HEVC中运动补偿算法的动态可重构实现
2020-04-11谢晓燕周金娜刘新闯
谢晓燕,周金娜,朱 筠,刘新闯,雷 祥
1(西安邮电大学 计算机学院,西安 710121)2(西安邮电大学 电子工程学院,西安 710121)
1 引 言
HEVC是在视频编码专家组(Video Coding Experts Group,ITU-T VCEG)和运动图像专家组(Moving Picture Experts Group,ISO/IEC MPEG)的共同协作下开发的最新视频编码标准[1].HEVC具有显著的压缩效果,在确保与H.264相同视频质量的同时降低了50%的比特率[2].其预测单元块(Prediction Unit,PU)的大小从64×64到4×4不等[3].运动补偿算法由于不同尺寸的编码单元和插值操作,采用了8抽头亮度滤波器和4抽头色度滤波器.HEVC的内插滤波器分别占编码器和解码器执行时间的20%~30%和20%~40%,使得插值滤波器成为HEVC中最耗时的编码工具之一[4],插值运算的高复杂性增加了对硬件加速的需求.为了提高运动补偿算法的计算效率,一些学者提出了多种解决方案.
文献[5]提出了四行并行2维(2 Dimensional,2D)缓存机制,以减少61.86%的存储器流量并支持更高的内插器吞吐量,可以更高效地完成数据的更新,但是其硬件设计复杂,灵活性差.文献[6]根据运动补偿算法中8抽头滤波器的系数设计出了21个加法器完成滤波操作,将A、B型滤波器合并为一个可重构滤波器架构.虽然这种方法与H.264相比效率提高了0.043%,但是所需滤波器和寄存器的数量较多,占用硬件资源较大.文献[7]设计了一种可重构数据通路的亮度插值滤波器,拥有较高的设计效率,但是需要额外的存储器和控制逻辑.文献[8]提出了一种新的灵活的硬件结构,用于插值滤波器中使用的半像素和四分之一像素.该架构可以在30个时钟周期内处理4×4 PU的整个分数位置,但是却仅能计算4×4块.文献[9]使用64个可重构的滤波器来满足不同的滤波器类型,该架构虽然能够实现高吞吐量,但是设计复杂性较高,仅能计算8×8块.文献[10]提出了并行化和流水线结构的分像素插值方案,采用高并行度的8输入双通道插值器,实现了视频的实时传输,但所占资源较多.
综上所述,动态可重构的并行化运动补偿算法已成为视频高计算性能有效的解决方案[11].本文采用动态可编程可重构的阵列处理器来实现运动补偿算法的并行化实现,基于该结构即高效又灵活的特点,又采用数据复用和并行操作的思想,动态实现运动补偿算法的可变块模式切换.提高插值过程的计算效率,缩短了编码时间,提高算法的灵活性.
2 运动补偿算法
运动补偿算法采用8抽头滤波器替换H.264中的6抽头滤波器,新的8抽头滤波器中使用了三种不同的插值系数,使得分数精度的样本预测更加精确,插值系数如表1所示.
表1 分数精度样本位置对应插值系数
Table 1 Fractional accuracy sample position corresponding
to interpolation coefficient

分数精度样本位置插值系数 a、d、e、f、g{-1,4,-10,58,17,-5,1}/64 b、h、i、j、k{-1,4,-11,40,40,-11,4,-1}/64 c、n、p、q、r{1,-5,17,58,-10,4,-1}/64
图1所示为亮度插值分数精度样本位置示意图.整数样本所在位置用大写字母表示,分数样本所在位置用小写字母表示.当运动矢量(Motion Vector,MV)指向整数样本所在位置时,不进行插值运算,直接以此整数样本值作为最后的预测结果输出.当运动矢量指向分数位置时,即1/2像素精度或1/4像素精度位置时,运动补偿插值模块将利用插值滤波器进行非整数样本预测.
