基于特征融合和中心预测的目标检测算法
2020-04-25段志伟
段志伟
(四川大学视觉合成图形图像技术国防重点学科实验室,成都610065)
0 引言
如今图像和视频逐渐成为人们获取信息的主要来源,如何让机器像人一样理解图像或视频中的内容是计算机视觉领域的主要任务。目标检测作为计算机视觉的一个重要研究方向,近年来得到快速的发展。早期的目标检测方法依靠手工设计的特征提取器提取图像中目标的特征,但随着处理数据中的目标类别越来越丰富和数据量越来越大,传统方法显得力不从心。目前,主流的目标检测方法都是基于深度学习的,依靠深度卷积神经网络提取目标特征,模型泛化能力较强。Ross Girshick 等人提出的R-CNN[1]是早期成功将深度卷积网络与目标检测任务相结合的算法之一,它将传统的手工特征,如SIFT、HOG 等,替换成用深度卷积网络自动提取的特征,检测精度大幅提高。后续改进算法[2,3]在R-CNN 基础上改善采样方式和缩减计算量,检测速度和精度都有显著提升。但它们都只在一层卷积特征上做预测,感受野单一,无法有效适应目标的尺度变化。Wei Liu 等人提出的SSD[4]算法在多层卷积特征上提取多尺度特征并预测,有效缓解了单尺度预测的漏检问题,但浅层特征提取不够充分,对于小目标检测效果较差。
本文基于Faster R-CNN[3]目标检测框架,针对单尺度预测目标检测算法无法有效适应目标多尺度变化的问题,提出一种结合通道域注意力的多尺度特征融合方案,并针对该算法在图像上通过滑动窗口方式密集采样会产生较多难分负样本的问题,提出一种目标中心区域预测模块。
1 特征融合
1.1 多尺度特征融合
Faster R-CNN 目标检测算法针对多尺度目标采用不同尺寸的锚点框定位,然后在ROI Pooling 层使用VGG16[5]网络最后一层卷积层(conv5_3)特征和RPN 网络搜索的建议框去提取对应的目标特征。由于只使用一层卷积特征导致感受野单一,且锚点框的尺寸需要人工设计,不能有效的适应物体的多尺度变化。Songtao Liu 等人提出的RFBNet[6]通过空洞卷积模拟人类视觉的感受野,提升感受野复杂度,有效地加强了网络提取特征的能力且计算量不大。空洞卷积是一种间隔采样的特殊卷积,它可以获得更大的感受野从而获得更大尺度的信息,并且大感受野还能捕捉到更多的上下文信息,防止小目标的误检。Yanghao Li 等人提出的TridentNet[7]发现检测不同尺度目标的精度和感受野大小正相关,在感受野较大的卷积层特征上能更好地提取大目标特征,在感受野较小的卷积层特征上能更好地提取小目标特征。Jie Hu 等人提出的SENet[8]通过引入通道域注意力机制使网络能学习到特征通道之间的联系,对不同的通道赋予不同的关注度,可以增强对当前任务有用的特征并抑制收效甚微的特征。受以上论文的启发,本文设计了一种结合通道域注意力的多尺度特征融合方案,如图1 所示。
首先在VGG16 的conv5_3 特征上使用不同rate值的空洞卷积在不同的感受野下提取特征,然后拼接得到特征F。F 含有目标的多尺度特征以及目标附近的上下文信息。接着利用通道域注意力机制学习conv5_3 特征通道之间的关系,在通道域上进行加权赋予不同的关注度得到特征G。最后通过element-wise add 的方式融合特征F 和G。本文设计的特征融合方式使得特征信息更加丰富,不仅融合了来自不同感受野下的特征,还在通道域上增强了含有丰富信息的特征,削弱了信息较少的特征。
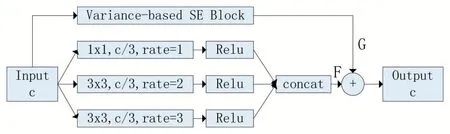
图1 多尺度特征融合
1.2 通道域注意力机制
基于SENet 提出的SE 模块,将其中的全局平均池化修改为计算每个通道的方差。信息论中认为信息的信息量与信息的不确定性有关,不确定性越大信息所含的信息量就越多。本文认为方差在一定程度上可以描述信息的不确定性,特征的方差越大,所含有的信息越多。所以本文用方差计算替换全局平均池化,提取每个通道上特征的方差,然后利用两个全连接层学习特征通道之间的复杂关系,接着使用sigmoid 函数激活,最后将学习到的权重加权到对应的通道上。如图2所示。
图2 中第一个全连接层(FC)将特征通道维度缩减至原先的1/16 减少计算量,然后用ReLU 函数激活增加非线性,接着再用一个全连接层恢复特征的通道维度,最后用sigmoid 函数激活得到各通道权重。
