文档检索中文本片段化机制的研究*
2020-04-15李宇,刘波
李 宇,刘 波
暨南大学 信息科学技术学院 计算机系,广州 510632
1 引言
信息检索(information retrieval,IR)的直接目的是查找用户所关注的信息。IR 既包括常见的搜索引擎、文章推荐等各种系统,也包括一些嵌入在应用里面的隐式查询,如抖音、美团等通过用户历史数据来查找用户的兴趣点。IR 技术中使用的文本间相似度算法[1-3]在释义识别、语言研究、文本分类等领域也有着广泛的应用。本文研究的检索对象是长文本,即由句子构成的段落或文章。长文本具有信息量丰富且冗长的特征,对于要查询的信息,长文本匹配往往不是全部语句与查询语句都相关,还可能出现某些高相似片段的强干扰。在最新的研究中,许多学者将文本特征表达与相似性匹配结合起来[4-5],致力于在特定领域中探索不同文本表达式对应的相似度匹配方案,以提高检索准确率。
目前,文本长度较长时可能带来的负面影响:
(1)当文本较长时,一些体现查询意图的词、短语分散在文档中,整篇文档直接比较会影响关联匹配效果和整体检索性能。
(2)一些文本相关性计算方法或相似度匹配算法往往会受到长度的影响[6-7],检索出来的有效文本的质量很不稳定。

Fig.1 Analysis of related medical reports图1 关联医学报告的查询分析
如图1 中,与查询词hemophilia pseudotumor(血友病,肿瘤)关联的医学报告文档中,全长277 单词,9个长句,其中查询有关的词只出现6 次,但在5 个句子中有提及,频度低但分散程度均匀,使得采用一般计算方法所得的相关性整体得分偏低。
近年来,一些工作[8-9]在论坛、产品评论、微博、电影评论等短文本相似度计算及匹配研究方面取得了很好的成果。Chen 等人[10]提出了内容感知的主题模型,将高度相关的片段应用到主题模型的构建中,提高了主题分类的效果。短文本匹配的优点在于:相似性匹配方法比较直接,受到比较文本之间的长度差异影响小,区分度很高。但其不足在于:数据量小,缺乏上下文信息,一出现相同词眼便具有较高的相似度,又由于文本数据稀疏而难以对单词权重进行准确评估。
为了能提高长文本有价值部分的利用率,本文提出文本片段化机制(text snippet mechanism,TSM),其通过提取重要的短文本句子片段来度量查询与文档之间的相关性,目的是利用关键有效的文本片段信息提升文档整体相关性评分的参考价值,在一定程度上消除文档长度对相似度匹配的影响。本文的主要研究内容如下:
(1)如何实现长文本进行切分、记录、筛选、整合。
根据标点和一些特殊符号对文本进行切分,查询语句和候选文档看作是一个或几个文本片段组成,通过查询片段来检索相近内容的文档时,能关联出多个相似片段的文档。候选文档中提取的片段与查询片段之间的相似性越高,那么被提取的概率和设置的权重就越高。片段之间的比较可以很好地削弱噪声数据的影响,因为在某些候选文档中只匹配极少与查询相似度极高的片段,但高度的局部相似性并不意味着这些候选文档与查询内容相关。
(2)如何在片段化机制中对查询文本和候选文档的片段进行整体相关性评分。
本文在文本片段之间的相关性评估上,以统计模型BM25[11]和语义模型WMD(word mover's distance)[12]为基础,结合单词权重的相似度匹配方案来检索相关文档。在整体相关性评分中,考虑了候选文档筛选提取后的相关片段本身的相关性评分信息以及相关片段比率。
2 文本检索相关技术
在文本检索的研究中,主要涉及文本表达特征、相似度匹配、查询拓展、碎片化方法等方面的研究,相关技术成果介绍如下。
2.1 文本表达及相似度匹配
2.1.1 TF-IDF 和BM25
TF-IDF(term frequency-inverse document frequency)是一种基于语料库的统计方法,它通过词的频率和词在文档集中的分布密度来反映词的重要性,然后将所有词的权重映射到一个固定的向量空间中,可应用于文本表示。现在已经开发出许多改进的TFIDF 形式的变体[13],研究人员利用这些变体计算向量空间之间的余弦,完成分类或相关匹配任务。然而,这种向量空间的表示是稀疏的,忽略了词频的增长限制和词汇间的相关信息。
Robertson 等人[11]提出了一个相似度评分标准BM25,专门用于查询语句和候选文档之间的相关性匹配。为了估计查询语句Q和候选文档D的相关性,BM25 公式定义为如下:

其中,q表示查询语句Q的查询项(单词),|DSet|表示文本集中的文档总数,len(D)表示当前文档单词总数,nq表示在语料库中有多少文本出现查询项q,qf表示查询项q在查询文本Q中的词频,f表示查询项q在候选文档D中的词频,b、k1、k2是需设置的超参数,avgl是文本语料库中文档的平均长度。式(2)用于计算逆向文档频率(inverse document frequency,IDF)。
BM25 分解查询中的每个单词项q,计算q与候选文档D之间的相关得分,并对所有相关得分进行加权求和。BM25 考虑了词频上限和文档平均长度对文本相关性得分的影响。但文献[14]发现,由于文章长度平均值的设置,BM25 搜索功能在实践中往往会过度惩罚有用的长文档。Na 等人[15-16]提出了文本冗余的概念,将BM25 改进为vnBM25,修正后的公式可以有效地缓解文章长度的冗余影响。
2.1.2 词嵌入模型和WMD
考虑到词语出现的顺序是文本表达的重要因素,Bengio 等人[17]提出了神经网络语言模型(neural network language model,NNLM),产生了词嵌入文本表达方式,如word2vec,以及统计概率模型的产物glove[18]。word2vec 的核心思想是从大量的上下文信息中学习单词的语义信息[19],词汇的语义表征值映射到k维实空间中的向量(k是一个可设置的超参数),即词向量。
Kusner 等人[12]在词向量的基础上提出了词移距离(WMD),从文本转换成本的角度计算两文本对象的相似度,该思想来源于测地距离(earth mover's distance,EMD)[20]:一种线性规划中求解多工厂多仓库运输问题最优解的方法。Kusner 将查询文本的每个词向量视为工厂,并将候选文档的每个词向量视为仓库。相关性越强,运输转换成本越低。假设将查询文本Q转换为文档D,WMD 公式如下:
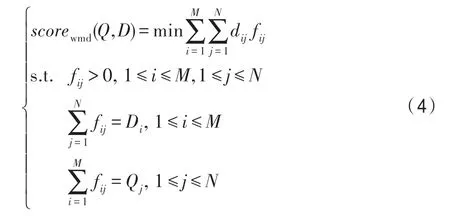
其中,单词i和单词j分别在文档Q、文档D中;文档Q、D中出现的单词总数分别为M、N;dij代表单词i、j之间的距离,一般可以用向量之间的欧几里德距离表示;fij表示单词i转换为单词j的成本;Di、Qj为单词i和单词j用归一化词袋模型表示的值,即单词在所在文本中的出现比率。
2.2 查询扩展技术
查询扩展(query expansion,QE)是目前文本检索的常用手段。Hao[6]在问答研究中提出了基于wordnet的针对问题目标词扩展方法,显著提高了目标词与回答类型匹配的准确性。Guo 等人[21]将实体的复杂关系一块记录在文本数据中,构造语义关系网络,用于扩展查询和启发式查询。Blei 等人[22]提出的生成概率模型(latent Dirichlet allocation,LDA),采用文档、主题和单词的三层结构来挖掘主题对应的单词分布,相关研究者[23]利用LDA 模型在检索前挖掘查询文本的主题,并根据所属题目的词类分布情况添加扩展词。
除了直接从输入文本扩展单词外,还有其他使用伪相关反馈技术的扩展方法[4,24]。反馈信息包括一些训练模型的结果和一些实时数据或日志,记录了在线用户的点击、阅读停留时间、反馈意见等操作。通过分析反馈信息,补充一些有用的特性并用于重新查询。但获取高质量的相关查询词是一个挑战,因为一个简短的查询常常不能完全传达用户的搜索意图,使得查询扩展的方向具有不稳定性。查询扩展词的不精确会导致检索性能下降。许多实验表现出QE 方法的性能不如原始查询。
2.3 文本片段机制
Rathod 等人[25-26]研究发现,探索和利用包含多个相关且不同单词的片段,往往比将这些单词直接加入查询进行检索更有效,因为扩展的内容(特别是对于一般的、模糊的查询)可能与查询无关。许多相似性匹配方案往往受到长文本长度的影响[27]。Ceccarelli等人[28]证明了高质量短文本片段对用户查询具有较高的价值,可以显著提高查询的检索性能。Chen 提取了有效的上下文片段,增强了主题模型的主题预测能力,在训练过程中建立了一种新的分段提取判断规则,将其从主题模型中分离出来,使实验更具可调整性。
受上述思想的启发,本文利用标点符号切割(句号、分号等)方法得到大量的文本片段,并利用相似度计算结果选择出高质量的文档片段。该方法通过提取重要的短文本句子片段来度量查询与文档之间的相关性,更好地消除文档长度对相似度匹配的影响。
3 信息检索中的文本片段机制
本文利用标点符号切割(句号、分号等)方法得到大量的文本片段,并利用相似度计算结果选择出高质量的文档片段。该方法通过提取重要的短文本句子片段来度量查询与文档之间的相关性,结合上下文并更好地消除文档长度对相似度匹配的影响。
相对于已经提出的许多片段化方式,提出的TSM 目的是提取与查询有关的短文本并进行相关度整合,包括片段筛选和相关性分数的整合计算过程。发现筛选过程产生的相关片段比例在评估文档相关性中是一个非常重要的因素,它可以大大减少部分短文本高度相似偏向的影响。
3.1 基于文本片段机制检索模型概述
本节提出了一种用于信息检索的文本片段机制TSM,图2 显示了TSM 检索模型的框架。它分为三个模块,即预处理模块、相似度匹配模块、片段管理模块。如图2 中所示,主模块对文本进行分词、删除停止词与词干等预处理,相关的候选文档集通过倒排索引库获得,显示最后的排序结果。片段机制管理模块对相关候选文档进行的一系列文档片段操作,包括文本切割、片段间相关性计算、记录片段信息、筛选相关片段、集成计算和文档排序。相关性计算所涉及到的相似度匹配算法等都封装在相似度匹配模块中。图3 展示了基于TSM 的检索处理流程示例,分为如下三个阶段。

