深度学习技术在工件自动检测中的应用
2020-04-10刘信君郑飂默王诗宇
刘信君,林 浒,郑飂默,王诗宇
1(中国科学院大学,北京 100049)2(中国科学院 沈阳计算技术研究所,沈阳 110168)3(沈阳高精数控智能技术股份有限公司,沈阳 110168)
1 引 言
工业机器人的使用不仅可以解决劳动力少、劳动力成本高等问题,又可以结合高新技术来建设智能化工厂[1].在自动化生产线上,很多情况下需要先将待操作物体的位置信息给到机器人,例如:机器人抓取工件、搬运、焊接等场景.然后,才能驱动机器人完成相应的工作.传统的方式大多是基于离线编程或示教的方法,这种方式虽然可以满足精度的要求,但是对于操作人员要求极为苛刻,而且方法的泛化性能极差.因此,利用工业相机捕捉场景图像,对图像中物体进行自动检测与定位,实现机器人对物体的进一步操作,具有很好的实际应用价值.
目前,有很多不同的边缘检测算法,有根据亮度、颜色、像素梯度或者其他手工设计的特征,来对边缘和非边缘进行分类的传统算法,还有现在比较流行的基于深度学习的端到端的神经网络[2,3].本文基于深度学习技术搭建的机器人视觉系统,通过边缘检测以及后续的图像算法对场景中工件进行识别与定位,实现六关节机器人对工件的抓取.本文第二部分对整个视觉系统的工作流程进行了简单的概述.第三部分分析了当前边缘检测算法和相机标定算法存在的缺陷,并进行了相应的优化,提出了可行的解决方案.第四部分通过实验验证了优化算法的有效性和可行性.
2 视觉系统工作流程
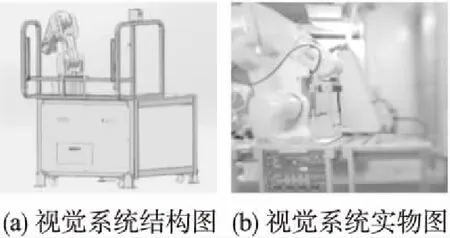
图1 视觉系统结构图Fig.1 Vision system structure
实验过程中,首先由相机采集待抓取物的图像信息并交由计算机,计算机通过图像算法对图像中待抓取物进行识别与定位.然后通过坐标转换算法,将得到的待抓取物体二维坐标信息转换成六关节机器人基坐标系下的三维坐标.机器人通过该坐标信息完成抓取.
3 视觉系统设计流程
3.1 工件边缘检测
边缘检测可以理解为从图像中提取视觉上显著的边缘和对象边界的方法.传统的方法通常是根据亮度、颜色、像素梯度或者其他手工设计的特征,采用Sobel算子、Canny算子等来对边缘和非边缘进行分类,虽然传统特征检测的方法在某些场景下具有不错的表现,但是局限性也很明显,一方面对噪声敏感、对人工设计的阈值等参数要求高,另一方面仅仅依靠强度、梯度、纹理这些低级特征会损失图片的空间信息等高级信息.近几年,在卷积神经网络的帮助下,边缘检测的研究取得了重大进展,基于卷积神经网络的边缘检测器已经在标准数据集的测试中超过了人工标注的度量结果.
3.1.1 RCF网络
RCF(Richer Convolutional Features)网络[2]是2017年由刘云等人在HED网络[3]的基础上改进的一个可以执行端到端的训练和预测的边缘检测器.网络结构如图2所示.
该网络以VGG16作为主干网络,保留了VGG16网络前5个阶段,省去了最后的全连接层以及第5个阶段的池化层.在每个阶段融合了每一个卷积层提取的特征,并采用反卷积,将每个阶段得到的特征图调整为原始图像大小.最后,融合这些特征图以获得最终的预测图.具体每一阶段执行结果以及最后融合的预测图,如图3所示.
