群组推荐系统:现状与展望
2021-05-24赵海燕成若瑶陈庆奎
赵海燕,成若瑶,陈庆奎,曹 健
1(上海理工大学 光电信息与计算机工程学院,上海市现代光学系统重点实验室,光学仪器与系统教育部工程研究中心,上海 200093)2(上海交通大学 计算机科学与技术系,上海 200030)
E-mail:13223683653@163.com
1 引 言
在大数据时代中,能够精准地找到有价值的信息是件困难的事情,而推荐系统(Recommender System,RS)正是人们解决信息过载的有力工具,它根据用户的信息需求、兴趣爱好等,帮助用户进行信息过滤,将用户感兴趣的信息、产品等推荐给用户[1].
随着推荐技术的快速发展,个性化推荐系统正在不断完善,并成功应用于各个领域,与我们的生活已经息息相关,比如电子商务、影音视频、新闻资讯等等领域都存在着推荐系统的身影.个性化推荐系统是给个体用户进行推荐.但是,在现实生活中人们可以根据不同的标准划分成群组,例如,根据不同的兴趣划分出不同的学生团体,与此同时,人们也常常聚集在一起进行各种活动,比如家人一起看电视、朋友聚会等.在这些应用中,我们需要为群组进行推荐.
由于对群组进行推荐的需求日益增长,群组推荐系统(Group Recommender System,GRS)应运而生,它帮助群组快速筛选大量的信息,通过聚合群组成员的不同偏好,向群组推荐满意的项目.群组推荐系统节约了群组决策的时间,减少了群组成员之间不必要的矛盾与冲突.
群组推荐系统与个性化推荐系统相比较,两者之间存在共同点,例如均使用个性化推荐算法进行推荐,也存在很多区别.最基本的不同是推荐对象的不同,个性化推荐系统为个体用户推荐,而群组推荐系统为群组推荐.在推荐步骤上也有不同,群组推荐系统加入融合群组成员偏好的步骤.个性化推荐系统只考虑用户与项目之间的交互,而群组推荐系统不仅仅考虑用户与项目之间的交互,还涉及用户与用户之间交互的建模.
群组推荐强调群组成员偏好的聚合.由于群组中每个成员之间的差异性较大,偏好各有不同,同时也有着不同的期望和愿望,因而,在偏好聚合的过程中,群组成员之间经常会发生冲突.在群组决策过程中,为了达成一致,每个成员都会不同程度地接受或拒绝其他成员的偏好需求[2].最后的推荐方案需要能够尽量减少群组成员之间的冲突,提高成员共同的接受度.此外,群组是动态的、复杂的,群组成员会由于各种因素产生变动,用户的偏好也会受到其他群组成员的影响,需要动态捕捉群组实时变化.这使得为群组进行推荐更加困难.
近年来,围绕群组推荐的研究取得了不少研究成果.本文分析了群组推荐过程的特点和步骤,总结了目前群组推荐的模型和面临的挑战,并对未来的发展方向进行了展望.
2 群组推荐过程
目前,大部分群组推荐系统的研究工作可以分为群组识别、信息获取、融合策略、推荐算法和评价指标5个步骤.为了对群组进行推荐,首先需要识别出对应的群组,然后获取群组成员的个人信息,再根据目标群组的特征,使用融合策略和推荐方法,生成对群组的推荐结果,最后,利用评价指标检验推荐系统的性能.总体而言,群组推荐的实现分为两种技术路线[3],如图1所示.

图1 群组推荐的总体方法Fig.1 Overall process of group recommendation
一种是模型融合方法[3],即先融合偏好再推荐.通过融合策略将群组成员的偏好信息融合,生成群组的偏好模型,再采用推荐方法对群组进行推荐.模型融合容易受到评分稀疏性问题的影响.另一种则是推荐融合方法,即先推荐再融合.根据评分预测和Top-k推荐两类问题,将推荐融合又分为列表融合和评分融合[3],都是先对群组中每个成员进行推荐,再利用融合策略将所有成员的推荐列表或者预测项目评分进行融合,生成群组的推荐结果.推荐融合有更高的灵活性,并且有利于推荐结果的解释,但是缺乏新颖性,并且对大规模群组推荐效率低下.此外,融合方法的选择直接影响了群组推荐的效果,有时模型融合方法的准确度优于推荐融合,而有时推荐融合方法的准确度优于模型融合方法.因此,需要针对不同的问题,合理选择融合方法,使推荐效果更佳.
2.1 群组识别
群组识别是群组推荐的第一个步骤,同时也是关键的一步.推荐的群组主要分为两种,即实际群组和虚拟群组.对于实际群组进行推荐需要先判断群组类别,匹配最适合的推荐方式.然而,当用户需要加入群组并以群组的形式获得推荐[3],或者当个体信息匮乏、为个体推荐工作量较大的情况下,也需要构建虚拟群组进行推荐.
