基于神经网络与卡尔曼滤波的手部实时追踪方法
2020-05-06曾公任姚剑敏林志贤郭太良
曾公任,姚剑敏*,严 群,林志贤,郭太良,林 畅
(1. 平板显示技术国家地方联合工程实验室,福州大学物理与信息工程学院,福建 福州 350108;2. 晋江市博感电子科技有限公司, 福建 晋江362200)
1 引 言
手部追踪技术是指对视频序列检测是否存在检测目标手,并能对目标进行持续跟踪。近年来,智能人机交互技术不断发展[1],手部追踪技术是其中重要的一环。手部追踪技术能够应用在监控技术上,检测人们是否进行误操作。动态的手势识别包含3个步骤:手部检测、手部追踪和手势识别,其中手部追踪是中间环节,手部追踪的不准确可能会导致最后的手势识别的错误。而在视频监控中,手部追踪能够检测到人们手部的运动轨迹,判断用户是否进行必要或异常的操作,大大减少人工检测的成本和时间。
在进行手部追踪前,首先要进行手部检测。要将手从视频中分辨出来,传统的方法有:基于YcbCr颜色空间的手部检测[2]、基于前景提取的手部检测[3]、基于模型匹配的手部检测、基于C-means的手部检测[4]。基于YcbCr颜色空间的手部检测,在不同光照条件下对肤色检测有较好的效果,但该方法在场景中有相似色调、手臂暴露在摄像头下或者检测肤色不在检测区间内的情况下会出现误检、多检测和漏检情况,并且YcbCr颜色空间的手势检测的方法耗费时间多,不适用于实时系统。基于模型匹配的手部检测,是寻找图像子区域中与目标模板相似度最大的区域,该方法适用于目标做刚体运动或检测目标形变较小的情况,当检测目标发生形变与目标模板相差较大时检测效果不佳。基于前景提取的手部检测,是将前景检测目标和背景分离开的方法,若检测目标在场景中长时间没有运动,可能会将检测目标检测为背景,并且该方法对阴影响应敏感,会将视频中阴影的部分检测为检测目标。由于传统方法中的种种问题,这里采用神经网络算法进行手部检测。近年来,深度学习的方法大量应用在图像领域,神经网络算法已经应用在目标检测。对于特定的检测目标,能够达到较高检测正确率,并且,近年提出的网络模型相较于早年提出的模型在运算速度上有较大提高,已经能够满足实时的目标检测。
对于手部追踪,由于手势非刚体,在手部的运动过程中常常会发生手部变化。当前大多数动态手势追踪方法有Camshift[5]、粒子滤波[6]、相关滤波算法、kalman滤波[7]等方法。Camshift算法是以颜色分布图为基础进行的目标跟踪技术,是对Meanshift算法的改进,当目标发生较大形变或者遇到遮挡后,会出现目标丢失或者追踪框位置偏移等问题,并且Camshift没有对目标的运动进行估计,在背景颜色复杂的情况下也会出现目标丢失的情况。粒子滤波算法是基于门特卡洛仿真的最优回归贝叶斯滤波算法,适用于非线性非高斯模型。但是每次进行估计与更新都需要从当前系统状态中取出带权粒子,计算的过程复杂,虽然每次估计的正确率比较高,但是耗费时间多,不适用于实时较高的系统。相关滤波算法利用快速傅里叶变换进行滤波器训练和响应图计算,具有较好的实时性,但是对目标的光照、形变较为敏感,不适用于手部形变较大的情况。Kalman滤波适用于线性高斯模型,由预测和修正两部分组成。由于神经算法在不同光照和手部形变的情况下都有较好的检测效果,所以对于Kalman滤波有较好的修正效果。并且Kalman滤波算法相较于粒子滤波算法其计算量较小,适用于实时系统。
2 系统概述
图1展示了本次设计系统的整体流程图。首先对视频输入进行预处理,并将每一帧的画面进行神经网络目标检测,在前几帧时追踪器为空,检测到的目标都是新目标,为每个出现的目标生成一个追踪器,对于后面输入的每帧图像,先进行神经网络目标检测,再将目标信息输入追踪器。如果该目标存在追踪器,对该目标进行追踪,并对追踪器中的参数进行修正;如果该目标不存在对应的追踪器,则生成对应的追踪器。

