结合DBSCAN聚类与互信息的图像拼接算法
2020-04-11张美玉王洋洋吴良武秦绪佳
张美玉,王洋洋,吴良武,秦绪佳
1(浙江工业大学 计算机科学与技术学院,杭州 310032)2(大连测控技术研究所,辽宁 大连116013)
1 引 言
图像拼接是通过匹配将具有重叠部分的多幅图像合并成一幅高清晰宽视角的图像.图像拼接技术已广泛应用于摄影绘图,三维重建,虚拟现实,计算机视觉等领域.图像拼接方法有三大类:第一类是基于变换域的方法,又叫相位相关法.该方法最初由Kuglin和Hines于1975年提出,该方法基于快速傅立叶变换,将拼接图像转换为频域,接着利用相互功率谱,可计算出两幅图像间的平移矢量,用平移矢量实现图像拼接.但是该方法非常依赖图像的重叠率,当重叠率不到50%,会错误估算平移矢量,图像就很难配准.第二类是基于灰度相关的方法.该方法是用图像的部分区域作为模板来匹配另一幅图像中最相似的区域.该方法实现简单,图像不需要预处理,但计算量非常大,无法做到实时性.第三类是基于图像特征点的方法.该方法是先提取图像特征点,然后通过两幅图特征点之间的对应关系找到两幅图像之间的变换关系.基于特征点方法是目前主流的拼接方法,它对图像变形,缩放,照明等变化有很好的鲁棒性.
提取图像特征点方法很多,有Harris、SIFT、SURF、FAST和ORB等算法.本文提取特征点的方法是ORB算法,ORB算法是Ethan等人在2011年提出的[1],是基于FAST角点检测算法和BRIEF描述子并加以改进.ORB算法改进后运行速度得到很大提高,运算速度是SIFT算法的100倍,是SURF算法的10倍[2].FAST(Features from Accelerated Segment Test)角点检测方法由Edward Rosten和Tom Drummond在2006年提出,计算速度快,精确度高,常用于快速检测图像的角点.Calonder提出一种特征描述符(BRIEF)[3],该特征描述符是用二进制串表示的,减少了特征点提取时间,对存储空间的需求也相应减少,但特征点不具备尺度和旋转不变性.
张树生等人通过邻接图在三维CAD模型中检索相似区域[4].鉴于他们的思路,本文用DBSCAN算法对特征点进行快速聚类,然后利用聚类结果构建邻接图,通过邻接图来估计图像的重叠区域.仅在重叠区域内的筛选特征点,可以减小计算量,提高特征点匹配的效率.特征点粗匹配,传统的方法是利用欧式距离,匹配的特征点较少,而且存在错误匹配.为了匹配更多的特征点,减少错误匹配,本文采用了二值化互信息与欧式距离方法相结合的筛选方法[5,6],分段匹配特征点,可以得到更多更准确的匹配点集.为了得到更精确的变换矩阵,本文利用已有特征点在重叠区域边界添加新的特征点,再用RANSAC算法提纯并计算变换矩阵,最后得到更好的图像拼接结果.
2 基于DBSCAN估计重叠区域
本文为了加快图像匹配速度,只对重叠区域内的特征点进行匹配,先用DBSCAN聚类算法估算了图像重叠区域.得到重叠区域主要包含三个步骤:特征点检测与描述、特征点的聚类、用邻接图估计重叠区域.
2.1 特征点检测与描述
ORB是基于视觉信息的特征点检测和描述算法,ORB改进了FAST角点检测与BRIEF描述子.ORB算法中的特征点提取是用FAST角点检测方法[7],FAST是检测像素点与周围像素点的像素差,如果像素差大于某一阈值,就判定该像素点为角点(特征点).FAST检测角点只是比较像素值大小,其角点不具备尺度和旋转不变性.
ORB算法中用了灰度质心法解决了角点不具备方向性问题.当角点的灰度值与质心的灰度不同时,则角点与质心存在一个偏移,通过这个偏移来确定主方向.角点的灰度矩定义为:
(1)
其中的p,q决定了灰度的阶数,I(x,y)是像素点(x,y)的灰度值.
图像块的质心C为:
(2)
接下来就是构建方向,从图像块角点中心到质心的方向就是特征点的方向,计算方向的公式为:
θ=arctan(m01,m10)
(3)
ORB算法是用BRIEF特征描述子描述这些特征点.BRIEF算法对噪声敏感,ORB算法用像素平均值来替代某点的灰度值,减少噪声的干扰.BRIEF算法是用二进制串描述特征点,是在特征点邻域内随机选取一些点对,用0、1记录这些点对,得到一个二进制串,用二进制串描述该特征点.二值判断方法为:
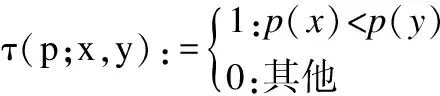
(4)
其中p(x)是图像块p在点x处的灰度值.