群组之间存在显著差别,如文献[4]发现随着群组规模增大,随机群组会出现众口难调的局面,导致推荐质量下降.相反,群组成员相似度高的群组随着群组规模的增大推荐效果会变好.文献[5]进一步证明了推荐系统性能与群组的凝聚性(群组偏好接近程度)有关.因此,对所有的群组均使用统一的推荐方法,必定会使推荐的效果大打折扣,所以判断群组的类别很有必要,我们总结了群组的不同类别,如表1所示.

表1 群组分类表Table 1 Group classification
目前,群组发现一般通过人口统计学特征和社会关系构建虚拟群组[3],而对于相似的虚拟群组,经常使用相似度计算方法和聚类算法来构建.用于群组发现的聚类算法有基于划分的方法[6],基于层次的方法[7],基于密度的方法[8]和基于图论的方法[9]等.文献[6]使用K-means聚类方法,根据用户的个人评分,将相同项目评分相似的用户分为同质群组,评分不同的用户分为异质群组,实验结果证明对同质群组的推荐效果比异质群组好.文献[7]则采用自顶向下的子空间聚类,将目标用户群分为五类,同时规定了生成群组的数量.文献[8]针对基于密度聚类算法效率低下的问题进行了改进,通过改进的算法聚集相似用户,构建相似群组,实验结果证明组内相似度越高,推荐效果越好.文献[9]则利用马尔可夫聚类算法完成广播电视用户群组的发现工作,分别对收视时间和收视节目聚类,并将时间和节目属性均相似的记录归为一类,并对同一类记录有偏好的用户归为同一群组.
2.2 信息获取
信息获取是任何推荐中不可或缺的一部分,通过获取用户的属性、搜索记录、浏览记录和评分等,我们可以进一步构建起群组的信息模型和偏好模型.信息获取的方式可以分为:
1)显式获取:用户主动提供信息,诸如用户的年龄、性别等人口统计学特征信息和用户对项目的评分、评价等偏好信息,这些信息能够明确显示用户的个人情况和对物品的偏好程度.但是,用户主动提供的信息数量可能较少.
2)隐式获取:隐式获取与显式获取相对,它不需要用户主动提供信息,而是通过用户的历史行为数据挖掘用户偏好.只要用户的行为数据足够多,就能够准确地抽取用户的偏好特征,并且有利于保护用户隐私[3].
2.3 融合策略
融合策略又称为偏好融合策略,属于群组推荐中独具特色的部分,不同于个性化推荐,群组推荐需要协调群组中每个成员的意愿.融合策略分为普通融合策略和加权融合策略,如表2所示.
2.3.1 普通融合策略
普通融合策略是按照某一预定义的策略将用户偏好或推荐结果聚合起来,其中平均策略(Averaging strategy)、最小痛苦策略(Least misery strategy)和最受尊敬者策略(One user choice strategy)的使用最为广泛.然而,没有最佳的、普遍适用的普通融合策略,群组推荐系统需要结合融合方法和推荐方法来选择融合策略,并且上下文和应用领域也影响融合方法和策略的选择[10].因此,文献[11]将普通融合策略进行组合使用,利用该方法推荐的准确度会提高,但是相应地增长了运行时间.所以在不同的情形下,针对不同类型的群组,应该选择合适的普通融合策略.

表2 融合策略表Table 2 Fusion strategy
2.3.2 加权融合策略
在同一群组中,不同成员的影响力是有差别的,加权融合策略为群组成员定义不同的权重,它又可以分为静态加权融合策略和动态加权融合策略.
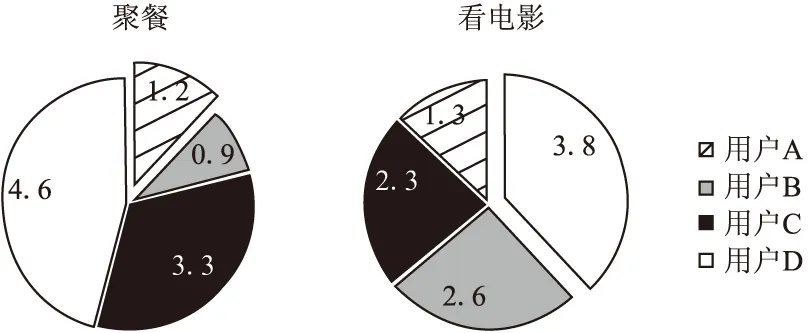
图2 用户在同一群组不同场景的权重图Fig.2 Weights of users in different scenarios from the same group
静态加权融合策略在群组推荐中广泛使用,它根据用户的人口统计学特征或者用户对历史项目的评分,计算用户的权重.但是,静态加权融合策略忽略了群组成员之间的交互和群组的动态性.此外,用户的喜好也受其他因素影响而发生改变,同一个群组为不同的项目做决策时,用户的权重可能发生改变,如图2所示,用户在不同群组中的权重也不一样,如图3所示.
