无监督迁移学习红外行为识别
2020-04-10黑鸿中肖儿良简献忠
黑鸿中,肖儿良,简献忠
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
红外热成像对光照变化具有较强的鲁棒性,在光照条件较差的情况下,可见光视频中几乎看不到人,而红外视频可以很好的捕捉到人体,因此可用于24小时监控[1].此外,红外热成像可以很好的抑制阴影、背景杂波和遮挡等比人体或者运动物体温度低的干扰.由于这些特性,红外行为识别可以应用到可见光行为识别难以胜任的一些应用场景,并必将成为未来计算机视觉研究的一个热点.然而现在利用深度学习和机器学习对红外行为识别的研究,需要大量的红外动作数据集支撑,目前可供研究的红外数据集有限,造成红外行为识别的识别率较低[2],迫切需要开发大量的红外数据集,据了解目前需要通过人工繁琐标注大量的数据构建红外行为识别数据集;在大数据的当下,每天都有上万数据产生,人工标注红外视频是一项费时费力的工作,而且速度得不到保证.相比于红外行为识别,基于可见光的行为识别已经有很多公开的数据集,例如KTH[3],HMD51[4],和UCF101[5]等,但是由于可见光和红外视频来源于不同的传感器,数据存在于不同的特征空间中,二者之间既有关联,也有很大的模态差异.差异性决定了现有的可见光行为识别模型不能直接用于红外行为识别,但如果重新开发与可见光数据集具有相同动作的红外数据集就会造成可见光数据资源的浪费,而且增加大量繁琐的数据集建造工作.而二者之间具有的关联性,是否可以将现有的可见光数据集应用到红外行为识别中来,还没有引起足够的重视.本文对此工作进行了探索.
利用可见光动作识别红外动作要缩小二者之间的模态差异,因此本文基于迁移学习的思想,从已标注的源域(可见光数据)中学习到大量领域知识,迁移到目标域(红外数据)中,缩小可见光和红外之间的模态差异,完成目标域红外动作的识别.目前迁移学习主要集中在半监督域适应[6,7],需要加入带标签的目标域训练,或者要求源域和目标域具有相同的数据结构[8,12],而现实中可能没有足够多的带标签的红外数据可供训练,同时可见光行为动作和红外动作是异构的,二者之间有很大的模态差异.针对这些问题,本文提出一种用可见光动作(源域)来识别红外动作(目标域)的无监督异构行为识别算法(UHDIAR),为了将原始目标域和源域引入到同一个特征空间中,迁移更多的知识,本文使用了两个不同的投影,分别将源域和目标域投影到同一个对齐的特征空间中,通过这种方式减少了两个数据集之间的模态差异,同时利用源域和目标域数据的余弦相似度,引入权重支持向量机(W-SVM)重新加权源域样本,增加源域中和目标域相似度高的样本权重,降低异常值的样本权重,这样可以减少负迁移,提高识别率.
2 相关工作
目前有许多迁移学习算法被提出,根据在特征迁移过程中目标域加标签的情况,特征迁移的文献大致可分为三类适应问题:监督学习、半监督学习和无监督学习[22].监督学习又称主动学习,指源域和目标域都被大量标记,例如常用的监督方法流形对齐,通常使用拉普拉斯矩阵,其目的是在保持每个输入域拓扑的同时并发地匹配相应的实例[10,11],但是实际情况没有大量的有标签源域和目标域数据供训练.半监督域学习使用较少的目标域标签,减少了对有标签目标域数据的依赖,文献[12]提出一种新的传输弗雷德霍姆多核学习(TFMKL)算法来抑制复杂数据中分布的噪声.在图像迁移学习获得了较好的效果,但算法需要标记少量的目标域样本进行训练,且需要源域和目标域有相同的数据结构.无监督域自适应不需要标记目标域进行训练,例如文献[9]提出学习多个转换,每个域对应一个转换(TIT),以便将数据映射到共享的潜在空间,在这个潜在空间中,域可以很好地对齐,算法将特征向量抽象为图的顶点,只采用一种模拟的快速整数算法,而不采用已有的浮点算法进行矩阵运算.通过对图像分类、文本分类和文本到图像识别等多个标准基准和大规模数据集的广泛评价,验证了该方法的优越性.然而,TIT方法还没有应用到跨领域的红外人体动作识别中.因此,本文研究了源域和目标域独立转移的有效性,将其应用于挑战性更大的可见光到红外的视频动作识别中,以获得跨数据集的对齐特征表示.本文工作的主要重点是利用TIT在可见光到红外的行为识别中进行特征对齐,这在相关文献及文献[9]中均没有涉及.