图1 整体流程图Fig.1 Overall flow chart
3 基于SSD的手部目标检测
3.1 神经网络算法介绍
近年来,深度神经网络在计算视觉领域发挥了重大作用。深度神经网络已经使用在图像分割、物体检测、语义分割等领域。对于目标检测的算法,目前有Faster-RCNN[8]、YOLO[9-11]和SSD[12]等。Faster-RCNN的检测精度较高,但是检测时间较长。YOLO检测速度较快,但是检测精度较低,并且对多尺度变化的目标检测效果不理想。SSD网络在精度与处理速度上达到了相对的平衡,并且SSD对于不同尺度的目标检测效果较好。本文的检测目标会出现在场景中的任意位置,并且检测目标的尺度也会发生变化,因而在此选择SSD为检测网络。
3.2 SSD卷积神经网络
SSD卷积神经网络的结构框图如图2所示,由图中能够看出,SSD卷积神经网络由特征提取网络与检测识别网络组成。
特征提取网络是基于VGG-16网络[13]修改得到的,VGG-16网络结构参数如表1所示。可以看出VGG-16网络由13个卷积层、15个激活函数层、5个最大池化层、3个全连接层、2个Dropout层和1个Softmax层组成,并且输入的图像尺寸为224×224。SSD的特征提取网络对VGG-16网络进行3方面的修改:首先,将VGG-16的两个全连接层Fc6和Fc7修改为卷积层Conv6和Conv7,并对Conv6卷积引入空洞卷积[14],能够在不改变特征图尺寸的情况下增大感受野;然后将Max Pool5的池化窗口尺寸从2×2修改为3×3,滑动步长由2变为1;最后,去掉Dropout层、全连接层和Softmax分类层。特征提取网络的主要作用是提取不同尺寸的卷积特征图,能更好地检测和识别目标并能提高不同尺度目标的检测与识别效果。
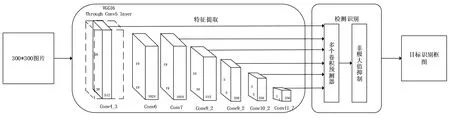
图2 SSD卷积神经网络的结构框图Fig.2 Block diagram of the SSD convolutional neural network
检测识别网络运用独立的卷积预测器进行处理,预测输入图像中目标的类别以及目标所在图像中的位置,并给出目标的置信度得分以及目标的边界框位置信息,然后综合这些在多尺度特征图上获得的目标类别以及位置的预测信息,执行非极大值抑制(Non-Maxium Suppression, NMS)算法,去除冗余的目标预测边界框,从而得到最终的检测与识别结果。

表1 VGG-16网络结构参数Tab.1 VGG-16 network structure parameters
SSD卷积神经网络采用多任务学习策略,同时进行目标检测和目标识别的任务,所以SSD网络的损失函数包含两部分:置信损失函数和定位损失函数。损失函数的定义如式(1)所示:
(1)
其中:α为置信损失函数和定位损失函数的权重,N为真实框的数量,c为置信度,l为预测框,g为真实框,Lconf(x,c)为置信损失函数,其函数表达式定义如式(2)、(3)所示:
(2)
(3)

