面向污水处理过程的预测元-RVM故障诊断建模
2020-04-29程洪超吴菁刘乙奇黄道平
程洪超 吴菁 刘乙奇 黄道平
(华南理工大学 自动化科学与工程学院,广东 广州 510640)
随着《中国制造2025》和工业4.0战略的提出,智能故障诊断技术受到越来越多的重视[1- 3]。但是污水处理系统是一个复杂的系统,包含了化学、物理和生物反应。具有多模态、参数时变、多变量耦合、大滞后等特性[4]。同时,我国大部分污水厂自动化水平不高,因此常出现不易辨识的传感器故障和污泥膨胀等问题[5],而这些故障会直接导致出水水质不达标。由于污水处理工艺的日趋成熟,开发高效的故障诊断技术是避免污水厂发生深度故障的重要举措。最初的故障诊断技术大多是基于定性分析,这需要从业者对工艺过程和硬件设备具有深度的认识[6]。但是随着污水厂的处理工艺逐渐复杂,大量的中小型污水厂根本无法被有效监测。而污水厂产生和存储的数据蕴含着设备运行和生化反应的重要信息,如果能够把这些有用的设备信息从海量数据中提取出来,将会为污水厂的高效监测提供源源不断的动力。数据驱动的统计方法的优越信息提取能力得到关注[2,7]。这些统计方法可以根据能否提前获得数据标签分为监督统计学习方法和无监督统计学习方法。以主成分分析(PCA)为代表的无监督统计学方法在污水处理过程得到了广泛应用[8- 9]。但是监督统计学习方法在污水厂的故障诊断领域的研究相对较少。随着污水厂采集和存储数据的自动化水平越来越高,有标签数据获取更加容易。所以监督统计学习方法也越来越受到重视[7,10]。
监督学习方法是利用污水厂存储的历史数据和对应的标签来训练模型,然后当输入新的工况数据时能够精确输出对应的工况信息(标签)。其中支持向量机(SVM)就是一种最常用的有监督学习方法[11]。然而SVM存在罚参数不易设置,核函数必须满足Mercer 定理,无法得到概率性预测等桎梏。鉴于此,Tipping[12]提出了相关向量机算法(RVM)。RVM是以贝叶斯理论为基础,通过相关决策理论(ARD)来移除无关点,从而获得稀疏化的模型。因此RVM不仅能够得到概率输出值,而且能够通过删除无关点来避免伪“相关向量”对模型复杂度的影响,从而大大节约运算成本。Widodo等[13]将RVM用于齿轮的故障诊断,Psora-kis等[14]将RVM扩展到多分类问题上。尹金良等[15]将扩展的多分类RVM用于变压器的故障诊断。Liu等[7]利用RVM建立相应的软测量模型,用于预测污水厂的难测变量。但是RVM方法在污水厂的故障诊断的中应用相对较少。尤其是当采集的数据存在大量冗余信息时,RVM的监测性能就会明显下降。
为了提高RVM的故障诊断性能,尤其是当数据存在冗余信息和重复特征的时候,Xu等[16]提出将PCA和独立元分析(ICA)混合的策略来提取数据的有效特征。该策略首先利用ICA提取数据的非高斯信息,然后利用PCA提取剩余的高斯信息,最后与RVM结合来提高故障诊断的精度。但是PCA和ICA结合能否彻底且不重复地提取数据信息仍待商榷。而且PCA是根据方差的大小来度量信息量的,但是方差是描述离散程度,无法直接用于描述信息不确定度。于是笔者考虑将最初用于经济学领域的可预测元分析(ForeCA)引入本研究。ForeCA是一种全新的统计信号处理算法,是卡内基梅隆大学的Goerg博士为了能够有效提取股票基金数据中蕴含的可预测信息提出的[17]。它融合了傅里叶变换、谱密度、信息熵和期望最大化-type(EM-type)等理论。该方法首先将时域信号转化为频域信号,然后以香农熵为媒介推导出评价时间序列的可预测信息指标——可预测度,最后根据EM-type算法提取最优可预测元序列和对应的可预测度。本研究借鉴PCA利用累计方差提取主元的思想[2,18],利用累计可预测度来提取变量的可预测主元变量。
基于上述分析和讨论,本研究提出了一种全新的故障监测技术,即预测元-相关向量机。该方法首先将ForeCA算法引入污水处理过程监测,对污水厂的历史数据进行有效的特征提取。然后与RVM有效结合,一方面能够有效提高RVM的诊断精度,另一方面可以缩减RVM运行时间。
1 相关向量机理论
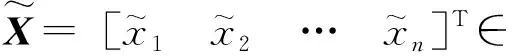
(1)
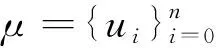
(2)
同时假设变量时间序列是独立同分布的,而且都服从伯努利分布,则对应的似然函数可以表示如下:
(3)

