基于空时注意力网络的面部表情识别
2020-04-29冯晓毅黄东崔少星王坤伟
冯晓毅 黄东 崔少星 王坤伟
摘要:基于视频序列的面部表情识别问题主要有两个特点:空时性和显著性。近年来,许多研究人员利用卷积神经网络、循环神经网络、三维卷积神经网络等深度学习方法处理该问题的空时特性。但是,面部表情的显著性问题却往往被忽视。随着注意力机制在深度学习网络中的应用发展,其能够有效地解决各类任务中的显著性问题。该文将空时注意力机制应用到面部表情识别中,使得深度网络更多地关注空时特征中的显著性。具体地,该文将空间注意力模块嵌入到卷积网络中,以使空域特征更加关注对表情识别重要的区域,将时间注意力模块嵌入到门控循环单元(gated recurrent units,GRU)后,使得时域特征更加关注信息丰富的视频帧。在RECOLA情感数据库上的实验表明,与一般的深度模型相比,该文的深度空时注意力网络显著提高了面部表情识别的性能。
关键词:深度学习;空时方法;注意力机制;面部表情识别
中图分类号:TP391.41
DOI:10.16152/j.cnki.xdxbzr.2020-03-002
Spatial-temporal attention network forfacial expression recognition
FENG Xiaoyi1, HUANG DongCUI Shaoxing WANG Kunwei
Abstract: Facial expression recognition (FER) based on video sequences has two main characteristics: spatio-temporal and significance. Of late, many researchers combined
convolutional neural networks (CNNs), recurrent neural networks (RNNs) and 3D CNN to address the spatio-temporal characteristics. However, few works focus on the salient features of this issue. Meanwhile, with the development of the attention mechanism for deep learning, its effectiveness in the salient problem has attracted the interest of researchers. In this paper, we introduce the attention mechanism into FER, by which our deep network pays more attention to the salient extraction of spatial-temporal features. Specifically, a spatial attention module is inserted into the CNN networks to make the spatial feature extraction more objectively. A temporal attention module is inserted into the output of the gated recurrent units (GRU) at each step of a sequence, so that the