无监督分词算法在新词识别中的应用
2020-04-10姜涛,陆阳,2,张洁,洪建
姜 涛,陆 阳,2,张 洁,洪 建
1(合肥工业大学 计算机与信息学院,合肥 230601)2(安全关键工业测控技术教育部工程研究中心,合肥 2306013(安徽医科大学第一附属医院 信息中心,合肥 230022)
1 引 言
在中文自然语言处理领域中,对文本进行分词通常是第一步.由于中文中没有明显的界限符,所以在英文中不存在的分词问题在中文中却是很重要的一步.而歧义词和未登录词(out-of-vocabulary,简称OOV)是影响分词准确率的重要因素.Bakeoff 数据上的估算结果表明,未登录词造成的分词精度失落至少比歧义词大5倍[1].然而随着科技的迅猛发展,新的未登录词和未登录词的变体层出不穷,依靠人力去构建词库费时费力,因而使用某些方法让计算机自动从文本中挖掘出新词成为一项重要的课题.
目前主流的未登录词识别的方法是根据词的外部特征进行识别.Huang等在文献[2]中提出了一种基于互信息和邻接熵进行新词识别的方法,这种方法通用性强、使用简单,但容易产生大量的垃圾词串,需要人工进行标记.解决这个问题常用的方法是对语料进行预分词[3,4].使用有监督算法进行预分词准确率较高,但需要大量的标注语料,代价较大.使用通用的分词工具,由于领域的变化不可避免的带来训练语料中未曾出现的专有词汇,使得领域适应性较差,造成预分词性能的下降[5],最终影响新词识别的准确率.
针对上述问题,本文在新词识别算法[2]的基础上提出了一种改进算法.首先对语料进行无监督预分词,然后根据词频、互信息和邻接熵等词的特征对候选词组进行过滤,最终得到新词.在实验部分将本文提出方法和Huang等提出的baseline方法、使用ICTCLAS进行预分词的方法进行对比.实验表明在多领域的语料上进行新词识别,我们使用无监督预分词方法的准确率和领域适应性均超过ICTCLAS.
2 相关工作
目前新词识别主要有两类方法,一类是基于规则识别新词,另一类是基于统计识别新词.前者是通过语言构词学的原理,配合语义信息和词性信息来构造规则进行匹配.这种方法准确率高、针对性强,但基于规则仅仅适用于特定领域,并且维护十分困难.基于统计的方法是通过提取词的特征信息进行统计,再根据不同的特征进行新词识别.相比较基于规则的方法,基于统计更加灵活,在各领域都有较好的适用性.其中统计的方法又可以分为有监督的方法和无监督的方法.有监督的方法通常基于大规模语料,将新词识别问题转化成词的分类或者标注问题,利用最大熵模型、条件随机场等对标记进行解码,然后获取词边界,进而分词得到新词[6].有监督的方法准确率高,产生的垃圾串少,但需要对语料进行大批量的标注处理.无监督的方法主要是计算词的统计量特征,然后对候选词进行筛选,最后得到新词词表.常用的统计量有词频、词性、文档频率、互信息、邻接熵等.
陈飞等[7]基于条件随机场将新词识别问题转化为预测词边界的问题,并归纳了许多词边界的特征,在开放语料上取得了较好的效果.杜丽萍等[3]提出一种改进算法PMIk,在贴吧语料上获得了精确率和召回率的提升.李文坤等[8]提出了一种邻接熵扩展的方法,并在COAE2014提供的语料上取得了较好的效果.张华平等[9]将有监督和无监督的方法结合起来,使用基于条件随机场的字标注模型进行候选词提取,然后进行命名实体过滤,最后结合词的一些特征进行新词发现,其效果在开放领域预料上得到了验证.张婧等[10]在传统的词特征的基础上加入了词向量作为新的特征,并以此改进了一种无监督的新词识别方法.在当前高质量的标注语料的缺失的背景下,无监督方法相比较有监督方法,无需大规模标注语料的支持,能适用于各个领域,更具有实际意义.
3 主要技术
3.1 N-gram语言模型
统计语言模型(Statistical Language Model)是基于统计的方法来描述词、句子、文档等语法单元的概率模型,能够衡量出词、句子等是否符合人类日常语言表达.一般来说,语言模型的实质都是将句子的概率分解为各个单词的条件概率的乘积[11].
使用w1,w2,…wn来表示一个句子中的各个词,那么该句子S出现的概率如公式(1)中所示.