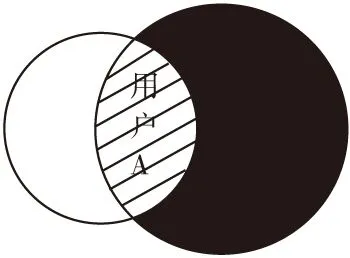
图3 用户在不同群组的权重图Fig.3 Weights of users in different groups
因此,动态加权融合策略考虑到群组成员之间的交互和用户权重需要更新的要求,动态学习群组成员的权重变化,使群组推荐效果更好,但是也付出计算开销方面的代价.目前,动态加权融合策略有纳什均衡策略、遗传算法、注意力机制和贝叶斯排序等.
1)纳什均衡(Nash Equilibrium)策略:将博弈论的思想运用到偏好融合中,把群组决策看作群组成员之间的非合作博弈:每个成员不需要衡量其他成员的偏好而调整自己的偏好,将提高群组满意度的问题看作是求纳什均衡解的问题.研究实验效果表明[6,12,13],纳什均衡策略推荐的准确度、命中率、鲁棒性和公平性都优于普通融合策略,并且推荐结果的多样性好.同时,纳什均衡策略的结果也具有较好的稳定性,即组内用户偏好相似度降低时推荐效果不变.相比而言,普通融合策略在运行时间上更有优势,尤其是对大规模群组,纳什均衡策略的运行时间会更长.文献[12]将纳什均衡策略搭配不同的融合方法使用,发现不论是使用模型融合方法还是推荐融合方法,纳什均衡策略的推荐结果都比普通融合策略好.文献[13]通过群组的纳什均衡解了解群组成员的个人偏好,利用奇异值分解整合成员的个人偏好为群组偏好.并且针对运行时间较长的问题,提出了两种剪枝方法(NashSkyline,Nash Skyband),通过去除群组成员意见不一致的决策,缩短了运行时间、提高了推荐效率,但是也付出了多样性和公平性方面的代价.
2)遗传算法(Genetic Algorithm,GA):通过模拟“物竞天择,适者生存”的自然进化过程,求解优化问题.具体来说,遗传算法将问题编码为由染色体构成种群,一代代选择、交叉、变异,进化出新的种群,最终得到最适应的种群,即问题的最优解[14].遗传算法也被用于学习群组成员之间的交互作用.群组推荐领域涉及遗传算法的研究较少[14],文献[14]根据群组的已知评分和成员的个人评分,通过遗传算法学习群组成员之间的交互作用,预测群组对项目的评分.该方法将基因视为群组成员的权重,初始化群组,通过最小化适应度函数评估遗传后代的优劣程度.并对适应度函数值进行迭代求解,得到最优解.采用轮盘赌方案选择,单点交叉和0.01比特的突变率作为遗传算子.由于遗传算法不受已知群组评分数量的影响,可以解决群组评分稀疏的问题.
3)注意力机制(Attention Mechanism,AM):是深度神经网络研究中的最新进展,主要思想是人们观察物体时,倾向于关注物体的重要部分,忽略其他部分.在群组推荐中,将每个用户表示为一个嵌入向量,应用注意力机制学习用户在群组中的权重.注意力机制也可以使推荐结果具有可解释性.目前,群组推荐存在不少涉及注意力机制方面的研究[15-18],文献[15]提出了基于Mavens进行特征挖掘和BERT嵌入构成的群组模型,再运用注意力机制聚合生成群向量.通过注意力机制,每个成员都参与了群组决策,还能清晰地反映群组成员的影响.文献[16]则利用由群组和用户组成的双层注意网络,共同学习群组成员的重要性.当群组与不同项目互动时,群组成员的注意力权重会动态地调整.文献[17]利用注意力机制,动态调整用户在不同群组中的影响力,较好地解释了群组决策的过程.文献[18]采用自注意力机制获取群组成员之间的相似关系,从群组成员和项目之间的交互中,自动学习每个群组成员的动态权重,同时聚合群组成员的偏好生成群组偏好.
4)排序学习算法:群组推荐问题可以描述为排序学习问题,它是利用机器学习技术解决排序问题的方法.从训练的数据中自动为每个群组构建单独的排序模型,并利用排序模型预测项目评分,但是此过程中训练效率低下.为了解决这一问题,文献[19]提出了一种基于学习排序算法的群体活动推荐框架,将上下文影响和成员偏好融入到群组中.提出贝叶斯群组排序算法,用于学习每个群组聚合模型的权重.该方法的结果优于普通融合策略,可扩展性强,提高了推荐准确度.
