启发式概念构造的组推荐方法*
2020-04-15刘忠慧
刘忠慧,邹 璐,杨 梅,闵 帆,2+
1.西南石油大学 计算机科学学院,成都 610500
2.西南石油大学 人工智能研究院,成都 610500
1 引言
形式概念分析[1](formal concept analysis,FCA)是一种针对形式背景的数据分析和规则提取方法,常用于机器学习、数据挖掘、知识发现等[2-5]领域。形式背景表示了对象、属性以及它们之间的二元关系,能描述电子商务中的用户消费记录或偏好,因此近几年FCA 被引入到推荐系统领域[6-8]。
当前,基于FCA 的推荐思路是先构建概念格,然后根据概念间的层次关系计算用户或项目的邻域。然而概念格构造效率低,几乎与形式背景的规模呈指数关系[9-10]。为降低构造的复杂度,研究者提出了构建概念格的优化算法,如基于统计的概念格构造[11]、基于剪枝的概念格构造[12]等。基于树结构的增量算法[13]在构造概念格时,通过快速定位父子节点的范围,缩短搜索时间,但在数据稀疏时改进效果不明显。形式背景分解法[14-16]利用并行计算,加速子概念格的构造,但在概念格合并时花费的时间较长,也未解决构造效率低的问题。
基于概念格的推荐[7-8]通常只考虑概念中用户的相互关系,而概念间的层次关系仅用来寻找邻居。因此只要保证概念集合能正确表示形式背景的信息,推荐效果就有望得到保障,故概念格的构造对于推荐应用不是必要的步骤。
本文提出一种不构建概念格的方案,使用启发式算法挖掘重要概念进行推荐,从根本上解决效率问题。
新方案包含两个阶段:第一阶段是概念构造,即生成一系列内涵与外延均较大的概念,同时满足它们对整个对象集合的覆盖;第二阶段是组推荐,即利用概念本身的群组特性进行推荐。
在抽样数据集和MovieLens 上,对比了本文算法与两类不同的推荐方法。结果表明,本文算法的概念生成效率高,推荐效果比基于概念格的推荐方法好,与KNN(K-nearest neighbor)算法[17]效果相当。
2 相关工作
本章主要介绍FCA 的相关概念和知识,以及两类常见推荐系统。
2.1 相关定义