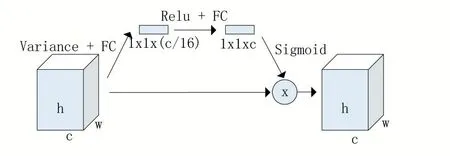
图2 Variance-based SE block
2 中心预测
2.1 中心区域预测模块
Faster R-CNN 目标检测算法中的RPN 网络在图像上通过滑动窗口方式密集采样会产生大量的锚点框,正负样本数量十分不平衡。RPN 网络通过为每个锚点框预测正负样本的分类分数,来剔除负样本。由于密集采样产生了大量的锚点框,有一些难以分辨类别的负样本在分类过程中会被误分为正样本,这些难分负样本会在非极大值抑制阶段使部分正样本被抑制。本文为解决在推理阶段难分负样本的干扰,让RPN 网络去学习图像上每个点属于目标中心区域的概率,将其与分类分数结合,抑制难分负样本。
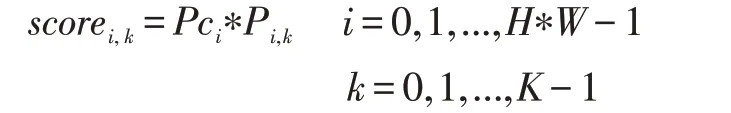
scorei,k表示特征上第i 个特征点第k 个锚点框的分数。Pci表示第i 个特征点属于目标中心区域的概率,Pi,k表示第i个特征点上第k个锚点框是正样本的概率。
如图3 所示目标的中心区域定义为,以目标中心点为中心,长和宽同时缩放α倍后的矩形范围。训练阶段,我们忽略阴影区域,只学习背景和目标中心区域。图4 是添加了中心区域预测模块的RPN 网络。使用一个3×3 卷积层加sigmoid 预测每个特征点属于中心区域的分数。RPN 网络会以每个特征点为中心,生成K个锚点框,一共会生成H×W×K 个。中心预测模块在学习每个特征点落在目标中心区域的概率。
从另一个角度看,也就是在学习RPN 网络中每个锚点框的中心落在目标中心区域的概率。
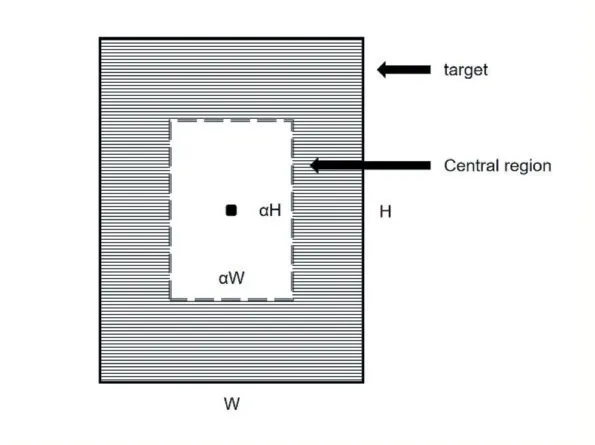
图3 中心区域
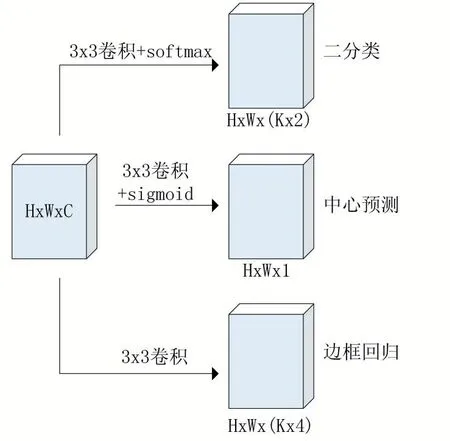
图4 加入中心预测后的RPN网络
2.2 损失函数
一般情况下,图像中所有目标的中心区域并集的面积相比于图像面积较小,正负样本不平衡。因此,本文选择focal loss 损失函数,它不仅可以解决类别不平衡问题,还能处理难分样本。公式如下:
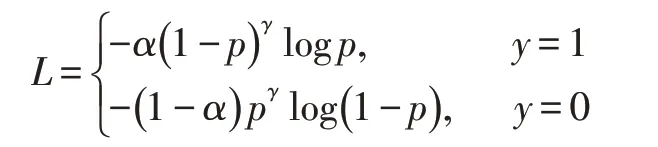
训练时,α取0.5,γ取2,p 是预测值,y 是真实值。
3 实验及结果
本文的实验环境:操作系统为Ubuntu 16.04,CPU为Intel Core i5-8400,显卡为NVIDIA RTX2070。数据集使用VOC2007,训练集一共有5011 张图片,测试集有4952 张图片。
通过表1 的对比试验我们可以看出,加入多尺度特征融合,检测精度有明显提升。本文提出的多尺度特征融合方案可以有效增强特征的表达能力,使得特征信息更加丰富,更利于学习。在多尺度特征融合的基础上,加入中心区域预测模块检测精度也有提高,但检测速度略微变慢。

表1 多尺度特征融合和中心预测对比实验
然后对比了多尺度特征融合方案中SE 模块使用全局平均池化和方差计算两者对检测精度的影响。表2 中使用方差检测精度更高,说明使用方差比均值更利于学习特征通道之间的关系。不同通道特征的方差体现了各个通道特征所含信息量的多少,根据信息量去建模特征通道间的关系比使用均值效果更好。

表2 SE 模块的均值与方差
最后我们测试了目标中心区域α的取值。从表3中可以看出α值取0.7 较合适,此时中心区域面积约占目标框面积的一半。当α较大时会在靠近目标边缘的区域产生许多质量较差的锚点框,增加训练难度使检测精度下降;α较小时采样的锚点框较少,漏检较多。
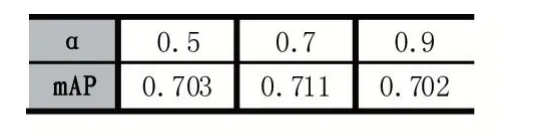
表3 中心区域α值
4 结语
基于Faster R-CNN 目标检测框架,本文针对单尺度预测目标检测算法无法有效适应目标多尺度变化以及密集采样产生较多负样本锚点框的问题,分别提出结合通道域注意力的多尺度特征融合方案和目标中心区域预测模块来解决。由于在单个卷积层特征上做预测感受野单一,本文通过空洞卷积增加卷积特征感受野复杂度,从而获取多尺度特征。同时在通道域上利用特征的方差建模通道特征之间的关系,增强信息量多的特征,削弱信息量少的特征。接着通过中心区域预测模块学习锚点框的中心落在真实目标框中心区域
