基于注意力增强网络的场景文字识别
2020-04-25徐富勇
徐富勇
(四川大学计算机学院,成都610065)
0 引言
近年来,由于自然场景文字识别在广泛应用中的重要性,其引起了学术界和工业界的广泛关注。很多应用都受益于场景文字的丰富语义信息,例如:交通标志的识别[1]、产品识别、图片搜索和无人驾驶等。随着场景文字检测方法的发展,场景文字识别也成为当前研究的前沿课题,也是一个开放性和极具挑战性的研究课题。
目前,规则的文字识别[2]取得了显著的成功。基于卷积神经网络的方法[2]得到了广泛的应用。有很多研究方法将递归神经网络[3-4]和注意机制[5-8]结合到识别模型中,并且还取得了很好的效果。然而,目前大多数的识别模型仍然不稳定,无法处理来自环境的多种干扰。不规则文字的各种形状和扭曲模式对识别造成了更大的困难。如图1 所示,透视和曲线形状等不规则的场景文字仍然很难识别。
因此,我们提出了一种注意力增强网络(Attention Enhanced Network,AEN),它可以识别自然场景中缩放和拉伸的文字,AEN 将含有文字的图像作为输入,直接输出预测的单词。

图1 规则和不规则场景文字例子
当前的文字识别网络存在一些问题,例如Cheng等人[5]发现现有的基于注意力的方法会出现注意力偏移的情况。因此,根据他们所提出方法的启发,我们针对自己的模型,提出了注意力增强的方法来改进和训练AEN。提出了基于相邻注意力权重的双向LSTM 解码器。由于注意力增强的作用,AEN 对于上下文的变化更加鲁棒。简而言之,本文的主要贡献如下:第一我们提出了一种基于注意力增强的解码器方法,本方法可以解决注意力偏移的问题。第二我们提出的方法可以以弱监督的方式进行训练,只需要提供文字标签,这样省去了大量的标注工作。
1 相关工作
随着递归神经网络(RNN)的广泛应用,基于CNN(Convolutional Neural Network)与RNN(Recurrent Neural Network)结合的方法可以更好地学习上下文信息。施等人提出了一个具有CNN 和RNN 的端到端可训练网络,称为CRNN。此外,注意力机制侧重于信息区域以实现更好的性能。李等人[7]提出了一种基于注意力机制的递归网络,用于场景文字识别。Cheng 等人[5]使用聚焦注意网络(FAN)来纠正注意力机制的变化,实现更准确的注意力位置预测。
与规则场景文字识别工作相比,不规则文字识别更加困难。一种不规则的文字识别方法是自底向上的方法[8],它搜索每个字符的位置然后连接它们。另一种是自顶向下的方法[4]直接从整个输入图像识别文本,而不是检测和识别单个字符。我们提出的AEN 方法采用的是自顶向下的方法。注意力增强方法被用于提高注意力的准确度。