近年来,一些迁移学习方法应用到行为识别当中,例如,文献[13]提出同时从不同视角拍摄的视频对中学习一对可转移字典,目的是使每个视频对具有相同的稀疏表示.利用稀疏表示作为特征,在源视图中构建的分类器可以直接传输到目标视图.文献[14]提出异构转移判别分析的典型相关法(HTDCC)来发现一个有区别的公共空间,在这个空间中源视角和目标视角相互连接,领域知识可以在二者之间相互传递.通过同时最小化样本的类间正则相关和最大化类内正则相关,优化了将源视图和目标视图数据映射到公共空间的两个投影矩阵.不同的源视图有不同的联合权重分配,每个权重表示对应的源视图对目标视图的贡献程度.文献[15]针对跨视图动作有不同维度的特征,引入一个判别公共特征空间来连接源视图和目标视图.学习了两种不同的投影矩阵,将来自两个不同视角的动作数据映射到具有低类内多样性和高类间方差的公共空间中,减少了它们之间的不匹配,分别将来自两个不同视图的动作数据映射到公共空间.文献[23]提出跨视点人体动作识别算法,通过捕获多视点的共同知识实现了对不同视点的人体动作识别.将特定的视图作为目标域,其余视图作为源域,从而将跨视图的动作识别组织到跨域的学习框架中.算法学习了两个变换矩阵,将不同视图的原始动作特征转化为一个共同的特征空间,并将原始特征与变换特征相结合,分别为目标域和源域学习不同的特征映射函数.文献[24]为了解决观察同一行为动作会因视角的不同而发生很大变化的问题,提出一种基于动作时间结构模型的层次转移的深度学习算法,将不同视图的原始特征空间转换为视图共享的低维特征空间,并在该空间中共同学习这些视图的字典.可以在无监督和有监督的跨视图场景中运行.文献[16]针对正则相关分析(CCA)在特征提取中没有考虑结构和跨视图信息的问题,引入了一种称为正则稀疏交叉视图相关分析(CSCCA)的方法来解决多视图特征提取问题,通过类内样本之间执行稀疏表示来构造相似矩阵,将局部流形信息和跨视图关联引入CCA,在包括多个特征的人脸数据集上得到较好的效果.文献[17]提出利用内核流行对齐(KEMA)和对准广义编码器(AGE)的方法将可见光数据作为辅助数据来提高红外行为识别的识别率,取得了较好的效果,但是其方法是半监督的,可见光数据只是作为辅助数据,且需要大量的目标域红外数据来训练.据了解目前还没有人实现挑战性更大的直接利用可见光(源域)视频动作来识别红外(目标域)视频动作的跨数据集无监督行为识别.基于以上研究本文提出了一种新的无监督异构行为识别方法(UHDIAR),利用可见光动作(源域)来识别红外动作(目标域),不需要标记目标域进行训练.