2.4 群组推荐方法
推荐方法是群组推荐系统的核心,通常将传统个性化推荐方法应用到群组推荐系统中,推荐算法既可以在模型融合方法中使用,也可以应用于推荐融合方法,但是搭配不同的融合方法使用,推荐效果会有差异.并且,不存在“总体最优”的推荐算法和融合方法,两者应该一起选择以优化群组推荐的质量[4].目前,经常使用的推荐方法有基于协同过滤的推荐、基于内容的推荐和组合推荐[1],下面详细介绍这3种推荐方法.
2.4.1 基于协同过滤的推荐方法
协同过滤(Collaboration Filter,CF)推荐是推荐方法中的主流,它的主要思想是“物以类聚、人以群分”.协同过滤具有良好的可扩展性,但在存在数据稀疏问题和冷启动问题时效果下降[1].协同过滤推荐又分为两大类,即基于内存的协同过滤和基于模型的协同过滤.
2.4.1.1 基于内存的协同过滤
基于内存的协同过滤根据相似用户或者项目的评分去预测未来的评分,又分为基于用户的协同过滤(User-Based Collaboration Filter,UBCF)和基于项目的协同过滤(Item-Based Collaboration Filter,IBCF).由于传统协同过滤计算相似度时,会受到用户评分数据稀疏的影响,文献[20]改进了基于用户和项目的协同过滤中相似度的计算方法,利用用户对项目共同评分的数目与用户对项目评分总数目的关系(相似性影响因子)和用户评分的关联性(关联性因子)来调整用户之间的相似性,有效缓解了数据稀疏性造成的相似度计算不准确的问题,从而提高单个用户预测评分的准确性.最后,使用推荐融合方法,将群组成员的推荐结果结合,生成群组推荐列表.
2.4.1.2 基于模型的协同过滤
基于模型的协同过滤推荐效果要优于基于内存的协同过滤,表3总结了群组推荐中常用的基于模型的协同过滤方法.
基于主题模型(Topical Model,TM)的推荐方法在群组推荐中采用的是基于主题的概率模型,它通过群组主题,判断用户影响力,做出群组决策.文献[21]提出个人影响主题概率模型(Personal Impact Topic,PIT),将用户对项目的偏好抽象成许多潜在的主题.该模型学习群组成员的个人影响,区分群组成员对群组决策的不同影响,选择最具影响力的用户(最符合群组主题),将其决策代表群组决策.但是,该模型只有当最有影响力的用户是相关领域的专家时,才有助于群组推荐.并且,PIT模型忽略了在不同主题中用户影响力的不同.文献[22]则考虑了群组中用户对群组主题的依赖性和用户从个人到群组成员的行为变化,提出一种基于隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)的共识模型(Consensus Model ,COM),模拟群组活动的的过程,加入用户选择行为和内容因素,实行群组推荐,但是该模型没有考虑到用户可能跨组做出决策.
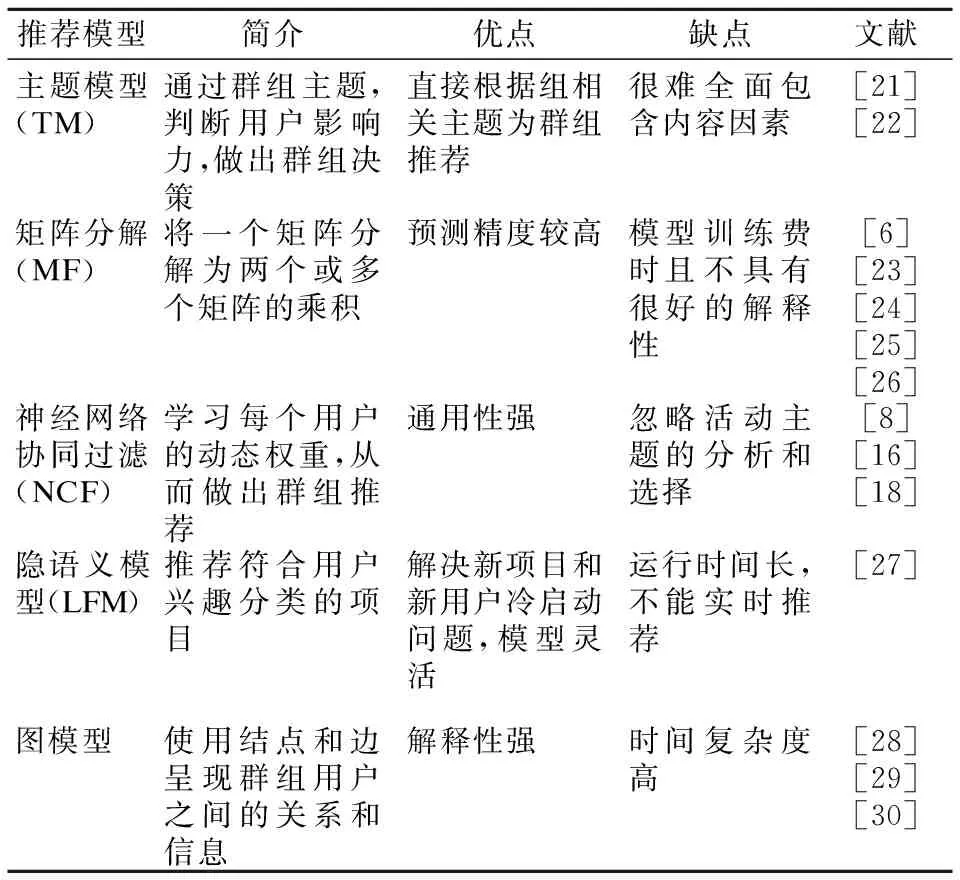
表3 推荐模型Table 3 Recommendation model