二进制串的计算公式为:
(5)
BRIEF描述子也没有旋转不变性,ORB算法将特征点方向作为BRIEF描述子的主方向.在像素(xi,yi)点处,对n个二进制特征集任意一个,可定义一个2*n的矩阵M:
(6)
用特征点方向θ的旋转矩阵R作为变换矩阵,对矩阵M旋转变换,使矩阵M变为有向形式:
(7)
旋转变换公式为:Sθ=RθM.最后BRIEF特征描述子结果为:
gn(P,θ)=fn(P)|(xi,yi)∈Sθ
(8)
为了图像拼接的实时性,本文用ORB算法提取特征点数目是500对.
2.2 特征点的聚类
DBSCAN是一个基于密度的聚类算法[8].DBSCAN聚类算法的步骤如下:
1)需要二个参数:扫描半径(eps)和最小包含点数(minPts).从特征点中随机选取一个没有被访问的点,在其附近寻找所有距离小于扫描半径的特征点.
2)当找到的特征点数目大于最小包含点数,该特征点和附近的特征点构成一个簇.接着用同样的方法遍历其他没有被访问的点.
3)当找到的特征点数目小于最小包含点数,该特征点是没用的噪声点,就接着遍历下一个未访问的特征点.
4)当簇完全扩展时,即簇中的所有点都是已访问的点,接着用相同的方法处理其他未访问的特征点.
根据特征点的位置,用DBSCAN算法进行聚类.如果扫描半径过大,簇的数目就会少,而且覆盖区域非常大,无法用来计算重叠区域.如果扫描半径较小,簇的个数就太多,增加不必要的计算量.簇的数目控制在10到30比较好,而且聚类时间短,不超过20ms.如图1所示,图(a)有14个簇,图(b)中23个簇.
2.3 用邻接图估计重叠区域
首先利用簇之间的分布关系构建邻接图,再用邻接图的属性找到最相似的几个簇,最后用相似簇的位置得到重叠区域.
2.3.1 构建簇的邻接图
首先根据特征点的位置信息,求出簇的中心点.根据簇的中心点位置,得到两个簇之间的距离d.同时统计每个簇包含特征点的数目,并计算这两个簇的特征点数目的比值r.r、d是估计重叠区域的重要参数.
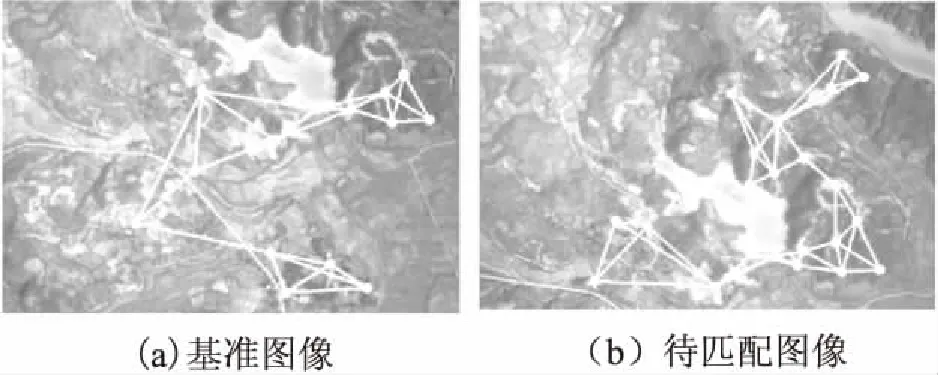
图1 簇的邻接图Fig.1 Adjacency graphs of clusters
然后根据两个簇间的距离,连接三个距离最小的相邻簇.每个簇都与最近的三个簇相连接,构成由簇组成的邻接图.如图1所示.
2.3.2 估计重叠区域
上一步骤可以得到两个邻接图G1和G2,顶点集V1和V2,边集E1和E2.估计重叠区域的具体步骤如下:
Step1.对图G1中任意一条边ei(1≤i≤n),遍历图G2中的每一条边ej(1≤j≤m),比较两点距离di、dj和特征点数目比ri、rj的大小,如果误差在阈值内,就认为ei与ej相似,将(ei,ej)保存到相似边集合HE中.
