自适应聚合策略优化的密度峰值聚类算法*
2020-04-15钱雪忠
钱雪忠,金 辉
江南大学 物联网工程学院 物联网技术应用教育部工程研究中心,江苏 无锡 214122
1 引言
随着信息技术和互联网的快速发展,数据源的多样化和数据量的高速增长,如何进行大规模的数据挖掘和快速获得有价值的信息成为近期研究的焦点。聚类分析作为一种重要的数据挖掘技术,广泛应用于模式识别、图像处理、机器学习、信息检索等领域。聚类是一个根据样本间的相似性将数据集划分成簇的过程,使得簇内的对象最大程度地相似,同时不同簇间的对象最大程度地相异。
在聚类分析的发展过程中,相继提出了DBSCAN[1](density-based spatial clustering of applications with noise)、FCM(fuzzy C-means)、AP(affinity propagation)等一系列的具有代表性的聚类算法。2014年Science[2]上发表了一篇Clustering by fast search and find of fast search(DPC),论文提出一种快速搜索和发现密度峰值的聚类算法。该算法简单高效,无需迭代,性能不受数据空间维度影响自动给出数据集样本的类簇中心,而且对数据集样本的形状没有严苛的要求,对任意形状的数据集样本都能实现高效的聚类。然而DPC 算法也存在一些缺陷:算法需要设置截断距离dc,算法的准确性需要依赖截断距离dc的选择和对数据集的密度估计;算法使用欧氏距离定义样本之间的相似性来计算局部密度,存在局限性;聚类中心的选择需要人工干预而且有的时候聚类中心的选择不是那么明显,选择起来有一定的困难等。
针对DPC 聚类算法存在的不足,Xu 等[3]提出将网格划分和圆划分的方法应用于DPC 算法来筛选点,提出基于网格划分的密度峰值聚类算法和基于圆划分的密度峰值聚类算法,都能降低算法复杂度,前者的计算时间更短,后者在大规模数据集上的准确度要高于DPC 算法。Du 等[4]提出一种基于K近邻的快速密度峰值搜索并高效分配样本的算法KNNDPC(study on density peaks clustering based onKnearest neighbors and principal component analysis),解决了DPC 算法聚类结果对截断距离dc比较敏感和因为一步分配所带来的连带分配错误的问题,但是该算法的聚类结果对近邻数K的选取比较敏感。针对如何准确获取密度峰值聚类算法聚类中心的问题,文献[5-6]提出了新的获取聚类中心的策略,并且较少受到参数影响,提高了聚类的准确率,但是在处理复杂数据[7-10]和大数据时稍显不足。
