基于Pandas+Python 的机场进出场流量和气象情报统计系统
2020-04-25李卿
李卿
(四川大学视觉合成图形图像技术重点学科实验室,成都610065)
0 引言
随着旅客出行总次数的增加,历史航迹数据和气象雷达数据也呈指数及增长,空管系统中的硬件性能的更新远远不及高速增长的数据,这就需要我们进行实时统计和计算,例如提取出高价值的历史流量信息并结合气象数据信息,还原机场的某个历史实时状态,为后续的基于神经网络的诸多算法在流量预测,流量控制策略选择方面的应用提供原始数据。流量预测需要从多方面考虑,造成流量拥堵或者流量控制的因素非常多,从根本原因上可以分为气象因素、军事活动、历史流控信息和自然业务增长冲突几个方面。罗萌、崔德光等在文献中指出,流量管理原型系统的形成需要从空管部门得到与流量管理相关的原始数据并进行整理和加载[1],但从实际工作中来看,在空管部门得到的数据往往是零散的、碎片化的,就需要数据处理程序运行在相对更加灵活的平台上,传统的基于数据库的模型配置也较为繁琐。所以针对以上方面,本文使用基于Pandas+Python 的灵活数据处理框架,构建了一种数据采集、融合、挖掘的系统方案,采用本方案可以让数据在终端完成处理,降低本地数据库主机的存储负荷,提高数据的可用性,提升系统的稳定性,并且可以减轻预测系统的深度数据挖掘的工作量,为进一步精确的机场短时流量预测提供了良好基础。
1 数据模式分析及框架介绍
1.1 模式分析
流量数据和气象数据都有相当大规模的数据统计,流量数据是一种较为高层的抽象数据,它来自于实时航迹信息,计划报文信息,其中包含了大量的雷达配对信息,各种飞越信息和各种实时计划报文信息,从这些基础数据中可以抽象出短时流量信息,并进一步累积出长期报文信息[2]。流控信息为管制部门实时发布,短期的流量和实时的气象信息可以作为长期流量和历史气象的依据,依托大量短期甚至实时的数据统计,可以挖掘出机场长期的行为模式和相关空管协调模式。这三块数据涉及到部门众多,在数据的采集过程中很难做到向中心化的汇聚,从而导致庞大的协调开销。所以我们提出采用基于Pandas+Python 的方案在现有的边缘终端上进行数据处理和分析,然后按照时间序列统一汇聚成一份精炼有用的数据集。
1.2 Pandas原理介绍
Pandas 是Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的主要数据结构是一维数据(Series)与二维数据(DataFrame),这两种数据结构足以整理分析相关的气象情报和飞行情报。此外在现有的空管系统环境中,进行数据采集需要对I/O 文件的良好支持,而Pandas 能够很好地完成该项任务[3]。另外航行数据和处理过的METAR 报文都是一种时间序列数据,对于缺失的数据,Pandas 能够使用灵活的方法,例如支持范围日期的生成、窗口统计、频率转换、移动窗口线性回归、UTC 时间和GMT8+序列转换等功能。也有助于处理很多实际序列中的缺值或异常值的问题。