Step2.选取集合HE中的一组相似边(ea,eb),遍历集合HE的其他相似边(ec,ed).其中边ea、ec属于邻接图G1,包含4个顶点,选择其中三个顶点,与G2中的对应的三个顶点相比较.通过比较三边距离总和、特征点数目的比值,如果误差在阈值范围内,就认为这三点是正确的簇点,保存在最终结果S中.然后,随机选择S中两个点,验证剩下的一个顶点,依旧用距离总和、特征点数目比进行验证.

图2 估计重叠区域Fig.2 Estimation of overlapping regions
最后根据点集S中点的坐标,求出一个包含相似簇的最大区域,如图2中小矩形.因为簇是由特征点聚类得到,两幅图的特征点位置是不同的,所以根据簇得到的小矩形重叠区域不精确.本文在小矩形的基础上,选取一个更大的范围作为重叠区域,如图2中大矩形围成区域.
3 二值化互信息筛选特征点
根据图像的特征点,采用基于K最近邻近算法[9]快速对特征点进行匹配,匹配结果中有大量的错误,所以要去除错误的匹配对.在特征点粗匹配过程中,传统的方法是利用欧式距离.欧式距离方法是在基准图任选一个特征点,然后通过欧式距离在待匹配图像中找到距离最近的两个点,当最近邻和次近邻的距离比值小于某一阈值,是正确的匹配点.采用欧式距离方法,如果阈值小,筛选的特征点数目少;如果阈值大,筛选的特征点错误率高,所以阈值控制比较困难.本文是用二值化互信息筛选方法与欧式距离方法相结合,筛选特征点的数目多,正确率高.
3.1 图像的二值化互信息
信息熵是用来衡量一个信源所包含信息量的度量.图像的信息熵是指一个图像所包含的信息量[10],熵值反映了一张图像的复杂性或不确定性,图像中灰度值分布越分散,表示灰度值具有很大的不确定性,则图像的熵值越大.信息熵表达式为:
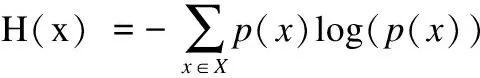
(9)
其中,x是图像灰度值,p(x)是灰度值x的概率.
互信息在图像中是统计一幅图包含另一幅图的信息总量,可以度量两幅图像相似度[11].图像互信息的表达式为:
I(A,B)=H(A)+H(B)-H(A,B)
(10)
其中H(A)、H(B)是图A、图B的信息熵,H(A,B)是联合熵.联合熵是度量一个联合分布的不确定性,这里统计了两幅图灰度值分布不相关概率.联合熵的表达式为:
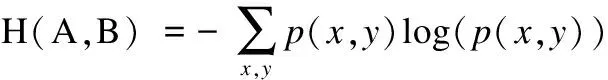
(11)
联合熵[12]就越小,则互信息就越大,就说明两幅图相关性越大,也能反映两幅图像相似度越高.
本文使用图像的二值化信息来计算互信息,不仅可以减少图像噪声的干扰,而且在计算过程中,灰度值只有0和255,所以只要统计灰度值为0、255的分布概率,大大减少计算量,在粗匹配过程中,能够实时地筛选特征点.
3.2 二值化互信息筛选特征点
Step1.随机选取一对特征点,根据上一步骤得到的重叠区域,先判断该对特征点是否在区域内,如果不在重叠区域,随机选择下一对特征点.如果在重叠区域内,才去判断是否是正确的匹配对.
Step2.先利用欧式距离方式,计算最近邻和次近邻的比值,如果比值小于0.6,则认为是正确的匹配对.如果比值大于0.6且小于0.9,就用二值化互信息进一步判断特征点是否匹配正确.如果比值大于0.9,就判断下一对特征点.
Step3.根据特征点坐标,截取特征点邻域,使用二值化信息,根据公式(9)-公式(11),计算特征点的互信息.如果互信息大于0.4,就判断为正确的匹配对.
3.3 筛选特征点流程
筛选特征点流程如图3所示.
4 改进的RANSAC算法
通过二值化互信息筛选的特征点,虽然提高了正确率,还有一定的误匹配,需要通过RANSAC算法再次提纯,并求出变换矩阵.
很多图像提取的特征点,都集中在颜色变化区域,特征点分布不分散,筛选后的特征点较集中.如果一些图像的特征点集中某一小区域,用RANSAC算法求得的变换矩阵稍微有误差,拼接结果误差会更大[13].针对特征点集中问题,本文在求变换矩阵前,先在重叠区域边缘选取一些新特征点.使特征点分散在重叠区域.
4.1 RANSAC算法
RANSAC算法的主要步骤如下:
1)用置信概率P、数据错误率ω和最小量数据m来计算模型参数、抽样次数.抽样次数的计算公式为:
1-(1-(1-ε)m)M=P
(12)
2)从初始样本中随机选取4对匹配点对(要求四点不共线),并计算出变换矩阵H.