Fig.2 Framework of retrieval model by TSM图2 TSM 检索模型运行流程
第一阶段:文件切割。查询文本和候选文档将被标点符号和一些特殊符号分割。
第二阶段:记录片段信息。通过不同的相似度匹配对候选文档中的每个片段进行评分。查询和被查询片段的文本特征表示与使用的相关性度量有关。如果使用BM25,则将文本单词的TF-IDF 值作为文本特征;如果使用WMD,则将语义词向量作为文本特征。
第三阶段:提取、整合计算、排序。提取每个候选文档的高度相关文本段,并记录相关片段比率(相关片段比率是指高度相关片段占整个文档片段的比例);对收集的相关片段记录元组综合排序分配权重,根据整合公式计算出查询与候选文档相关度总分,并根据总分排序。
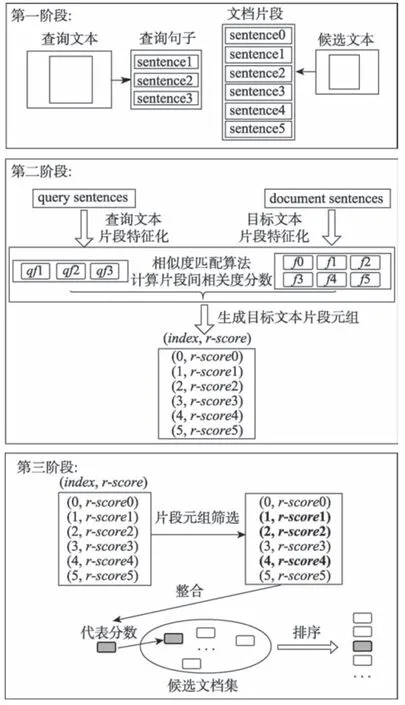
Fig.3 Processing flow of snippet model图3 片段化管理模块处理过程
例如,在图3 中,假设候选文档由六个句子组成,而查询由三个句子组成。在候选文档中记录句子片段,用元组(index,r-score)表示,其中index是在候选文档中句子片段的位置,r-score是这个句子片段与查询句子计算后的相关分数。筛选后得到的相关片段以粗体显示(本例是文档中的第一个、第二个和第四个句子片段),它们的相关分数参与整合运算,结果为该文档的最终相关性得分,并依据该得分参与检索结果排序。
本文方法可以嵌入现有典型搜索方法中,如在Lucence 全文检索引擎框架中应用本文方法是可行的。在第一阶段,文档片段来源于候选文本集,可以利用Lucence 本身的倒排索引与评分体系得到候选文本集,大大减少所需要片段化的文档数量,接着候选集文本可以经过TSM 的处理,进一步筛选片段,并参与后续的相关度整合计算。将本文提出的片段化机制与现有搜索方法相结合,发挥了短文本匹配的优势,同时考虑了上下文信息以及各片段的重要度,能够提高检索的准确性。
3.2 片段相关性评分及相关片段比率
有些相似性匹配方案,虽然考虑了相同或相似词对的存在可能性,但它们可能对于检索结果参考意义不大,即使在文档中重复出现多次,也不能反映出真实的查询意图。本文分别基于BM25 和WMD相似度匹配方法进行片断之间相关性计算。如果采用BM25,其已经考虑了查询项在候选文档中的权重,因此它们片段之间的相关评分参照式(1)计算。
如果采用WMD 相似度计算方法,补充考虑了片段中相似词对权重的影响。基于WMD 的两条句子的相关性评分计算式如下:

其中,S为提取的相似词集,|S|为词集中元素的个数,idfri代表词语元素ri在语料库中IDF 值,idfmax代表语料库所有词语中最大的IDF 值。
在获取相关文本片段的过程中,相关性评分阈值m将用于判断目标片段是否是相关片段,并影响相关片段比率(标记为rs_ratio)的结果。rs_ratio定义如式(6)。

其中,Q表示查询,S表示最终在候选文档D中包含的相关片段序列,Swhole是从文档D中能提取到的所有片段,Saccept是经过筛选过滤操作后被接受的相关片段集合,s为某一片段。如果rela_score(Q,s)>m,该片段为相关片段,rs_ratio(Q,S)表示在D中与Q相关的片段数与所有片段数的比值。
相关性阈值m在短文本片段筛选分析中起到非常重要的控制作用,当m值过高,会过滤掉过多的有参考价值片段,导致相关片段比例变小,整体分数降低;当m值过低(趋近于0),会保留过多没有参考价值的片段,相关片段比例过大(趋近于1),这使得片段化失去了意义,无法提高大多数相关片段低频均匀分布的关联文档。在实验中,经敏感性分析取得了比较适当的值,即根据语料库中的词汇平均idf值进行调节,见4.3 节。
3.3 相关片段提取算法
给定一个元组序列,每个元组为与查询高度相似的相关文本片段的索引号和相关性分数,形如[(Indexs1,Scores1),(Indexs2,Scores2),…]。提取高质量的片段直接影响到最终的方案选择和整体评分。
相关的片段获取处理流程描述(related snippet acquisition processing,RSAP),如算法1 所示。
变量说明如下:Q为查询;processed_doc为预处理后候选文档集;q-snippets、d-snippets为查询文本片段、候选文本片段;片段总数分别为dlen、qlen;q-features、d-features分别为查询文本片段和候选文本片段的文本表达特征;match_fun为计算片段相关性评分中使用到的相似性计算方法(BM25或WMD);相关性片段的阈值设置为m;accept_num记录筛选过程中被保留下来的相关片段数;最后返回输出上述描述的记录元组序列T和相关片段比率r。
算法1 RSAP 算法

