基于差分进化的中文情感分类集成算法研究
2020-04-11杨梦月陆慧娟卢海峰
杨梦月, 卫 伟, 陆慧娟, 卢海峰
(中国计量大学 信息工程学院,浙江 杭州 310018)
1 引 言
随着互联网的快速发展,越来越多的人通过网络表达自己的观点和看法,导致网上的评论数据与日俱增,所以,从文本中获取情感信息有着巨大的现实意义和研究价值。
从文本中提取情感倾向,就是文本情感分类[1~3]的主要内容。情感分类与传统的基于主题文本分类的区别在于情感分类关注的对象是一些主观因素,从文本中获取它是否支持某种观点的信息[4]。
目前,对情感分析的研究主要采用2种方法:一种是结合情感词典的方法,其主要依赖于情感词典的质量;另一种是结合机器学习的方法,其关键依赖于特征词的提取[5,6]。前者主要是依据情感词典从主观文本中提取带有情感极性的词,根据某种规则,获取文本的情感极性;后者首先要对文本进行特征表示,然后通过机器学习算法训练分类模型来完成分类任务。应用更为广泛的是基于机器学习的方法。
文献[7]提出了一种基于情绪词的非监督情感
分类方法,在中文评论语料上进行了实验,获得了较好的分类性能。文献[8]分别使用了不同词性、不同特征选择方法和不同分类方法在中文情感语料上进行了实验。文献[9]使用了朴素贝叶斯和支持向量机2种机器学习方法在电影评论语料上进行了实验;但是实验结果表明,这2种分类器在语料集上的分类准确率并不高,朴素贝叶斯的分类准确率是65.57%,支持向量机的分类准确率是45.71%。
单一的机器学习算法在文本情感分类上存在准确率不高,样本数据不多时对新样本分类效果不好的问题;而集成学习[10]通过将多个学习器进行结合,可获得比单一学习器显著优越的泛化性能。文献[11]使用了3种常用的集成学习方法Bagging、Boosting和Random Subspace在标准的文本情感分类数据集上进行了实验,实验结果表明3种集成学习方法对基础分类器的分类精度都有所提高。文献[12]提出了一种基于半监督集成学习的情感分类方法,实验结果表明,这种方法的分类效果明显优于单独的半监督情感分类方法。
集成方法较单个的分类方法有较好的分类效果;但是在集成多个分类器时,个体分类器的权重难以确定。为了解决这个问题,文章提出一种基于差分进化优化分类器权重的集成分类方法。
2 中文情感分类相关技术
2.1 文本表示
文本是一种特殊的数据格式,分类算法不能直接处理原始文本,必须把文本表示成可处理的数学向量形式。向量空间模型(vector space model,VSM)是最常见的文本表示模型。
在向量空间模型中,每个文本被表示成
D=(w1,w2,…,wn)
(1)
D是一个n维向量,wi是特征项权重,表示该特征项在文本中的重要程度,i=0,1,…,n。每个文本就是一个n维的向量。特征项权重wi可以用词频(term frequency,TF),TF-IDF(term frequency inverse document frequency),布尔函数等方法计算得出。由于实验所用数据集是评论类的短文本,使用词频作为特征项权重意义不大,而且文献[13]通过实验表明在情感分类中使用布尔函数计算特征项权重是可行的,因此,本文实验采用布尔函数计算特征项权重。
