胶囊网络在知识图谱补全中的应用
2020-04-24李冠宇祁瑞华王维美
陈 恒,李冠宇,祁瑞华,王维美
1.大连外国语大学 语言智能研究中心,辽宁 大连116044
2.大连海事大学 信息科学技术学院,辽宁 大连116026
1 引言
一个典型的知识图谱KG(Knowledge Graph)是事实三元组的集合,节点代表实体,边代表实体间关系[1]。现如今,很多知识图谱,如YAGO[2]、Freebase[3]、DBpedia[4]和NELL[5]已经被创建并成功应用于一些现实应用程序中[6]。知识图谱提供有效的结构化信息,成为包括推荐系统[7]、问答[8]、信息检索[9]和自然语言处理[10]在内的智能应用程序的关键资源。尽管知识图谱在各领域有着重要应用,很多大型知识图谱仍不完整,大量实体之间隐含的关系没有被充分地挖掘出来[11]。针对知识图谱补全,进行了大量的研究工作,即预测缺失三元组是否正确[12],将正确三元组添加到知识图谱进行补全。目前,许多嵌入模型用来学习实体和关系的矢量表示,如早期的TransE[13]、TransH[14]、TransR[15]等模型,这些模型中正确三元组得分高于错误三元组得分,这可以有效预测缺失三元组。例如:在知识图谱中,三元组(Aliens,_ditrected_by,James Cameron)得分高于(Community,_ditrected_by,James Cameron)。
在这些嵌入模型中,TransE 简单有效,实现了更高级的预测性能。受文献[16]的启发,TransE 学习实体和关系的向量表示,将关系视为头实体到尾实体之间的一种平移[17]。其他的翻译模型扩展了TransE,使用投影向量或矩阵将头尾实体嵌入转换为关系向量空间,例如:TransH、TransR、TransD[18]、STransE[19]和TranSparse[20]。上述嵌入模型仅使用加法、减法或简单的乘法运算符,因此只能捕获实体间的线性关系。最近,很多研究将深度神经网络应用于三元组预测问题[21]。例如,ConvKB[22]是一种基于卷积神经网络(CNN)的知识图谱补全模型,并获得较好的实验结果。大多数嵌入模型通过对实体和关系相同维度的特征进行建模,每个维度捕获某些特定属性。然而,现有嵌入模型没有采用“深度”架构来对同一维度三元组的属性进行建模。胶囊是一组神经元的集合,利用向量来表示。该向量包含任意多个值,并且每个值代表当前物体的一个特征。在传统卷积神经网络中,卷积层的输出为神经元加权求和的结果,因此是标量。在胶囊网络中,每个值使用向量表示,即胶囊不仅可以表示物体的特征,也可以表示物体的方向、状态等。因此,使用胶囊代替神经网络中的神经元可以更好表征实体和关系,使得知识图谱补全效果更好。CapsNet[23]使用胶囊捕获图像中的实体,利用路由操作指定从上一层胶囊到下一层胶囊的连接。为此,引入CapsNet 模型提出的胶囊网络对三元组进行补全操作。与分割特征映射构造胶囊的传统CapsNet模型不同,使用胶囊对实体和关系在相同维度上的属性进行建模,捕获实体和关系矢量表示。本文提出一种胶囊网络知识图谱补全方法,解决卷积神经网络单层神经元不足以表征实体和关系属性等问题,利用胶囊代替每层神经元表示实体和关系,输入一个三元组,输出连续矢量的值,利用该值判定给定三元组正确性,将正确的三元组添加到知识图谱,对知识图谱进行补全。
实验采用三个数据集FB15K-237、WN18RR、FB15K进行相关的链接预测和三元组分类实验。实验结果表明,基于胶囊神经网络的知识图谱嵌入方法拥有更好的预测准确度,三个数据集的补全效果优于某些传统基准嵌入模型。
2 相关工作
2.1 基准嵌入模型
基准模型TransE 将知识库中的关系看作实体间的平移向量,即关系是头实体到尾实体间的一种平移,例如,三元组(Alaska,cityOf,America),即有:vec(′Alaska′)+成 立,即,认 为无限接近零,这也表明在嵌入空间中t 应该是h+r 最近的邻居[24],见图1。