3 提出的方法
本文提出的无监督异构红外行为识别算法(UHDIAR)如图1所示,算法包括三个阶段.在第一阶段,对源数据集和目标数据集进行特征提取和编码,在此阶段中,用改进密集轨迹(IDTs)[18]对可见光视频和红外视频进行特征提取,提取的特征作为视频的底层特征表示,采用LLC[19]将IDTs提取出的特征进行编码,编码后的特征经PCA[25]简化为低维子空间.在第二阶段,将编码后的低维特征映射到再生核希尔伯特空间(RKHS),在RKHS中学习两个投影,分别将源域和目标域投影到一个公共的对齐子空间中.最后,在源数据集和目标数据集提取的对齐特征的基础上,利用经过余弦相似度调整权重的有标签源域数据训练支持向量机W-SVM,进而输出目标域的标签.
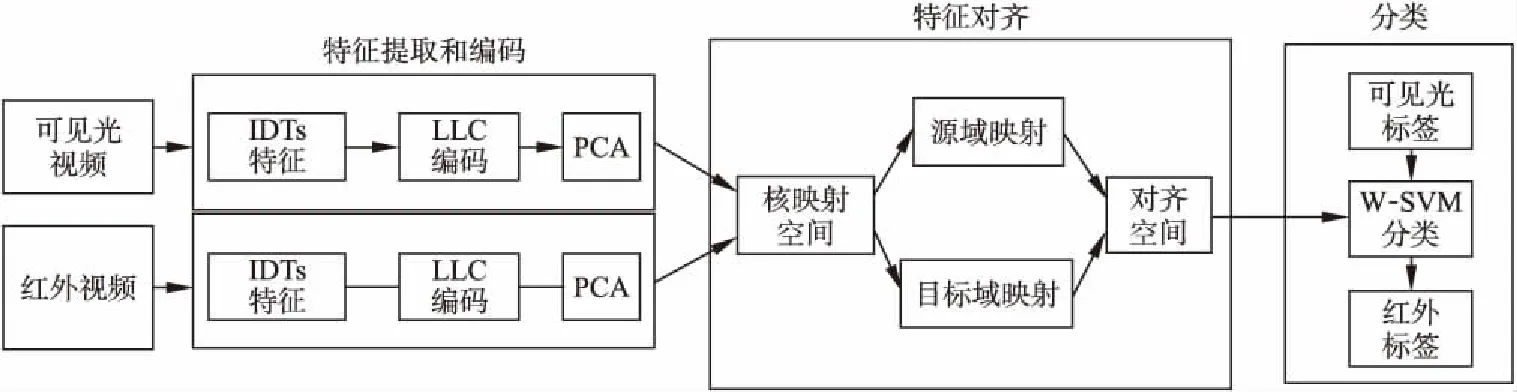
图1 无监督异构红外行为识别框架(UHDIAR)Fig.1 Unsupervised heterogeneous infrared action recognition framework(UHDIAR)
3.1 特征表示
3.1.1 特征提取和编码
改进稠密轨迹IDTs[18]由于其对视频特征的提取更加有针对性,消除了由于相机抖动造成识别率下降的影响,因此本文选用IDTs对视频中的人体进行稠密采样得到运动轨迹点,参数选用默认设置.IDTs通过SURF特征和光流计算当前帧与上一帧的投影变换矩阵得到运动轨迹,提取的轨迹带有方向性;然后对轨迹点提取特征,提取的特征信息包括光流方向直方图HOF、轨迹点的方向梯度直方图HOG以及运动边界直方图MBH.
对于IDTs,因为其对人体运动轨迹的密集采样而得到大量的局部轨迹描述符,所以采样得到的兴趣点数目较大,这样会导致较高的计算复杂度和内存消耗.为了解决这一问题,本文采用基于位置约束的线性编码(LLC,Locality-constrained Linear Coding)[19]方案,LLC利用位置约束将每个局部描述符投射到其局部坐标系中,并通过最大池求得最终的投影坐标.为了加快逼近速度,首先进行k邻近搜索,然后求解一个约束最小二乘拟合问题.LLC用多个基来表示IDTs,在保持局部光滑稀疏性的同时,可以带来更少的量化误差.在兼顾效率和构造误差的前提下,将LLC编码方案应用于具有5个局部基的IDTs,并将所有训练测试的码本大小设置为4000.因此,编码的IDTs特征的维数为4000.为了降低码本构建的复杂度,在每个视频序列中随机选取200个局部IDTs.