3.1.2 RCF优化
这种设计可以充分利用CNN丰富的特征层次结构,会保留原图像中更多的细节信息.但是从图3中也可以看出,得到的预测图边缘比较粗糙,为了提高边缘检测器的定位能力,必须寻求细化边缘的方法.从网络结构方面分析RCF网络,边缘过粗主要存在以下两个原因.首先,由于连续的池化层,图像不断被下采样,在更具边缘判别能力的顶层中,特征的空间分辨率显著降低,导致边缘的模糊输出.另一方面,在每一阶段融合的时候采用反卷积的上采样方法不足以恢复空间细节,因此进一步模糊了边缘图.由于在每一阶段最后的池化层
马约翰先生在1948年接待校刊记者时说:“我觉得体育的功效,最重要是培养人格,补充教育的不足,培养一种‘干、干、干!’的精神”他认为体育是教育的重要组成部分,培养全面发展人才的手段,运动场是培养学生品格极好的场所,培养青年们勇敢的精神,坚强的意志,自信心,进取心和争取胜利的决心。
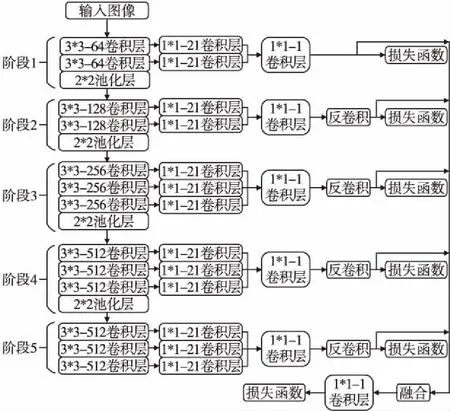
图2 RCF网络结构图Fig.2 RCF network structure
可以有效提高计算效率,因此本文不做考虑,主要从使用亚像素卷积[4]替换反卷积以及数据增强两个方面来对RCF网络进行优化.

图3 RCF结果图Fig.3 Result graph of RCF
1)亚像素卷积
亚像素卷积是一种在低分辨率图像上直接计算卷积得到高分辨率图像的高效率方法.相对而言,反卷积是使用单个滤波器,先将图像从低分辨率放大到高分辨率空间,然后在高分辨率空间进行操作,这就意味着增加了额外的计算复杂度.不同于反卷积,亚像素卷积是在低分辨率图像上直接计算,然后通过一个升序滤波器阵列将最终的低分辨率特征图提升到高分辨率空间.通过这种方式,可以有效地替换反卷积中的单滤波器,并且为每个特征图提供了更加复杂的升频滤波器,同时还降低了整体的计算复杂度.
在RCF中使用亚像素卷积代替反卷积可以消除反卷积引入的模糊,增加更精细的边界细节.同时,为每一阶段的输出增加了额外的非线性,降低了相邻像素之间的相关性.图4是对两种卷积方式同一阶段边缘特征图、同一区域放大之后的结果,从图4的对比中可以看出,使用亚像素卷积可以生成“正确”并且“清晰”的边缘图.

图4 卷积结果对比图Fig.4 Convolution result comparison
2)数据增强
本文使用BSDS500[5]和VOC Context[6]的增强数据集训练.BSDS500数据集是边缘检测中被广泛应用的数据集.它由训练集、验证集和测试集组成,其中,训练集包括200张图像、验证集包括100张图像、测试集包括200张图像.增强数据集由BSDS500数据集中200张训练图像、100张验证图像和VOC Context数据集混合,经过旋转、翻转、裁剪等操作生成,总共约36800张图像.
3.2 工件定位
定位工件抓取位置只需要定位到工件的中心即可.可是如果想要在图像中定位出工件的边缘与中心,仅仅依靠RCF网络预测出的边缘图像还远远不够,还需要对边缘图像提取最小外接轮廓,来得到工件的位置以及旋转角度.在这里,我们使用OpenCV3[7]中的已经封装好的方法来获取边缘图像的最小外接矩形,该方法会根据检测到的角点,返回矩形的中心、长宽以及旋转角度,这里的矩形中心就是我们需要的工件中心.如图5所示,得到的最小外接矩形可以很好地找到抓取所需的工件中心.