矩阵分解(Matrix Factorization,MF)是典型的基于模型的协同过滤方法,利用降维的方法处理高维的数据.相比传统的协同过滤方法,矩阵分解能够缓解数据稀疏问题.随着用户项评分矩阵维数的不断增加,群组推荐面临着用户评分数据稀疏的问题,因此,文献[23]则提出一种按项目加权的矩阵分解模型,并与时间效应函数相结合.该算法容易获得群组偏好,能够很好地适应不同群体规模,并且对中小型群组有更好的推荐效果.文献[24]提出一种基于Hellinger距离的社会信任关系提取方法,通过描述二分网络中一侧节点的f散度来进行用户相似度计算.将提取的隐式社会关系加入改进的概率矩阵分解(Probabilistic Matrix Factorization,PMF)中,提出一种新的基于用户组群和隐性社会关系的概率矩阵分解算法,提高了推荐的精确度,并且在无法提取明确用户信任关系数据时,相对推荐效果更好.文献[25]则采用联合概率矩阵分解方法(Unified Probabilistic Matrix Factorization,UPMF),首先,利用用户加入群组的信息,构建群组-用户二部图来计算用户之间的相关性,再将用户相关性矩阵融入到概率矩阵分解过程中,得到个人预测评分,最后对个人预测评分进行融合,得到群组对项目的预测评分.该模型提高了群组推荐的精度,较奇异值分解SVD和PMF有更好的准确度、召回率和稳定性.
基于神经网络的协同过滤(Neural Network-Based Collaborative Filtering,NCF)是深度学习在推荐系统中的应用,将用户和项目嵌入到神经网络中,从数据中学习用户、群组和项目之间的交互.首先,给定用户项目对和组项目对,通过表示层返回每个给定实体的嵌入向量.然后将嵌入的数据输入到池化层和隐藏层中,得到预测的评分.由于神经网络具有很强的数据拟合能力,所以NCF方法比MF更具通用性.文献[16]在NCF框架中嵌入群组项目和用户项目的复杂交互,并将群组嵌入与用户嵌入共享同一个隐藏层进行预测.此外,利用用户项交互数据来增强组项交互功能的训练,反之亦然,使得群组推荐和用户推荐的性能相互提高.文献[18]提出了一种结合神经网络和协同度量学习的推荐模型(Self-Attention and Collaborative Metric Learning,SACML),利用自我注意机制学习群组成员与项目之间的交互作用,自动了解群组成员的重要性.此外,通过协同度量学习获得群组与项目之间的相似度量空间实现群组推荐.SACML模型学习了群组成员之间的相似关系,能够更好地收集整个群组的兴趣,将权重可视化,使推荐结果更具解释性.
隐语义模型(Latent Factor Model,LFM)即潜在因素模型,它通过隐含特征联系用户兴趣和项目,例如基于用户的行为对项目自动聚类,划分为不同的类别,即用户的兴趣.文献[27]研究了群组信息对事件推荐的影响.基于群组的双重视图(用户和事件),提出了一种潜在因素模型,并且模型灵活,可以将上下文信息,如事件地点、流行程度、时间影响和地理距离合并到模型中.