情感分类与其它文本分类的差别在于:情感的正面表达和负面表达主要以形容词、副词和少数动词和名词的表达为主[8]。因此,本文仅使用名词、副词、形容词和动词共4种词性的词作为特征项。
2.2 特征选择
文本向量化后的数据特征维度很大,一般不直接使用,就需要进行特征选择。卡方统计(CHI)在文本特征选择上有较好的效果,故本文实验采用卡方统计进行特征选择。
卡方值表示词项与类别之间的相关性,卡方值越大表示相关程度越高。
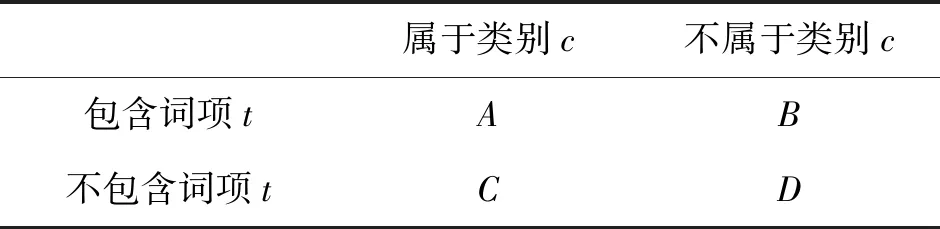
表1 CHI中各参数的意义Tab.1 The meaning of parameters in CHI
表1给出了CHI中各参数的意义,t表示一个特征项,c表示文本类别,A、B、C、D表示文档数目。N为文档总数,则N=A+B+C+D。
特征项t与类别c的卡方值为
(2)
2.3 分类方法
2.3.1 逻辑回归(logistic regression,LR)
逻辑回归是一种经典的分类算法,一般用于二分类。给定一个输入变量x,它可以计算出该变量属于某一类别的概率,逻辑回归模型为
(3)
式中:x是输入变量;w,b是参数;y是一个介于0到1之间的数。
对于给定的训练数据集T={(x1,y1),(x2,y2),…,(xn,yn)},求解参数w,b,得到逻辑回归模型。然后对于给定的输入变量x,计算出对应的y值,根据设定的阈值,判定x归属的类别。
2.3.2 线性判别分析(linear discriminant analysis, LDA)
线性判别分析是一个简单、有效、鲁棒性强的线性分类方法。该方法的思想是设法将样本数据投影到一条直线上,使同类别的投影点尽可能接近,不同类别的投影点尽可能疏远[14]。对于二分类来说,就是将带有类别标签的高维样本投影到一个向量W(一维空间)上,使得在该向量上样本的投影值达到类内距离最小、类间距离最大,根据这一准则,求解参数W,最后将样本点投影到新的一维向量空间进行分类。
2.3.3 朴素贝叶斯(naive Bayes,NB)
朴素贝叶斯是一个概率模型,在文本分类上有较好的分类效果。该方法假设特征之间相互独立,即词与词之间相互独立,文档d的特征是X,则文档d属于类别ck的概率是
(4)
对给定的文档特征X,求该文档属于每个类别的概率P(c|X),若最大的概率值是P(ck|X),则该文档属于ck类。
2.3.4 支持向量机(support vector machines,SVM)
支持向量机[15~17]是一种二分类模型,它的基本思想是求解能够正确划分训练数据集并且使几何间隔最大的分离超平面,其学习策略就是间隔最大化,最终可转化为一个凸二次规划问题的求解。对于非线性分类问题,将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。文献[7]通过实验证明了支持向量机在情感分类上有较好的分类效果。