图1 实体和关系低维嵌入表示
与以往模型相比,TransE 模型参数较少,计算复杂度低,却能够直接建立起实体和关系间的复杂语义联系[25]。TransE 模型简单有效,可以处理较为简单的1-1关系,却不适用复杂关系类型:一对多,多对一,多对多。给定两个正确三元组(Shanghai,cityOf,China)和(Beijing,cityOf,China),若要得到Shanghai和Beijing两个头实体嵌入,利用TransE打分函数计算出两个相同的实体嵌入,这显然是不成立的。由于这些复杂关系的存在,导致TransE学习得到的实体表示区分性较低。为了弥补这个缺陷,TransH模型提出不同的实体在不同关系下应该拥有不同表示,对关系r ,同时使用平移向量r和超平面的法向量wr来表示。由于TransH 假设实体和关系处于同一语义空间,从某种程度上限制了它的表达能力。TransR 通过将实体和关系投影到不同的实体空间和关系空间,解决实体和关系属于不同的对象,难以用同一个空间表示的问题。另外,针对TransR 参数过多,时间复杂度高等问题,TransD 使用两个投影向量生成两个投影矩阵Mh,Mr,让实体和关系实现交互。DistMult[26]模型和ComplEx[27]模型使用向量点乘计算三元组得分,利用概率判定三元组的正确性。KBGAN[28]模型提出一种生成对抗性学习框架来抽取负样本,在一些基准数据集上取得了显著效果,可以应用于大型知识图谱补全任务。文献[29]提出一种新的语义图推理方法,通过将新实体链接到知识图谱中,进而对知识图谱进行补全,该方法获得较为先进的实验结果。
2.2 神经网络模型
嵌入模型仅仅关注三元组的结构信息,没有对三元组同维度属性进行深入研究,不能深层次挖掘实体和关系特征。基于这个原因,很多工作开始使用卷积神经网络补全知识图谱,DKRL[30]使用两种表示学习方法,连续词袋(CBOW)以及卷积神经网络(CNN)来建立实体描述文本的语义向量。文献[31]提出一种基于CNN 的链接预测模型,ConvE将实体和关系向量的重组作为模型的输入,实体和关系间的交互是通过卷积层和完全连接层建模的。此外,该模型利用CNN 可以高效训练三元组,获取实体和关系的嵌入表示,同时学习三元组更多的特征。ConvE将头实体和关系向量作为模型的输入,没有考虑三元组全局信息,忽略了三元组的全局特征,为此,文献[22]提出ConvKB模型,该模型将三元组矩阵[vh,vr,vt]作为输入,和不同滤波器进行卷积操作,通过打分函数得到每个三元组的得分,作为判断三元组正确的依据。上述两个模型均利用卷积神经网络提取实体和关系的嵌入表示,捕获实体间的复杂关系,适用于大规模知识图谱补全。ConvKB 使用卷积层对知识图谱中三元组信息进行编码,但输入层和输出层神经元过于简单,不能深层地挖掘实体和关系的嵌入表示。受文献[23]的启发,用一组胶囊代替神经网络每层神经元,胶囊使用矢量作为模型的输入、输出,能够很好表征实体和关系。算法中,输入一个三元组矩阵[vh,vr,vt],在CNN 中卷积生成不同特征图,连接特征图得到多个胶囊(即一组神经元的集合),通过和权重点乘生成一个连续向量,该向量和权重点积操作的分数用于判定三元组正确性。利用胶囊网络嵌入方法进行知识图谱补全任务,可以有效提高知识图谱补全准确性。以上部分模型的打分函数如表1所示。

表1 模型打分函数
3 算法设计
3.1 相关算法
由于TransE模型具有以下特点:(1)模型参数少,计算复杂度低;(2)简单有效,适用于大规模知识图谱补全。将TransE 训练得到的实体、关系嵌入,作为本文算法的输入,胶囊网络算法伪代码如下。在KG=(E,R,T)中,E 是实体集合,R 是关系集,T 是所有数据集,根据不同比例划分成训练集、测试集和验证集。
Input:Training set S=(h,r,t),entities and relation sets E
and R,margin γ,embeddings dim K.