本文针对上述遇到的问题,提出了自适应聚合策略优化的密度峰值聚类算法AKDP(optimited density peak clustering algorithm by adaptive aggregation strategy)。AKDP 算法根据数据点的K近邻数来计算每个数据点的局部密度[11-16],然后用一种新的方法来确定初始聚类中心,最后提出类簇间密度可达的概念来聚合相似度高的类簇,实验证明AKDP 算法具有更加优秀的聚类效果。
2 局部密度和初始类簇中心
密度峰聚类DPC 算法基于这样的假设:聚类中心具有比其邻居更高的局部密度,并且与其他中心的距离相对较大[17-19]。为了建立决策图然后找到理想的聚类中心,DPC 计算每个点i的两个量:由式(1)定义的局部密度ρi和由式(2)定义的和更高密度点的距离δi。

其中,dij是点i和点j之间的距离,dc是用户输入的截止距离,其可以根据百分比参数p计算得到,p则表示数据对象的近邻数占总样本数的平均百分比,一般情况下p在1~2 取值时,DPC 算法能够取得较好的聚类效果。如果t<0,则χ(t)=1,否则χ(t)=0。对于具有最高密度的点,其Δ取为δi=maxj(dij)。在计算所有点的密度和Δ值之后,DPC 绘制决策图,其由点的集合(ρi,δi)组成。可以在决策图的右上区域找到聚类中心,这些聚类中心是具有高δ和相对高ρ的点。通过聚类中心,DPC 可以在一个步骤中将剩余的点分配给与其最近的较高密度的邻居相同的聚类。结果,DPC 的执行是有效的。具体地,对于“小”数据集(例如,对于声纳数据集),难以对密度进行可靠的估计。因此,DPC 采用式(3)给出的另一个密度度量来计算局部密度。

然而,它没有客观的度量来决定数据集是小还是大,而使用这两个密度指标进行聚类会产生非常不同的结果。此外,对于小型数据集,即使使用式(3)计算局部密度,DPC 的聚类结果也会受到截止距离dc的极大影响。为了消除截止距离dc的影响并为任何大小的数据集提供统一的密度度量,本文将引入K最近邻居的思想来计算局部密度,采用一种新的方法来选择初始聚类中心,并且提供一种新的聚合策略来聚合初始的类簇。