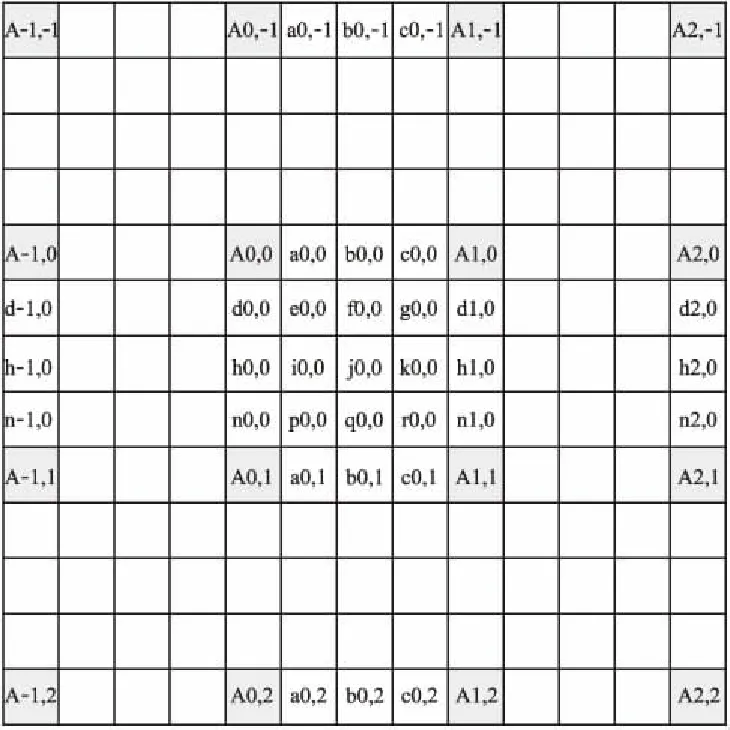
图1 亮度插值分数精度样本位置Fig.1 Luma interpolation score accuracy sample position
运动补偿算法的数据相关性大部分来源于参考像素的读取,插值操作需要用周围的像素点作为参考.例如一个8×8编码块,最多需要15×15参考块,而对于下一个编码块,也需要15×15参考块.其中当前参考块的数据和下一参考块的数据存在数据重叠现象,如果对参考数据分开做处理,则需要复杂的控制逻辑来完成.而针对更大的编码块,需要的参考块数据更多,可以根据数据复用思想来更新下一参考块数据.并且PU块越大,需要计算的插值像素点越多,需要处理的分像素位置情况也更复杂.如果每次只处理一个像素点,只针对一种分像素位置进行处理,耗时较长,算法的计算效率低下.运动补偿算法在同一时间内可以进行相同的插值计算操作,比如执行8×8像素块,每个像素点的插值计算和其余63个像素点的插值计算并无数据相关性,所以插值计算过程可以采用并行的思想,在同一时刻处理多个像素.读取参考块数据和插值计算数据存在相关性,所以参考块读取与插值计算这两个过程为串行执行.
依照前面分析,本文提出一种基于动态可重构阵列处理器的运动补偿并行插值计算方法,该结构兼顾专用硬件的高效性和通用处理器的灵活性,充分满足了运动补偿算法插值计算的需求[12].同时采用数据复用的思想进行参考块数据的动态选取,进行阵列和指令的可配置来实现可变块模式的动态选择.
3 参考块数据更新
采用数据复用的思想进行参考块数据的动态选取,参考块更新以8×8的编码块为例进行说明.当前一编码块处理完之后,就紧接着处理下一编码块,这涉及到了参考块数据的更新,如图2所示.当前参考块和下一个参考块数据重合的区域大小为7×15,则下一个参考块可以通过当前参考块更新120个数据即可得到下一个参考块.该过程分为两个步骤,执行流程图如图2所示.