2. r ←r/||r||for each r ∈R
4. Loop:
5. e ←e/||e||for each e ∈E
6. Sbatch←sample(S,b) //sample a minibatch of b
7. Tbatch←∅
8. for(h,r,t)∈Sbatchdo
9. (h′,r′,t′)←sample(S′(h,r,t))
10. Tbatch←Tbatch⋃{((h,r,t),(h′,r′,t′))}
11. end for
12. update embeddings w.r.t:
14. Input ←[vh,vr,vt]//input matrix
16. update loss function w.r.t:
18. End Loop
3.2 算法架构
本文模型图如图2所示。
vh,vr,vt是h,r,t 的K 维嵌入,参照文献[13],将嵌入三元组[vh,vr,vt]定义为一个矩阵表示A=[vh,vr,vt]∈RK×3,其中,Ai,:∈R1×3代表A 的每行。在卷积层使用过滤器ω ∈R1×3和Ai,:重复卷积操作,令 ||ω =N ,产生N 个特征图q=[q1,q2,…,qN]∈RK,其中,qi=g(ω ⋅Ai,:+b),⋅代表点乘操作,b ∈R 是偏置项,g 是非线性激活函数。
上述介绍了卷积层操作,下面将使用胶囊层构建基于胶囊网络的知识图谱补全算法,以简化模型架构。在第一层,使用卷积得到的N 个特征图重构成K 个胶囊(V1,V2,V3,V4,V5,V6),所有特征图同维度特征被封装进相应胶囊,如图2 所示。因此,每个胶囊可以捕获嵌入三元组相应维度不同特征,这些胶囊和不同的权重点积生成较小维度的胶囊,得到一个个连续矢量;然后该矢量和权重向量再次进行点积运算获得对应得分,所有分数求和的结果用来判断给定三元组的正确性。得分越低,三元组越正确。图2中,嵌入大小定义为:K=6,滤波器的数量为:N=5,第一层胶囊内神经元数量等于N ,第二层胶囊内神经元数量:d=2。
第一层包含K 个胶囊,每个胶囊i ∈{1,2,…,K}产生一个矢量输出Vi∈RN×1,矢量输出Vi和权重矩阵Wi∈Rd×N相乘产生矢量vi∈Rd×1,将矢量vi和不同权重点乘生成胶囊s,s 作为第二层输入,继续和权重作点乘,得到一个个分数,最终求和判断三元组正确性,如式(1)所示:
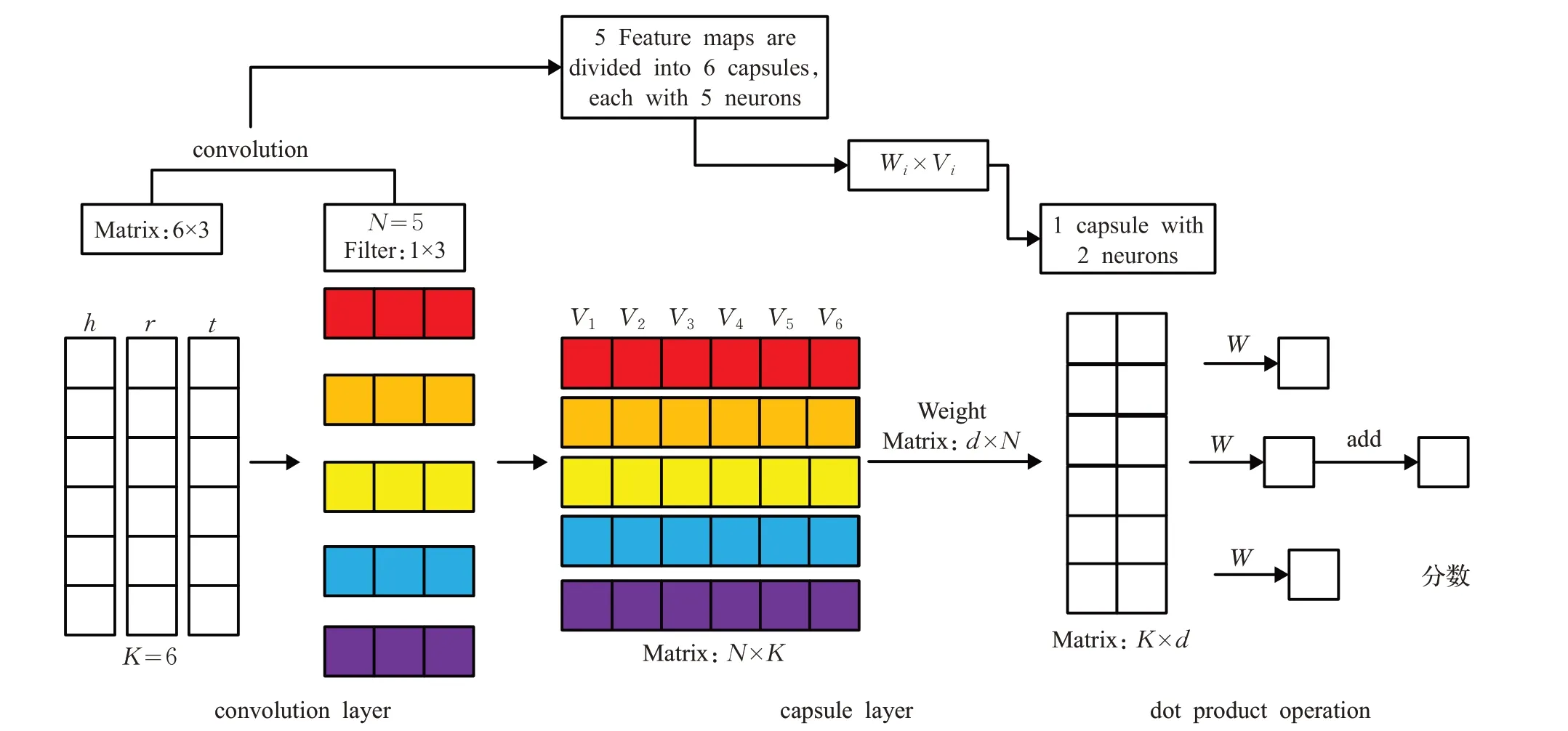
图2 算法架构

形式上,定义三元组打分函数,如式(2)所示:
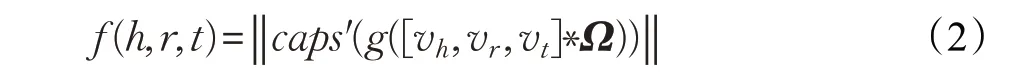
其中,滤波器集Ω 是卷积层的共享超参数,*表示卷积运算符,caps′表示胶囊网络操作,g 代表激活函数,本文使用ReLU。本文将最小化以下的损失函数作为模型最终的训练目标,损失函数如式(3)所示:


负例三元组构造方法如式(5)所示,即将正确三元组头实体和尾实体分别用数据集所有实体代替。

本文使用Adam[32]最小化如式(3)所示的损失函数,使用ReLU 作为算法激活函数。
4 实验
4.1 数据集
在三个广泛使用的数据集WN18RR[31]、FB15k[13]、FB15K-237[33]上评估实验。数据集FB15k包含很多反转关系,例如:朋友关系、夫妻关系。参照文献[33],将数据集FB15k中所有具有反转关系的三元组过滤掉,得到数据集FB15K-237。同理,去掉数据集WN18所有反转关系,得到WN18RR。
WN18RR大约包含40 943个具有11种不同关系的实体,93 003个三元组,参照文献[33],分为训练集、验证集、测试集3种。
FB15k 大约包含14 951 个实体,具有1 345 种不同的关系,592 213个三元组。知识图谱中描述了电影、演员、奖项和体育等三元组类型。
FB15k-237大约包含14 541个具有237种不同关系的实体,310 116 个三元组,参照文献[33],划分成训练集、验证集、测试集3种。
数据集统计情况如表2所示。

表2 数据集统计
4.2 参数设置
参照文献[13]和文献[22]提出的TransE模型和ConvKB模型实现本文算法。本文首先使用TransE 模型训练三元组,得到实体嵌入表示和关系嵌入表示,将三元组矩阵[vh,vr,vt]作为本文算法的输入。对于ConvKB模型,设定过滤器数量的范围是: ||ω =N ∈{50,100,200,400},Adam 初始化学习率是:γ ∈{0.000 01,0.000 05,0.000 1,0.000 5},利用超参数网格搜索训练模型500 次。其中,每训练100次,监测一次Hits@10得分,以选择Hits@10最优超参数。最优超参数设置如下:在FB15K-237上,Hits@10最优设置:N=100,K=100,γ=0.000 01。在WN18RR 上,Hits@10 最优设置:N=400,K=100,γ=0.000 05。
与文献[22]类似,使用TransE训练生成的实体和关系嵌入初始化本文算法实体和关系嵌入,用于三个基准数据集WN18RR、FB15k-237 和FB15k,嵌入维度K=100。设置批处理大小batchsize为128,即每次训练128个三元组;第二个胶囊层中的胶囊内神经元数量设置为10(d=10);权重w 最初由截断函数初始化,最终由模型训练后确定。训练算法多达500 次,平均每100次监测Hits@10,以选择最优Hits@10超参数:验证集上最优Hits@10 如下:在FB15K-237 上,最优Hits@10:N=100,K=100,γ=0.000 1,d=5。在WN18RR上,最优Hits@10:N=400,K=100,γ=0.000 05,d=10。
