基于图神经网络的实体对齐研究综述
2020-04-25孟鹏博
孟鹏博
(四川大学计算机学院,成都610065)
0 引言
随着计算机计算能力的不断提升与可获取数据量的不断增大,机器学习与人工智能技术在工业界的应用也越来越多,知识图谱便是这其中较为成功的一项应用。
知识图谱概念最早由谷歌公司于2012 年提出,作为提高其搜索引擎搜索质量的一种方法。谷歌公司使用语义检索,对不同来源的网站信息进行信息抽取,并结构化储存,方便用户只在搜索页面即可获取搜索目标的大部分信息,而不需要再次跳转到不同的网站并自行汇总。
在知识图谱的构建之中,最为重要的步骤是将原本隐藏在文本之中的信息抽取出来,并进行结构化储存。而实体对齐又是信息抽取任务中的一大难点。实体是指客观存在且互相可以明确区分的不同事务,例如人、物、事件、抽象概念等,知识图谱中往往包含多种不同的实体。实体对齐是指对异构数据源构成的知识图谱中,找出表述不同,但对应现实世界中同一实体的关系。实体对齐方法可以帮助构建一个包含多个来源,多种语言的大型知识图谱,但是跨语言跨源的对齐任务中存在许多问题与挑战,不同数据往往包含不同的关系类型与结构,如图1 所示,李明与中国的关系在不同知识图谱中可能具有不同的结构。不同语言之间的对齐任务也是如此,只能通过机器翻译建立部分可信度较高的实体间联系,但是质量低下的机器翻译有时反而会引入更多脏数据。
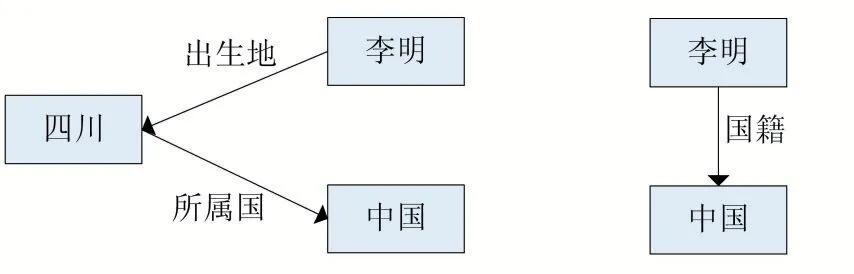
图1 同一实体周边不同结构
本文将着重介绍基于图神经网络相关的研究,主要由以下三个部分构成:相关工作,详细的介绍近年来使用图神经网络解决实体对齐问题的相关研究;相关数据集,介绍实体对齐任务中常用的公开数据集;结语,概括并总结本文主要内容,并对知识图谱的未来研究与应用方向做进一步的展望。
1 相关研究
传统的实体对齐方法有基于相似性函数的特征匹配方法,如利用文本相似性[1],通过计算实体对名称的编辑距离来判断是否为同一实体,或利用结构相似度,通过函数计算周围节点相似度来计算是否为同一实体;基于分区索引的对齐方法,即事先对图谱中的实体进行剪枝,排除不可能相似的实体对,建立索引,最后将有可能匹配的实体对分配至一个或几个小分区中,成为候选实体对;也有研究者[2]的方法主要利用了实体之间的关系,他们假设,如果一个实体与另一个实体在一个源中存在链接,则在另一个源中也很可能会存在链接。以两个源举例,他们通过构造同源实体间关系的邻接矩阵Si与Sj,尝试找到一个代表不同源之间实体对应关系的二维转换矩阵Tij,以使得两个Si经过Tij转换后与Sj矩阵的差异最小,即两个矩阵最为相似,此时便可认为Tij代表了两个源间对应的关系。但此方法也存在缺点,无法处理多源之间因为关系类型不同而造成的结构不同。
针对上述方法的诸多不足,越来越多的学者将目光投向了基于图的解决方法。作为一种常用的数据结构,很多任务都能被描述为图问题。具体在知识图谱方向,对图的应用可以分为三种:
(1)经典的图算法。如生成树算法、最短路径算法、二分图匹配、费用流问题等。
(2)将条件概率表述为图结构,再对其进行进一步的提取,如有条件随机场等。
(3)基于图神经网络的应用,比较经典的有图嵌入(Graph Embeding)、图卷积(Graph CNN)等。
基于图神经网络相关研究是近期较多学者关注的方向,接下来也将就研究进行介绍。
研究者Kipf 和Welling 于2017 年开始采用图神经网络来进行图结构的向量化表示。他们为神经网络模型引入了一种简单且有效的分层传播规则,该规则可直接基于图来进行使用,并介绍了该方法如何用于快速大规模的半监督图节点分类。随后,Velickovic、Abu-El-Haijia 等研究者也提出了关注于不同角度的图结构编码方法。该类方法一般使用递归聚合的方法来对节点机器周围邻居节点信息进行编码,使得在随后的对齐过程中能够使用到图的结构信息。但是该类方法往往仅编码了周围一阶邻居,仍然无法克服不同知识库中关系类型不同造成的图结构不同问题。Zequn Sun 等研究者[5]于2019 年提出的多跳邻居采样方法AliNet 在一定程度上解决了该问题。AliNet 在每一层都使用多个不同的函数来对节点周边的多跳信息进行采样,为了去除多次采样产生的噪音,他们添加了注意力机制来在不同节点采样中选取最重要的端到端邻居,最后,通过门机制来将不同函数的采样结果融合于一起,以获取包含多跳邻居信息的当前层隐式表达。