定义1[1](形式背景)形式背景是一个三元组T=(O,A,R),其中O为对象集,A为属性集,R为O和A之间的二元关系,O×A→R。对于r(x,a)=1,表示对象x拥有属性a,也可以表示为xRa。
对象集X⊆O和属性集B⊆A,分别定义运算:
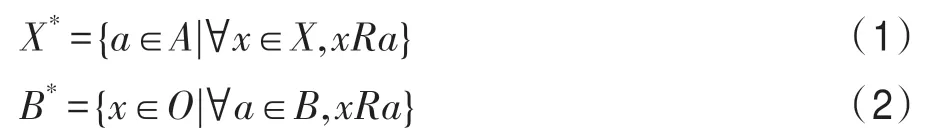
表1 是电影评分表转化后的形式背景,记录了10位用户观看7 部电影的情况。如果用户ui(0 ≤i≤9)看过电影mj(0 ≤j≤6),则r(mi,mj)=1;反之r(mi,mj)=0。

Table 1 Exemple of formal context表1 一个形式背景的例子
定义2[18](形式概念)在形式背景T=(O,A,R)中,令E⊆O,I⊆A,当二元组(E,I) 满足E*=I,I*=E时,则称C=(E,I)为形式概念,简称概念。E(C)表示概念的外延,I(C)表示概念的内涵,简写为E和I。
从表1 中可得一个概念C=({u1,u5},{m1,m4}),其外延为u1、u5,内涵为m1、m4。
定义3[18](偏序关系)设C1=(E1,I1),C2=(E2,I2)是T的两个概念。若C1≤C2⇔E1⊆E2⇔I2⊆I1,且不存在概念C3使得C1≤C3≤C2,则可称C2是C1的父概念,C1是C2的子概念,称“≤”为概念间的偏序关系。
定义4[18](概念格)形式背景中所有概念通过概念间的偏序关系构成的格L(O,A,R)称为概念格。
Hasse 图是概念格的图形表示方式,按照父概念在上,子概念在下的原则,用线段把父子概念连接起来。图1 为表1 的概念格,共33 个概念,其中接近50%的概念外延或内涵只有一个元素。
2.2 常见推荐系统
目前常见有两类推荐系统,分别是基于邻域的推荐系统和基于群组的推荐系统。
基于邻域的推荐系统由Zaier等人[19]在2007 年提出,其核心思想是通过相似度计算,找到相关邻域,利用邻域信息进行推荐。主要分为基于用户的推荐[20]和基于项目的推荐[21],前者是根据邻居用户的喜好进行推荐,后者是根据项目的相似度进行推荐。基于概念格的推荐属于邻域推荐,它通过概念间的偏序关系来寻找目标用户的邻居。