μm=arg maxμp(μ|y,α)=arg maxμP(y|μ)·
p(μ|α)
(4)
首先对式(4)两边取log,然后用牛顿法求解μm最终可以计算出对应的协方差矩阵和初始权值参数μm如下所示:
μm=ΩTΛy
(5)

(6)

(7)
模型通过式(7)更新超参数α直到满足收敛条件为止。在对超参数进行更新时,如果会出现量级较大的αi,就将其视为无限大而停止更新。
2 预测元-RVM方法和故障诊断流程
预测元-RVM方法是把一种新的特征提取方法(可预测元算法)与RVM结合。ForeCA是通过信息熵来度量信息量的[17,19],所以在特征提取方面,ForeCA要优于PCA。通过ForeCA提取有效特征,一方面可以去除重复特征的冗余信息和噪声,从而降低数据维数,避免出现维数灾难;另一方面可以提高RVM的分类精度,降低计算机的运算负担。
2.1 可预测元分析
2012年,Goerg[17]首次提出了ForeCA算法。ForeCA算法的核心是找到最优的可预测传递矩阵A,将原来的数据空间分别映射到对应的可预测空间和白噪声空间。假设离线数据集为X∈Rn×m(n表示采样次数,m表示监测变量数目),A∈Rm×m,是可预测元的最优传递矩阵。
Y=AXT
(8)
式中,YT∈Rn×m,表示得分矩阵。ForeCA算法需要解决的优化问题就是找到最优的A和Y。Goerg[17]指出应首先将时域信号转化为频域信号,所以本研究以单变量平稳时间序列xt为例。可以求得xt的自协方差函数:
rx(l)=E(xt-ux)(xt-l-ux)
(9)


(10)
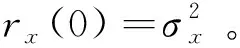
(11)


(12)

HF,a(xt)≤HF,a(εt)=

(13)
可以利用式(13)推导出求解可预测元传递矩阵的重要指标——可预测度Φ(·)。

(14)
其中可预测度Φ(·)是评价时间序列xt可预测性的重要评价指标,与所求解的可预测传递矩阵的列向量一一对应。所以对于多变量时间序列Xt∈Rm,只需要找到最优可预测向量w,使得zt=wTXt。而最初选的w很可能不是最优的,即无法使得Φ(·)的值最大。求解可预测传递矩阵就变成了如下的优化问题。
maxwΦ(xt)=maxwΦ(wTXt)=
(15)
s.t.wT∑Xw=1。

FX(ωj)w
(16)
令L(w;ωj)=logawTFX(ωj)w,w*就是需要求解的最优可预测向量。Goerg[17]给出了求解w*的EM-type算法的详细推导过程。通过循环调用EM-type算法可以得到一个最优传递矩阵w和对应的可预测度。本研究借鉴主元分析中利用累计方差贡献率确定主元的思想[2,18],通过累计可预测度贡献率来求可预测主元。

(17)
式中,k是可预测主元个数,m是监测变量个数。Lthreshold表示保留的可预测信息容量的控制上限,用来决定需要保留的可预测主元个数。通过上述的可预测元算法提取数据的特征变量后,然后用这些特征训练对应的RVM模型。
2.2 预测元-RVM的故障诊断流程
预测元-RVM算法首先利用可预测元算法对训练集的数据进行特征提取,然后将去除冗余特征的干净数据输入随后的RVM模型。最后利用已经训练好的RVM模型对在线数据进行诊断,从而准确判断在线数据的工况信息。本研究给出了预测元-RVM的故障诊断系统框架图,如图1所示。由于该课题的研究主要是针对单传感器故障,所以对不同的传感器故障分别建立了对应的预测元-RVM模型。图1中RVMm模型表示某个时间段第m个传感器出现阶跃故障时的诊断模型,笔者利用包含正常工况和故障工况(m)离线数据集训练预测元-RVM模型。通过图1的流程对在线数据进行诊断。