2 数据统计系统构建
Pandas 的灵活性体现在安装方便,部署简单,代码量极少,在本地终端使用脚本化的处理方式就可以完成数据的分析处理。针对数据的来源我们分别对三套系统进行单独设计,在实际运行中,这样的方案取得了较好的效果。只要部署Python3+Numpy 就可以很方便地运行。
2.1 历史流量分析统计系统
本系统只统计短期机场的进出场流量数据,通过实际起飞降落情况以每个小时为单位统计流量,最后将计算出的流量数据以csv 的形式加入文件中。对于数据的统计最好是一天一次,这样可以避免数据磁盘容量不足的情况。如图1 所示,其中DEP 是起飞计划,从起飞计划中可以找到实际起飞时间,从而统计实际出场流量,而ARR 为到达报,从到达报中解析出实际到达时间就可统计进场流量。流量统计具有不同的时间粒度,有10min、30min、1h 的统计方式,最后通过存成csv 文件放到飞行计划服务器上。

图1 历史流量分析统计系统
2.2 METAR、TAF、SPECI报文解析统计系统
本系统主要是统计机场航行气象通告,将三种气象报文中的气象相关特征进行数据挖掘,得到例如风速、风向变化、能见度、下雨、雷暴、大雾等具体的气象特征。由于处理出来的情报较少,为了方便拷入拷出,气象情报服务器处理聚合报文后,通过.csv 文件的形式进行归档。
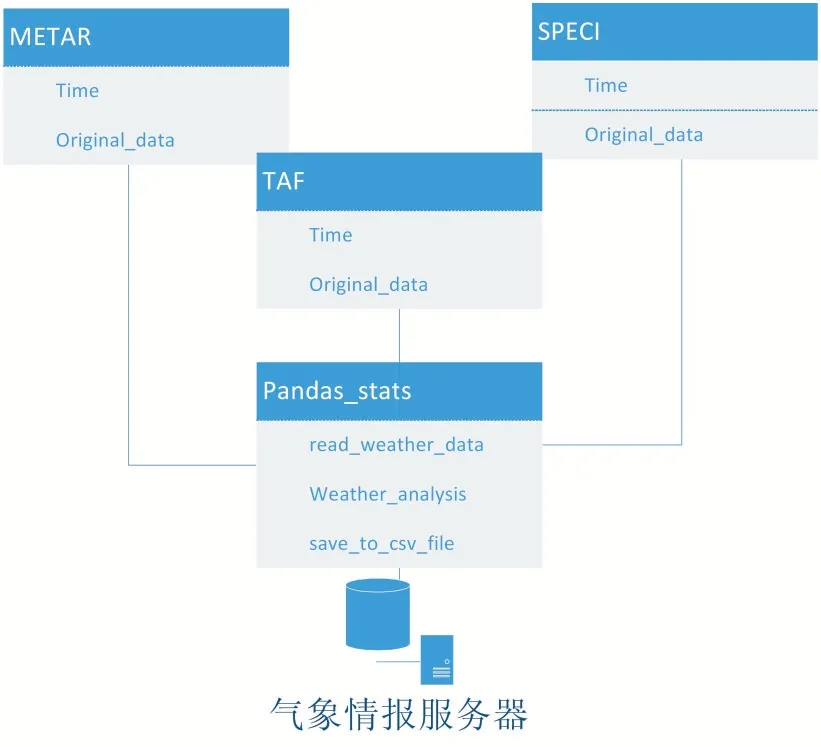
图2 历史气象情报统计分析系统
2.3 流量控制信息收集统计系统
流控信息主要关注来自气象因素、机场因素和管制中心调配因素,将三种因素作为流量控制影响流量的主要因素进行整理,同上述操作一致,放到.csv 上进行存储。
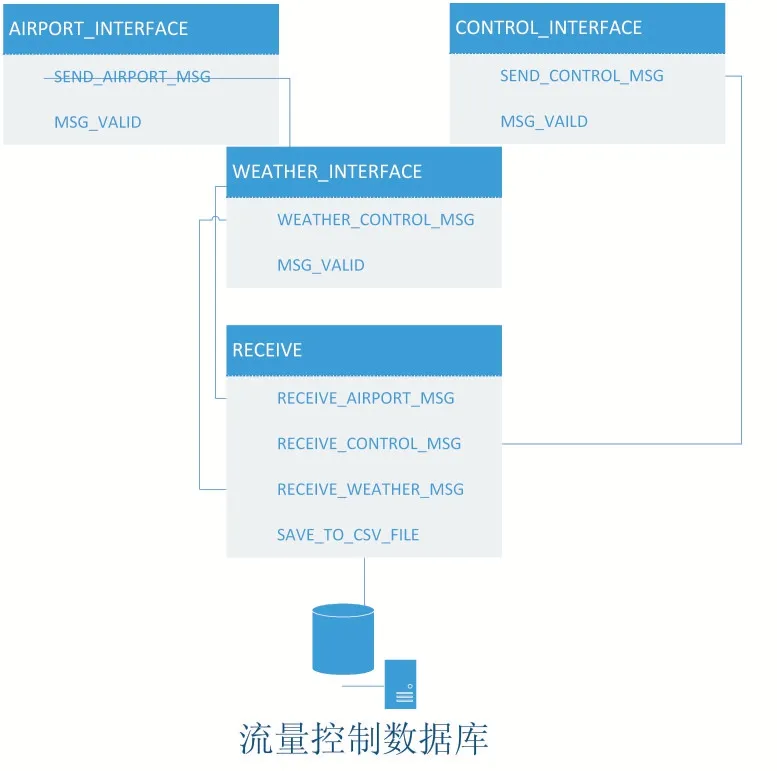
图3 流控信息统计系统
2.4 聚合统计系统
以上零散的系统需要进行聚合,把上面三个系统聚合后效果如图4。
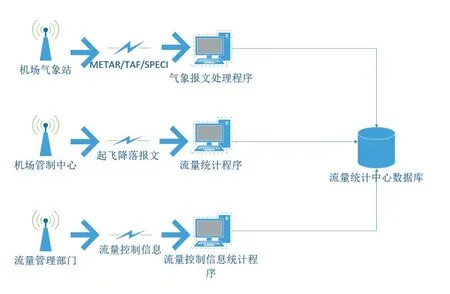
图4 聚合系统
3 数据统计效果
3.1 统计对象数据描述
数据来源分为三大部分,分别是气象情报信息,航迹数据和计划情报报文,历史流量控制信息。以上数据源经数据清洗后放入数据库中,具体数据存放结构需要统筹规划,对核心数据进行初步计算和统计分析,才能最后得到切实可用的数据集。