组推荐系统(group recommender system)由Garcia等人[22]在2012 年提出,推荐对象是整个群组。组推荐系统统计所有群组成员的偏好,通过共享和交互缩小群组成员之间的偏好差异,融合得到群组偏好,最后利用群组偏好进行推荐[23]。
本文结合FCA 和组推荐思想,根据用户所在的群组,以及群组成员的偏好,实现用户的相互推荐。
3 问题描述与方案分析
概念由用户集和项目集组成,用户集中的成员具有相同的偏好(概念内涵),从协同过滤[24]的角度可知,他们之间可以进行相互推荐。
3.1 问题描述
利用概念进行推荐,需要解决两个子问题:一是概念集合的构建;二是基于概念集合的组推荐。
问题1 概念集合的构建
输入:形式背景T=(O,A,R)。
输出:概念集C 。
约束条件1:∪(E,I)∈CE=O。
约束条件2:∀(E,I)∈C,|I|≥α。
优化目标:min|C|。
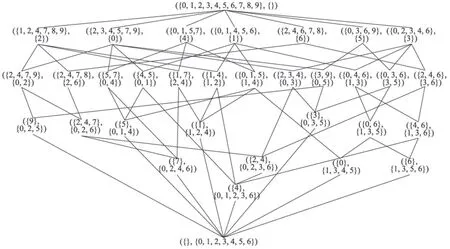
Fig.1 Hasse of table 1图1 表1 的Hasse图
其中,约束条件1 表示概念集覆盖了T的所有对象,保证任一对象至少属于一个概念,为后一阶段的推荐做准备。约束条件2 表示所挖掘概念的内涵规模不小于阈值α,从推荐系统的角度,仅当用户之间拥有足够多的共同项目,所形成的群组才有意义。优化目标为最小化概念集合,其目的是获得更简洁的表示,以提高模型的泛化性。
问题2 基于概念集合的组推荐
输入:形式背景T=(O,A,R),概念集C,推荐阈值β。
输出:推荐矩阵L。
约束条件:∀(E,I)∈C,∀u∈E,m∈A且r(u,m)=0,满足E中至少有β个对象向u推荐m。
优化目标:max(F1)。
将概念用户集视为一个群组,约束条件表示向目标用户推荐项目,需要满足组内至少达到推荐阈值的用户有m偏好。优化目标是最大化推荐F1 指标,实现高质量的推荐。
3.2 方案分析
KNN 算法是借助k个近邻对象进行推荐,本文算法则基于高质量概念。根据问题1 的优化目标,应尽量挖掘对象多的概念。而为使推荐效果更好,这些对象需具有更强的共同爱好,即概念的内涵更大。为此,定义了衡量概念质量的指标。
定义5(概念面积)形式概念C=(E,I)的面积为:

其中,|·|表示集合的基数。