图1 预测元-RVM算法的故障诊断框架图
Fig.1 Fault detection framework plot of Forecasts component-RVM
2.3 故障诊断模型的性能评价指标
性能评价指标是考察一个监测模型性能的重要决策函数,漏报警率(MAR)和误报警率(FAR)指标是评价监测模型性能的重要函数[20]。误报警是当污水厂在正常运行时,监测系统一直给出警报,这就需要工作人员不断去巡查现场。如果误报警比较频繁,不仅会浪费大量的人力物力,也会影响污水厂的正常运营。漏报警是指监测系统无法通过在线数据分析出系统故障,是比误报警影响更严重的指标。如果监测系统无法及时辨识传感器故障或者污泥膨胀,就无法及时给出有效的解决办法。所以本研究采用漏报警率和误报警率,以及常用的故障诊断准确率(AC)来评价监测模型。对应公式如下所示:
(18)
(19)
(20)
其中,TP表示预测值和实际值都是正,即预测值和实际值都是故障,TN表示预测值和实际值都是负,而对应本研究就是预测值和实际值都是正常工况,FP表示预测值是故障工况,而实际值是正常工况。
3 案例分析
3.1 BSM1介绍和监测变量选择
(1)BSM1是由国际水协会(IWA)以实际前置反硝化工艺污水处理厂设计为前提开发的一种仿真基准平台,是被普遍认可的仿真基准模型。模型的大致框架如图2所示。图2中,Q0表示入水流量,Qint表示内部循环水流量,Qr表示外部废水回流量,Qu表示二沉池下溢流量,Qe表示符合排除标准而排除的废水流量,Qf是指经过生化反应池到二沉池的污水流量,SO,5、SNO,2、KLa5表示污水处理过程中污水中对应成分的量,下标数字表示对应的反应池。该污水厂日处理污水量平均可达20 000 m3,设计的主要目的是用于去除C和N。如图2所示,该平台主要分为两部分:第1部分是由国际水协(IAWQ)的活性污泥模型(ASM1)模拟的。第2部分是二沉池(容积6 000 m2)。在进行仿真数据收集之前,首先要对BSM1进行稳态仿真,以恒定的成分和流量的入水仿真150天。然后,用晴朗天气的入水数据作为污水厂的动态输入,进行为期两周的仿真。每隔15 min采集一次数据,最终可以得到1 344组测量数据。

图2 污水厂的模型框架图
(2)本研究的过程数据均是在污水厂晴天的时候采集,笔者根据经验挑选了37个变量作为过程监测变量。所选的监测变量涵盖了污水厂的全部过程,可以对污水处理厂起到全面的监控。
3.2 污水厂的故障诊断
本研究的主要目的是为了诊断出传感器是否发生故障,所以模拟了传感器阶跃故障的同时,也建立了对应的RVM模型。其中前700次采集的数据为正常工况数据,后644组数据是传感器发生35%的阶跃故障。取700组正常工况中前350组和后644组数据中的前323组数据用来训练模型。所有离线数据和对应的标签提前已知。首先对数据进行归一化处理,然后利用相应的离线数据集分别去训练对应的RVM模型,最后利用在线数据去验证。为了比较预测元-RVM模型和PCA-RVM模型的性能,除了两个模型建模和测试数据一样以外,PCA与可预测元都保留90%的信息,而且RVM的参数设置都是相同的。选择的高斯核函数的核宽为0.5,最大迭代数为1 000。本次实验按照图2中污水厂水处理流程选择了10个故障传感器分别建立对应的RVM模型。表1给出了4种监测模型的故障诊断结果。