在RSAP 算法中,步骤1 查询文本和候选文本进行切割操作,得到相应片段集合;步骤2 根据匹配算法的需要提取相应的文本特征;步骤3 根据相似性匹配方法match_fun计算得到的结果相关性矩阵,其中矩阵元素为各个文本片段与查询片段之间的相关性评分;步骤5~步骤10 给出了相关片段的标注和筛选过程。
例如,一个相关矩阵如下,其中S0、S1、S2 为候选文档的句子片段,它们在候选文档中的位置索引编号分别为0、1、2;Qa、Qb、Qc是组成查询文本的疑问句子片段;S0-Qa表示S0 与Qa之间的相关性评分。

在上面矩阵的每一行中,选择候选文档语句和查询语句的最大相关性评分,得到元组序列:[(0,2.00),(1,8.80),(2,9.11)]。如果阈值m设置为5.80,则根据式(6),最终选择的相关片段元组序列T为[(1,8.80),(2,9.11)],相关片段比率r为2/3=0.667。
3.4 计算相关性整合分数
所选元组序列的整合分数表示候选文档的最终相关性评分,并由式(7)计算,如下:

在式(7)中,候选文档的最终相关性整合分数可以分为两部分:一个是针对记录的相关片段元组中的相关性得分的价值函数v(S),它反映了相关片段元组序列S的整体参考值;另一个是相关片段比率rs_ratio(Q,S),它反映查询与候选文本之间有多少相似成分。当文档中的一个片段得分较高时,它能在一定程度上反映与查询的相关性,将其作为关键文档片段,可以增加得分高的相关片段的权重,同时考虑相关片段比例的影响。
本文提出两种计算v(S)的方案:第一种计算方式,强调最重要的片段,并计算元组序列中相关片段的平均值,如式(8)所示;第二种计算方式,假设相关的代码片段是第一个非增量排序的,根据相关性分数排序给出每个片段的权重,如式(9)所示。
价值函数1:

价值函数2:
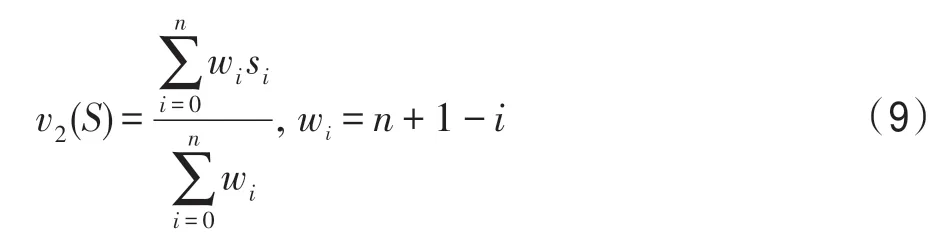
其中,max(S)为相关片段元组序列S中最大的相关性评分数值,n为序列长度,si是指在序列中(已按相关性分数值由大到小排序)的第i个元组的相关性分数值。
例如,假设相关片段元组序列为[(0,9.00)(4,7.00)(5,6.00)],相关片段比率为0.20,采取第一种价值函数计算方式时,整合得分为:
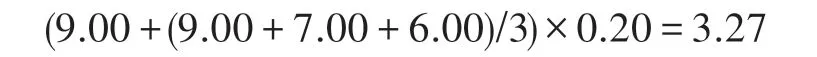
采取第二种价值函数计算方式时,整合得分为:
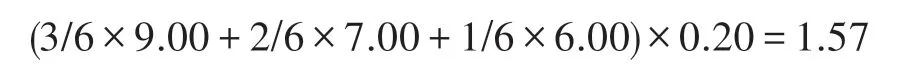
将价值函数引入到整合相关度评分中,更有效地利用了短文本片段的分数值。如果不采用价值函数判定短文本句子片段的重要性,单考虑相关片段比例,会导致许多文档排名并列的情况,而缺乏大量的参考信息。所设计的价值函数能增加得分高的相关片段的权重。
3.5 TSM 运算复杂度分析
设R为某一种片段之间相关性评分算法(如BM25),其复杂度记为O(R),p为查询文本的片段数,n为候选文本的片段数,片段化机制的运行时间主要开销花费在三部分:(1)片段之间相关度计算,复杂度为OPA=O(pnO(R));(2)片段提取运算,为提取每个目标文本片段的最大值,复杂度为OPB=O(n);(3)与价值函数有关片段整合运算,复杂度为OPC,因为片段提取过滤操作的存在,所剩片段数少于pn,所以OPC<O(pn),TSM 整体运行复杂度为O(TSM)=OPA+OPB+OPC<O(n)+O(pn)+O(pnO(R))=O(pnO(R))。
当相关性评分算法R为BM25 时,运算复杂度为O(wq),wq为查询语句中的查询词个数,此时TSM运算复杂度O(TSM)=O(pnwq);当R为WMD 时,运算复杂度为,wd为文档中非重复词的个数,因此采用WMD 的查询效率明显低于BM25。
由于查询语句一般较短,p大部分为1,则采用TSM 方法与原始方法相比,候选文本的片段数n的大小是运算效率差别所在。当语料库中文本可提取的片段越多时,TSM 单一查询所消耗的时间越长。
与其他片段化方式比较,例如,固定窗口滑动切分的形式[10],假设nk是以窗口长度为k分割后得到的片段数,Wd为构成文本的单词总数,则复杂度为O(nkWdO(R)),高于TSM 的复杂度。
4 实验结果分析对比
本文使用的数据集来自Glasgow 大学收录的信息检索标准文本测试集,数据集的详细情况展示如表1。这6 个数据集的原始文本保留了标点符号,能用于实验测试。