由定义5 可知概念面积由外延和内涵的规模共同决定。外延规模大表示对象的邻居多,稳定性强;内涵规模大表示对象群组相似度高,推荐成功率高。基于此,给出强概念定义如下。
定义6(强概念)(E,I)为x∈E的强概念,当且仅当不存在x∈E′,Area(E,I)<Area(E′,I′)且|I|≥α,其中(E′,I′)为概念,α为内涵阈值。
例1 构建表1 中u5的强概念,α为2。通过计算,共3 个概念,C1=({u2,u3,u4,u5,u7,u9},{m0}),C2=({u4,u5},{m0,m1}),C3=({u5},{m0,m1,m4})。根据式(3)可知C2的面积为4,且满足强概念的条件,将保留用于第二阶段的推荐。
根据问题2 的优化目标,保证推荐质量,定义推荐置信度如下。
定义7(推荐置信度)给定形式背景T=(O,A,R),概念C=(E,I),对象x∈E,属性i∈A-I,r(x,i)=0 。则基于C向x推荐i的置信度为:

由式(4)可知置信度由对象群组每个对象的推荐综合决定。
4 算法设计
本章采用启发式方法构造概念来解决问题1,基于概念进行组成员推荐来解决问题2。启发式概念构造的组推荐算法(group recommendation based on heuristic concept set,GRHC)由3 个子算法构成:算法1构建一个对象代表的强概念,算法2构建基于形式背景的强概念集合,算法3 利用概念集合进行组推荐。
图4为各方案扰动能量随时间的演变。由图4d可知,平均来讲,扰动能量的增长据降水量调整方案最大,其次为传统BGM方案,另外两种调整方案效果相对较弱。据降水量调整方案各层分开来看,模式第8层扰动能量在预报18 h后稳定维持在较大数值(图4a),模式第16层(约500 hPa)增长饱和时间则提前到14 h左右(图4b),而在模式第25层(约200 hPa),扰动能量在预报18 h之后大幅度下降(图4c)。该方案24 h预报扰动能量在中低层增长到某一数值后稳定维持,说明集合预报对中低层影响较大,能较好地作用于控制预报误差,从而最有可能改善预报效果。
4.1 概念构造算法