(1)
其中n表示句子中包含的词的数量,p(wi)表示第i个词wi出现的概率,p(wi|w1,w2,…,wi-1)表示在第1个词到第i-1个词出现的前提下,第i个词出现的概率.可见计算一个词wi出现的概率依赖于前面的i-1个词出现的概率,而计算所有的条件概率并不现实.数学家马尔可夫提出了著名的齐次马尔科夫假设,认为词wi出现的概率只与前一个词wi-1相关,并由此衍生出N元模型(N-gram Model)[12].
N元模型满足N-1阶的马尔可夫假设,即认为词wi出现的概率与前面的N-1个词相关,而与更前面的词无关,其具体描述如公式(2)所示:
p(wi|w1,…,wi-1)=p(wi|wi-N+1,…,wi-1)
(2)
本式中N的选取决定了模型的精度和复杂性,N值越大,对词语之间依赖关系的描述越准确,但同时计算复杂度也越高.
3.2 互信息
互信息(Mutual Information,简称MI)的概念最早出自信息论,粗略的来说是一种度量形式,用来表示词与词之间的联系.文献[13]中指出互信息是二元组p(w1,w2)的概率和两个单独词的概率乘积p(w1)p(w2)的似然对数比,如公式(3)所示:
(3)
其中p(x),p(y)表示字或者词x,y在语料中出现的概率,p(x,y)表示x,y在语料中共同出现的概率.互信息被引入到自然语言处理领域常被用于新词识别、消歧等,常常在新词识别领域也被称之为内部凝聚力,是用来衡量两个字或词的组合能否构成一个新词.MI越大表示x,y成词的概率越高,MI等于零的时候表示x,y是相互独立分布的,当MI小于零的时候表示x,y是互不相关分布的.
虽然互信息能够很好的表示词的内部凝聚度,并且计算也较为方便,但在文本量较小时词汇更接近多项式分布而不是正态分布[14],因而多数统计方法会过高地估计低频词之间的相关性.杜丽萍等[3]将K次互信息(PMIk)的方法用于新词识别领域.K次互信息的定义如公式(4)所示.
(4)
其中p(x),p(y)分别为字串x,y的概率,p(x,y)表示字串x和y组合在一起的联合概率.特别的,当k=1时即等同于传统的互信息的求法.并且当k越大时,准确率也越高,当k≥3时基本上可以克服互信息方法的缺点.
3.3 邻接熵
邻接熵可以用来寻找词的边界.它是衡量一个文本片段的左邻接字集合和右邻接字集合的随机程度,邻接熵值越大表示随机程度越高,即该字符片段成词可能性更高,邻接熵值越小表示随机程度越低,即该字符片段和邻接的词共同构成词语的可能性更高,而单独成词的可能性更低.通常计算邻接熵是通过计算其左右邻接字的信息熵得出的.
信息熵是信息论中的一个基本概念,是由香农在1948年提出的,用来解决信息的量化度量问题.其计算方式如公式(5)所示.
(5)
信息熵越大,其所携带的信息也就越大,随机变量的不确定性也就越高,熵值越小,其确定性越高,当熵为0时,则可以准确预测随机变量.对于一个词来说其存在左右邻接集合,通过计算该候选词组在语料库中的所有左右邻接字集合的信息熵,即可以得到左右邻接熵.具体计算如公式(6)所示.
(6)
其中w表示候选词,Hl(w),Hr(w)分别表示左右邻接熵,Sl,Sr表示该候选词在语料库中的所有左右邻接字集合.
4 新词识别的改进
4.1 算法概述
本文提出的方法首先使用四元模型进行预分词,而后进行命名实体识别对候选词进行过滤,再加入词频、互信息、邻接熵等特征并通过参数搜索寻找最优超参数进一步过滤候选词,其中互信息采用的是改进后的PMIk算法并取k=3计算3次互信息.具体算法步骤如下:
1) 语料预处理.
2) 进行命名实体识别,构建实体词表.
3) 使用四元模型结合实体词表进行无监督预分词,获得候选词表.
4) 统计词表中所有词的词频、3次互信息、邻接熵.
5) 随机选取部分样本点,进行参数搜索,得到最优的参数组合.