3.1.2 主成分分析(PCA)
在LLC编码后,特征表示仍然是高维的、有些冗余的特征.为了获得更紧凑的特征表示,本文利用常用的线性降维方法主成分分析(PCA,principal component analysis)[25]对这些高维特征进行预处理.PCA通过最大化样本方差,保证新的特征维度互不相关,先通过消除特征之间的相关性,然后调整缩放因子使新特征具有相同的方差,可以保留超过99%的原特征表达的特征,但是特征维数可以从4000降到不超过600维.
3.2 特征对齐
由于可见光动作视频和红外动作视频采集于不同的传感器,所以可见光视频和红外视频之间有很大的模态差异,造成二者之间有不同的数据结构,这就需要进行数据对齐,本文学习了两个不同的映射As和At,利用最大平均差异MMD[20]来计算二者之间的分布距离,ns和nt是源域和目标域中的样本数,Xs和Xt分别表示源域和目标域的数据.为了简化计算,将原始数据矩阵和两个投影矩阵合并为同成一个矩阵(1),但对于局部的数据和映射任然具有独立性.
(1)
其中ds和dt分别是源域和目标域的原始维数.这样源域和目标域的MMD可以通过式(2)计算得到.

(2)
矩阵M可以通过式(3)计算:
(3)
为了将源域和目标域的数据对齐,本文引入了再生核希尔伯特空间RKHS,将数据映射到RKHS中进行对齐.由
x→ψ(x),ψ(X)=[ψ(x1),ψ(x2),…,ψ(x3)],令核空间K=ψ(X)Tψ(X),A=ψ(X)P,可以将式(2)变化为式(4).
MMD(Xs,Xt)H=tr(PTXMXTP)
(4)
3.3 W-SVM样本权重调整
在跨域迁移学习的过程中,源域和目标域有很大的模态差异,而且并不是每个源域样本对目标域的作用是相同的,基于以上考虑,本文引入了样本权重,通过判断源域样本和目标域样本的相似度来改变源域的样本权重,增加主样本的权重,降低异常值样本的权重,来减少负迁移.对此引入k邻近,源域样本和目标域样本k邻近则具有相同的标签,同一类样本的距离较近,不同类样本远离.在式(5)中用Zj表示对齐后特征空间,Xj表示新特征.为了保持结构的一致性,将式(5)最小化.
(5)
其中Z=PTK,L=D-W,L为拉普拉斯矩阵,D是一个对角矩阵,它的第i个对角元素计算为W的第i行和,W为表征样本关系的对称邻接矩阵,通过余弦相似度式(6)得到.
(6)
Nk(xi)是Xi的k近邻,它们与Xi同属一类。对于W的第i行和第j列,如果样本Xj是Xi的k近邻,且与Xi具有相同的标签,则将Wji设为两个样本之间的余弦距离,否则将Wji设为0,这样就可以保证具有相同的类接近,不同类远离.
本文学习TIT将特征向量抽象为图顶点式(7),v为顶点的度数.
(7)
这样就可以通过式(7)得到的顶点度数更新源域样本权重α式(8),源域经过训练W-SVM得到模型,然后使用这个模型分类目标域.
(8)
最后,对式(9)的分解优化P映射,其中参数λ、β和γ均大于0.
(9)
其中矩阵G通过式(10)计算得到,Pi为P矩阵的第I行.