2 方法
AEN,由带有注意力增强解码器的CNN-BLSTMLSTM 架构构成,直接处理和识别文字图像,输出预测结果。

图2 AEN整体架构
2.1 AEN
如图2 所示,AEN 的主要结构是CNN-BLSTMLSTM 框架。编码器部分我们采用的是CNN-BLSTM架构。目前方法的解码器是基于LSTM 直接生成目标序列(y1,y2,…,yT)。解码器生成的最大步数为T。解码器在预测到序列结束标记EOS 时停止处理。在时间步t,输出yt如下:
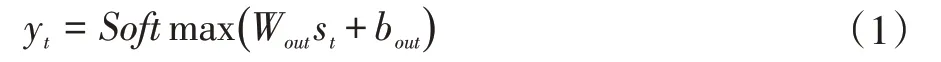
公式中,st是时间第t 步隐藏层状态,我们使用LSTM 来更新st,由如下公式计算更新:
st=LSTM( )yprev,gt,st-1(2)
yprev代表的是前一个时间段的输出yt-1的嵌入向量,gt代表注意力权重向量。

在公式(4)中hi代表的是序列特征向量,L 是特征图的长度。而第一项αt,i是注意力权重向量,计算如下:
4、移民安置监测。监测结果表明:6个移民安置点规划建设总规模为3415.76亩,实际建设规模为4100.40亩,超规划建设684.64亩;规划人均建设用地面积84.36 m2,超出规划要求的人均建设面积4.36 m2。2017年实际监测人均建设用地面积101.26 m2,相比于水区淹没区人均建设用地面积108.97 m2,移民集中安置点人均建设用地减少了7.71 m2,新建设的城镇移民安置点比淹没前的居住建设更能体现出合理用地与集约节约用地。
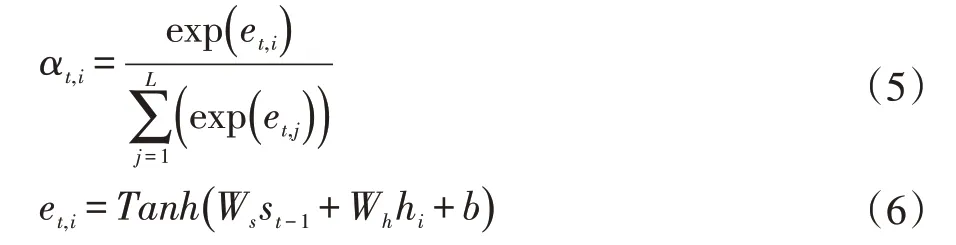
在上述的公式中Wout,bout,Ws,Wh和b 都是可训练的参数。注意:在训练阶段yprev是来自最后一步的真实标记。然而,在测试阶段使用最后一步的预测输出作为yt-1。本文解码器是基于注意力增强的解码器,借鉴于文献[5]的思想,本文提出了相邻注意力权重和双向LSTM 解码器方法,在2.2 小节详细说明。AEN 的架构详细信息见表1。
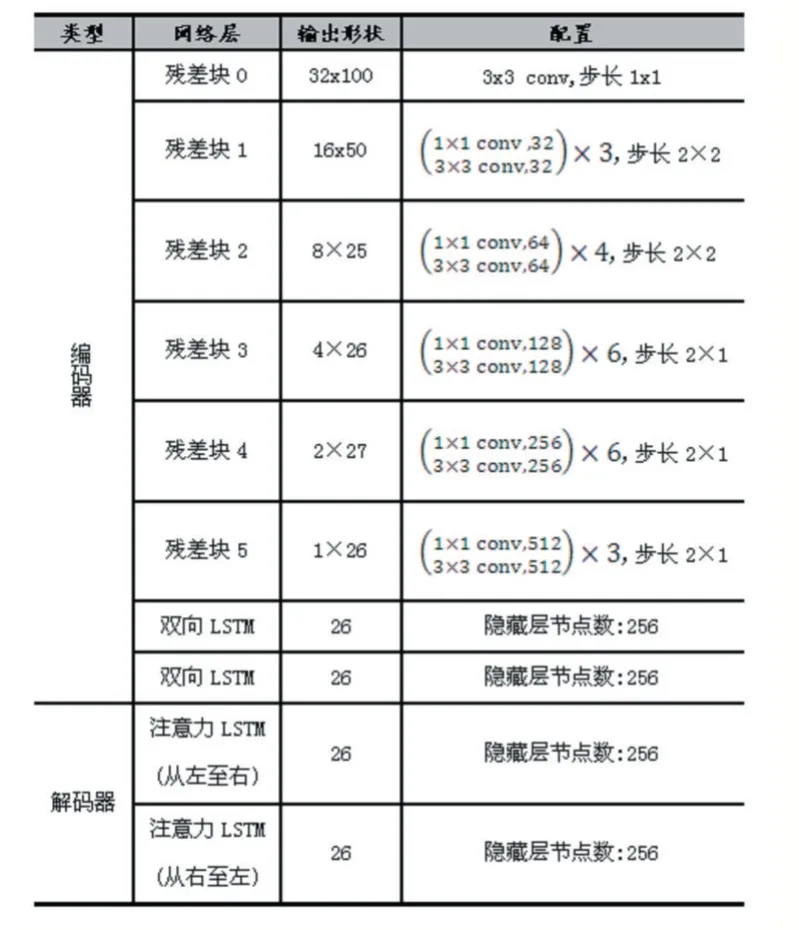
表1 AEN 架构
2.2 相邻注意力权重方法
解码器通过正确注意力的反馈,可以增强选择正确注意力区域的能力。但是,自然场景图像中存在着各种类型的噪声。在实际应用中,解码器可能会被欺骗以关注模糊背景区域。如果解码器生成不正确的注意力区域,选择非对应的特征,这将会导致预测失败。