图5 外接矩形定位图Fig.5 External rectangle positioning
3.3 相机标定
得到了工件的二维图像坐标之后,需要考虑如何将二维坐标转换到机器人基坐标系下的三维坐标.相机标定的过程主要分为两步:首先建立相机成像模型,然后设计标定算法来对相机内、外参数进行标定.相机模型主要分为线性模型和非线性模型,针对非线性模型,传统的标定方法只考虑了径向畸变,忽略了切向畸变等其他非线性畸变,因此,在很大程度上制约了标定的精度.本文根据相机模型,针对相机参数不精确的问题,借助神经网络强大的非线性拟合能力,以相机成像模型为基本思想,提出了一个浅层的BP神经网络模型来完成相机的标定,实现了二维像素坐标到三维世界坐标的非线性映射.
3.3.1 相机模型
相机成像模型建立了三维物体和二维图像之间的对应关系,成像过程涉及了世界坐标系、相机坐标系、图像坐标系、像素坐标系之间的转换.下面首先以理想状态下的针孔相机模型为例,对涉及的四个坐标系进行定义.如图6所示,坐标系OwXwYwZw表示世界坐标系、坐标系OcXcYcZc表示相机坐标系、坐标系Oxy表示图像坐标系、坐标系Ouv表示像素坐标系,p(Xw,Yw,Zw)为世界坐标系中的一点,p(x,y)是点p在图像中对应的成像位置,在图像坐标系中坐标为(x,y),在像素坐标系中坐标为(u0,v0).
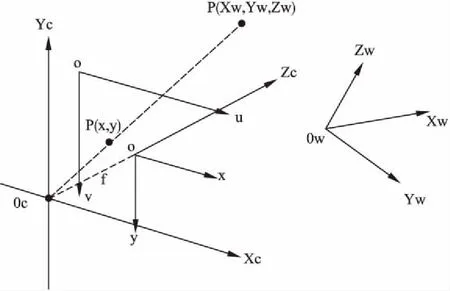
图6 坐标关系图Fig.6 Coordinate relationship
在成像过程中,首先是世界坐标系到相机坐标系的转化,因为两者均是空间的绝对坐标,因此该变换属于刚体变换,用[R|t]表示;然后是从相机坐标系到图像坐标系的转化,根据小孔成像原理可知,该变换属于透视投影变换,转化关系为公式(1),其中f为相机镜头的焦距.
进一步,从图像坐标系转化到像素坐标系,图像坐标系和像素坐标系都在成像平面上,图像坐标系的x轴和y轴分别于像素坐标系的u轴和v轴平行,两者转化关系为公式(2).综上所述,从世界坐标系到像素坐标系转化的数学模型如公式(3)所示.
(1)
(2)
(3)
上述的过程是在理想情况下的线性模型,实际环境中会因为透镜的形状和相机组装过程中透镜和成像平面不平行,带来非线性误差,一般分为径向畸变和切向畸变,用数学模型表示为:
Xcorrect=x(1+k1r2+k2r4+k3r6)+2p1xy+p2(r2+2x2)
Ycorrect=y(1+k1r2+k2r4+k3r6)+2p1(r2+2y2)+2p2xy
(4)
其中,r2=x2+y2,(x,y)是成像装置上畸变点的原始位置,(Xcorrect,Ycorrect)是畸变矫正之后的位置,k1、k2、k3是径向畸变系数,p1、p2是切向畸变系数.
上述相机模型可以简化为Q=H*P,但是在实际场景中需要的是机械臂基坐标下的三维信息,所以需要将二维坐标转化成三维坐标,本文假设待抓取物的Z轴垂直于地面,机械臂末端在平行于待抓取物X轴和Y轴所在的平面内定位待抓取物,因此可以根据P=H-1*Q通过像素坐标来得到待抓取物的三维信息.