基于图的推荐方法也很常见,使用图模型的结点和边表示用户的信息和用户之间的关系,使得推荐结果更具有解释性.基于图模型的推荐通常用于大规模群组的推荐.文献[28]提出一种层次可视化群组推荐方法 (Hierarchy Visualization Group Recommender,HVGR),通过多层次的节点和边组织和呈现信息,为推荐提供解释.同时通过每个节点的饼图将成员映射到切片中,了解个人影响力和社会关系.随机游走(Random Walk)方法是基于图模型中广泛应用的方法.文献[29]利用社会标签,建立图模型来反映用户之间、项目之间以及用户项目之间的各种关系,并提出一种将随机游走与重启相结合的随机排序技术,可以有效地以概率的方式同时计算项目的群组排名评分.该方法适合为大规模群组推荐,当群组规模较小用户偏好不足时,推荐效果会很差.文献[30]提出一种描述学术网络中大规模群组决策问题的图模型,以专家为中心将大规模群组划分为多个子网络,根据用户的相关性,采用基于重启的随机游走决策加权(RWR)技术计算用户的加权决策,为研究人员提供更可靠的推荐.
2.4.2 基于内容的推荐方法
基于内容的推荐(Contentbased,CB) 是根据用户偏好的项目,通过计算项目内容之间的相似性,推荐给用户可能感兴趣的项目.基于内容的推荐具有很强的可解释性,不存在数据稀疏性问题.但是,推荐的内容过于一致,并且也存在冷启动问题.文献[31]引入GroupReM群组推荐系统,通过电影内容和群组简介之间的相似性,以及电影的受欢迎程度,来提高群组推荐的准确性.
2.4.3 混合推荐模型方法
由于每一个单独的推荐方法都有自身的局限性,为了使推荐效果更佳,将推荐方法混合,形成了混合推荐方法.混合推荐可以扬长避短,比如将基于内容的推荐与协同过滤结合,可以缓解协同过滤数据稀疏性问题.文献[12]通过神经网络中的多层感知器(Multilayer Perceptron,MLP)获得用户与项目之间的非线性交互,再结合潜在因素模型LFM,构成LFM-MLP混合推荐模型,它既能捕捉用户与项目之间的线性关系,又能获取用户与项目之间的非线性关系.在相同的潜在因素数下,混合推荐模型LFM-MLP的推荐精度最高,并且随着潜在因素的增多推荐效果越好.文献[32]设计了一个考虑群组凝聚力的主题模型GGC.首先,将群组中积极参加活动的成员定义为积极者,其他成员为旁观者.旁观者较多的群组为弱内聚群组,否则为强内聚群组.其次,凝聚力强的群组倾向于选择反映群组主题和多数群组成员意愿的项目.同时,使用一个包含关于实体和关系信息的异构信息网络(Heterogeneous Information Network,HIN),提取额外的内容信息.并与GGC结合起来的构成混合群组推荐模型HGGC.实验表明该模型适用于大规模群组推荐,缓解了群组推荐的数据稀疏性问题.
2.5 评价指标
为了衡量群组推荐策略的性能,需要对其效果进行评价.下面介绍几种衡量群组推荐系统性能时常用的评价指标.
2.5.1 推荐质量
一般采用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)测量预测评级和真实评级之间的偏差,衡量推荐质量.MAE和RMSE指标数值越小,推荐项目和实际偏好项目之间的差异越小,即系统推荐质量越高.根据文献[10],对于CB和UBCF推荐方法,使用模型融合方法的推荐质量更好,而SVD和IBCF更适合使用推荐融合方法.
评估群组推荐系统的多样性使用汉明距离 (Hamming Distance,HD)[13],高HD意味着高多样性.并且,推荐融合方法的多样性比模型融合方法好,CF推荐方法产生了最多样化的推荐,CB的多样性最小,对于SVD、UBCF和CB,采用模型融合方法生成最多样化的推荐,而IBCF更适合使用推荐融合方法生成多样化的推荐[10].
2.5.2 覆盖率
覆盖率描述一个推荐系统对物品长尾的发掘能力.除了UBCF外的推荐方法,使用偏好融合方法的推荐覆盖率略高于推荐融合方法,CB方法的覆盖率最低,CF的覆盖率最高,并且随着组内相似度增加,覆盖率通常不变[10].
2.5.3 公平性
公平性衡量群组推荐列表对群组成员的公平程度.Hongke Zhao等人[13]首先通过满足增益计算用户满意度(Satisfaction Gain,SG).SG衡量一个群组G对推荐列表L的满意度,见公式(1):
(1)
其中,Uj表示群组G中的成员,Ik是推荐列表L中的项目.R(j,k)则是Uj对Ik的评分.
在高满意度情况下,采用谐波(Harmonic)衡量推荐列表L对群组G的公平性,见公式(2),如果谐波很高,则推荐对所有成员都公平.