表1 故障诊断结果
4 诊断结果的分析和讨论
由表1中的故障诊断结果可知,预测元-RVM模型的故障诊断性能要明显优于RVM、ICA-RVM、PCA-RVM。通过诊断结果的平均值来看,预测元-RVM的平均故障诊断准确率为93.64%,是4种方法最高的。PCA-RVM的故障诊断准确率最低,仅仅为60.22%。虽然PCA-RVM相比RVM降低了计算负担和程序运行时间,但是故障诊断正确率并未提高。这是因为主元分析提取数据的特征信息时只有在服从高斯分布的时候才能达到最优,而ICA则是用来提取数据的非高斯信息,实验结果也表明ICA-RVM的平均故障诊断准确率高于RVM和PCA-RVM。可预测元分析通过信息熵来提取数据信息,在特征提取中具有独特优势。因此,预测元-RVM模型性能优于另外3种模型。
漏报警对真实污水厂的影响更严重。本研究开发的预测元-RVM的漏报警率是4种方法最低的,相比基础的RVM方法,漏报警率降低了76.3%。但是数据降维方法也存在缺陷。在本研究中发现,降维方法虽然降低了计算负担,可是本研究的3种降维方法与RVM结合的误报警率均值都高于RVM方法的误报警率均值。从3种降维方法的结果来看,本研究提出的预测元-RVM的误报警率增加得最少,仅仅增加了0.014 2。而ICA-RVM次之,增加了0.059 4。综上来看本文提出的预测元-RVM方法的漏报警率明显低于其他3种方法,误报警率虽然比RVM方法有点增加,但是也明显低于其他两种方法。所以预测元-RVM方法在故障监测方面还是比较有效的。
为了使故障诊断结果更加可视化,笔者选择了传感器9和传感器17。分别给出了两种模型的故障诊断图,并且将预测值在原有基础上提高两个单位。
图3给出传感器9发生了阶跃故障时的诊断结果。图中灰色部分表示数据预测工况,黑色表示真实工况。从图3(a)的诊断结果可以看出,RVM方法的诊断效果最好。误报警率和漏报警率都为零,故障诊断准确度也达到了100%。图3(b)的ICA-RVM方法出现了少量漏报警和误报警的情况。所以降维方法虽然能够降低RVM方法的计算负担,但是在提高RVM方法的分类精度方面确实具有不确定性。如果降维方法提取数据特征不充分,很有可能导致RVM的分类性能下降。图4给出了传感器17的可视化图。图4(d)中的预测元-RVM方法相比于RVM方法的漏报警率和误报警率明显下降,而且故障诊断准确率也明显提高。在时间上,未进行降维的RVM方法运行时间为3.937 s,而利用可预测元算法降维后的RVM耗时2.763 s。所以本研究所提的预测元-RVM方法的性能要明显优于RVM。


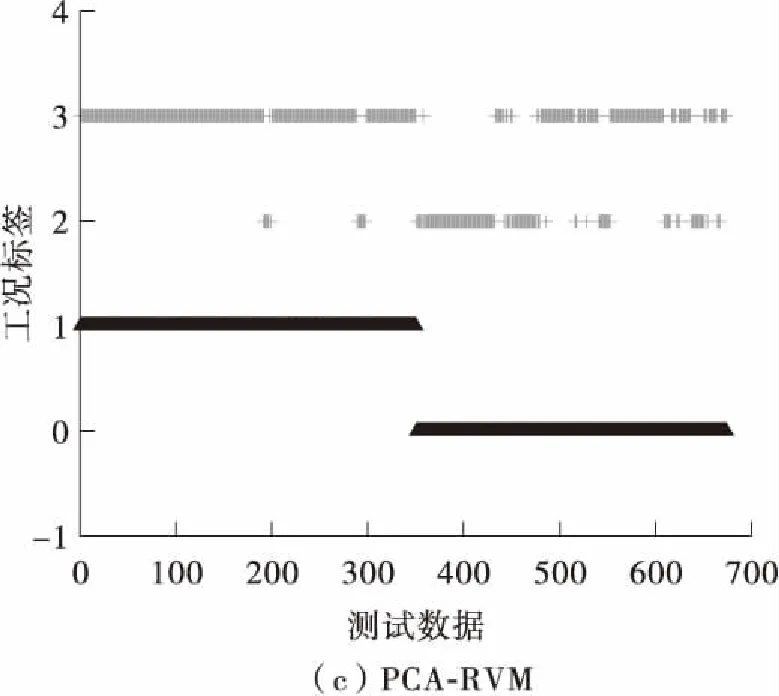

图3 传感器9故障的诊断结果

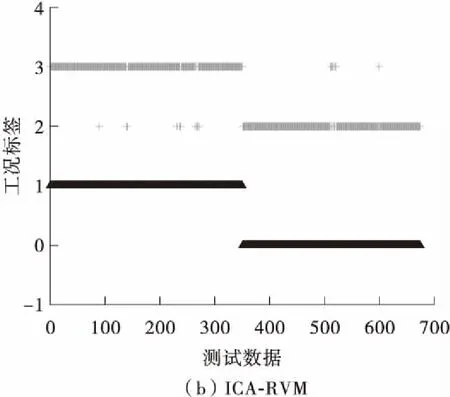


图4 传感器17故障的诊断结果
5 结论
污水厂由于工作环境恶劣和外部扰动复杂,一些重要的传感器长期在强腐蚀的环境下工作很容易出现故障。所以本研究针对污水厂常见的传感器故障提出了一种有效的监测算法,即预测元-RVM。通过对污水厂常见的10种传感器故障进行诊断,实验结果表明该方法的性能优于RVM、PCA-RVM和ICA-RVM,尤其是漏报警和故障诊断精度方面明显优于其他3种方法。