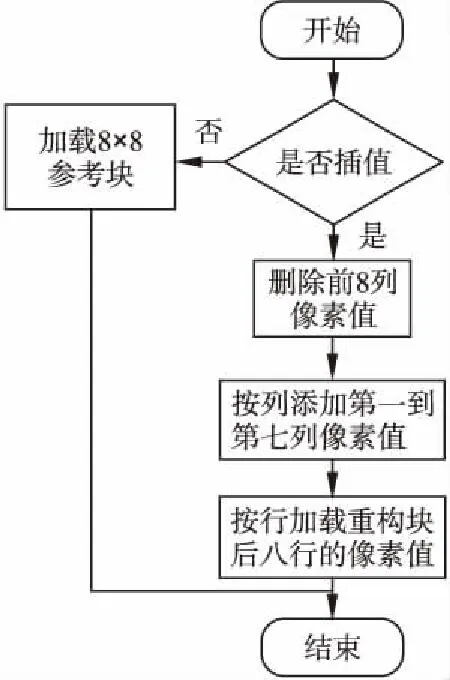
图2 更新参考块数据Fig.2 Update reference block data
第一步:按列处理参考块像素:首先将处理元中15×15参考块的前8列像素值删除.并把第9列像素作为重构15×15参考块的第1列像素;然后把第10列像素作为重构15×15的参考块的第2列像素;把第11列像素作为重构15×15的参考块的第3列像素;把第12列像素作为重构15×15的参考块的第4列像素;把第13列像素作为重构15×15的参考块的第5列像素;把第14列像素作为重构15×15的参考块的第6列像素;最后把第15列像素作为重构15×15的参考块的第7列像素,即处理完成下一参考块的前7列数据.
第二步:将剩余参考块数据从外存中按行加载,处理后8列像素:先将第一行8个像素从外存中加载进来,放在重构15×15参考块的第1行像素位置;再将下一行8个像素从外存中加载进来,放在重构15×15参考块的第2行像素位置;并将第3行8个像素从外存中加载进来,放在重构15×15参考块的第3行像素位置;以此类推,最后将第15行8个像素从外存中加载进来,放在重构15×15的参考块第15行像素的位置.
4 运动补偿算法的动态可重构实现
4.1 动态可重构结构
本文所采用的可重构视频阵列结构由1024个同构且规则的轻核处理元以邻接互连的方式构成,簇内通过邻接互连和共享存储通信,簇间通过路由器和适配器进行通信.可重构阵列处理器由全局指令存储器、输入存储器、输出存储器、阵列处理器和全局控制器五部分组成.全局指令存储器用于存储阵列处理器工作的操作指令和调用指令;输入存储器负责从外存中加载相应的视频序列;阵列处理器为核心计算部分由8×8个簇(Processing Element Group,PEG)组成.全局控制器为可重构机制的核心部分,全局控制器用于实现对阵列计算资源的控制与管理,包括操作指令的广播、调用指令的分发、计算资源信息的收集等.其上层为主机接口,下层为32×32个处理元(Processing Element,PE)组成的阵列处理器.主要功能是在主机接口和阵列处理器之间形成一个层次化编程网络,利用层次化编程网络来实现对阵列计算资源的控制与管理.为取址简单,寻址过程中的位宽可以逐级递减以确保每一条指令都同时到达PE,层次化编程网络设计通过H型网络进行指令加载.主处理器只需要向全局控制器发送任务指令和必要的数据或数据存储地址,全局控制器便会控制指令传输网络分配指令给不同PE执行相应的操作,如图3所示.