4.3 链接预测
4.3.1 实验设计
链接预测是指预测知识图谱缺失的三元组,即三元组中缺失的实体或关系。例如:给定三元组(Michelle Obama,residence,?),其中,头实体为Michelle Obama,关系为residence,尾实体缺失,为补全三元组,将知识图谱中正确尾实体添加到该元组中,对其进行补全操作。实验中,对于缺失的实体或关系,从知识图谱实体集中选择一组候选实体进行排名,而不是仅给出一个最佳结果。参照文献[13]和文献[15],对测试集中每个三元组,用所有实体替换头实体或尾实体来创建一组负例三元组。对这组负例三元组使用打分函数计算它们的相似性得分,以此对它们进行排名,相似度越高排名越靠前,由此可以得到正确实体的真实排名[15]。
4.3.2 评估指标
参照文献[13],使用以下三个指标作为评估标准:(1)正确实体的平均排名MR(MeanRank),越小越好;(2)正确实体的平均倒数排名MRR(Mean Reciprocal Rank),越大越好;(3)正确实体进入前10 的百分比Hits@10,越大越好。实际上,知识图谱中也可能存在错误三元组,认为是正确的。因此,本文采用文献[13]的标准,从数据集中过滤掉错误的三元组。过滤后的设置称为Filter,原来的称为Raw。另外,在数据集FB15K-237和WN18RR上,仅使用Filter设置,即不考虑错误的三元组。
4.3.3 实验结果和分析
本文实验环境为:实验环境为Window 7 64位系统,物理内存为8 GB,使用独立显卡芯片:NVIDIA GeForce GT 720M,显存容量为2 GB。实验工具为Pycharm,使用Python 3.6作为编程语言编写程序,深度学习框架采用TensorFlow。在实验中,MRR和Hits@10最优参数设置为:N=400,K=100,γ=0.000 05,d=10。数据集WN18RR链接预测结果如表3所示。
从表3可以看出,基于胶囊网络的知识图谱嵌入方法在WN18RR 上获得最好MR、MRR 和最高Hit@10。具体分析如下:(1)和CapsE模型相比,数据集WN18RR在MR 上有1.8%的提高,在Hit@10 上有3.5%的提高;和ComplEx模型相比,数据集WN18RR在MRR上提高5.4%。(2)TransE 模型的MR 指标优于ConvE、ComplEx等模型;TransE模型的Hit@10指标优于ConvE、DistMult等模型。从中可以看出,基准嵌入模型TransE在数据集WN18RR上具有很好的表示效果。(3)和其他模型相比,本文方法在数据集WN18RR 上具有更好的补全能力,也说明了胶囊网络用于知识图谱补全性能更好。