(2)
文献[33]将群组推荐的公平性问题描述为一个多目标优化问题,并利用帕累托效率来同时提高群组推荐的准确度和公平性.文献[34]研究了package-to-group推荐中的公平性问题,引入了两个公平性定义:比例公平性和无嫉妒公平性.比例公平性指群组成员对于推荐列表中的项目比列表之外的项目更感兴趣;无嫉妒公平性是判断群组成员在推荐列表中感兴趣的项目是否比其他成员多.但是目前并没有一个统一的评价指标去判断群组推荐的公平性,文献[36]则提出一个能够评价一般群组推荐公平性的评价指标,评价推荐列表S对于群组g的公平性,见公式(3):
(3)
其中,Tu表示用户u参加的活动集合.更高Fairness指标表示更高的公平性.
3 数据集
目前,多数关于群组推荐系统的研究,采用的数据集分为以下3类:
1.爬取数据集
研究者从相关的网站上自行爬取与群组相关的数据集,并将数据进行处理,得到适用于实验的群组数据集.文献[35]从旅游社交网站TripAdvisor.com上,爬取餐饮领域真实的数据集,包括6269个评级,涉及到纽约60家餐馆和1945名顾客.
2.群组公开数据集
目前适用于群组推荐系统的公开数据集并不多,主要有两种:
1)CAMRa2011数据集(1)http://camrachallenge.com/2011.:上下文感知电影推荐竞赛中发布的可公开访问的数据集,包括用户、群组、电影和用户群组对电影的评分,其中群组以家庭为标准.文献[16]对数据集中的用户进行筛选,将没有加入群组的用户去除.最终的数据集包含602个用户、290个群组、7710个项目、116344个用户项交互和145068个组项交互,平均群组规模为2.08.
2)Meetup数据集(2)https://www.kaggle.com/sirpunch/meetups-data-from-meetupcom/data,2017.:是从社交网站Meetup.com上爬取的公开数据集,其中包含群组、活动、场地和群组用户之间的交互等.文献[18]使用的数据集包含5893887个用户、16330个群组、2510个项目、3195246个用户项交互和31214个组项交互,平均群组规模为685.
3.个体公开数据集
部分研究者使用个体公开数据集,生成虚拟群组,构成群组数据集.经常使用的个体推荐数据集很多,比如典型的Movielens数据集等.
4 群组推荐面临的挑战
群组推荐系统的发展虽然有一定的进展,但是在实际应用中依然面临一系列挑战:
1.冷启动问题
传统个性化推荐系统中普遍存在的冷启动问题,在群组推荐系统中也不可避免,而对于临时群组和随机群组冷启动问题更加严重.文献[27]从用户和事件双重角度考虑,建立群组信息的双重视图,对解决冷启动问题有一定的帮助.
2.自然噪声问题
用户的评分由于上下文等因素引入噪声,自然噪声不是出于恶意引入的噪声,它会使推荐结果产生偏差.群组推荐系统中的自然噪声问题目前还很少被关注.文献[37]提出了基于模糊工具的群组自然噪音管理方法.该方法使用模糊工具在噪声检测中将噪声进行分类,在噪声校正中对噪声等级进行调整修改,一定程度上消除了自然噪声产生的影响.但是,自然噪声问题仍然需要继续研究.
3.群组决策不一致问题
由于群组成员的偏好不同,容易出现群组决策不一致(Group decision making,GDM)的问题,这是群组推荐中的难题.研究人员对群组决策不一致的问题进行了一定的探索,通过定义群组共识度和和谐度指标来判断群组成员满意度,并建立群组信任机制,解决群组决策不一致问题.文献[38]在此基础上进行了改进,定义区间值信任函数,将群组成员的态度分为信任、不信任、犹豫不决和反复无常,并且建立视觉图形模拟共识情形,使专家们重新审视自身影响力,随时调整决策.然而,该方法中忽略了影响信任关系的其他因素,如历史互动和专家声誉.文献[39]提出不同的群组成员态度的划分方法,分为可信的专家和不一致的专家,根据可信专家的建议,群组成员可以重新审视自己的评价,并且调整不一致专家的态度参数,同时提出态度信任诱导反馈机制,该方法比传统的不考虑信任度分级的反馈机制更为合理,实现了共识与和谐之间的平衡.然而,该方法中没有考虑社会网络中的信任关系.群组决策不一致问题仍需继续探索与研究.
4.隐私问题
隐私保护一直是推荐系统研究的热点,群组推荐过程中也存在泄露用户个人信息的问题,因此,对于群组成员的隐私保护也很关键.文献[40]提出一种基于影响因素IF的MSNs隐私保护群组推荐(IFRG),运用模糊矩阵算法在保护群组用户的隐私方面进行了探索,并且即使不是每个人均在线的情况下,也能实现具有隐私保护的群组推荐.文献[41]提出一种基于可信客户端的个性化隐私保护框架和基于此框架的群组敏感偏好保护方法,它利用用户敏感主题的相似性发现组内相似用户,使用群组内相似用户的评分对目标用户评分进行协同扰动的方式来保护用户隐私,然而,该方法中忽略了在数据传输过程中可能存在隐私泄露的风险.群组推荐中如何进行隐私保护仍然是未来的研究方向.