Table 1 Information of datasets表1 数据集信息
实验中使用的实验方法和代码分享于https://github.com/malajuanxiao/tx_snippet。
Glasgow 大学IR test collection 数据集公开网址http://ir.dcs.gla.ac.uk/resources/test_collections。
4.1 评估标准
实验使用准确率、召回率、F1[29]、mAP(mean average precision)[30]这几个信息检索常用指标作为实验模型的评估标准。准确率、召回率定义为:

其中,TP为与查询相关且被正确识别文档的数目,FP为与查询不相关且被错误识别文本的数目,FN为与查询相关却未能被识别文本的数目。
由于文本检索中每组实验获取的是Top-K的文档数,因此:

根据P和R,F值定义如下:

当参数a>1,准确率的参考值加重,a<1 则相反,一般情况下平等权衡取值为1,即F1=2PR/(P+R)。F1 综合考虑准确率、召回率的性能,F1 越高,反映检索模型性能越好。
mAP表示所有查询在不同召回率下的平均精度的积分,反映了搜索排名的全局性能。定义如下:

其中,R*指召回率指标;P(R*)是指在不同R*下的准确率分布。
4.2 实验对比分析
本节使用两种基准匹配方案(baseline)BM25、WMD,与使用TSM 优化机制的实验结果进行了对比,这里使用到的BM25 算法为vnBM25[15]。所有实验中相关片段的选择阈值m为基于语料库中所有单词的平均IDF值。Med 数据集的平均IDF值为5.878,LISA 数据集的平均IDF值为7.381。
采用的实验方案归纳如下:
两个baseline(BM25 和WMD):基于python nlp的gensim[31-32]库实现。
TSM_BM25(v1(S)):片段匹配方案使用BM25,相关性整合分数使用v1(S)。
TSM_BM25(v2(S)):片段匹配方案使用BM25,相关性整合分数使用v2(S)。
TSM_WMD(v1(S)):片段匹配方案使用WMD 的相关性整合分数使用v1(S)。
TSM_WMD(v2(S)):片段匹配方案使用WMD 的相关性整合分数使用v2(S)。
每个实验从测试集查询的搜索结果中提取Top5、Top10、Top20(Q5、Q10、Q20)来计算平均查准率、查全率和F1 得分。6 个数据集的评估结果如表2~表7 所示。下面以Med 和LISA 的实验结果为例进行分析。
从表2、表3 中的结果来看,Med 的实验结果比LISA 好。LISA 数据集涉及与信息技术相关的知识,领域广泛,存在大量的噪声数据,容易混淆;而Med数据集只涉及医学领域,范围和内容更为具体,因此搜索结果的准确性会更好。TSM 能取得较好的结果,特别是Top5 和Top10 的查询结果,符合精细搜索结果的目的。
为了更直观地反映性能差距,选取了两种方法的实验结果进行了可视化对比,一个是BM25,另一个是TSM_BM25,片段整合计算使用v2(S)价值函数,这两种方法针对全文本库在不同召回率下的平均精度的曲线直观地反映出mAP值,如图4 和图5 所示。