2.3.5 感知机(perceptron learning algorithm,PLA)
感知机是一个二分类的线性分类模型,学习目标是寻找一个能将样本正例和负例完全正确分开的超平面。感知机模型可表示为
f(x)=sign(wTX+b)
(5)
式中:w,b是参数。
感知机使用随机梯度下降法,根据误分类点更新参数w和b,使损失函数最小化。
2.4 结合策略
集成学习中常用的结合策略有简单平均法、加权平均法、绝对多数投票法、相对多数投票法和加权投票法等。在本文的对比实验中,将提出方法的实验结果与采用简单平均法(averaging,AVE)的实验结果进行对比。
3 差分进化算法
3.1 差分进化算法
差分进化(differential evolution,DE)算法是用于求解优化问题的一种启发式搜索算法[18~20],具有较好的全局优化能力,通过在群体上不断进行变异、交叉操作,产生中间个体,利用贪婪思想根据适应度值选择表现较好的个体作为下一代种群个体,经过数次迭代找到问题的最优解。
(1) 初始化种群个体
随机产生m个个体,每个个体都是一个n维向量,n就是进行优化的参数个数,第i个个体的第j维初始化为
(6)
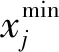
(2) 变异操作
对种群中的每个个体,变异操作就是根据随机选择的种群个体生成变异向量,变异向量有多种生成方式,这里选择的方式为
(7)

(3) 交叉操作
交叉操作是为了增加种群的多样性,将变异向量与种群个体交叉组成一个新的试验个体。交叉方式为
(8)
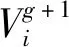
(4) 选择操作
采用贪婪策略,交叉操作产生的试验个体和原来的种群个体进行竞争,根据适应度值,将表现较优的个体保留下来,作为下一代的种群个体。选择方式为
(9)
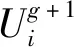
3.2 基于差分进化优化分类器权重的集成分类 算法
本文提出基于差分进化优化分类器权重的集成分类算法,并应用于中文情感分类。该方法通过差分进化算法优化集成方法中个体分类器的权重,以分类准确率为适应度值,寻找最优的个体分类器权重组合,通过加权集成得到最终的分类模型。算法描述如下:
输入:种群个体数目m;最大迭代次数G;变异因子F;交叉概率CR。
输出:最优权重组合w=(w1,w2,w3,w4,w5);最优适应度值best_fit。
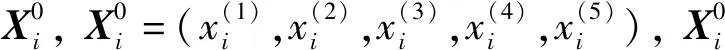
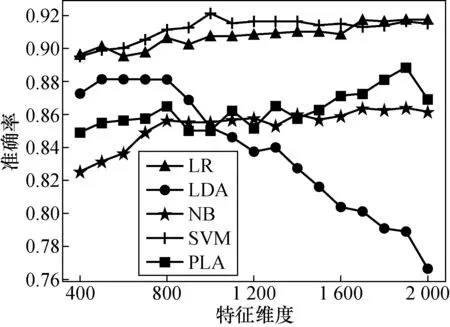
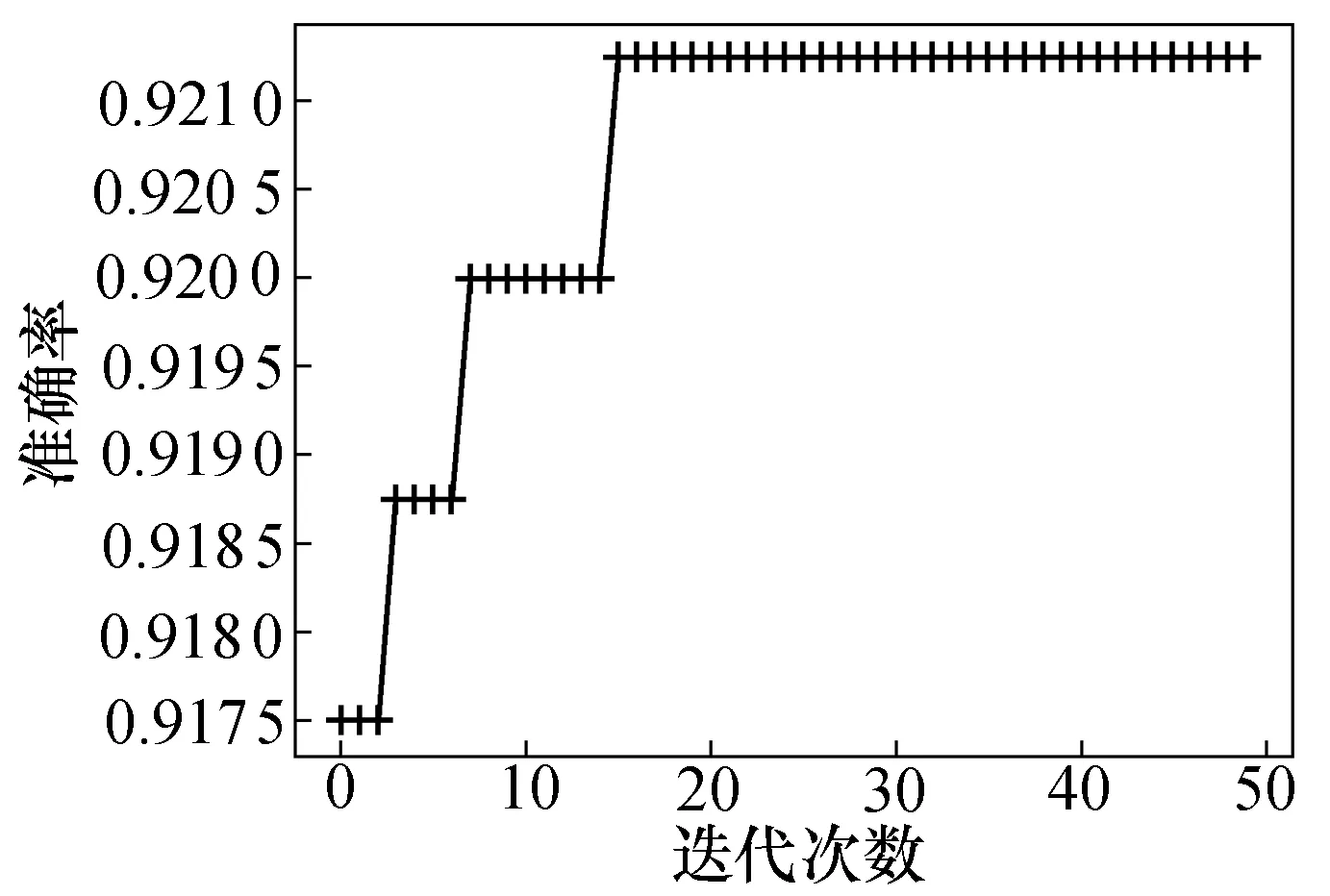