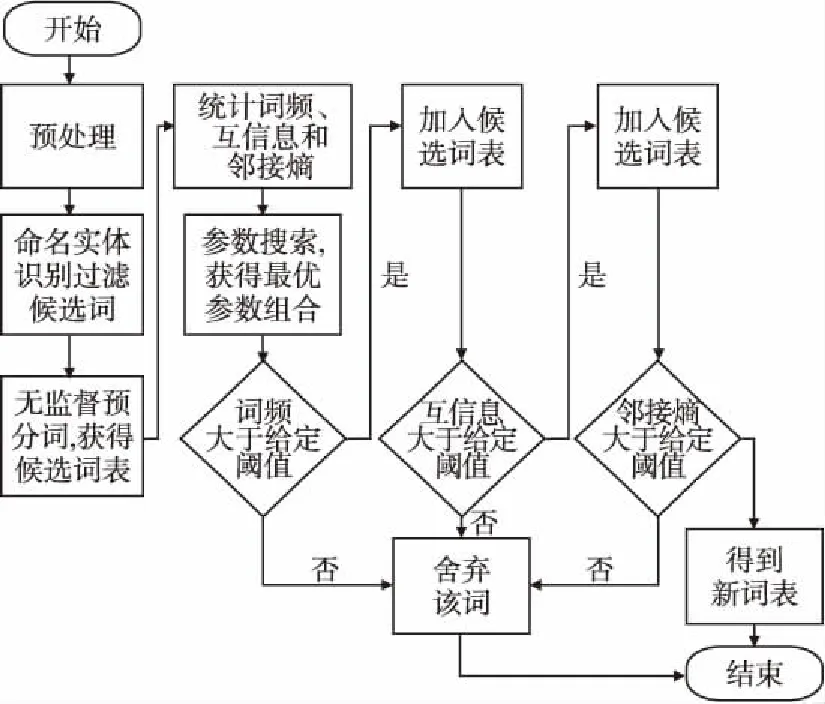
图1 算法流程图Fig.1 Algorithm flow chart
6) 根据词频阈值过滤掉词频较小的候选词.
7) 根据互信息阈值过滤掉互信息较低的候选词.
8) 根据邻接熵阈值过滤掉邻接熵值较低的候选词.
9) 最终得到新词词表.
算法流程如图1所示.
4.2 无监督预分词
基于N元模型的无监督中文分词,实际上是将分词问题转化为一种字粒度的标注问题[15].例如取4-gram时,使用四个标记符T1,T2,T3,T4分别表示某个词的第一个字、第二个字、第三个字和剩余部分,此时对于“自然语言处理”这个词即可以将其标记为[T1,T2,T3,T4,T4,T4].在这种对字进行标注的情况下,对于字ck来说,分别计算其为某个标记的概率,如公式(7)所示.
(7)
其中k表示当前时刻,ck-i(1≤i 语料中存在大量的人名、地名以及机构名等实体,识别出这些实体既可以减少新词识别过程中统计量的计算,也可以提高预分词的准确率. 目前主流的命名实体识别方法是使用Bi-LSTM结合条件随机场(CRF)进行识别,常见的词向量一般选取的是Word2vec、Glove等.谷歌提出预训练模型BERT,更容易提取深层次的语义关系,故而本文使用BERT结合Bi-LSTM和CRF的方法进行识别,构建实体词表.实验中使用开放的人民日报语料进行训练,并最终在测试集上对于人名(PER)和地名(LOC)和机构组织名(ORG)等实体的识别的F1值分别达到了96.48%、93.61%和88.76%. 在以互信息和邻接熵等作为主要特征的新词识别方法中,多处需要设定阈值,这些超参数的设定对最终结果影响较大,需要进行搜索以寻找最优的参数.其中超参数主要包含词频的阈值、互信息的阈值、邻接熵的阈值.本文中主要使用网格搜索方法进行参数调优.首先将所有候选词的词频、互信息和邻接熵计算出来并保存,然后根据各特征对评价指标的影响选取合适的区间,构成多维网格空间,进行搜索. 网格搜索法是指定参数值的一种穷举搜索方法,通过将估计函数的参数通过交叉验证的方法进行优化来得到最优的学习算法.但当参数较多,构成的维度空间十分庞大,使得模型训练时间过长.而对于本文的方法,各统计值是预先计算好的,并不用重复计算,只需指定参数范围,进行过滤验证即可,故使用网格搜索结果准确且速度较快,可适用于本文所提的方法. 语料分别是80M新浪微博语料、80M搜狗新闻语料、80M电子病历语料以及80M豆瓣多轮对话语料[16]. 新浪微博语料为2018年6月到9月期间产生的共计41W条微博,平均文本长度大约在90个字符. 搜狗新闻语料为2012年6月到7月期间国内、国际、体育、社会、娱乐等18个频道产生的新闻数据,取其中新闻的正文部分,共计22万条数据,平均文本长度约为210个字符. 电子病历语料为某医院生产环境下主诉和现病史构成的语料,其中主诉长度约为20个字符,现病史长度约为100个字符,共计70万份电子病历. 豆瓣多轮对话语料是公开的语料,语料已完全分词,平均文本长度约为81个字符,语料共计52万条对话记录. 精确率(Precision)是指识别出的新词中TP所占的比率,其计算方式如公式(8)所示. (8) 其中TP(True Positives)为所有正样本中被正确识别为正样本的数量,FP(False Positives)是指负样本被错误的识别为正样本的数量. 