temporal features pay more attention to the informative frames. We validate our approach on the RECOLA emotion database. A comparison of the results with attention and without attention shows that our deep attention network improves the performance compared to the general deep model.
Key words: deep learning; spatial-temporal method; attention mechanism; facial expression recognition
面部表情是人类语言的一部分,通常,它是一种用于传达情绪的生理和心理反应[1-2]。面部表情识别(facial expression recognition,FER)的研究可以应用于人机交互、情感分析和心理健康评估等多个领域[3]。近几十年来,这项技术引起了计算机科学家和心理学家的极大兴趣,该问题也由最开始的人脸基本表情的分类逐步演变为现在更加细致的对表情强度的分析。特别是深度学习技术的发展使得模式识别可以去探索更为细致的变化,所以,当前的研究多是趋向于后一类强度分析问题[4]。
此外,由于面部表情的研究可受益于视频序列中连续帧的时间相关性,因此,基于视频的面部表情识别得到了更加广泛的关注。在该问题中,面部表情呈现出两个特点:空时性和显著性[5]。空时性即面部表情在空间和时间上具有动态变化的特点,而显著性则是在空间上人脸只有部分区域对表情识别是起作用的,在时间上只有部分的图像帧才具有表情信息。因此,面部表情识别问题存在着两个主要的挑战,一个是如何描述空时特征,另一个是如何体现视频序列中重要信息帧的重要区域。
随着深度学习技术的发展,许多深度学习方法被提出来应对这些挑战。循環神经网络(recurrent neural networks,RNN)因其可以从连续数据中获取动态信息,在该领域得到了广泛的使用[6-9]。卷积神经网络(convolutional neural networks,CNN)也应用到该问题中,例如三维卷积神经网络(3D convolutional neural networks,C3D)[10],被用于动态面部表情识别以获取空时动态特征[11-15]。与此同时,一些研究人员认为CNN可以提取更有效的空域特征,因此,他们将CNN和RNN结合起来以生成面部表情的空时特征[6,12,16-19]。对于FER的第二个挑战,即显著性问题,一些研究人员利用注意力机制来处理。注意力模块根据CNN中的特征图谱自动计算注意力权重[5,20-22]。然而,这些方法只关注了静态图像的问题,并没有提供动态面部表情识别的解决方案。
据此,本文针对面部表情识别的这两个挑战提出了一个深度空时注意力网络,该网络包括空域子网络和时域子网络,在两个子网络中分别嵌入相应的注意力模块,使得CNN提取空域特征时,更加关注与表情识别最为相关的区域,RNN提取时间特征时,更专注信息量更大的图像帧。
本文的主要贡献如下:
1)将空间注意力模块添加到空域子网络的卷积过程中,并将全连接层修改为回归任务。首先,训练空域子网络,使其完成FER的任务,然后,可视化空间注意力模块所学习到的结果,得到与面部表情识别最相关的区域。
2)训练好的空域子网络作为特征提取器提取空域特征,将每一个时间步骤的空域特征输入到GRU中,得到时域动态特征。随后,将GRU的输出经过时间注意力模块,获得每一个时间步骤的权重。利用注意力权重对时域动态特征进行加权平均,得到具有空时注意力的动态特征。