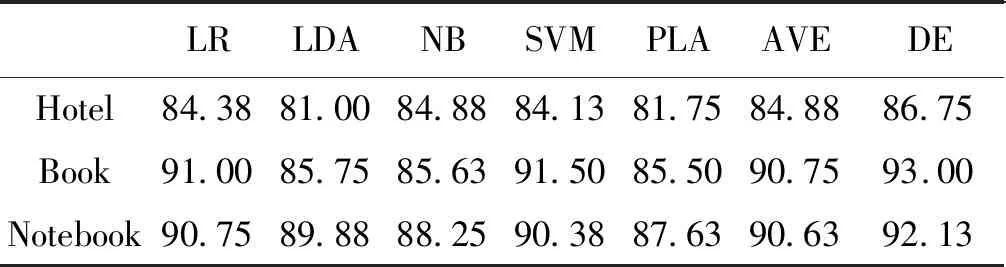
Step2:判断当前迭代次数g是否满足g Step4:g=g+1,返回Step2。 实验使用3个语料集:酒店评论(Hotel)、书籍评论(Book)和电脑评论(Notebook)。3个语料集均来自谭松波搜集整理的中文情感挖掘语料。3个语料集各有正向、负向评论文本2 000例。 文本预处理:使用中科院NLPIR2014汉语分词系统对评论文本进行分词和词性标注,保留名词、动词、形容词和副词共4种词性的词作为特征项;利用向量空间模型进行文本表示,将每个文档表示为一维向量形式;使用卡方统计方法进行特征选择,保留较为重要的特征项,过滤掉不重要的特征项。 4.2.1 个体分类器的实验结果分析 从数据集中各抽取正向、负向评论的80%作为训练集,20%作为测试集;用LR,LDA,NB,SVM,PLA在训练集上分别进行训练;实验使用文本分类中较为常用的分类准确率作为模型评价标准。 在情感分类任务中,对分类有影响的是具有情感极性的特征词,而这类特征词占总特征词的比例较低,所以大部分特征词是无用的,如果保留全部特征反而会干扰分类效果。 图1~图3分别给出了在3个数据集上,选择不同的特征维度时,LR,LDA,NB,SVM,PLA的分类准确率变化情况。可以看出,LR,NB,SVM,PLA在不同特征维度上的分类准确率折线较为平稳,在一定范围内波动,而LDA的分类准确率随特征维度的增大呈下降趋势。因为提出的模型是一个集成模型,每种个体分类器的准确率会影响到整体模型的准确率,所以每种个体分类器的准确率不能过低,否则会降低整个模型的分类效果。在Hotel数据集上,特征维度为800时,LDA的准确率已经低于80%,并且持续下降,所以数据集的特征维度不能过大。同时特征维度又不能太小,否则会影响分类效果。综合以上因素,在后续实验中,选择数据集的特征维度为800。 图1 Hotel数据集上准确率对比Fig.1 Accuracy comparison on Hotel datase 图2 Book数据集上准确率对比Fig.2 Accuracy comparison on Book dataset 图3 Notebook数据集上准确率对比Fig.3 Accuracy comparison on Notebook dataset 表2给出了5种分类器在3个数据集上进行10次训练的平均分类准确率。可以看出,在3个语料集上,LR和SVM表现最好。LR和SVM在Hotel语料集上的分类准确率可以达到84%左右,在Book和Notebook语料集上可以达到90%左右。5种分类器在Book语料集和Notebook语料集上的分类效果都明显优于在Hotel语料集上的分类效果,这种分类效果的差异可能是由于语料文本本身的差异性所致。 