Table 2 Evaluation of Med dataset表2 Med 数据集测试评估
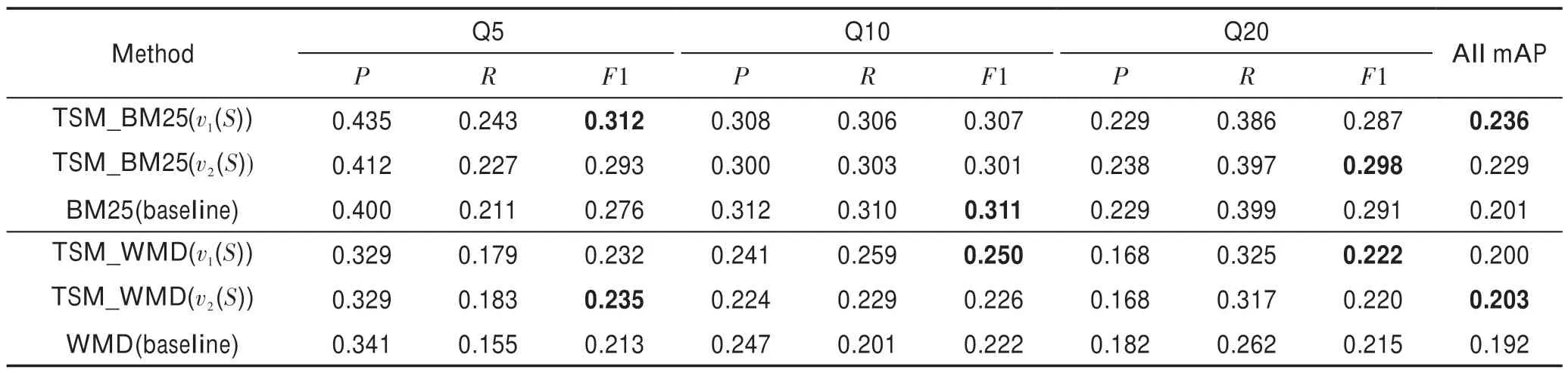
Table 3 Evaluation of LISA dataset表3 LISA 数据集测试评估

Table 4 Evaluation of ADI dataset表4 ADI数据集测试评估

Table 5 Evaluation of CACM dataset表5 CACM 数据集测试评估
另外,本文模型与多个其他文献公开的检索模型的实验结果进行了比较,包括图检索模型(graph comparison,GC)、TF-IDF空间矢量的余弦方法Cosine(TF-IDF)[33]、改进的LSI方法(latent semantic indexing),如kLSI、LSI-Q、LSI-U[34]。此外,根据文献[6,22]的描述,结合wordnet、LDA 模拟查询扩展[35]的方法进行了实验,标记为QE(WN)、QE(LDA)。表8 列出了针对Med 数据集每种方法的平均精度,实验结果表明TSM 具有最好的效果。