为了使得核心区域中的点更易于区分其他区域中的点,也为了提供一个统一的密度度量,通过使用高斯核函数提出了基于K最近邻概念的新密度度量,这将有助于群集获得更准确的结果。相对于原先的局部密度度量计算不同数据集需要的不同度量方式,本文提出的局部密度度量减少了算法的人为选择,也使算法更易区分类簇中心。为了简化算法使算法具有更高的普适性和减少人为的干预,将截断距离dc定义为一个普适性的公式,使算法更加智能。因此,本文提出了一种新的局部密度定义公式,如式(4)所示:

其中,N指的是数据点的个数,指的是数据点i和它的第K个近邻之间的距离,uk指的是所有数据点和它的第K个近邻之间的距离的平均值,即所有数据点的值的平均值。为了AKDP 算法的聚类效果,定义了一个确定初始聚类中心的阈值α,如式(5)所示:

3 聚合策略
为了使AKDP 算法更加智能有效地将数据集进行有效的聚合分离,本文基于以下的定义提出了一种新的有效的聚合策略。
定义1(簇核距离(core-distance of a cluster))一个类簇u的核距离,表示为σu,定义为:

其中,|Cu|指的是类簇u中的数据点的个数,di,center指的是数据点i和类簇中心之间的距离。
定义2(边界点对(border-points-pair))在类簇Cu和类簇Cv之间的边界点对,表示为,定义为:

定义3(边界密度(border-density of a cluster))类簇u的边界密度表示为,定义为:
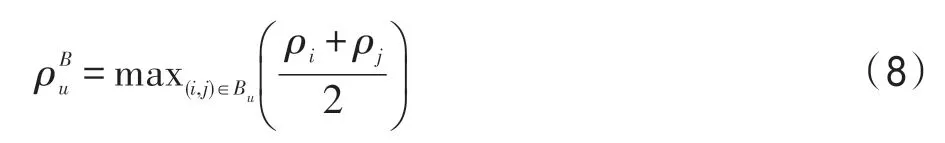
其中,Bu是类簇u和数据集中所有其他的类簇的边界点对。
定义4(密度直接可达(density directly-reachable))一个类簇u和一个类簇v可以通过边界密度直接密度可达,只要满足以下条件:
即类簇u和v之间存在边界点对,且存在边界点对满足第二个条件。
定义5(密度可达(density reachable))如果存在类簇u和类簇w直接密度可达,类簇w又和类簇v直接密度可达,那么说类簇u和类簇v是密度可达的。
通过以上定义,在实验中如果发现两个类簇之间是密度可达的,那么就会合并这两个类簇。通过自适应合并策略,可以找出所有的初始类簇中心,但是这些初始类簇并不一定就是最好的聚类结果,它们之间具有一定的相似性,通过类簇间密度可达合并相似类簇,不会遗漏掉类簇原本的类簇中心,也大大提高了算法的准确性。
根据以上理论,提出AKDP 算法,AKDP 算法的主要优点:
(1)用一种新的基于K近邻的公式来计算数据点的局部密度,避免了参数敏感问题,提高了算法对数据集的普适性;
(2)算法自适应策略给出的初始阈值可以找出所有的初始类簇中心,确保不会遗漏掉真实的类簇中心,有效提高算法准确率;