表3 数据集WN18RR实验结果比较
MRR和Hit@10最优参数设置为:N=100,K=100,γ=0.000 01,d=5。数据集FB15K-237 链接预测结果如表4所示。

表4 数据集FB15K-237实验结果比较
从表4可以看出,基于胶囊网络的知识图谱嵌入方法在数据集FB15K-237 上获得最好的MR 和最高的Hit@10。具体分析如下:(1)和ConvE 模型相比,数据集FB15K-237 在MR 上提高2.5%,ConvE 模型在MR 指标上优于所有模型。(2)和CapsE 模型相比,数据集FB15K-237 在Hit@10 上提高2.5%,MRR、Hit@10 指标优于TransE、ComplEx 等模型,可以看出,CapsE 模型在数据集FB15K-237 上具有很好的表示效果。(3)和其他模型相比,本文方法在数据集FB15K-237上具有更好的补全效果,这也说明胶囊网络可以用于大规模知识图谱补全。
4.4 三元组分类
4.4.1 实验设计
三元组分类即判断一个给定三元组的正确与否,这是一个二分类任务。引用文献[13,15]提出的三元组分类任务,设置一个阈值,对于任意一个三元组,使用式(3)所示的打分函数计算三元组得分,如果这个得分低于阈值,则三元组是正确的,否则为错误三元组。
4.4.2 实验结果和分析
参照文献[15],使用基准数据集FB15K进行三元组分类实验。实验环境与4.3.3节相同。FB15K最优参数为:N=400,K=100,γ=0.000 1,d=8。实验结果如表5所示。

表5 三元组分类实验结果比较
从表5中可以看出:本文方法在数据集FB15K上实现了92.5%的准确率,这表明胶囊网络在三元组分类任务中效果显著,相比其他模型,准确率较高。另外,实验结果可以看出,胶囊网络用于知识图谱补全性能更好,并可以应用于大规模知识图谱补全。
5 结束语
本文针对知识图谱补全提出一种基于胶囊网络的方法,即利用胶囊代替神经元建模实体和关系的嵌入表示,输入三元组矩阵,输出三元组真实得分,利用该分数判定三元组正确性,将正确的三元组添加到知识图谱,对KG进行补全。在三元组分类实验中,本文方法取得92.5%的准确率,优于一些传统嵌入模型;在链接预测实验中,本文方法在MR、MRR、Hit@10 指标上均有明显提高,这表明本文方法可以有效解决知识图谱数据稀疏问题,提高知识图谱完备性。为提高链接预测和三元组分类准确率,在今后的研究中,将从两方面进行探索:
(1)本文模型较为简单,提取三元组有一定误差。下步工作将重新设计模型并引入更有意义的算法来补全知识图谱。
(2)外部数据源含有大量实体描述文本,考虑将实体和关系的描述文本合并到胶囊网络中作为模型的输入。