3)在RECOLA表情数据库进行了大量的实验验证。从实验结果可以看出,本文提出的深度空时注意力网络对比于其他方法具有明显优势。
1 相关的研究工作
1.1 面部表情识别方法
近年来,由于深度学习的出现,越来越多的深度网络被应用于基于视频的面部表情识别,模型的性能表现也越来越好。在这些工作中,他们采取相应的网络框架提取面部表情识别中涉及到的空时动态特征。
由于RNN能够探索连续数据之间的动态变化关系,因此,它被用于表情识别的各种任务中。在2015年,自然场景的情感识别(EmotiW)挑战赛中引入了RNN就获得了比仅使用CNN网络更好的结果[6]。Zhang等人提出了一种基于部件的分层双向循环神经网络[9],以获取视频序列中的动态面部表情信息。在Yan等人的工作中,双向递归神经网络的框架被用来捕获面部纹理的动态变化[7]。在最近的研究中,Yu等人提出了一个嵌套长期短期记忆(long short-term memory,LSTM)模型[8],该模型由T-LSTM模型和C-LSTM两个子模型组成。其中,T-LSTM模型从时间上对所学的特征进行建模,C-LSTM将所有T-LSTM的输出集成在一起,以便对网络的中间层进行多层级编码。
与RNN相比,CNN非常适合应用于计算机视觉的任务,因此,它的衍生物C3D被广泛应用到相应的研究中来。在Liu等人的工作中,C3D与可变形的面部动作约束条件结合在一起,以表示动态运动信息[14]。Jung等人应用了在时间轴上不共享权值的3D卷积核,提出了一种深度时间表观分析网络,每个卷积核的重要性可以随时间的变化而变化[13]。Iman等人在生成的数据集中训练了一个深层C3D,以对面部表情进行分类[11]。另外,Fan等人以后融合的方式将C3D和RNN结合在一起解决了16年EmotiW挑战赛所提出的问题[12]。Zhao等人提出了一种3D CNN架构,可从面部视频序列中同时学习静态和动态特征,并从光流序列中提取高层次的动态特征[15]。
與此同时,还有一些研究人员致力于利用CNN和RNN的组合来探究面部表情识别的问题。Donahue等人设计了一个空时的深度模型,该模型将CNN与LSTM相结合来解决不同视觉任务中输入视频长度不同的问题[16]。Kim等人在CNN和RNN的组合框架中,使用了不同的强度状态(起始,起始到峰值,峰值,峰值到结束和结束),以及五个损失函数(表情分类损失,同类表情类内变化损失,同类表情强度分类损失、表观特征变化损失和表情空间特征连续性损失)来对表情的各个强度状态进行编码,通过优化这些损失函数来训练网络[18]。Jain等人提出了基于多角度最佳模式的深度学习方法,以纠正光照突然变化所带来的影响,使用CNN-LSTM对面部表情进行预测[17]。Rodriguez等人通过将CNN与LSTM相结合来完成疼痛表情识别的任务,使用了预先训练的VGG网络来微调疼痛表情数据库,随后,LSTM对VGG网络的输出进行了分类[19]。
1.2 注意力机制的相关研究
到目前为止,注意力机制已经成功地应用于许多领域,包括图像描述、机器翻译、特征图转换等方面[23]。其中,在图像描述和机器翻译的应用中,所提出的模型都是基于编码器和解码器的结构,而在其他应用中因为没有解码器的存在,往往通过特征图转换来学习注意力权重。