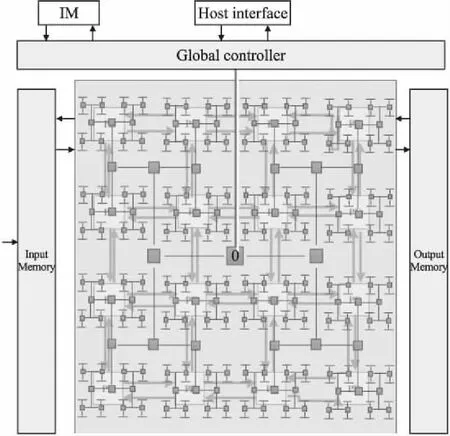
图3 动态可重构阵列处理器Fig.3 Dynamic reconfigurable array processor
4.2 运动补偿算法的并行化实现
在运动补偿算法中,处理的编码块越大,需要计算的插值像素点也就越多,待处理的分像素位置情况越复杂.如果每次只处理一个像素点,只针对一种分像素位置进行处理,则耗时太长,算法计算效率低下.所以本文采用数据并行的思想,在同一时间处理多个像素点,缩短数据读取和计算时间从而提高算法的计算效率.以8×8块大小为例,算法的映射图如图4所示,具体操作步骤如下:
Step 1.原始数据和参考数据加载.当前帧的数据存储在DIM中,参考帧的数据存储在到DOM中的.PE00访问DIM,读取原始像素值,并发送到PE03.同时PE01访问DOM,读取相应的参考像素值.并下发到PE00,PE11,PE02,PE03.其中PE00将数据下发给PE10,PE20,PE30;PE11将数据下发给PE21,PE31;PE02将数据下发给PE12,PE22,PE32;PE03将数据下发给PE13,PE23,PE33.为了提高数据传输效率,不需要等待PE00下发完后其他PE才下发,只要某个PE接收到下发数据命令就立刻将数据下发给相对应的PE.
Step 2.插值计算.各个PE接收到数据之后,开始进行1/2或者1/4插值计算.由于运动补偿算法在同一时间内有大量相同的插值计算,每个像素点的插值计算和其他像素点的插值计算并无数据相关性,所以插值计算可以在16个PE中同时进行.插值计算完成后再将预测值通过共享存储传输到PE03中.
Step 3.将PE03中的预测值和当前像素值进行残差计算,计算完后将残差值传输到PE30中与预测值完成图像重建.
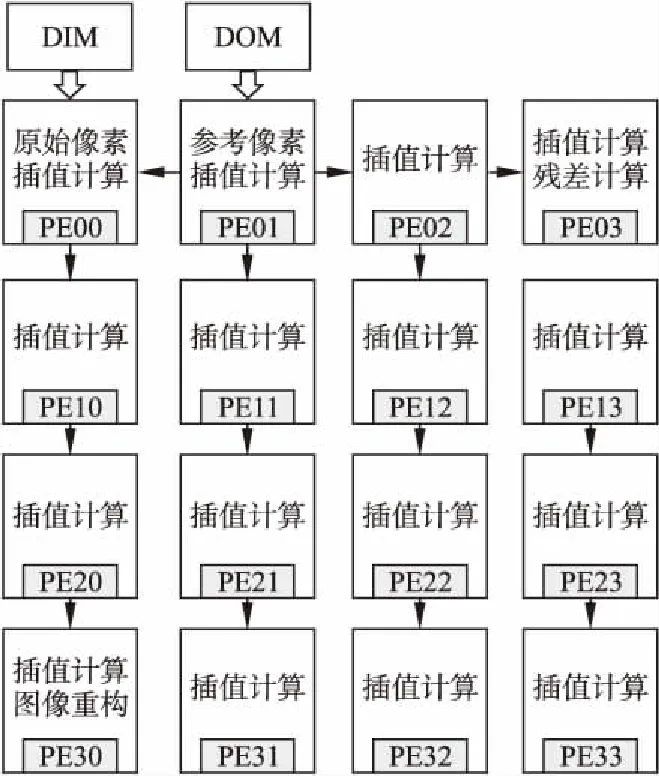
图4 运动补偿算法的映射图Fig.4 Map of motion compensation algorithm
4.3 运动补偿算法的可重构实现
运动补偿算法支持所有可能的PU尺寸,其范围从4×4像素块到64×64像素块,这对内存访问,控制和处理的并行性要求是一个重大挑战.为了应对这一挑战,本文提出了一种运动补偿算法的动态可重构实现方案,基于上下文切换的重构机制,实现对可变块算法的动态映射.动态重构机制主要核心分为指令重构和规模重构.主要用到指令下发网络的指令广播操作和指令下发操作.指令重构是将不同块的代码下发到相应簇中,实现PE功能单元的重构.规模重构是基于上下文切换的方式将指令预先存放在阵列结构中每个PE自带的指令存储器中,然后通过广播操作同时开启所需PE.规模重构有256个PE(16个PEG),64个PE(4个PEG)和16个PE(1个PEG),当执行4×4至64×64块大小时,PEG00-PEG33的本地同时存储指令,其规模重构如图5所示.若做64×64的块大小,则通过指令广播操作指令让所有的簇(PEG00-PEG33)工作;若做32×32块大小,则通过指令广播操作指令让所有的簇(PEG00-PEG11)工作;若做16×16块大小,则通过指令广播操作指令让簇(PEG00-PEG01)工作;若做8×8块大小,则通过指令广播操作指令让簇(PEG00)工作;若做4×4块大小,则通过指令广播操作指令让簇(PEG01)工作.