(10)
3.4 算法流程
a)输入可见光和红外视频,计算IDTs特征,使用LLC编码,PCA降维,得到底层特征表示.
b)设定迭代次数T,λ、β和γ,领域数k和子空间维数.
c)计算核函数K,初始化矩阵G,构造拉普拉斯矩阵L.
d)利用式(4)构造M矩阵.
e)分解式(9)计算映射矩阵Ps和Pt.
f)将RKHS中的源域和目标域使用不同的映射Ps和Pt投影到对齐的特征空间中.
g)权重SVM引入可见光标签对红外数据分类,输出红外动作标签.
h)余弦相似度式(6)利用输出的红外标签判定可见光样本的权重α.
i)判定迭代次数T是否达到最大值,没有达到最大值则返回d步开始执行下一次迭代,达到最大值则输出红外标签.
4 实验结果与分析
4.1 实验采用的数据集
无监督异构红外行为识别UHDIAR使用XD145数据集和InfAR数据集进行实验,其中XD145数据集作为源域,InfAR数据集作为目标域.
1)InfAR
InfAR数据集[21]有600个由红外热成像摄像机拍摄的人体动作视频组成.数据集中包含了fight、handclapping、handshake、hug、jog、jump、punch、push、skip、walk、wave 1(单手挥)和wave 2(双手挥)12类动作,所有的动作都由40名志愿者完成.其中每个动作类包括50个视频,每个视频平均持续4秒.帧速率为25帧/s,分辨率为293×256.视频的拍摄场景贴合实际情况,包括单人和多人的动作,体现出了背景的复杂度、季节差异、行为的类间差异、有无遮挡、以及视角的变化等,数据总体的挑战性很大.
2)XD145
XD145[17]数据集和InfAR数据集具有12种相同的动作类别.XD145动作数据集由可见光摄像机拍摄的600个视频组成,每个动作类有50个视频.所有的动作都由30名志愿者完成.每个视频平均持续5秒.视频帧速率为25帧/s,分辨率为320×240.如图2所示,在构建数据集时考虑了背景、姿态和视角的变化.图2为可见光和红外动作的比较,每一个动作左边为红外动作,右边为可见光动作.从图中可以看出,这些动作视频是在两种不同的光谱下拍摄的,表现出明显的类内方差和模态差异,而且相比于可见光数据集,红外数据集的背景、遮挡等更复杂.

图2 可见光和红外动作的比较Fig.2 Comparison of visible and infrared action
4.2 实验设置
4.2.1 参数设置
在源域和目标域每类样本数均为50的情况下,图3给出了UHDIAR的参数设置.图3(a)~图3(e)分别表示为邻域数k、γ、β、λ和子空间维数,Accuracy表示12种动作的平均识别率.从图中可以看出它们分别取4、0.002、0.01、0.11和120时,12类动作的平均识别率取得最高28.67%.可以看出相比于其它参数的取值变化β的值最敏感,取值变化0.01,准确率就会发生很大变化,因为β决定源域样本的权重,这也反映了调整源域样本权重的重要性.
4.2.2 源域样本数对准确率影响分析
将可见光动作作为训练集源域,红外动作作为训练集目标域,源域每种动作的样本数量随机选择为[5,10,15,20,25,30,40,45,50],目标域每种动作的样本数量选择为50,将UHDIAR与标准的SVM比较,SVM采用效率较好的线性核.图4为源域样本数对准确率的影响,从图中可以看到源域样本数越多UHDIAR的总体识别率越高,可以利用XD145数据集的全部数据,说明UHDIAR可以很好的利用带标签的源域样本,这也符合当前带标签的可见光动作数据比带标签的红外数据多的现实.带标签的源域样本数量增加对标准SVM的准确率几乎没有影响,这也反映了UHDIAR 的有效性.