关于面部表情识别,也有一些工作致力于注意力机制的发展。例如,Barros等人提出了一个可以关注于表情变化和表情识别的深度模型[5]。该模型由一个深层的网络组成,在网络中利用CNN来定位复杂场景中的情感表现。为了解决面部表情识别的问题,Sun等人提出了CNN注意力模型[22],在CNN提取的特征图上学习注意力权重,然后利用注意力特征对表情进行分类,以提高网络性能。Li等人提出了具有注意力机制的CNN网络用于面部表情识别[20],该网络可专注于面部最具判别性的区域,其描述了两种注意力类型,一种是基于局部的注意力,另一种是基于全局和局部的注意力,实验结果表明,所提出的方法在多个面部表情数据集上的识别精度均得到了提升。Minaee等人采用了空间转换网络模块,通过该模块,网络可以专注于与表情最为相关的区域,从而改善实验结果[21]。对于基于面部表情的年龄估计问题,Pei等人提出了一个端到端的注意力模型,从CNN特征图中学习注意力权重,在LSTM处理信息的过程中,学习了每一时间步骤的注意力权重,然后,对输出特征向量进行加权平均,用以进行后续的回归任务[24]。
越来越多的计算机视觉研究倾向于探索注意力机制的应用。在现阶段的面部表情识别研究中,也有像上文所提到一些研究开始专注于特定区域,他们试图在空间维度上选取相关性的区域[25-26],但还没有面部表情识别的相关工作同时涉及到空时上的注意力。故基于以上分析,本文提出基于一种空时注意力网络来同时解决面部表情识别中的空时特性和显著特性的问题。
2 基于空时注意力网络的面部表情识别
2.1 整体网络框架
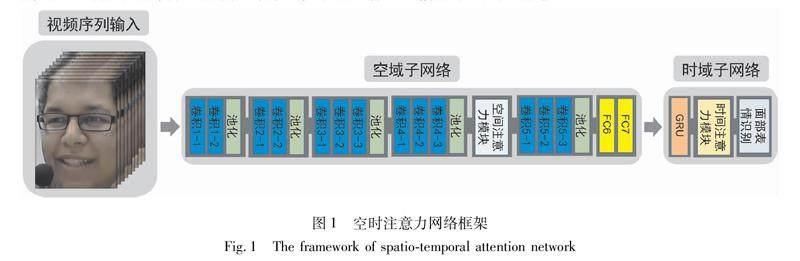
本文提出了一种用于视频面部表情识别的深度空时注意力网络。为了解决视频序列中表情识别的空时性和显著性的问题,采用了空时注意力机制,该机制可使网络在空域中专注于与表情最相关的区域,在时域中更加关注信息量丰富的视频帧。
图1为本文所提空时注意力网络的整体框架,该网络主要包括两个子网络:空域子网络和时域子网络。整体框架将视频序列作为输入,将这些图像输入到空域子网络中,并表示为特征图谱。在空域子网络中间,存在一个空间注意力模块,该模块可以使网络更多地关注与面部表情识别最为相关的区域。随后,将全连接网络(FC)的特征输入到时域子网络部分。在该部分中,将每个时间步骤的特征输入到GRU单元以生成时域动态特征。这些特征通过时间注意力模块使网络专注于信息丰富的视频帧。
2.2 空间注意力模块
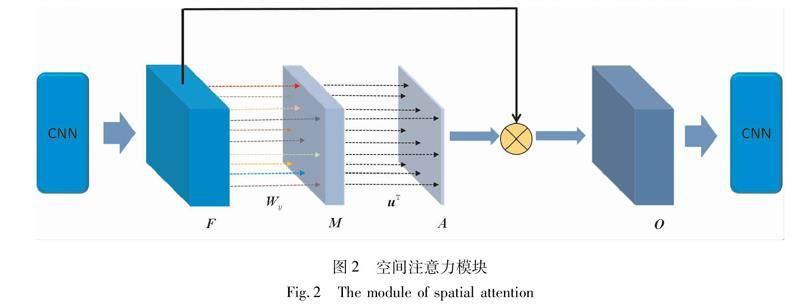
空间注意力模块的作用是自动评估图像中每个区域的重要性以及每个区域与目标任务的相关性。在空域子网络中,该模块由嵌入在特征图谱之后的卷积滤波器实现,它可以根据目标任务计算出每个区域的重要性,其结构如图2所示。
假设第L层卷积层的输出特征图谱尺寸为W×H×C,也即C个尺寸大小为W×H的特征图谱。这些特征输入到空间注意力模块得到注意力矩阵A。A
的尺寸大小也为W×H,其中的元素Aij表示特征向量Fij的重要性权重。Fij为卷积层输出特征图谱在(i,j)位置的特征向量,故|Fij|=C。每个特征向量都对应原图的一个接受域,因此,在卷尺层后嵌入空间注意力模块能够让卷积网络自动地改变各个接受域的重要性权重大小。
根据Pei等人[24]在注意力机制方面的研究,本文也采用了类似的空间索引的注意力机制。从图2中可以看出,注意力权重矩阵A由两层全连接网络计算所得到,第一层中对于每个输入的特征向量采用个性化的权值参数,第二层则采用共享的权值参数。因此,各个位置的注意力权重Aij可由式(1)得到:
Aij=σ(uTtanh(WijFij+bij)+c)。(1)
其中,Wij∈Rd×C和bij∈Rd×1分别是第一层的参数矩阵和偏置,u∈Rd×1和c分别是第二层的参数矩阵和偏置。在第二层的输出之后添加sigmoid函数σ,使得注意力权重矩阵的取值都位于[0,1]。注意力权重矩阵A通过与特征图谱F进行元素级的相乘操作控制下一层卷积层的信息流入,得到空间注意力模块的最终输出O。
