方程得到HSV的最小数和最大数。
Hmin=μH-ασH,Hmax=μH+ασH
Smin=μS-βσS,Smax=μS+βσS
Vmin=μV-γσV,Vmax=μV+γσV,
(1)
式(1)中,μ是非零像素的平均值和标准偏差。α、β和γ是H、S和V范围边缘的决定因素。一般取α为1.1,β和γ设置为2.5。最大值和最小值的选择都反映了足够的饱和度和值的裕度,因为它们都会随着光照条件的变化而发生变化。特别是在停止标志中,由于本文使用HSV二次曲线颜色空间模型,所以色调的最小值和最大值被设置为启发式的。红色的色调在170~180和0~10之间。
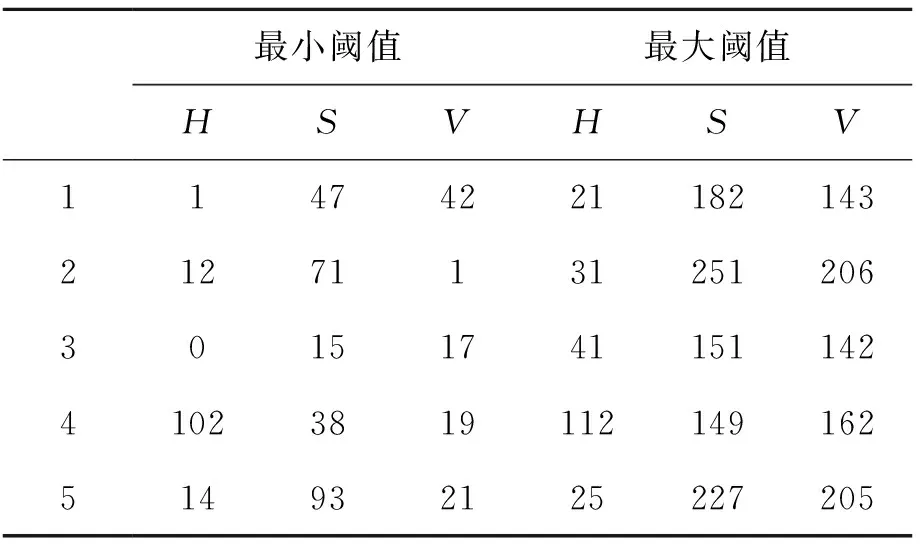
表1 HSV最大值最小值Tab.1 HSV maximum and minimum
限速标志的形状是一般圆形的,与其他物体的形状有区别。因此,Hough变换用于检测输入图像中的圆形[7]。在Hough变换算法之前,实现了高斯滤波(标准差为1.2的5×5核)和Canny边缘检测算法[8-11]。图1显示了前摄像头图像的区域检测的结果。检测阶段排除了尺寸过大或过小或长宽比过大(长矩形)的区域。

图1 交通标志检测结果Fig.1 Traffic sign test results
2.2 LeNet-5分类
CNN架构将每个检测到区域输入到CNN模型中。图像的大小调整为100×100像素,还具有rgb像素。换言之,CNN的输入数据具有100×100×3维。输出层设计为20个节点,其中18个为所选交通标志的类别数,另一个为其他类型标志的类别数,最后1个节点显示假阳性类输出。图2显示所选交通标志的图像。本文算法基于LeNet-5模型,并将一些节点进行修改。在两个卷积层中,使用5×5大小的卷积核,它将输入图像与步长1进行计算。在每个卷积层之后,max pooling层使用2×2核和步长2对数据进行重采样并减小数据大小。

图2 识别的主要标志Fig.2 Main identification signs
本文通过自动驾驶汽车挡风板上的4摄像头采集了驾驶视频。首先,只训练由简单仿射变换产生的正样本,经过多次检测,收集到了假阳性分类结果。本文将它们设为阴性样本。最后,将训练数据与25 000个正样本和78 000个负样本混合,图3显示了样本的示例。


图3 样本示例Fig.3 Sample example
2.3 算法核心流程
LeNet-5网络只为数字识别设计,传统的LeNet-5网络只包含10个输出[12]。考虑到本文有18个类型而不是10个,本文使用了与输出层中轻微修改的LeNet-5架构。网络的第一层是可训练的特征extactor,具有特定的约束,例如本地连接和权重共享。卷积层应用卷积核(5×5),子采样层应用核(2×2)。输出中的分类层是完全连接的mlp。这些层使用提取的局部特征对输入图像进行分类。本文采用C++、CUDA 7.5环境开发了TSR系统。本文使用Caffe[13-14]深度学习框架,其中包括模块化和高效的计算机操作。训练使用的电脑规格为i7-6820 CPU,titan x显卡,12 GB GPU内存。
3 实 验
本文的测试在一段校园道路进行。由于安全原因,校园内交通标志种类繁多,适合对TSR系统进行测试。在先前的现场测试中,输出节点阈值被调整为0.95,即如果输入的裁剪图像中的a类节点的输出值为0.95,则TSR系统确定该图像为a类。在可观察范围内,道路上有16个交通标志。所有的交通标志在驾驶过程中都被成功识别。图4显示了从输入帧到输出分类结果的整个过程。输入图像来自现场测试视频。如图4的底图所示,人行横道和停车交通标志被划分为安装良好的边界框。在本文的实时处理计算机上,运行平均每秒帧数约为16.9 Hz。
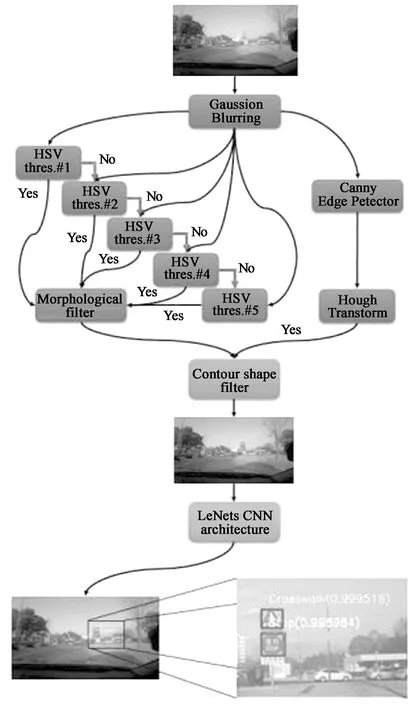
图4 系统流程图及识别结果Fig.4 System flow chart and identification results
4 结 论
在基于视觉的ADAS领域中,大多数研究都是利用静态算法进行的,传统的LeNet-5可以高效地进行数字识别,但是由于其模型较为复杂且检测区域过多,因此计算速度较慢,在很多情况下无法满足TSR系统中对实时判断的要求,本文提出了改进的LeNet-5卷积神经网络结构对18种交通标志图像进行识别。在检测阶段,采用基于颜色的轻量级分割算法和Hough变换算法提取交通标志的目标区域,再利用LeNet-5对交通标志进行分类识别。最后通过在校园道路中的交通标志进行实验证明,本文算法可以快速识别出道路中的交通标志,具有稳定高效、实时性好的优势。