(3)用一种有效的、无参的聚合策略来产生最后的结果,合并相似度高的类簇,提高聚类效果。
算法AKDP:


假设AKDP 算法要处理的数据集有N个数据点,存储每个点到第K个近邻点的距离需要K×N个空间;其次,存储每个数据点的δ和ρ值,需要2×N个空间;最后,存储边界点对集合最多需要N2个空间,因此AKDP 算法的空间复杂度是O(N2)。
AKDP 算法的时间复杂度由以下几点决定,计算数据点之间的距离的时间复杂度是O(N2),但可以用快速排序降至O(N×lgN),每个数据点的边界点的数量理论上可以达到N,计算边界点对的时间复杂度为O(N2),因此AKDP 算法的时间复杂度为O(N2)。
AKDP 算法对参数K的选择遵循一定的规律,一般先选择数据样本的10%作为初始值,聚类个数如果偏多则增加K的值,反之减小K的值。
4 实验结果与分析
为了证明AKDP 算法的有效性,将AKDP 算法与DPC[2]、DBSCAN[1]、KNNDPC[4]算法在合成数据集和UCI 数据集上进行实验,真实数据集上加上了Kmeans 算法进行对比。图1 显示了4 个合成数据集。Data1由两个不平衡的流形类组成,共567个点。Data2由3 个复杂流形类组成,共3 603 个点。Data3 由7 个复杂球形类组成,共788 个点。Data4 由31 个高密度复杂球形类组成,共3 100 个点。对于DPC 算法、KNNDPC 算法和DBSCAN 算法,进行多次实验取效果最好的结果进行对比,但DPC 算法和KNNDPC 算法在人为选择聚类中心时要符合选取聚类中心的一般规则。
图2 显示了Data1 在DPC、DBSCAN、KNNDPC和AKDP 算法上的聚类效果。DPC 算法能聚类正确的类簇数,也可以将所有点准确聚类,聚类效果较好,KNNDPC 算法同样可以准确聚类,DBSCAN 算法无法准确确定类簇的个数,聚类效果不好,错误地将一个类簇的点聚类成了两个类簇,AKDP 算法能准确聚类,聚类效果也很好,明显比DBSCAN 算法聚类效果要好,总之在Data1 数据集上,DBSCAN 算法聚类效果不好,DPC 算法、KNNDPC 算法和AKDP 算法可以准确确定类簇的个数且聚类效果很好,但是DPC算法和KNNDPC 算法需要一定的人为选择,有不确定因素。
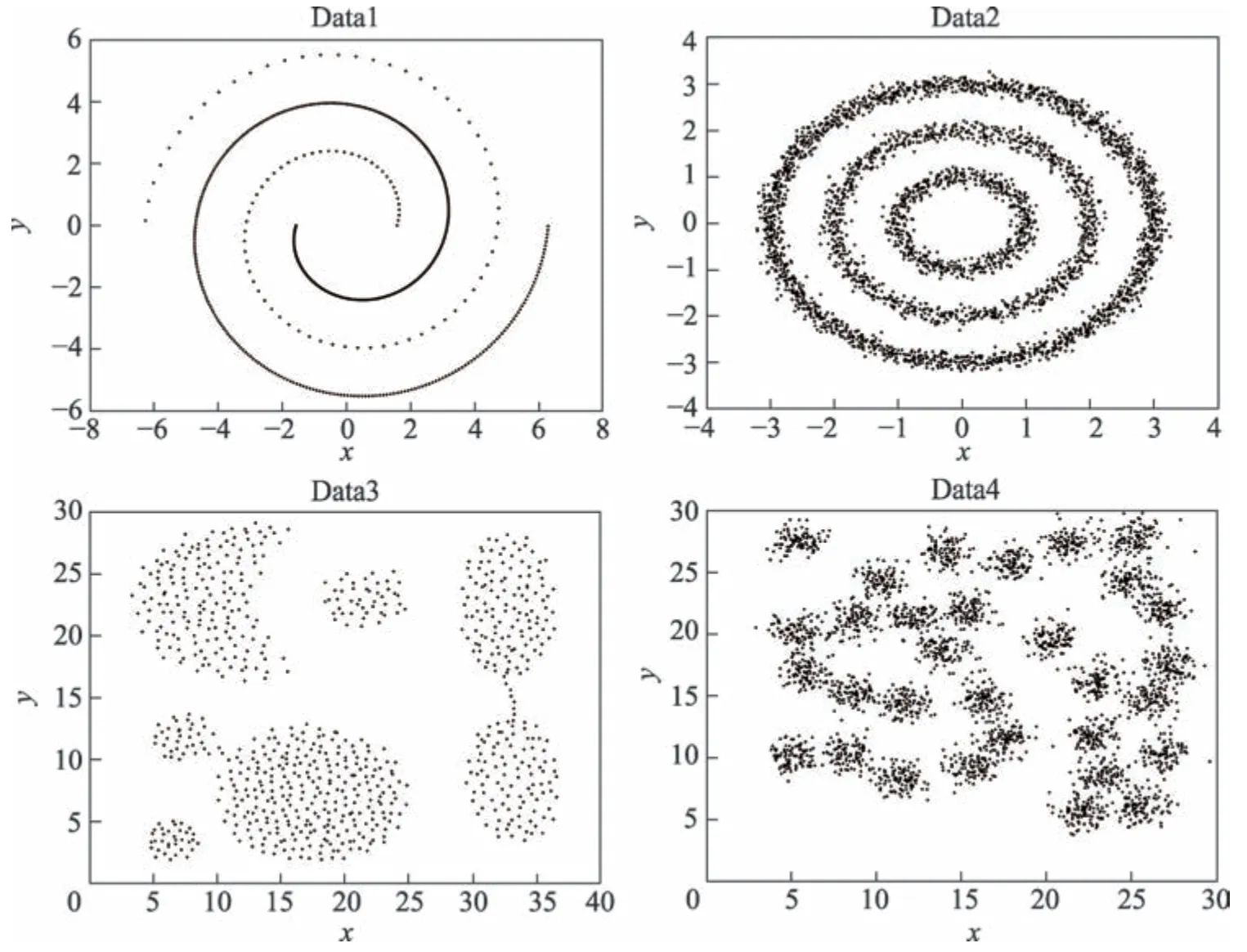
Fig.1 Original dataset图1 原始数据集
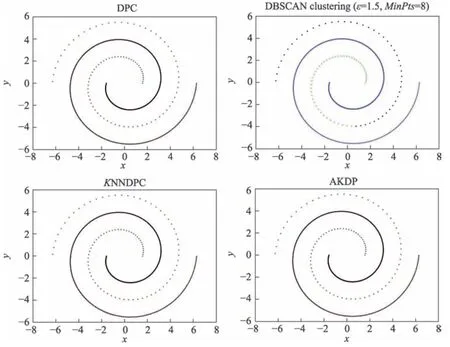