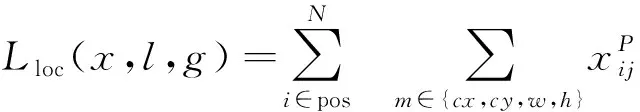
(4)
(5)
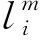
3.3 训练策略
神经网络参数庞大,从头开始训练需要大量的时间,采用迁移学习的方法,能够减少学习时间。使用Tensorflow提供的ssd_mobilenet_v1_coo模型作为训练的起点,采用EgoHand的数据集[15]进行训练。进行20万步训练,总损失在2.5处停止训练。训练完成后,当重叠度(IOU)取值为0.5时,手部检测器的平均精确率(mAP)值为0.96,达到了较好的检测效果。
4 手部跟踪
4.1 卡尔曼滤波追踪
卡尔曼滤波是建立一个线性高斯模型,能够根据前面时刻的信息推算出后一时刻各个状态的可能性。在手部跟踪中,根据前面时刻手部的位置与运动速度等信息推算出下一个时刻各个位置出现的可能性,将下一时刻检测出的手部位置进行可能性判断,推测出上一时刻画面中手部位置,对目标进行跟踪。
卡尔曼滤波器的状态方程如式(6)所示,卡尔曼滤波器的观测方程如式(7)所示:
Zt=AZt-1+B+ε,
(6)
Xt=CZt-1+D+δ,
(7)
式(6)中:Zt是t时刻的状态向量,ε表示高斯分布的噪声,由式(6)能够看出,t-1时刻的状态向量与t时刻的状态线性呈线性关系。式(7)中Xt是t时刻的观测向量,t表示高斯分布的噪声,由公式能够看出,t时刻的观测量可以由t-1时刻的状态向量线性变换得到。
根据公式(6)与公式(7),能够将手部跟踪问题变为卡尔曼滤波器递推计算的过程,卡尔曼滤波计算的过程分为两部分:“预测”与“修正”。预测过程:根据当前时刻预测下一时刻的状态向量。修正过程:根据最新的观测量对卡尔曼滤波器中的参数信息进行调整,修正上次预测中出现的误差,以便更好地进行下一次预测。
4.2 hand ReID手部重检测算法
对于多目标追踪,只用卡尔曼滤波追踪算法存在局限性,当追踪目标被遮挡或消失在视野中,再次出现时,往往不会继续保持追踪,会认为是新目标重新追踪。因此,引入了基于深度学习的多目标跟踪算法。手部重检测算法是基于行人重检测(person ReID)算法[16]。行人重检测算法主要应用于跨摄像头场景下行人识别与检索,其中一种检测方法是局部特征学习方法,局部特征检测方法将人的图像从上到下进行三等分,输入模型,动态调整不同区域在图像中的占比,将3个部分输入到 网络,提取特征,最后将3个分信息结合在一起进行估计。
由于手部追踪时没有人体那么多的特征,因此将行人重检测算法进行简化,去除将图像三等分的步骤,将图像输入到网络,提取特征,将特征存储起来。当卡尔曼滤波没有找到目标时,将其特征与检测目标的特征进行匈牙利匹配,找到先前跟踪目标或检测到新目标进入画面。
5 实验结果与分析
本文在Intel core i7 6700 16G内存的个人计算机上进行实验。采用google提供的TensorFlow机器学习算法库,在windows平台,使用python语言进行开发设计。
将带有手部的视频图像输入程序中,程序能够跟踪手部连续100帧的运动轨迹,手部运动过程在没有发生遮挡情况下的整个轨迹跟踪过程如图3所示。

图3 单手部跟踪Fig.3 One-hand tracking
图3(a)为视频中450帧时刻画面,其中图3(b)和(c)分别为第480帧和第500帧时刻的画面,图3(d)为第530帧时刻的画面。从图3中可以看出在复杂背景下即使手部发生较大形变也能够保持手部的正确跟踪。
两个手部发生交叉遮挡的情况如图4所示。

图4 两个手部发生交叉遮挡情况Fig.4 Cross-occlusion of two hands
图4(a)为视频中230帧时刻画面,图4(b)和(c)分别为第260帧和第290帧时刻的画面,图4(d)为第320帧时刻的画面。从图中可看出遮挡手的id都为101,在两个手部发生交叉遮挡后再次出现时能够继续保持正确跟踪。
测试视频1共有4 140帧画面,手部发生漏检或误检的帧数为212帧,其误检查率为5.12%,基本在能够接受的范围。由于使用两个追踪方法共同处理,手部丢失后的下一帧还能继续保持前面的跟踪。在跟踪处理过程中,实时处理平均帧数为21.212 f/s,最高帧数为24.327 f/s,最低帧数为18.964 f/s,基本能够满足手部跟踪的实时性。
该系统在追踪的实时性上得到了较好效果,与传统的手部跟踪方法对比有更好的鲁棒性和稳定性,并且对于目标交叉、目标遮挡带来的目标丢失的情况具有很好的处理效果。轨迹跟踪方法的实现,为后面研究运动手势检测提供了前提条件。
6 结 论
设计了一种基于神经网络与卡尔曼滤波的手部跟踪系统。该系统通过神经网络进行手部检测,卡尔曼滤波进行目标跟踪,hand ReID进行目标的重跟踪来对手部的非刚体运动进行跟踪,最后将手部运动的路径显示出来。实验分析证明,该方法手部的误检率为5.12%,并且在重新检测到目标后还能继续保持跟踪,每秒能够处理20张画面,基本满足实时跟踪手部的要求。