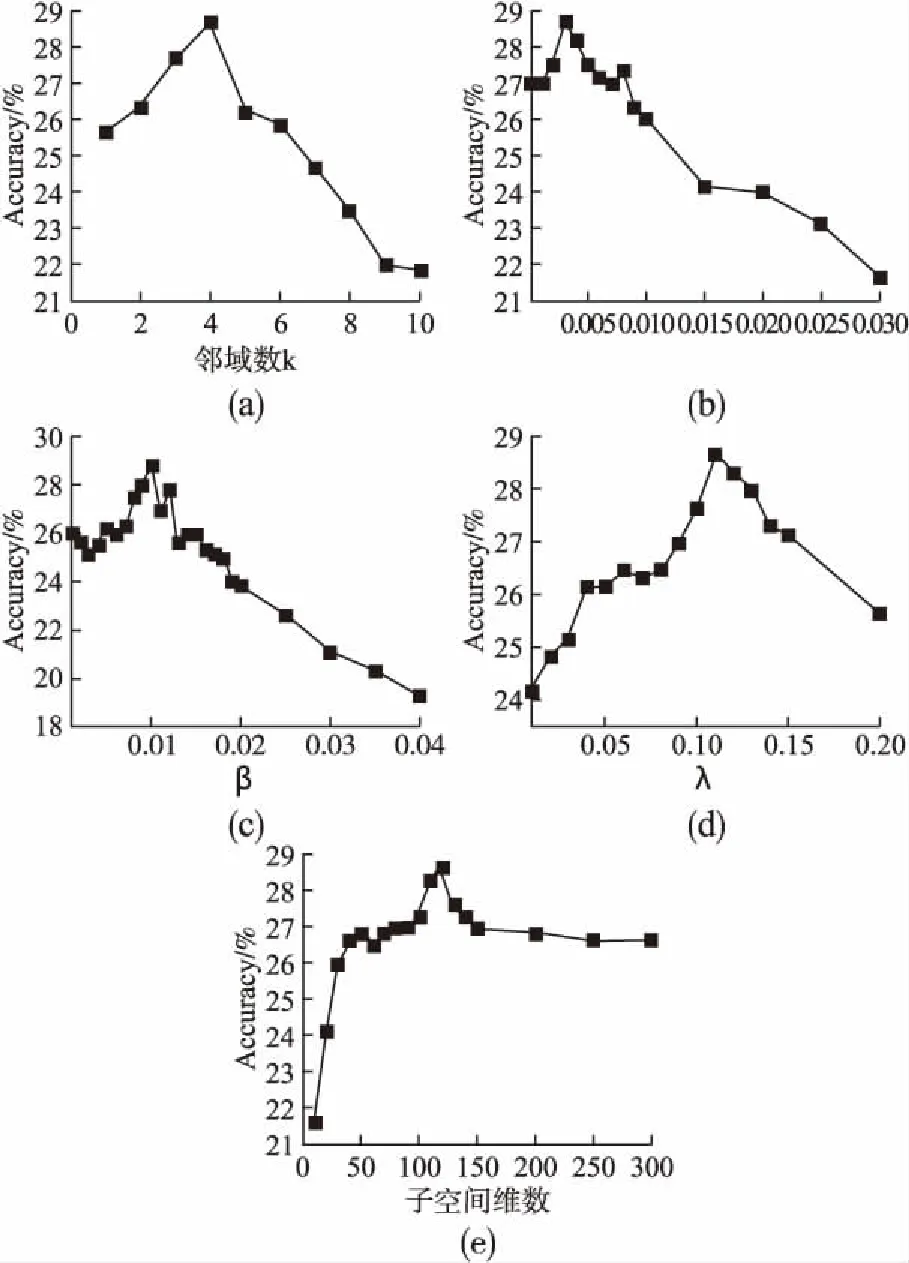
图3 a-e为UHDIAR优化参数设置Fig.3 a-e optimizes parameter settings for UHDIAR
4.2.3 UHDIAR与 CDFAG的比较分析
Liu等最近提出CDFAG[17]算法用于红外行为识别,将可见光动作作为辅助源域的同时加入了红外动作数据,其算法为半监督的,为了公平对比,本文也引入少量带标签的红外数据同CDFAG比较,其结果如表1所示.从表中可以看出,加入的红外训练个数不超过3个时UHDIR的识别率相比CDFAG有明显的提高.在红外训练个数超过3个后,UHDIR相比CDFAG精度有一定的下降,主要因为CDFAG特征对齐和泛化的过程中也加入了红外数据进行训练,为有目的的对齐和泛化,而UHDIR为无监督迁移,在特征对齐中并没有加入红外数据进行训练,红外数据只是用来训练SVM.在红外动作数据稀缺的当下,基本没有可以使用的带标签的红外数据,而UHDIR可以直接用可见光动作识别红外动作,CDFAG算法只有存在标记好的红外数据时才可以使用.