Fig.2 Clustering results of DPC,DBSCAN, KNNDPC and AKDP on Data1图2 Data1 在DPC、DBSCAN、KNNDPC、AKDP 上的聚类结果
图3 显示了Data2 在DPC、DBSCAN、KNNDPC和AKDP 算法上的聚类效果。DPC 算法虽然选择了正确的类簇数,但无法将所有点准确聚类,聚类效果不好,KNNDPC 算法同样只是将复杂流形簇距离近的点聚为一类,DBSCAN 聚类算法和AKDP 算法都能准确聚类,聚类效果都很好,但是DBSCAN 算法需要更多的参数。
图4 显示了Data3 在DPC、DBSCAN、KNNDPC和AKDP 算法上的聚类效果。DPC 算法对球形簇的聚类效果很好,对复杂流形簇也有一定的聚类效果,但是对Data3 数据集显然没有取得很好的聚类效果,将离得近的一大两小三个球形数据集错误地聚为一个类簇,KNNDPC 算法存在和DPC 算法类似的问题,错误地将两个流形的数据集聚为一类,聚类产生偏差,显然DBSCAN 算法聚类效果优于DPC 算法和KNNDPC 算法,对数据集具有很好的聚类效果,但是DBSCAN 算法的参数需求更大,AKDP 算法能够准确确定类簇的个数,同时最后的聚类效果也十分优秀。
图5 显示了Data4 在DPC、DBSCAN、KNNDPC和AKDP 算法上的聚类效果。DPC 算法和KNNDPC算法虽然选择了正确的类簇数,聚类效果也很不错,但是聚类时间较长,且在人工决策图上需要选出的聚类中心点多且密集,稍有偏差就会对聚类效果产生不好的影响,DBSCAN 获得了正确的类簇数,也获得了好的聚类效果,但是同样的需要较多的参数,AKDP 算法获得了正确的聚类数并获得了很好的聚类效果,人为影响较小。
因此,AKDP算法在Data1数据集上的聚类效果明显优于DBSCAN 算法,在Data2、Data3 上的聚类效果明显优于DPC算法和KNNDPC 算法,且比DBSCAN需要更少的参数,比DPC 算法和KNNDPC 算法需要人为干预的更少,具有一定的鲁棒性。
接着,将AKDP 算法在UCI 数据集上进行实验,数据集信息如表1 所示。
在实验中,采用Acc(准确率)、F-measure(加权F值)和算法聚类个数与正确的类簇数的比这3 个聚类指标来评价AKDP 算法,并将AKDP 算法与DPC、DBSCAN、KNNDPC、K-means 算法对比,实验结果如表2 所示。

Fig.3 Clustering results of DPC,DBSCAN, KNNDPC and AKDP on Data2图3 Data2 在DPC、DBSCAN、KNNDPC、AKDP 上的聚类结果