3)用变换矩阵H来计算出剩余的特征点对之间的欧式距离d.
4)若欧式距离d小于某一阈值,则认为该匹配点为内点,否则为外点.并统计内点的数目S.
5)重复上面2)-4)步骤,直到达到循环次数或内点数目最多且数目不变时,得到最佳的变换矩阵H.
RANSAC算法根据置信度、总匹配个数、当前内点个数、当前的总迭代次数动态的改变总迭代次数的大小[14].当内点占比多时,很快能找到正确估计,迭代次数就会减少,而且是以指数形式减少的,所以,当内点占比高时,最终的迭代次数可能只有几十次.本文在粗匹配得到的特征点样本数不超过200,正确匹配多,内点率高,故RANSAC算法的总迭代次数很少,计算耗时极小.
4.2 改进RANSAC算法
根据估算的重叠区域,在重叠区域边界选取一些点,筛选部分作为新的特征点,最后再用RANSAC算法提纯,并计算变化矩阵.筛选新特征点步骤如下:
Step1.选取特征点.在特征点集合中随机选择两对特征点.在第一幅图中,根据重叠区域边界在两点的延长线上截取一点,通过三点坐标的距离比例,计算出另一幅图中对应的第三点坐标.
Step2.验证新特征点.用RANSAC算法计算变换矩阵H.用H计算待匹配图像中三点的变换后位置.比较基准图像中三点距离,与待匹配图像中变换后三点距离,如果误差大于某一阈值,就重新选取.
Step3.再次验证新特征点.计算两个新特征点的二值化互信息,如果互信息小于0.4,就重新选取.如果大于0.4,就可以做作为新的特征点.
增加的新特征点,都分布在重叠区域边缘,同时使用变换矩阵、二值化互信息两种方法同时验证,保证了新特征点是正确性,同时也防止新特征点添加过多.如图4所示,是添加新特征点,增加124对新特征点,新增特征点都分布在重叠区域的边界.

图4 新特征点Fig.4 New feature points
最后,把新得到特征点与已筛选特征点合在一起,再用RANSAC进行提纯,并计算变换矩阵,实现图像拼接.
5 实验与结果分析
实验硬件环境为:处理器Intel Corei5-7500 CPU@3.41GHz,操作系统为Windows10.实验图像是不同来源不同场景的图像.本文实验用SIFT+RANSAC算法与本文算法进行了比较.
5.1 特征点匹配实验对比
不管用哪一种算法提取特征点,运算速度与提取特征点的数目成正比.提取5000对特征点,用SIFT算法耗时超过10s,用ORB算法大约是0.8s.本文提取特征点数目为500对,欧式距离方法的阈值比是0.75.如图5所示,图5(a)是SIFT算法提取特征点,然后用欧氏距离方法进行匹配,得到结果有128对特征点.图5(b),用ORB算法和欧式距离方法匹配了79对特征点,特征点相对集中.图5(c),用本文算法得到205对特征点,与图5(b)比较,特征点位置分散很多.

图5 特征点的筛选Fig.5 Screening of feature points
为了进一步说明本文算法的准确性与实时性,表1统计了5组实验数据,并求出了平均值.每组图像提取500对特征点.从表1中可以看出,SIFT算法匹配的准确度虽然高,但耗时太长,不能做到实时性.用ORB算法和欧氏距离方法筛选特征点,耗时最短,但准确度比较低.本文算法匹配的特征点最多,耗时较短,可以做到实时性.

表1 不同算法对比Table 1 Comparison of different algorithms
5.2 拼接结果对比
图像拼接结果如图6所示,图6(a)、图6(c)是用欧式距离方法,因为匹配的特征点数目较少,还有一些错误匹配,拼接错位,拼接结果并不理想.图6(b)、图6(d)是用本文算法的拼接结果,从图中看出本文算法可得到一个很好的拼接结果.如果用SIFT算法,耗时长,无法实现实时拼接.

图6 图像拼接结果Fig.6 Image mosaic results
6 总 结
本文用ORB算法提取图像特征点,极大地加快图像的拼接速度.然后用DBSCAN聚类算法构建邻接图,通过邻接图寻找图像的重叠区域,在重叠区域的约束下,提高了特征点匹配的效率和匹配的正确率.本文用二值化互信息与欧式距离方法相结合,分段匹配特征点,提高了特征点匹配数目,也提高了正确率.最后,用已筛选的特征点在重叠区域边界添加新的特征点,可以有效解决特征点集中的问题.实验证明,通过本文方法能够实时、高效、准确的实现图像拼接.