本文在空间注意力模块中的第一层使用个性化的权值参数,第二层使用共享的权值参数,是因为该模块中第一层网络被用来捕捉局部的详细信息,第二层网络被用来感知全局信息的变化。在Xu等人使用两层都是权值共享的网络研究图像分类[27]。而本文的任务则是表情识别,这就需要网络能够学习到纹理上的细微变化,如果采用文献[27]的方法,学习得到的注意力权重就会偏向模糊[24],因此,本文采用空间索引的空间注意力机制。
2.3 时间注意力模块
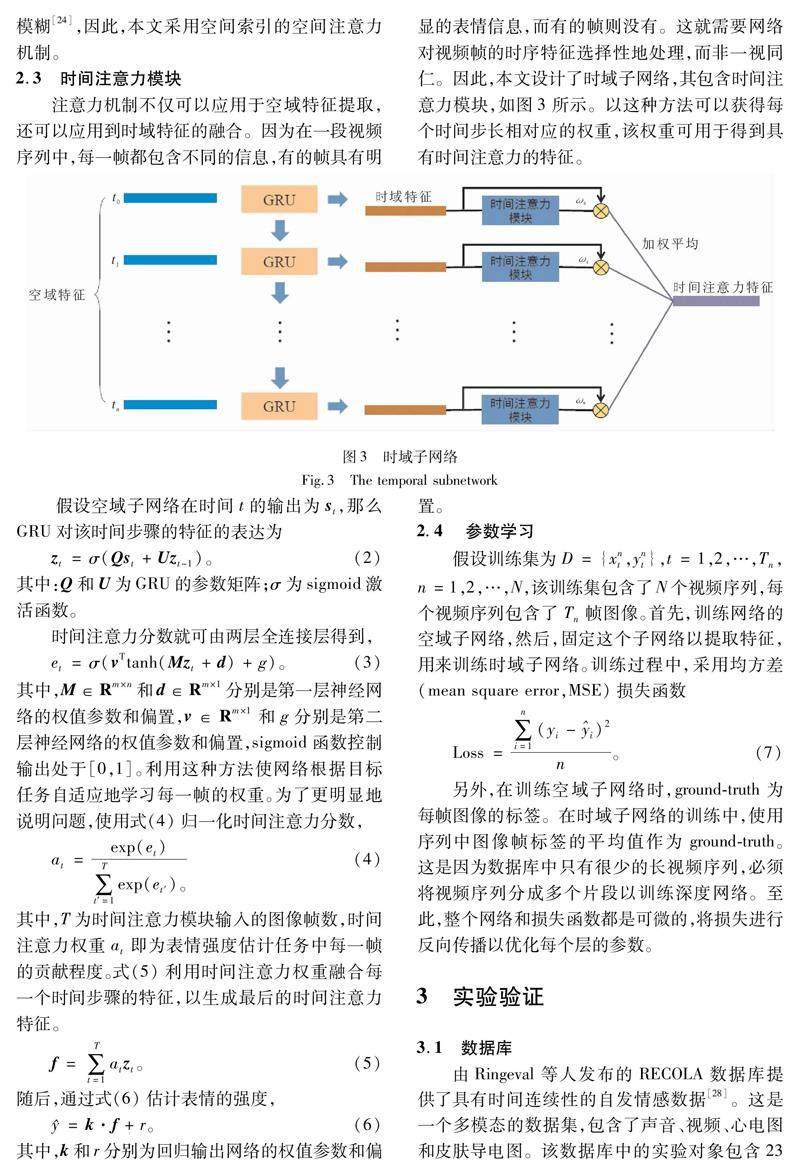
注意力机制不仅可以应用于空域特征提取,还可以应用到时域特征的融合。因为在一段视频序列中,每一帧都包含不同的信息,有的帧具有明显的表情信息,而有的帧则没有。这就需要网络对视频帧的时序特征选择性地处理,而非一视同仁。因此,本文设计了时域子網络,其包含时间注意力模块,如图3所示。以这种方法可以获得每个时间步长相对应的权重,该权重可用于得到具有时间注意力的特征。
假设空域子网络在时间t的输出为st,那么GRU对该时间步骤的特征的表达为
另外,在训练空域子网络时,ground-truth为每帧图像的标签。在时域子网络的训练中,使用序列中图像帧标签的平均值作为ground-truth。这是因为数据库中只有很少的长视频序列,必须将视频序列分成多个片段以训练深度网络。至此,整个网络和损失函数都是可微的,将损失进行反向传播以优化每个层的参数。
3 实验验证
3.1 数据库
由Ringeval等人发布的RECOLA数据库提供了具有时间连续性的自发情感数据[28]。这是一个多模态的数据集,包含了声音、视频、心电图和皮肤导电图。该数据库中的实验对象包含23个参与者,总长度为9.5 h,其中每5 min进行一次标注,录制的内容是一个执行协作任务的视频会议。参与者中有17名法国人,3名德国人以及3名意大利人。视频数据包含两个部分:9个视频序列用于训练,9个视频序列用于验证。视频序列中的每一帧都有两个标签:价分数和唤醒。由于价分数与视频之间的相关性很高,因此,在本文实验中采用了价分数的注释。
3.2 实验设置
从图1能够看出,空域子网络的主体部分是一个VGG-16的结构。这是因为本次实验的数据库是中等尺寸的数据库,如果使用较浅的网络,实验结果达不到最优,如果使用较深的网络则很容易陷入局部最小点,导致过拟合的发生,故使用一个表情数据库FER2013[29]上的预训练模型来初始化网络参数将会极大提高网络的实验表现和收敛速度。
由于空域子网络是用来估计静态图像的表情强度的,故除了嵌入空间注意力模块,将VGG-16最后一层的神经元个数修改为1,对应表情强度估计的任务。故第一步是先训练空域子网络,遍历整个数据库,随后移除最后一层,将整个空域子网络视作一个特征提取器。本次实验中将VGG-16的FC7层的特征作为一幅图像的特征。
在时域子网络中,因为普通的循环神经网络极易发生梯度爆炸,故采取LSTM和GRU来替换普通的循环神经网络。并且从Chung等人的研究中可知,GRU网络更加简单有效[30],因此,在本次实验的时域部分采用GRU网络。
本实验使用随机梯度下降(stochastic gradient descent,SGD)方法优化模型。动量设置为0.9,权重衰减设置为0.000 5。初始的学习率设置为0.000 1,随后,从第15次循环开始,每5次循环学习率降为原来的0.9倍。在所有的训练步骤中,批尺寸大小为8,全连接网络以0.5的概率随机临时删除神经元。通过将图像尺寸变为256*256,然后随机裁剪为224*224来实现数据增强。另外,因为标注的数值较为接近,故将该数值进行归一化到[0,1]。参照Tzirakis等人的预处理流程[31],本次实验对标签还进行了以下处理:①时间移动,因为标注和实际的表情强度存在着大约2s的时间偏差,故对标签进行时间移动使得表情和实际相一致。②均值移动,因为预测和目标存在均值差异,通过对预测值进行均值移动实现更优的实验表现。