采用启发式方法构建形式概念主要基于两个原因:其一,不是所有概念都对推荐有用。在极端情况下,某些概念的外延集合只有一个对象,或者内涵集合只有一个属性。这类概念包含的信息较少,不利于推荐。其二,不同的概念对推荐的贡献程度不同,群组的规模和对象间的相似度决定了推荐的准确度。因此,挖掘强概念是本文的关键,通过设计针对性的启发式方法可以达到此目的。
启发式方法构建形式概念,通过逐一添加对象代表的属性作为候选概念的内涵,同时更新候选概念的外延(见算法1 的第7 行),计算概念的面积并判断内涵大小是否满足阈值(见算法1 的第10~第16行),最终获得对象代表的强概念。
为了简化算法表示,做如下定义。
定义8(对象的属性集合)形式背景T=(O,A,R),任意对象u∈O,对象u的属性集合记为:

对象集合U⊆O的属性集合记为:

定义9(属性的对象集合)形式背景T=(O,A,R),任意属性i∈A,属性i的对象集合记为:

属性集合I⊆A的对象集合记为:

算法1 构建强概念



算法2 按照属性个数将对象有序排列(见第2行),依次选出对象代表,调用算法1 进行强概念构造(见第4 行)。从对象代表集合中删除新概念中的对象(见第6 行),再选代表继续下一个强概念的构造,直到所有对象都被包含在概念集合C 中。
4.2 组推荐算法
本文组推荐算法是基于算法2 得到的概念集合。一个概念中的用户具有共同的偏好和兴趣。组推荐方法通过统计用户群组在某个项目上的喜好程度,以决定是否推荐该项目给同一群组的其他用户,也就是计算基于概念向用户推荐某个项目的置信度(见算法3 的第3~6 行)。
算法3 基于概念集合的组推荐算法

4.3 复杂度分析
下面分析算法1 和算法2 的复杂度。假设形式背景由m个对象和n个属性组成,则任一个对象最多有n个非零属性。在构建其概念时,选择一个属性作为内涵,最多比较m-1 次。因此最坏情况下构建一个强概念的时间复杂度为O(mn),构建该形式背景下强概念集合时间复杂度为O(m2n)。
实际情况下,对象拥有的属性远远小于n,因此构建强概念集合所花的时间远小于O(m2n)。对比构建概念格的时间复杂度O(m2n)[9],GRHC 算法的优势较为明显。
4.4 运行实例
根据表1 的形式背景,下面描述GRHC 算法的运行实例。其中,设置内涵阈值为2,推荐阈值为0.5。