表1 CDFAG和UHDIR加入红外训练个数最高识别率对比
Table 1 Comparison of the highest recognition rate of
CDFAG and UHDIR added to infrared training

准确率(%)个数01234CDFAG—21.5928.8437.2545.16UHDIR28.6733.1636.6740.6042.97
4.2.4 实验结果分析
表2为SVM和UHDIAR的平均识别率,SVM平均识别率为17.00%,而UHDIAR的平均识别率为28.67,比SVM相对提高了68.65%,达到了较好的效果.图5(a)和图5(b)分别为标准SVM和UHDIAR的混淆矩阵结果,主对角线为每种动作的识别率.为了有更直观的区别,图6利用每种动作的识别率做成柱状图,从图6可以看到,除了wave2(双手挥)SVM识别率为56%,而UHDIAR的识别率为34%,比SVM低;其它11种动作UHDIAR的识别率均比SVM高,说明UHDIAR几乎对所有的动作都有效.从图2的wave2动作可以看出相比于其它动作双手挥的动作更容易辨识,提取的有效特征更有针对性,所以SVM直接用可见光数据识别红外数据可以得到较好的效果,相反如果进行迁移学习,由于数据对齐的过程中,会丢失一部分有效特征而造成识别率低,但其它动作提取的有效特征有限,对齐的过程中丢失的有效特征较少.
表2 SVM和UHDIAR的平均识别率
Table 2 Average recognition rate of SVM and UHDIAR

方法准确率(%)SVM17.00UHDIAR28.67

图5 SVM和UHDIAR的混淆矩阵Fig.5 Confusion matrices of SVM and UHDIAR
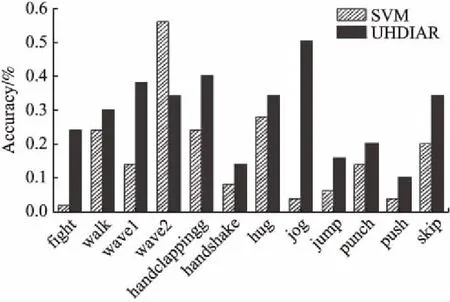
图6 SVM和UHDIAR的每种动作识别率对比Fig.6 Comparison of each action recognition ratebetween SVM and UHDIAR
5 结 论
本文首次提出基于迁移学习的无监督异构红外行为识别算法,利用带标签的可见光动作数据识别不带标签的红外动作.通过引入W-SVM增加源域有效样本的权重,降低异常样本权重,缓解负迁移,实验结果表明UHDIAR的平均识别率与标准的SVM相比相对提高68.65%,缩小了可见光和红外的模态差异,识别率有了明显的提高,证明可见光动作样本权重对红外行为识别的有效性.算法不需要标记目标域进行训练,提高了源域样本的利用率,可以有效的利用现有的可见光数据集,为利用可见光辅助红外行为识别提供了一种新的思路.本文虽然在缩小可见光和红外的模态差异取得了较好的效果,但由于可见光和红外的模态存在差异,目前提出的UHDIAR算法识别率有待进一步提高.课题组下一步工作考虑多源域迁移学习,构成图片和视频的多源域减少模态差异进一步提高识别率.