召回率(Recall)是指在所有的正样本样例中,被正确识别的正样本所占的比例,具体计算如公式(9)所示. (9) 其中TP(True Positives)为所有正样本中被正确识别为正样本的数量,FN(False Negatives)是指正样本被错误的识别为负样本的数量. F1值是精确率和召回率的加权平均,计算方式如公式(10)所示. (10) 其中P和R分别指的是精确率和召回率. 准确率(Accuracy)是指在测试的结果词语集合中,标注为正例的个数与标注集词语总个数的比值,如公式(11)所示. (11) 其中Tw表示词w被标注为正例的个数,Fw表示词w被标注为负例的个数. 实验中需要重点对阈值超参数进行搜索,其中包含词频阈值、互信息阈值、邻接熵阈值.首先分析各特征对评价指标的影响,如图2-图4所示.然后选取合适的区间和步长,构成多维的网格空间,进而进行搜索.其中搜索中的评价指标为F1值.本次实验中选取了频次范围为(5,20),互信息范围为(5.0,15.0),邻接熵范围为(1.0,3.0),共构成20000组参数进行实验,最终最优参数组合为:频次阈值为5,互信息阈值为5.6,邻接熵阈值为1.4,搜索速度为326组/秒. 图2 频次阈值对新词识别结果的影响Fig.2 Influence of frequency thresholdon new word recognition results 图3 互信息阈值对新词识别结果的影响Fig.3 Influence of mutual informationthreshold on new word recognition results 图4 邻接熵阈值对新词识别结果的影响Fig.4 Influence of branch entropythreshold on new word recognition results 首先在豆瓣语料上进行新词识别结果分析,然后对比不同的语料规模对结果的影响.最后在四个不同领域的语料上衡量不同方法的领域适应性.实验中我们分别将本文提出的方法和Huang提出的baseline方法、使用ICTCLAS进行预分词的方法在进行对比.首先在15万条豆瓣语料上的对比结果如表1所示. 表1 豆瓣语料上的新词识别结果 精确率/%召回率/%F1值/%Baseline22.264.433.1ICTCLAS+ Baseline63.543.151.3N-gram+ Baseline63.947.954.8NER+N-gram+Baseline62.851.356.4 Baseline:Huang等在文献[2]中提出的使用词频、互信息和邻接熵进行新词识别的方法. ICTCLAS+Baseline:基于ICTCLAS分词工具进行预分词后再使用Baseline的方法进行新词登录. N-gram+Baseline:使用无监督的方法进行预分词,然后在此基础上使用Baseline方法进行新词登录. NER+N-gram+Baseline:在上一组的基础上结合命名实体识别进行新词登录. 数据显示,Baseline的方法经过预分词后精确率和F1值均有非常大的提升.本文的方法比ICTCLAS进行预分词F1值提高3.5%.