构造以u4为代表的强概念。oca(u4)={m0,m1,m2,m3,m6},将拥有用户数最多的m0选中为备选概念的内涵,获得外延{u2,u3,u4,u5,u7,u9},备选概念面积为6;将u4余下项目依次与内涵结合,可得同时拥有m0、m2的用户数最多;添加m2到内涵中,并更新外延为{u2,u4,u7,u9},此时备选概念面积为8,大于前一个概念的面积;根据上述选择策略,在({u2,u4,u7,u9},{m0,m2})的基础上继续构造,直到同时满足内涵基数不低于2,概念面积最大。最终得到以u4为代表的强概念C=({u2,u4,u7},{m0,m2,m6})。
基于概念C为u4进行组推荐。u4的组成员为u2和u7,推荐候选项为m4、m5。根据表1 可知,u2推荐m4,u7无推荐。由式(4)可得基于C向u4推荐m4、m5的置信度分别为0.5 和0,因此满足推荐阈值m4被推荐给u4。
5 实验与结果
实验数据集为MovieLens,包含943 个用户和1 682 部电影,共10 万条评分数据。实验对比了概念格推荐方法、KNN 推荐方法。由于概念格无法在MoviesLens 上快速建立,因此实验先使用抽样数据集,对比GRHC 算法、概念格算法和KNN 算法,验证算法效率;然后GRHC 算法在MovieLens 中进行不同内涵阈值和推荐阈值的实验,讨论其对概念生成、概念集合规模的影响。
5.1 推荐效果指标
本文采用推荐系统常用的评价指标:精确度(precision)、召回率(recall)和F1-measure。令L(O)为算法对所有用户的推荐矩阵,T(O)为所有用户在测试集中的行为矩阵。则推荐结果的精确度为:
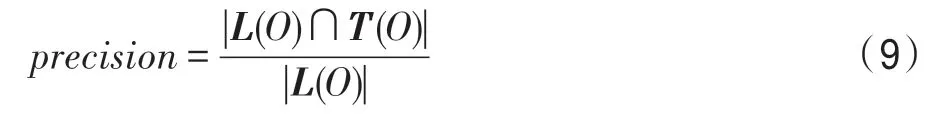
推荐结果的召回率为:

综合评价指标F1-measure为:
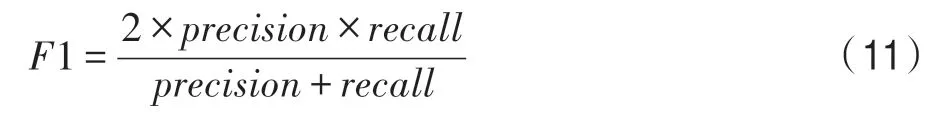
5.2 两类对比算法
将GRHC 算法和KNN 以及概念格推荐算法进行对比。与KNN 算法对比是为了验证GRHC 的正确性和推荐的有效性,而对比概念格推荐算法是由于两者都基于FCA。