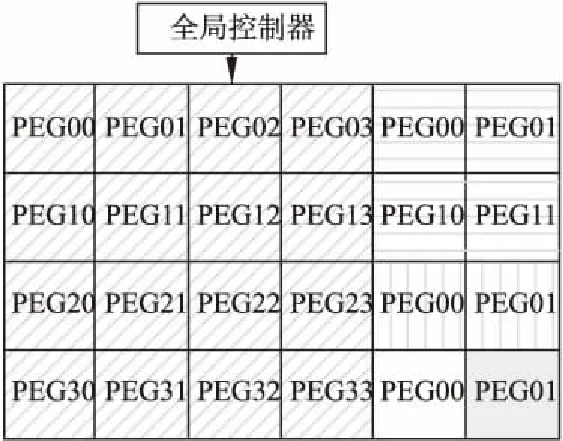
图5 4×4-64×64运动补偿算法可重构功能图Fig.5 4×4-64×64 motion compensation algorithmreconfigurable function diagram
下面以4×4块大小切换8×8块大小为例具体说明.在加载之前应针对不同分辨率的测试序列进行编码块首地址存放.首先将YUV测试序列通过Matlab软件转换成阵列结构能识别的二进制数值.并将该数据以阵列的格式分布在文档中,存放到DIM中.当执行4×4块大小,通过广播操作指令让PEG00工作,当执行完4×4块大小之后,通过CALL调用指令切换到8×8块大小,此时PEG01工作,其中簇内具体映射方案如上图4所示.4×4块的映射方案和8×8映射方案相同,4×4块大小每个PE计算一个像素,8×8块大小每个PE计算4个像素.
5 实验结果与分析
为了验证运动补偿算法可重构实现的可行性,本文基于动态可重构阵列结构进行验证.方法如下:通过修改测试模型HM10.0的配置文件,获取测试数据和块划分信息,存入片外存储,然后通过QuestaSim将可重构方案映射到动态可重构阵列结构上进行仿真验证.图6为不同阵列规模下处理不同块大小所需的时间,其中串行处理时间为单PE处理结果,相比于串行执行,并行处理缩短了约93%处理时间.在不同的阵列规模下,当执行4×4切换到8×8块大小时,执行4个4×4既可切换到8×8;当执行8×8切换到16×16块大小时,执行4个8×8块大小即可切换到16×16块;当执行16×16切换到32×32块大小时,执行4个16×16块大小即可切换到32×32块;同理,执行32×32块切换到64×64块大小时,执行4个32×32块大小即可切换到64×64.