根据以往在RECOLA数据库的工作[31-34],本文在实验中采用一致性相关系数(concordance correlation coefficient,CCC)作为评价标准。
3.3 空间注意力模块性能评估
首先,测试空间注意力模块在空域子网络中不同位置所呈现的不同结果。本实验一共测试了5个在池化层之后的不同位置,结果如图4所示,从结果能够看出,注意力模块放置于前3个位置,这些模型的性能甚至不如没有注意力的模型,原因是对于表情强度估计的任务而言,低级的特征图谱上注意力图的接受域太小,无法完全包含重要的区域。当注意力模块应用于最后一个位置时,结果会略有下降,这是因为在高级特征图谱上注意力图的接受域太宽,以至于无法关注重要信息的区域。从结果来看,最佳位置是位置4。
此外,实验为了显示所学到的注意力图的有效性,将注意力图应用到输入图像上,结果如图5所示,第一行是原始的图像,第二行为注意力图应用到原图上的结果。从结果来看,空间注意力模块的确能够使得卷积网络更加关注眼睛、鼻子以及嘴部的区域,这些区域最能反应表情强度。
3.4 时间注意力模块性能评估
本节将测试时间注意力模块的作用,实验共分为两组:包含时间注意力模块的和不包含时间注意力模块的。表1为不同时间长度下包含时间注意力模块和不包含时间注意力模块的CCC结果对比,从实验结果可以看出,在特定的时间步骤长度上,时间注意力方法要明显优于普通方法的。
为了显示时间注意力模块的作用,本实验可视化了该模块所学到的时间步骤权重,结果如图6所示,可以看出,时间注意力模块使得网络自动地调整某些重要的图像帧的权重,特征表达更加准确。
此外,由于本文整个网络的训练方式为逐步训练,即先训练空域子网络,然后固定该子网络,再训练时域子网络,因此,将整个网络进行了端对端的联合训练,实验对比结果如图7所示。从图7能够看出,端对端的联合训练方式不会让网络实验表现更好,这是因为实验数据库是中等尺寸的数据库,同时更新空域子网络部分和时域子网络部分将会对训练产生阻碍。
3.5 与现有方法的比较
表2为本文所提出方法与现有方法的对比结果。从表2能够看出,本文所提出的空时注意力方法对比现有方法具有明显的优势。
4 结 论
本文针对面部表情估计中的空时显著性问题,提出了一种深度空时注意力的方法。在空域子网络部分,在卷积过程中嵌入空间注意力模块,使得空间子网络能够更加关注与面部表情识别最为相关的区域。空域子网络被训练之后,将其视作特征提取器,提取每一幅图像的空域特征。在时域子网络采用GRU作为主体部分,在每一时间步骤中,将GRU的输出作为时间注意力模块的输入,以获得时域上每一帧图像的权重。通过注意力权重对每个时间步骤的输出时域特征进行加权平均,生成最终的时域注意力特征,随后,网络将使用该特征根据标签进行回归拟合。在RECOLA数据库上的实验表明,该方法取得了较好的效果,实验中可视化了空间注意力权重,从而显示了与面部表情强度估计最为相关的区域,时间注意力权重也呈现了与标签大致相同的趋势。与现有的方法相比,本文所提出的深度空时注意力网络具有明显的优势。
参考文献:
[1]SCHLOSBERG H. Three dimensions of emotion[J]. Psychological Review,1954,61(2):81-88.