在此基础上,结合命名实体识别的方法F1值提高4.7%.说明了这种无监督的方法在新词登录过程中的可行性,同时也说明了本文所提的新词登录的方法是有效的. 此外,为了衡量语料规模对结果的影响,我们改变了语料的大小进行了对比实验,实验结果如图5所示.通过实验结果可以看出,语料规模从1万条到15万条F1值增长较为明显,15万条到30万条F1值趋于平稳. 图5 语料的规模对新词识别结果的影响Fig.5 Influence of different size of the corpus on new word recognition results 同时为了衡量本文的方法在多领域、大规模语料上的可行性,将本文方法和ICTCLAS预分词方法进行对比,测试语料为5.1节中所述的四个领域的语料,语料规模为80M文本,在同一组参数下(频次阈值为52、互信息阈值为3.1、邻接熵阈值为2.2),按照排序取前10%候选词的准确率(Accuracy)进行对比结果对比如表2所示. 表2 四个语料上的新词识别结果 微博语料搜狗新闻电子病历豆瓣对话ICTCLAS84.7%80.3%68.8%86.8%N-gram88.3%80.5%85.9%91.9% 对比结果可以发现在大规模语料上本文的方法准确率更高,尤其在电子病历这种专业领域的语料上差异更加明显,可见本文所提方法在领域适应性上更强. 最终识别到的新词包含了各领域的术语以及人名、地名等命名实体.表3中列举了本文方法在四个语料上识别的典型新词. 表3 新词示例 语料 新词举例微博语料吃鸡、齐刘海、伦家、万达广场、官博、给力搜狗新闻人民网、座谈会、总冠军、农产品、扶贫、新一代电子病历患者、治疗、就诊、咳嗽、淋巴结、恶心、诊断豆瓣对话上班族、眼线笔、实体店、非诚勿扰、摄影师 本文将一种无监督的预分词方法应用在新词识别中,在15万豆瓣语料上对比分词工具ICTCLAS预分词的方法,本文所提方法F1值更高.另外在多领域语料进行实验,可以看出这种方法具有较强的领域适应性.本文还结合了一些命名实体识别的方法使得命名实体可以被更好的识别.同时本文还将网格搜索的方法应用在新词识别中,寻找到最优的参数,获得一种最优的效果.这种无监督的新词识别方法,在无需很大的代价的情况下即可构建领域词库,我们只需要优化语言模型的质量即可,如需要考虑语义也可使用神经网络语言模型来进行处理,在实际应用方面具有较大的可行性.4.3 命名实体识别
4.4 参数搜索
5 实 验
5.1 实验数据
5.2 评价指标
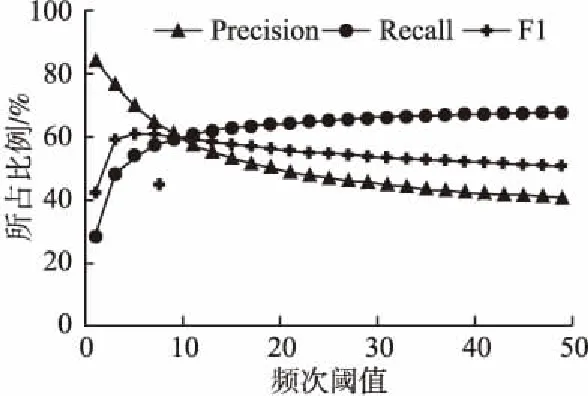
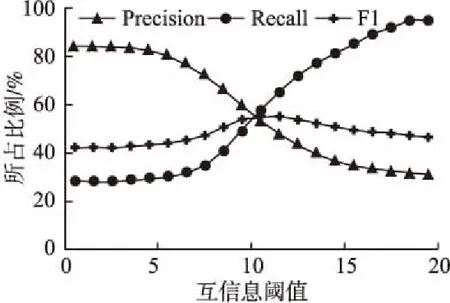
5.3 实验参数设置及调节

5.4 实验设计及结果分析
Table 1 New word recognition results on Doubancorpus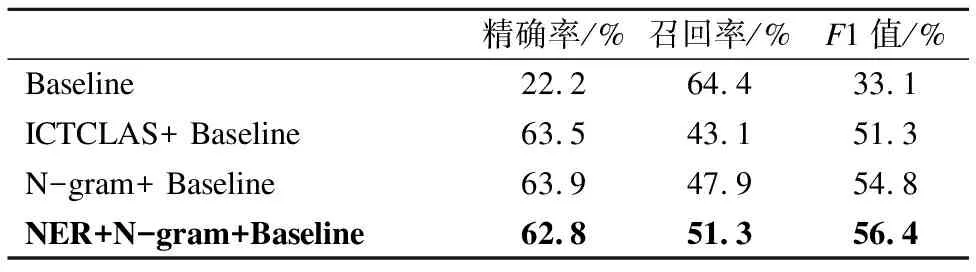
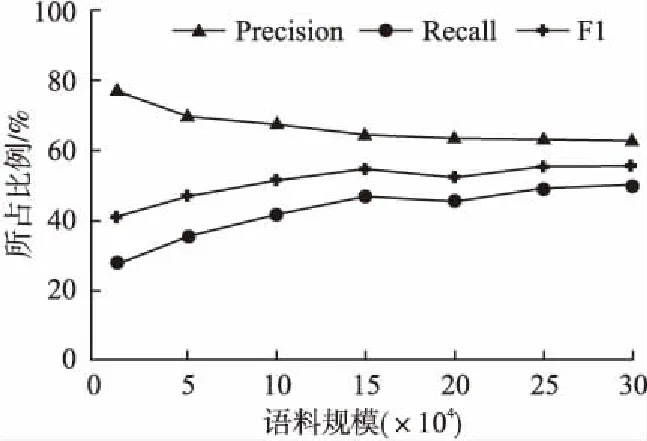
Table 2 New word recognition results on four corpora
5.5 新词识别结果
Table 3 New word examples
6 总 结