5.多样性问题
群组成员的偏好聚合会导致用户信息的部分丢失,对推荐的多样性产生负面影响.为了优化群组推荐系统,文献[26]对比了3种融合方法,即偏好融合、推荐融合和不融合直接推荐,发现不进行聚合直接生成群组推荐最适合生成多样化的推荐列表,因此,提出了模糊集群组推荐模型(Hesitant Fuzzy Set Group Recommender Model,HFSGRM),根据最近邻域的相似性直接进行预测,使用模糊集合生成群组推荐,解决了由于聚集导致的关键信息丢失的问题,保证了群组推荐的多样性,随着群组规模增大多样性可以得到进一步增强.但是,该模型只适用于协同过滤推荐方法.如何兼顾多样性和群组一致性依旧是一个挑战性问题.
6.大规模群组推荐问题
针对大规模群组的推荐一直以来都很棘手,由于群组用户数量较多,导致大规模群组推荐的效率偏低,推荐准确性较差.由于推荐列表的规模随着群组成员的增多而增大,文献[42]提出一种缩小群组推荐列表的方法,它基于群组成员的共同偏好,将群组划分为多个子组缩小群组规模,减少了群组偏好属性的数量,从而达到缩小群组推荐列表的目的,当群组规模越大时,该方法的推荐效果越好,然而,该算法的复杂度较高,计算效率低下.如何针对大规模群组进行高效的推荐是一个需要研究的问题.
5 展 望
1.研究能够普遍适用的群组推荐方法
目前,由于没有普遍适用的群组推荐系统,需要依据不同群组的特点和上下文信息,动态选择推荐方案.虽然这样的群组推荐系统针对性降低,但是能够为不同的群组匹配最佳的推荐模式.对于一个新的问题,需要较长时间的去探索最合适的模型,也可以将多个模型同时运行,对其结果进行融合,但是这种方法将带来显著的开销.为此,需要针对不同的群组类型、不同的应用场景,建立起群组推荐算法的适用范围,以指导群组推荐的方法选择.
2.实现群组的实时推荐
由于群组的动态性,群组的偏好也会随时间、地点和情绪等发生改变,未来可以运用大数据技术掌握群组的实时信息和偏好的变化,将大数据与推荐算法结合[43],满足群组用户实时在线推荐的需求[16].
3.更优的群组偏好融合模型
目前群组偏好的融合考虑的因素还比较少,未来可以在研究中加入用户的个人情感因素和群组成员之间的信任关系[39]等信息,从而能够融合生成更加具有代表性的群组偏好模型.
4.推荐方案的生成过程优化
针对群组意见不一致的问题,可以先聚集群组中相似度高的部分成员构成子组,使用偏好融合方法构成子组的偏好模型,再对不同的子组使用推荐融合方法,将不同子组的推荐列表融合成群组的推荐列表.或者对群组进行更细致的划分,将兴趣爱好相似的成员分成一个子组,提供给各个子组不同的推荐方案,为不同子组提供不同的选择.
5.增强群组推荐的可解释性
群组推荐的可解释性开始引起研究者的关注[44],在实际应用中也有很大价值,然而,群组推荐的可解释性具有更大的挑战,它需要解释如何得到群组的偏好信息,或者如何融合了每个成员的推荐结果.未来可以研究运用可视化技术对群组推荐进行解释.
6.群组推荐与个性化推荐的融合发展
由于群组推荐是在传统个性化推荐系统发展的基础上提出的,探究传统个性化推荐与群组推荐之间的联系,将更多传统个性化推荐的研究成果应用于群组推荐中,同时群组推荐的研究成果也有助于解决传统个性化推荐系统中的问题.此外,从群组与个人的关系入手,关注隐式群组的发现.例如,由于用户的社会角色,个体用户会代表整个群组的需求,此时会出现对个体用户进行群组推荐的模式.
6 结 论
群组推荐是推荐系统中的一种重要形式,吸引了研究者的广泛兴趣,被应用于餐饮、音乐、影视、旅行、商品、兴趣点、教育推荐等领域.关于群组推荐系统的研究已经有了一定的发展.本文对群组推荐系统的推荐过程和方法进行了系统总结与归纳.由于群组的异构性、动态性、群组成员兴趣的差别以及不同成员对群组的交互影响,使得群组推荐系统依旧面临许多技术挑战,需要进一步的研究.