我们使用了一种称为相邻注意力权重的训练方法,它在训练阶段每一个时间步都获取一对相邻的特征。通过此方法训练的注意力解码器可以感知相邻的字符。我们在解码器的每个时间步选择和修改一对注意力。在时间步t,αt,k和αt,k+1以如下方式更新:
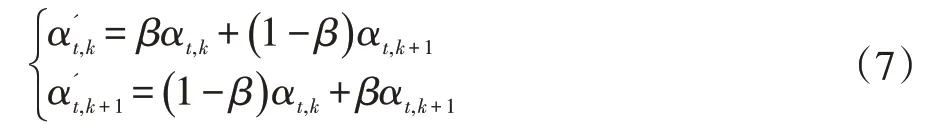
上式中的β 是(0,1)之间随机生成的小数,k 是[1,T-1]之间随机生成的整数。T 代表的是解码器的最大步长。
基于相邻注意力权重方法的解码器,在αt,k和αt,k+1中都加入了随机性。这意味着:即使对于相同的图像,在训练阶段的每个时间步长,αt的分布都会发生变化。如等式(4)中所述,注意力向量gt根据αt的各种分布来获取序列特征向量hi,其等同于特征区域在变化。 β 和k 的随机性不仅可以避免过拟合,并且可以增强解码器的鲁棒性。注意:αt,k和αt,k+1是相邻的。在不使用相邻注意力权重方法时,序列特征向量hk的误差项是:
δhk=δgtαt,k(8)
上式中δgt是注意力向量gt的误差项,δhk仅与αt,k有关。但是,使用相邻注意力权重方法,误差项变为:
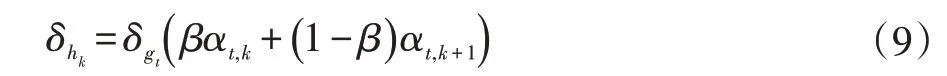
其中αt,k+1与hk相关,如等式(5)和(6)所示,这意味着δhk受相邻特征决定,因此,反向传播的梯度能够在更宽范围的相邻区域上动态地优化解码器。
使用上述方法训练的AEN 在每个时间步骤产生更平滑的αt。所以,我们不仅可以提取目标字符的特征,而且还提取了前景和背景上下文的特征。如图3所示,使用此方法能够正确地预测目标字符。
2.3 模型训练
网络训练的优化算法使用Adadelta,本文通过Adadelta 分别计算每个参数上的学习率。在实际使用中,Adadelta 的收敛速度更快。

图3 是否带相邻注意力权重方法训练的比较
3 实验
在本节中,我们将在各种基准数据集上进行广泛实验,包括规则和不规则文字数据集。所有方法的性能都是通过单词级的精度来衡量的。
3.1 数据集
IIIT5K-Words(IIIT5K)[9]包含用于测试的3000 张裁剪单词图像。每张图像都有一个50 词的词汇表和一个1000 词的词汇表。词汇表由一个正确的单词和其他随机选择的单词组成。
ICDAR 2003(IC03)是ICDAR 2003 竞赛所使用的数据集。本文只使用其识别数据集。包含非字母数字和长度小于3 的文字图片被从数据集中剔除。过滤后的识别数据集包含860 张裁剪图片。