表2 5种分类器在3种数据集上的分类准确率Tab.2 Accuracy of five classifiers on three data sets (%) 4.2.2 差分进化算法优化个体分类器权重的实验 结果分析 使用差分进化算法,根据2.2节中的算法描述,对5种个体分类器的权重进行优化。实验之前,设置种群数目m=50,最大迭代次数G=200,缩放因子F=0.5,交叉概率CR=0.5,在3个数据集上分别进行实验。 图4~图6给出了在3个数据集上,分类模型的准确率随差分进化算法迭代次数的变化情况。可以看出,随着迭代次数的增加,模型的分类准确率也在逐渐上升,达到一定的迭代次数后,分类准确率趋于稳定,说明算法达到收敛状态。差分进化算法具有收敛速度快的优点,经过多次试验,算法的迭代次数在50代以内已经收敛。所以,在后续的对比实验中,将差分进化算法的最大迭代次数设定为50次。 图4 Hotel数据集上准确率随迭代次数变化Fig.4 The accuracy of the Hotel dataset varing with the number of iterations 图5 Book数据集上准确率随迭代次数变化Fig.5 The accuracy of the Book dataset varing with the number of iterations 图6 Notebook数据集上准确率随迭代次数变化Fig.6 The accuracy of the Notebook dataset varing with the number of iterations 使用基于差分进化优化分类器权重的集成分类方法(DE)在3个数据集上进行实验,经过多次运行,调试参数,当种群数目m=40,缩放因子F=0.9,交叉概率CR=0.5时,分类效果最好。将实验结果与单个分类方法和简单平均方法(AVE)的实验结果进行对比,对比情况如表3所示。 表3 各个分类方法的准确率对比Tab.3 Accuracy comparison of each classification method (%) 从表3的实验结果可以看出,使用差分进化算法优化个体分类器权重后的分类模型(DE)在3个语料集上的分类效果都有所提高,与简单平均法方法(AVE)相比,分类准确率提高了2%左右。 差分进化算法是在遗传算法(genetic algorithm,GA)的思想上提出来的,与遗传算法相比,差分进化算法具有参数少、容易实现、收敛速度快的优点。因此,文章提出一种基于差分进化优化个体分类器权重的集成分类方法。选择5种个体分类器,用差分进化算法优化分类器权重,然后通过加权集成得到最终的分类模型,并在3个领域的评论文本上进行了实验。实验结果表明,这种方法的分类效果较加权投票方法有明显提高。 对情感分类的研究目前集中在对商品评论文本分类上,即判断文本表达的是支持还是否定的态度。在后续工作中,将进一步研究多类别情感分析,例如,判断一个文本表达的情感是喜欢、高兴、伤心、愤怒等,从而更准确地提取文本中隐含的主观情感。4 实验及结果分析
4.1 数据集
4.2 实验结果分析




5 结束语