3.2 气象情报信息
机场气象情报来自于METAR(METeorological Aerodrome Report)、TAF(Terminal Aerodrome Forecasts)和SPECI(SPECIal weather report),其 中METAR 和SPECI 通告了实际气象信息,TAF 报则表示了未来一段时间的预报信息。主要通过METAR 报文可以解析得到全面的气象指标,如表1 展示了2019 年4 月3 日19 时的双流机场及其附近的气象指标。通常全球的METAR 报文都是实时发布的,需要自己采集整理原始报文,从而累积起可用的历史气象数据。而TAF 可以作为预测流量的修正值来使用,在短时间内的TAF 对极端气象指标的预测是较为可信的。在气象特征中,雷暴、风、雾是对民用机场流量影响最大的因素[4],特别是变化很强的风,短时强对流天气对安全飞行造成了很大的隐患[5]。同时,由于METAR 等报文的历史统计信息并没有一个开源共享的历史信息,所以需要自己整理和统计相关数据[6],以备从一个长期的历史范围去研究气象变化对机场正常航行的影响。
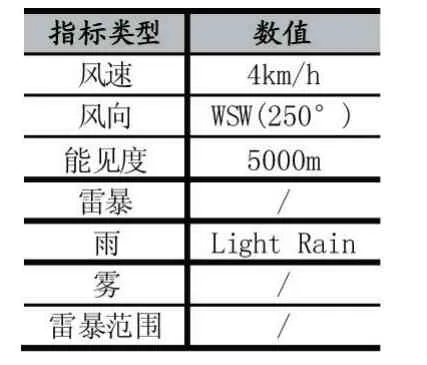
表1 2019 年4 月3 日19 时双流机场实时气象指标
3.3 航迹数据和计划情报报文
通过机场的计划起飞(DEP)降落(ARR)报文中的实时起飞时间和实时降落时间字段,可以较为精确的统计进出场流量信息,也可以通过飞机飞越报告点的时间来进行统计,如表2 就表示了2019 年9 月23 日的进出场流量信息。
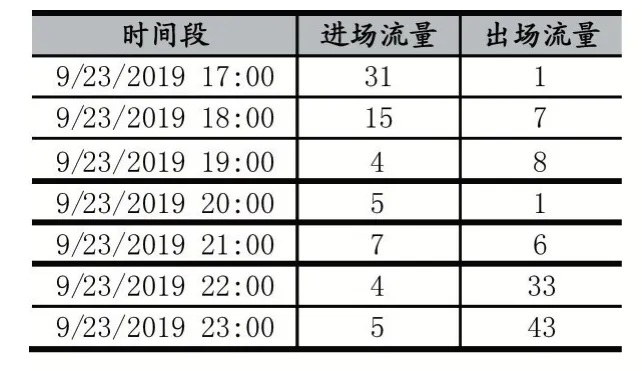
表2 2019 年9 月23 日17 时至23 时进出场流量统计结果
4 结语
本文给出一种灵活、高效的解决方案,Pandas 相比较于传统的数据库方式可以省去很多工作,例如数据库的安装,数据库关系结构化等。若基于传统的数据库,在处理数据上就会显得较为笨重,而一个复杂的系统它的易用性和稳定性都是难做到较好的效果的。此外,在生产终端的运算量往往不会很大,现在的生产终端或者后继节点实际上是具有很大算力空间的,而把以往汇聚到中心的计算放到边缘终端,则会很好地利用到这些冗余算力。再者,本文也总结了目前流量预测和流量控制系统中较为重要的几个特征量,在统一的时间段内,将重要的特征量聚合起来,为下一步基于统计的数据挖掘提供了巨大的发挥空间。笔者认为,空管数据由于其固有的惯性,注定是分散的,处理空管数据也可以用到基于分布式的一些技术例如Hadoop+Spark 的成熟运算架构,以其提升运算速度和存储规模。