Street View Text(SVT)[10]采集自Google Street View,其测试集包含647 张裁剪后的图片。许多图片都受到噪声的严重影响,或者分辨率很低。每个图像都与一个50 词的词汇表相关联。
ICDAR 2013(IC13)[11]的 大 部 分 样 本 都 继 承 自IC03,它包含1015 个裁剪文字图像。没有与此数据集关联的词汇表。
3.2 实现细节
网络结构:有关AEN 的详细信息分表1 中给出。解码器中LSTM 的隐藏单元数为256。
模型训练:AEN 以端到端的方式进行训练。训练数据由Jaderberg 等人发布的800 万张合成图像[21]和Gupta 等人发布的600 万合成图像构成[22]。使用Adadelta 自适应学习率调整的优化方法,我们在开始时将学习率设置为1.0。
实现:我们基于PyTorch 1.0 框架实现了我们的方法。我们的实验中使用NVIDIA RTX-1060 GPU、CUDA 9.0 和CuDNN v7 后端,所有图像尺寸都调整为32×100。
3.3 AEN在文字数据集上的性能
我们在常用规则文字数据集上进行评估,这些数据集中大多数测试样本是规则文字,其中有一小部分是不规则文字。我们将本文方法与之前4 种方法进行比较,结果如表2 所示。AEN 在没有词汇表的模式下优于所有当前最好的方法。
3.4 AEN的局限
为了公平比较和良好的可重复性,我们选择了广泛使用的训练数据集进行测试。我们发现由于场景文字背景复杂,当文字弯曲角度太大时,本文方法可能会失效,其可能会错误地将复杂背景视为前景。上述实验均基于裁剪文字识别,没有文字检测器的AEN 不是端到端场景文字检测识别系统。在更多应用场景中,不规则和多方向的文字对于检测和识别都具有很大的挑战性。所以,任意形状场景文字识别仍然是一个等待解决方案的挑战性问题。
4 结语
在本文中,我们提出了一个用于场景文字识别的注意力增强网络。本文方法使用基于相邻注意力权重的双向解码器的序列识别网络来识别文字图像并预测输出。我们在规则和不规则文字数据集上进行了大量实验,都表现出了优异的识别性能。将来,我们有必要扩展这种方法来处理任意方向和任意弧度的文字识别问题,由于文字和背景的多样性,这个问题更具挑战性。由于端到端文字识别性能的改进不仅取决于识别模型,还取决检测模型。所以,找到一种将AEN 与场景文字检测器结合起来的正确有效方法也是值得研究的方向。
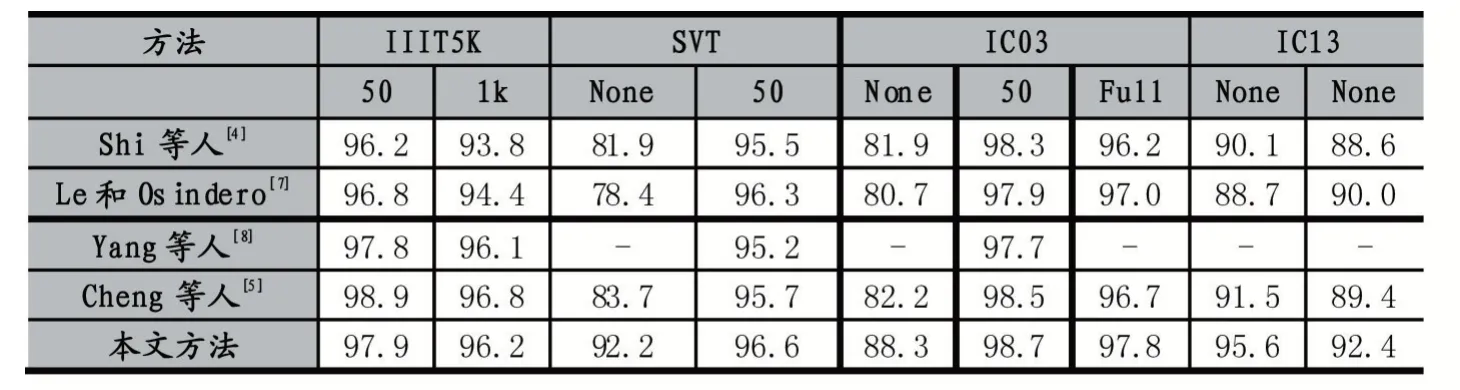
表2 AEN 在规则文字测试集上的准确率