[2]TIAN Y I, KANADE T, COHN J F. Recognizing action units for facial expression analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(2):97-115.
[3]彭先霖,张海曦,胡琦瑶.基于多任务深度卷积神经网络的人脸/面瘫表情识别方法[J].西北大学学报(自然科學版),2019,49(2):22-27.
PENG X L, ZHANG H X, HU Q Y. Facial/parelysis expression recognition based on multitask learning of deep convolution neural network[J].Journal of Northwest University(Natural Science Edition), 2019, 49(2):22-27.
[4]张璟.基于卷积神经网络的人脸表情识别研究[J].电脑知识与技术, 2019, 15(16):213-215.
ZHANG J. Research on face expression recognition based on convolutional neural network[J].Computer Knowledge and Technology,2019,15(16):213-215.
[5]BARROS P, PARISI G I, WEBER C, et al. Emotion-modulated attention improves expression recognition: A deep learning model[J]. Neurocomputing, 2017, 253:104-114.
[6]KAHOU S E, MICHALSKI V, KONDA K, et al. Recurrent neural networks for emotion recognition in video[C]∥Proceedings of the 2015 ACM International Conference on Multimodal Interaction. ACM,2015:467-474.
[7]YAN J, ZHENG W, ZHEN C, et al. Multi-clue fusion for emotion recognition in the wild[C]∥Proceedings of the 18th ACM International Conference on Multimodal Interaction. ACM, 2016:458-463.
[8]YU Z, LIU G, LIU Q, et al. Spatio-temporal convolutional features with nested LSTM for facial expression recognition[J]. Neurocomputing, 2018, 317:50-57.
[9]ZHANG K, HUANG Y, DU Y, et al. Facial expression recognition based on deep evolutional spatial-temporal networks[J]. IEEE Transactions on Image Processing, 2017, 26(9):4193-4203.
[10]TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]∥Proceedings of the IEEE International Conference on Computer Vision. IEEE, 2015:4489-4497.
[11]ABBASNEJAD I, SRIDHARAN S, NGUYEN D, et al. Using synthetic data to improve facial expression analysis with 3D convolutional networks[C]∥2017 IEEE International Conference on Computer Vision Workshop. IEEE, 2017:1609-1618.
[12]FAN Y, LU X, LI D, et al. Video-based emotion recognition using CNN-RNN and C3D hybrid networks[C]∥Proceedings of the 18th ACM International Conference on Multimodal Interaction. ACM, 2016:445-450.
[13]JUNG H, LEE S, YIM J, et al. Joint fine-tuning in deep neural networks for facial expression recognition[C]∥2015 IEEE International Conference on Computer Vision. IEEE, 2015:2983-2991.
[14]LIU M, LI S, SHAN S, et al. Deeply learning deformable facial action parts model for dynamic expression analysis[C]∥Asian Conference on Computer Vision. Springer,2014:143-157.
[15]ZHAO J, MAO X, ZHANG J.Learning deep facial expression features from image and optical flow sequences using 3D CNN[J]. Visual Computer, 2018, 34(1):1461-1475.