Fig.4 mAP distribution comparison in Med图4 Med 数据集mAP 曲线

Fig.5 mAP distribution comparison in LISA图5 LISA 数据集mAP 曲线
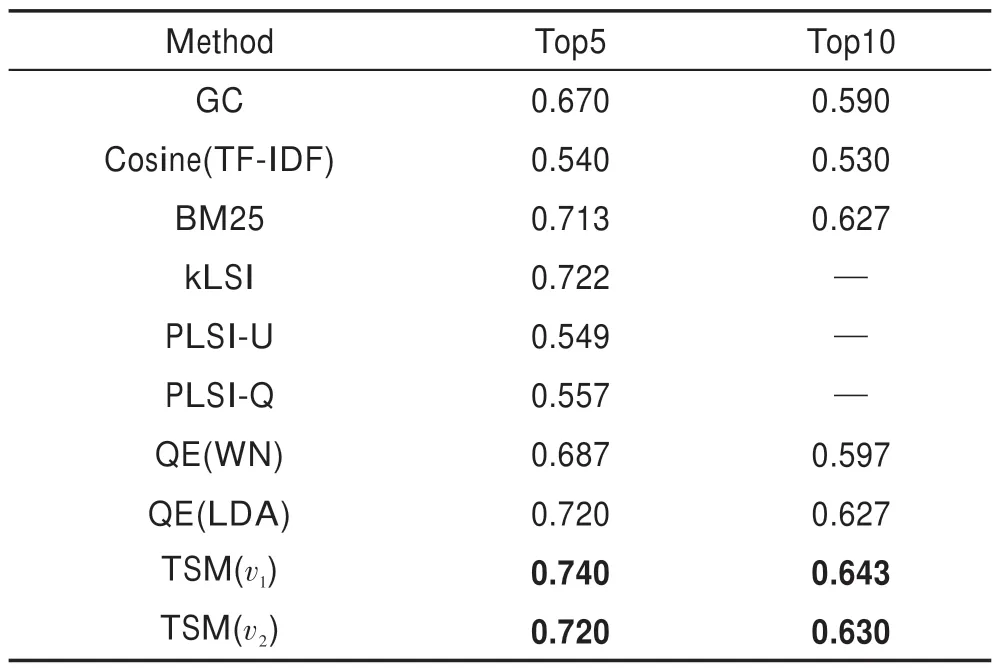
Table 8 Average precision of several methods表8 各实验方法的平均精度比较
4.3 参数敏感性分析
实验发现average idf与相关片段的阈值m密切相关。以Med 数据集和LISA 数据集为例,Med 数据集的average idf为5.878,LISA 数据集的average idf为7.381。从图6 和图7 可以看出,理想取值范围是average idf周边。
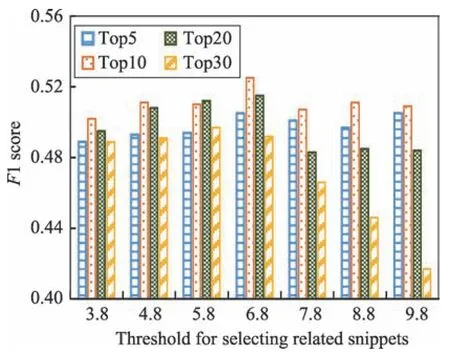
Fig.6 F1 with different thresholds for dataset Med图6 Med 不同阈值下F1 柱形分布图
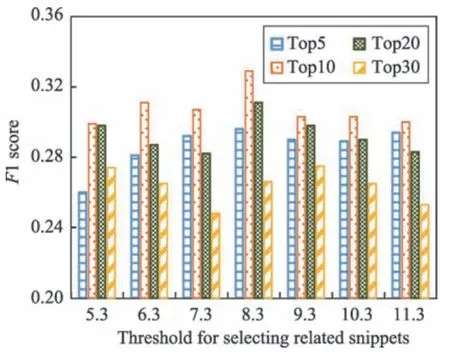
Fig.7 F1 with different thresholds for dataset LISA图7 LISA 不同阈值下F1 柱形分布图
5 总结和展望
本文针对长文本在检索中可能出现的问题提出了一种文本片段化机制TSM 来计算查询与被查询文本间的相关度,通过提取重要的短文本句子片段来度量查询与文档之间的相关性,目的是利用关键有效的文本片段信息提升文档整体评分的参考价值,在一定程度上消除文档长度对相似度匹配的影响。TSM 针对检索过程的优化,结合了不同的相似度匹配算法,可以有效嵌入到许多搜索算法中。实验结果验证了TSM 提升了检索模型的性能。
尽管TSM 在信息检索准确性方面取得了一定的成果,但仍有一些方面需要改进,如候选文本集的质量也会决定最终结果集的质量,且一些匹配过程,如与词向量有关的运算,时间效率较低。下一步拟研究改进的倒排索引方法,结合一些针对文本本身的语义挖掘和拓展技术,减小候选文本的数量和检索时间。