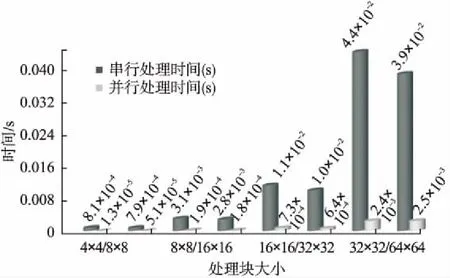
图6 不同块大小运动补偿算法计算时间统计Fig.6 Calculation of time statistics for different block sizemotion compensation algorithms
采用CMOS90nm工艺对可重构视频阵列处理器进行综合,再通过BEE4平台上的FPGA LX6V550T对设计进行综合,如表2所示为8×8编码块综合结果,从频率、资源占用率以及并行度分别进行比较.根据能同时处理像素的多少,可以得出16个PE规模的阵列结构并行度为16.文献[6]设计了可重构的滤波器,其频率远远低于本文,而且设计的像素处理并行度也是其2倍.文献[10]仅用于处理8×8编码块,虽然资源占用比本文低,但是工作频率远远低于本文,并行度也仅为本文的一半.文献[13]提出的高度并行的流水线设计,可同时处理32个像素,频率虽然略高,但是资源占用却是本文的2倍之多.文献[14]在频率和本文相当的情况下,硬件资源是本文设计的4倍还要多.文献[15]在频率上略高于本文,但是其硬件资源却差不多是本文设计的4倍.
表2 运算性能比较
Table 2 Comparison of computing performance
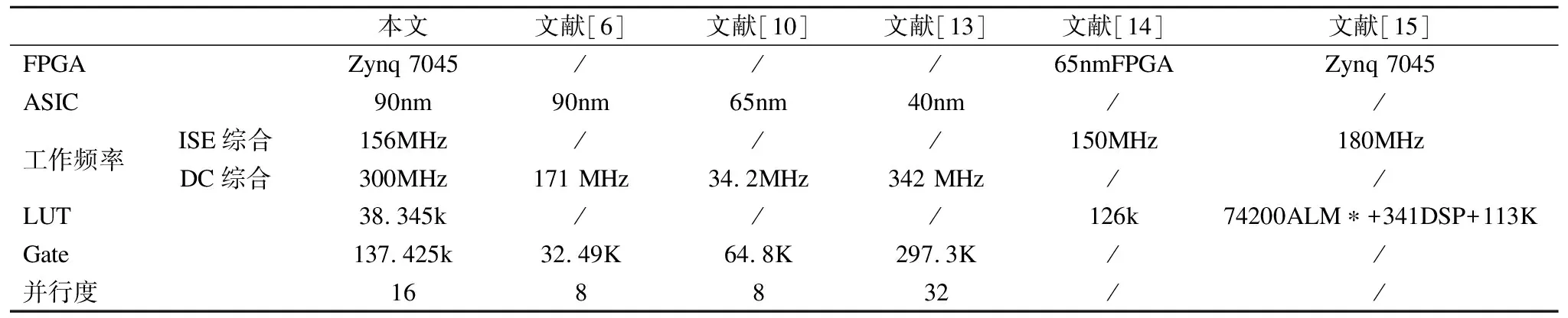
本文文献[6]文献[10]文献[13]文献[14]文献[15]FPGAZynq 7045///65nmFPGAZynq 7045ASIC90nm90nm65nm40nm//工作频率ISE综合156MHz///150MHz180MHzDC综合300MHz171 MHz34.2MHz342 MHz//LUT38.345k///126k74200ALM∗+341DSP+113KGate137.425k32.49K64.8K297.3K//并行度168832//
6 结束语
本文基于可重构视频阵列处理器结构,针对可变块的运动补偿算法,提出了一种新的高并行度的可重构方案.该方案能够通过动态调整视频阵列处理器规模,来实现不同块大小的运动补偿算法.该设计能够灵活的切换块大小并且最大限度地利用可重构阵列处理器.实验结果表明:所提出的可重构实现方式相比于串行单PE处理时间节省了约93%,该结构在具有较高的执行效率的同时也具有较好的灵活性.