[16]DONAHUE J, HENDRICKS L A, ROHRBACH M, et al. Long-term recurrent convolutional networks for visual recognition and description[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4):677-691.
[17]JAIN D K, ZHANG Z, HUANG K Q, et al. Multi angle optimal pattern-based deep learning for automatic facial expression recognition[J]. Pattern Recognition Letters, 2017:1-9.
[18]KIM D H, BADDAR W J, JANG J, et al. Multi-objective based spatio-temporal feature representation learning robust to expression intensity variations for facial expression recognition[J]. IEEE Transactions on Affective Computing, 2017, 10(2):223-236.
[19]RODRIGUEZ P, CUCURULL G, GONZLEZ J, et al. Deep pain: Exploiting long short-term memory networks for facial expression classification[J]. IEEE Transactions on Cybernetics, 2017(99):1-11.
[20]LI Y, ZENG J, SHAN S, et al. Occlusion aware facial expression recognition using cnn with attention mechanism[J]. IEEE Transactions on Image Processing, 2018, 28(5):2439-2450.
[21]MINAEE S, ABDOLRASHIDI A. Deep-emotion: Facial expression recognition using attentional convolutional network[EB/OL]. 2019: arXiv:1902.01019[cs.CV].https://arxiv.org/abs/1902.01019.
[22]SUN W, ZHAO H, JIN Z. A visual attention based ROI detection method for facial expression recognition[J].Neurocomputing, 2018, 296:12-22.
[23]谢飞,穆昱,管子玉,等.基于具有空间注意力机制的Mask R-CNN的口腔白斑分割[J].西北大学学报(自然科学版), 2020, 50(1):9-15.
XIE F, MU Y, GUAN Z Y, et al. Oral leukoplakia (OLK) segmentation baesd on Mask R-CNN with spatial attention mechanism[J].Journal of Northwest University(Natural Science Edition), 2020, 50(1):9-15.
[24]PEI W, DIBEKLIOLU H, BALTRUAITIS T, et al. Attended end-to-end architecture for age estimation from facial expression videos[J]. IEEE Transactions on Image Processing, 2019, 29:1972-1984.
[25]LI W, ABTAHI F, ZHU Z. Action unit detection with region adaptation, multi-labeling learning and optimal temporal fusing[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2017:1841-1850.
[26]ZHAO K, CHU W S, ZHANG H. Deep region and multi-label learning for facial action unit detection[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2016:3391-3399.
[27]XU K, BA J, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]∥International Conference on Machine Learning, 2015:2048-2057.
[28]RINGEVAL F, SONDEREGGER A, SAUER J, et al. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions[C]∥2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. IEEE, 2013:1-8.
[29]GOODFELLOW I J, ERHAN D, CARRIER P L, et al. Neural Information Processing[M].Berlin:Springer,2013:117-124.
[30]CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[EB/OL].2014: arXiv:1412.3555[cs.NE].https://arxiv.org/abs/1412.3555.
[31]TZIRAKIS P, TRIGEORGIS G, NICOLAOU M A, et al. End-to-end multimodal emotion recognition using deep neural networks[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(8):1301-1309.
[32]VALSTAR M, GRATCH J, SCHULLER B, et al. Avec 2016: Depression, mood, and emotion recognition workshop and challenge[C]∥Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge.ACM,2016:3-10.
[33]HUANG Z C, STASAK B, DANG T, et al. Staircase regression in OA RVM, data selection and gender dependency in AVEC 2016[C]∥Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge.ACM,2016:19-26.
[34]HAN J, ZHANG Z, CUMMINS N, et al. Strength modelling for real-world automatic continuous affect recognition from audiovisual signals[J]. Image and Vision Computing, 2017, 65:76-86.
(编 辑 李 静)
收稿日期:2020-04-02
基金項目:国家自然科学基金资助项目(61702419);陕西省科技计划资助项目(2020GY-050,2018ZDXM-GY-186);陕西省自然科学基础研究计划资助项目(2018JQ6090)
作者简介:冯晓毅,女,陕西西安人,教授,博士生导师,从事计算机视觉和模式识别研究。