KNN 推荐算法:利用相似度方法找到与目标用户最为相似的前k个邻居用户,再根据邻居用户的偏好信息来进行推荐预测。相似度计算一般采用杰卡德相似度,其计算公式如下:

其中,A、B为用户集合。
概念格推荐算法[7]:采用渐进式算法构建概念格,根据概念间的父子关系找到目标用户所在概念的兄弟概念与子概念,以此来得到候选项目列表。然后根据全局偏好度的计算结果,推荐与目标用户所拥有项目最为相似的前k个项目。用户u对候选项目i′的全局偏好度计算公式如下:

其中,I为用户u的项目集合,Ui为与项目i有关的用户集合,Ui′为与项目i′有关的用户集合。
5.3 抽样数据的实验和结果
从MovieLens 随机抽样4 组大小为230×420 作为实验数据集,其中每个数据集划分80%训练,20%测试。设置推荐阈值为0.5,内涵阈值为2。实验中,将对象代表按拥有的属性个数升序、降序以及原始序3 种情况分别验证GRHC 算法;概念格算法选取全局偏好度最大的前10 个项目予以推荐;KNN 算法选取与目标用户最为相似的前3 个邻居用户进行偏好信息推荐。
各算法的时间、精确度、召回率和F1 值如表2 所示,其中GRHC-D 表示对象代表为降序选择,GRHC-A 表示对象代表为升序选择,GRHC 表示对象代表按原序选择。表3 对比了在相同数据集下,GRHC 算法和概念格推荐算法生成的概念个数和运行的时间。
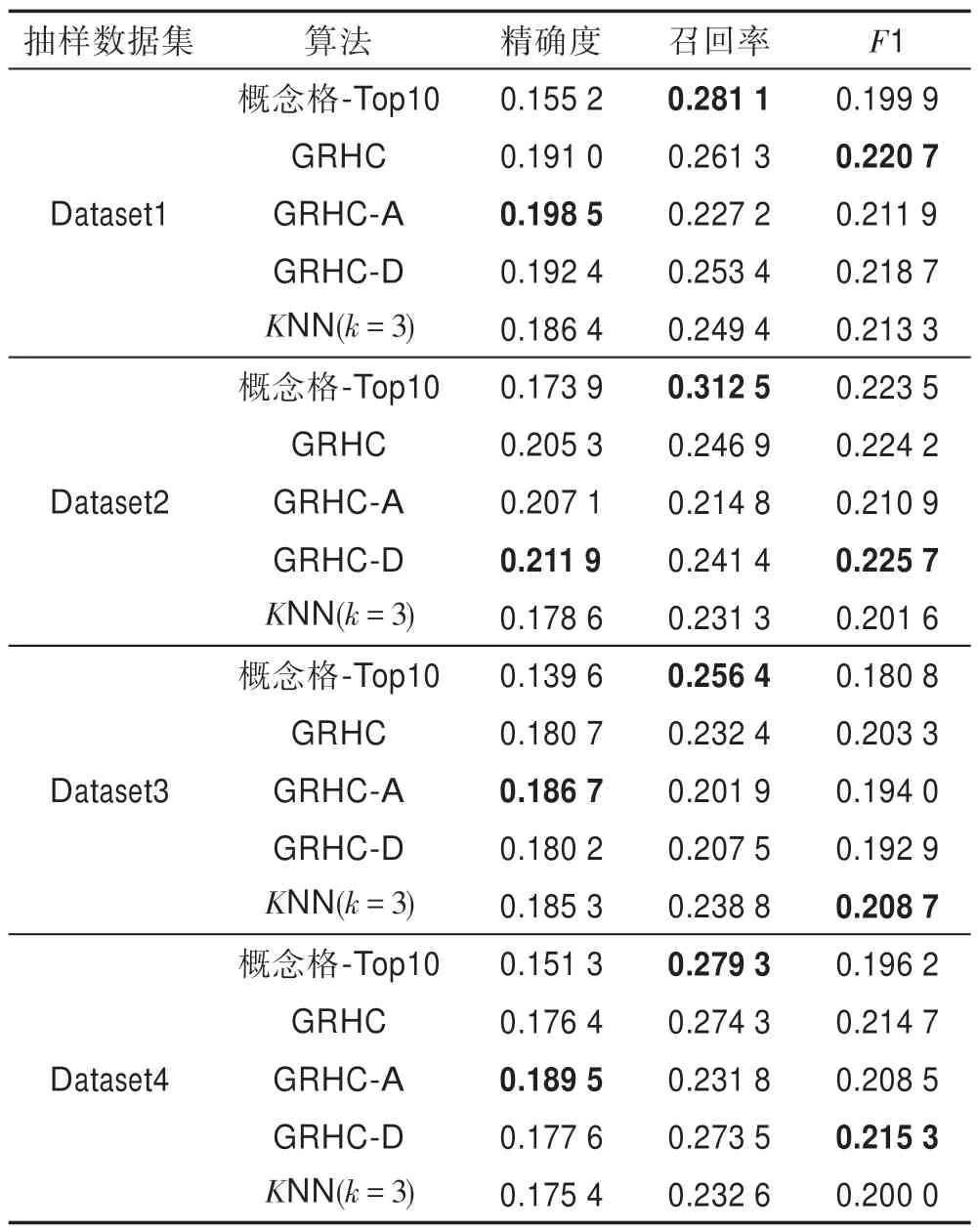
Table 2 Experimental results on sampled datasets表2 抽样数据集上的实验结果
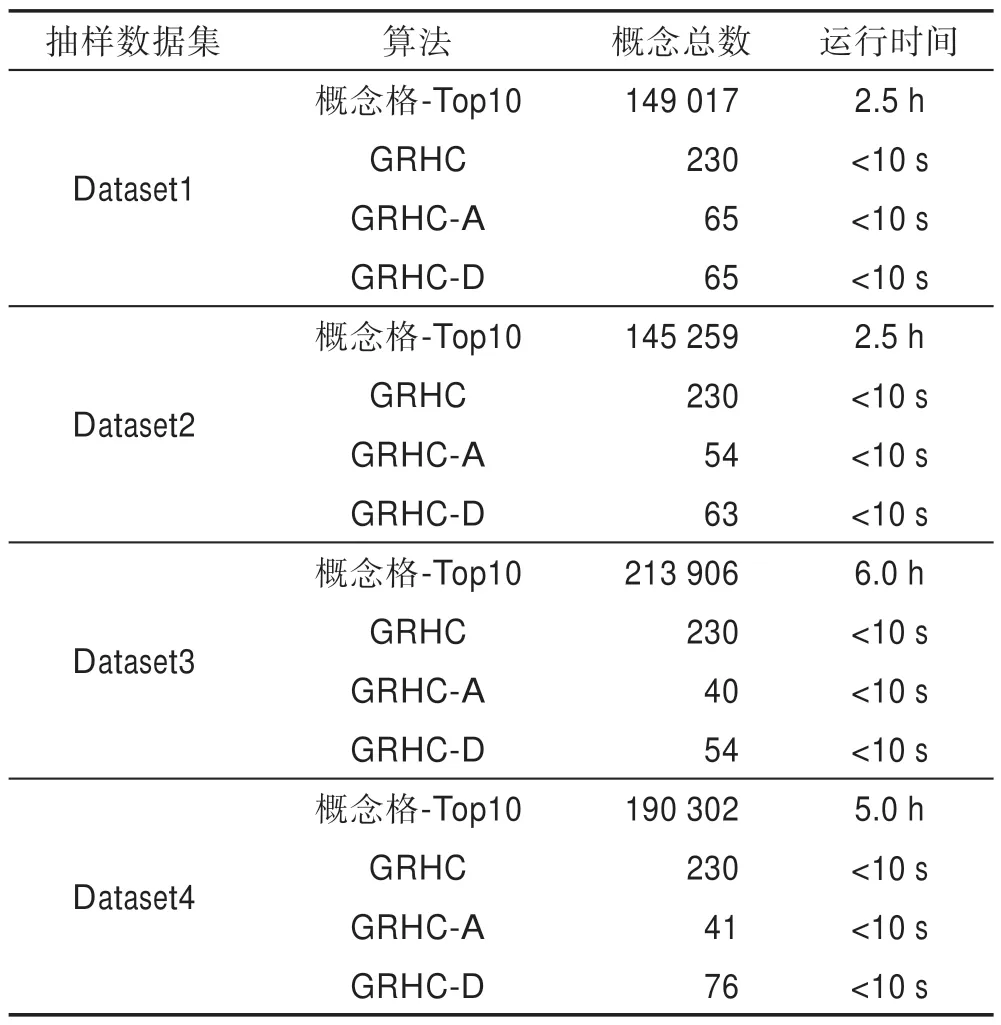
Table 3 Comparison of GRHC algorithm and concept lattice algorithm表3 GRHC 算法与概念格算法对比
实验结果表明,不管采用何种对象代表选择策略,GRHC 算法生成的概念个数和运行时间均远低于概念格算法;从图2 可以看出,在精确度、召回率和F1上,GRHC 算法明显优于概念格推荐算法,略高于KNN(k=3)算法。这体现了GRHC 生成的概念数虽较少,通过半数推荐约束,最终推荐效果能保持在较好的水平,从而证明强概念在具有泛化性的同时还有实效性。