除了对图结构进行编码,利用周围信息来进行实体对齐外,也有研究者利用其他维度信息来进行图嵌入以帮助改善对齐任务表现。Sun 等研究者于2017 年提出利用节点的拓扑结构与属性信息来完成跨语言知识图谱数据库的对齐工作。Chen 等研究者也在其方法中同时使用了实体的拓扑结构信息与文本描述信息。进一步的,Hsiu-Wei Yang 等人在其2019 年提出的方法中,融合了更多维度的信息。他们通过利用实体的拓扑结构、关系类型、节点属性与文本描述等信息的结合来进行跨语言知识库中的实体图嵌入表达。他们通过使用多层GCN 来获取实体的拓扑信息的编码,并利用考虑了关系信息的RGCN 来对关系类型进行编码,随后使用Bert 方法来对实体的文本信息进行编码,然后获取包含多种维度信息的节点的图嵌入表达。
此外,还有研究者没有使用图嵌入来完成实体对齐任务,而是将问题转化为了图匹配问题,Kun Xu 等研究者提出的方法就是如此。他们首先使用GCN 对目标知识图谱G1与G2内节点进行编码,得到两个包含节点图嵌入表达信息的列表,随后,使用注意力机制方法,将G1中每个个体与G2中每个个体对比,得到跨语言知识图谱感知匹配向量列表。紧接着,使用另一个GCN 来生成整张图的局部匹配信息,以获取每个话题子图的全局匹配向量。最终,使用全局匹配向量来进行配对关系的预测。
在以上几种方法外,还有多种结合其中一种或两种方法而实现的变种对齐方法,这些方法都在其小领域任务中取得了较好的表现,但是泛用性不强,本文不再一一赘述。
2 数据集
2.1 DBpedia
DBpedia 是目前研究者使用最为广泛的知识图谱数据集之一,其数据是从维基百科中提取而来的结构化内容。柏林自由大学以及莱比锡大学的研究者最先提出该项目设想,并于2007 年发布第一版。截至2016年,该数据库已包含600 万个实体,由95 亿条RDF 三元组数据组成。通过该数据库,研究者可以很快地获取分布在多个页面的信息。
2.2 YAGO
YAGO 数据集是由德国马普所(Max Planck Institute,MPI)的科研人员构建的综合型数据库。该数据库内包含了来自维基百科,WordNet、GeoNames 等多个不同的数据源,并将维基百科数据与WordNet 数据进行融合。该数据库的第一版就包含了多于100 万条的实体信息。同时,YAGO 还整合了时间维度与空间维度的描述,方便研究者从多种维度进行使用。
2.3 IMDB
IMDB(Internet Movie Database)是由电影创作者、电影演员、电影、电视节目等信息构成的影视资料库,创办于1990 年10 月。与前两个主要由算法自动提取文本中信息,并辅以人工进行抽查校验所构建的数据库不同,IMDB 内信息主要由世界各地的志愿者进行,有时甚至会有电影创作者本人参与进来,故具有更高的可信度。
2.4 DBP15K
该数据集由清华大学的多位研究者在2015 年提出,该数据依照研究者事先拟定规则,从DBpedia 数据库中选取中、英、日、法四种语言部分条目制作而成。该数据集也是研究者关于跨语言实体对齐常用数据集之一。
3 结语
知识图谱作为人工智能领域较为成功的工业化应用之一,实体对齐方法起到了至关重要的作用。本文从实体对齐的基本概念出发,对实体对齐任务进行分析,介绍了该任务中面临的主要问题与难点。随后简要介绍了实体对齐的不同类型方法,并针对基于图神经网络的实体对齐方法进行了深入的探讨。本文除了对相关论文进行了简要概括与总结,还介绍了目前实体对齐领域所取得的成就。最后,本文介绍了实体对齐任务中最为常用的4 个公开数据集。
本文认为,实体对齐任务未来可以改善方向是如何更有效地利用已知网络结构及相关信息,从多个维度对网络结构信息进行更深层次的编码。另外,大数量级的准确已对齐数据对改善该任务效果会起到至关重要的帮助。