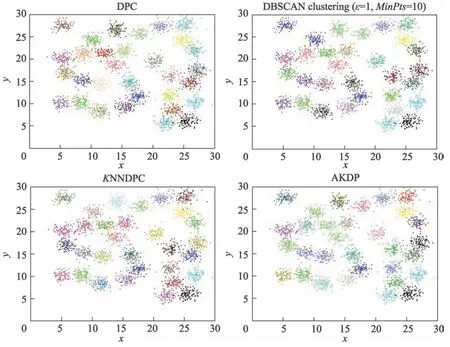
Fig.5 Clustering results of DPC,DBSCAN, KNNDPC and AKDP on Data4图5 Data4 在DPC、DBSCAN、KNNDPC、AKDP 上的聚类结果
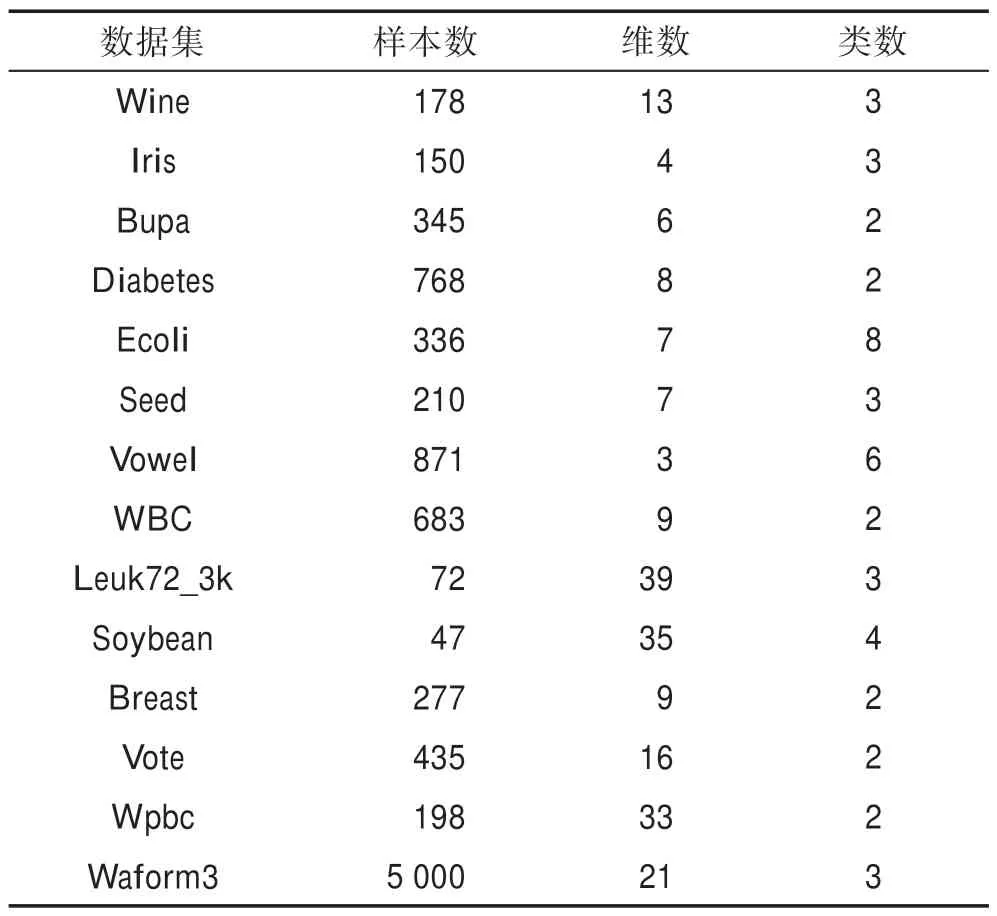
Table 1 Information of datasets表1 数据集信息
由表2 可知,在准确率上,除了在Vote 数据集上KNNDPC 算法比AKDP 算法高0.2 个百分点,在其他数据集上AKDP 算法要明显优于DPC、DBSCAN、KNNDPC 和K-means算法。
在F值的计算上,除了在Breast 和Wpbc 数据集上DBSCAN 要稍稍优于AKDP 算法,其他数据集上AKDP 算法都明显优于DPC、DBSCAN、KNNDPC 和K-means算法。
在最终聚类数的准确率上,AKDP 算法都能聚类出正确的类数,K-means 算法由于提前选择了正确的类簇数目,因此不存在能不能聚类出最终正确的类簇数这一评价指标,DNSCAN 算法在Ecoli、Seed、Waform3、Vowel 和Wpbc 数据集上无法聚类正确的类簇个数,而DPC 算法无法在Bupa、Ecoli、Vowel、Leuk72_3k 和Breast 数据集上聚类正确的类簇个数,KNNDPC 算法在Wine、Ecoli、Vowel 和Leuk72_3k 数据集上无法聚类正确的类簇个数。因此在聚类正确类簇个数这个评价指标上,AKDP 算法也是最优秀的。
综合这三方面,显然AKDP 算法是最优秀的。
5 结束语
本文提出了一种新的自适应聚合策略优化的密度峰值聚类算法AKDP。首先该算法通过最近K近邻的概念,用一个新的公式来定义数据点的局部密度,然后根据阈值判断初始聚类中心,最后通过类簇间密度可达概念来把相似的类簇合并产生最后的聚类结果。通过实验,AKDP 算法在对人工数据集、UCI 数据集和复杂流形数据集的处理上具有相当大的优越性,比DPC、DBSCAN、KNNDPC 和K-means算法更准确有效,且受人为影响更少。
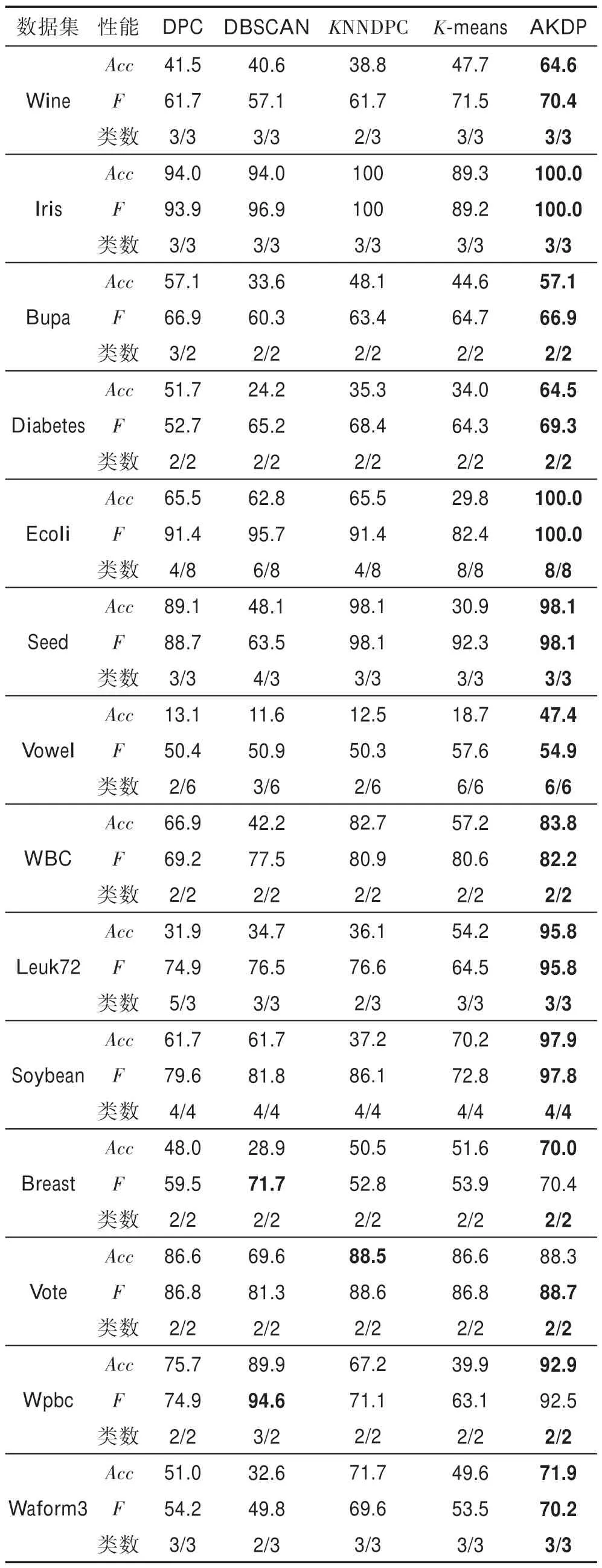
Table 2 Information of clustering index表2 聚类指标信息