5.4 MovieLens数据集的实验和结果
随机划分MovieLens 数据集80%训练,20%测试,推荐阈值为0.5,GRHC 算法内涵阈值范围为1~8,重复100 次,取这100 次结果的平均值作为最终结果,如表4 所示。
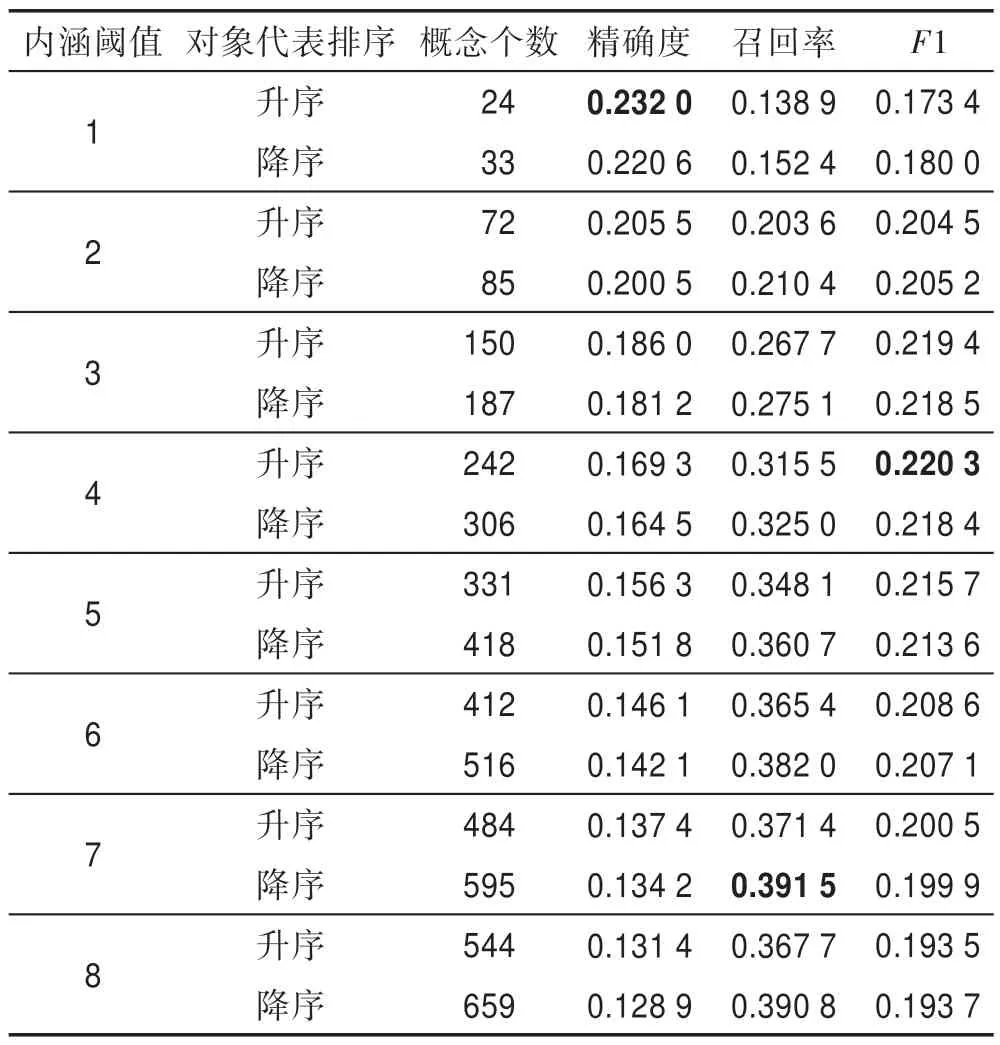
Table 4 Experimental results of GRHC algorithm on MovieLens表4 GRHC 算法在MovieLens上的实验结果
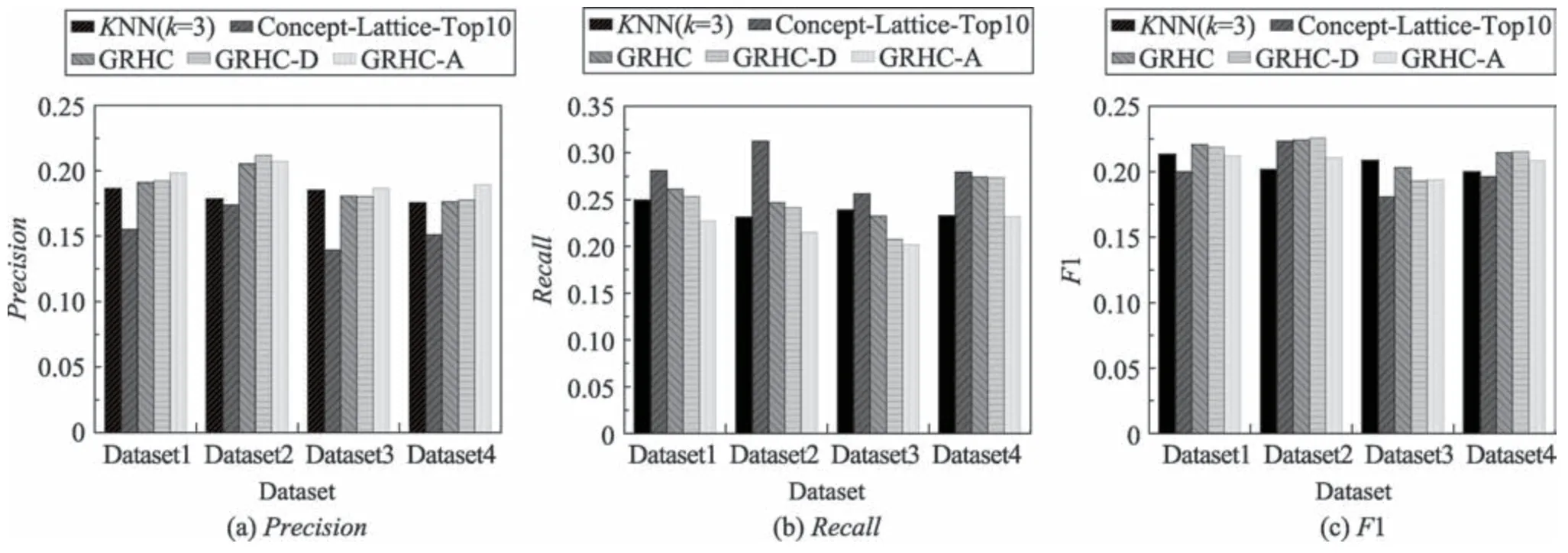
Fig.2 Experimental results of GRHC compared to other algorithms图2 GRHC 对比其他算法的实验结果
实验结果表明,GRHC 算法生成的概念个数与内涵阈值呈正相关,而对象代表的有序选择将减少生成的概念个数。当内涵阈值为4,概念数在200~300之间时,GRHC 算法的推荐效果较好,如图3 所示。当内涵阈值增大时,推荐效果随之降低,这说明了概念的泛化性,更有利于推荐模型的构成。在Movie-Lens 数据集上GRHC 算法的推荐效果略低于KNN 算法(k=3)的推荐效果(F1 ≈0.25)。
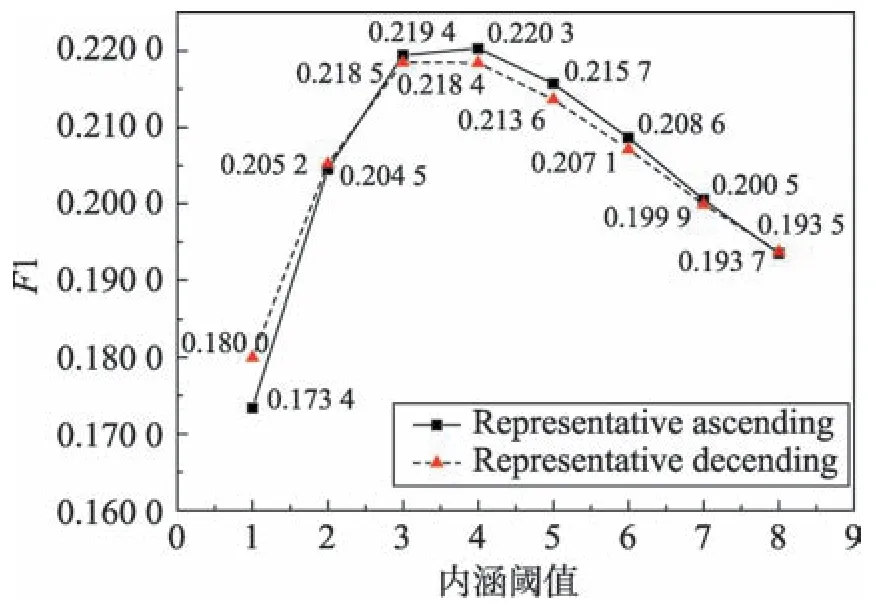
Fig.3 Impact of intention threshold on F1图3 内涵阈值对F1 的影响
6 总结和展望
本文提出了一种基于概念集合的组推荐算法。在概念构造时,采用了启发式方法快速获得满足内涵阈值的强概念,确保每个概念对推荐有用,同时利用概念中对象共同的特性进行相互推荐。解决了如何设计启发式构建信息,从何处开始概念的构建以及优化内涵阈值等问题。为形式概念分析方法提供了一种高效的推荐解决方案。目前的研究还缺乏对概念中项目组的信息挖掘,当前只考虑了对象群组的关联;另外在推荐应用时,仅考虑二值情况,未进行评分预测;最后数据集的粒度较单一,未引入电影和用户信息等特征值,这些都将成为今后继续研究和探讨的问题。