3.3.2 BP神经网络
BP神经网络的基本结构包括:输出层,隐藏层和输出层,理论上只要隐藏层神经元足够多,就具有拟合任意复杂非线性映射的能力.对于相机标定,由于相机镜头存在多种非线性畸变,传统的标定方法需要建立复杂的数学模型,而神经网络在应对这些非线性畸变上具有极强的鲁棒性,因此本文根据相机成像模型提出了一种基于BP神经网络的相机标定方法,具体网络结构如图7所示.
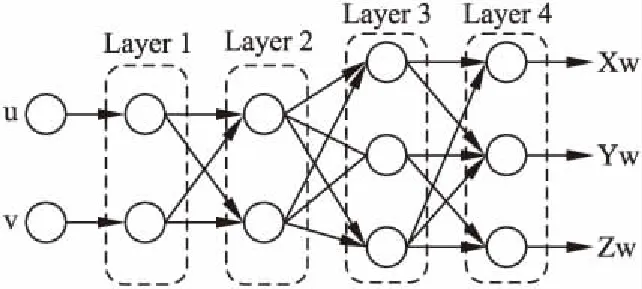
图7 相机标定网络结构Fig.7 Camera calibration network structure
整个网络使用Keras框架搭建,使用图8所示的6*9标准棋盘格采集的500组图像和机器人末端点对作为实验数据.激活函数采用tanh函数,来对每个节点进行非线性激活;学习率使用Keras提供的指数衰减法,这个方法先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的进行逐步降低学习率,使得模型在训练后期更加稳定;损失函数采用均方误差(MSE),定义如公式(5)所示:
(5)

图8 6*9棋盘格Fig.8 6*9 checkerboard
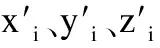
(6)
4 实验结果与分析
为了验证本文方法的可行性,本文进行两部分的实验,分别对优化的RCF网络和用于相机标定的BP神经网络进行评估.
4.1 RCF网络评估实验

表1 各算法在BSDS500上的边缘检测评估结果
Table 1 Edge detection evaluation results on BSDS500
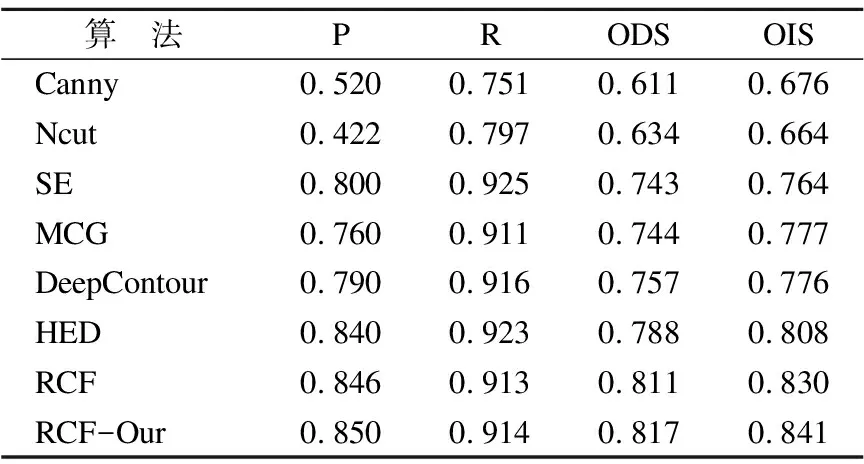
算 法PRODSOISCanny0.5200.7510.6110.676Ncut0.4220.7970.6340.664SE0.8000.9250.7430.764MCG0.7600.9110.7440.777DeepContour0.7900.9160.7570.776HED0.8400.9230.7880.808RCF0.8460.9130.8110.830RCF-Our0.8500.9140.8170.841
通过上述实验结果可以看出,本文提出的对RCF网络的优化策略在精确率和召回率方面均优于现在主流的边缘检测模型,ODS和OIS指标相较于经典的RCF网络分别提升了0.6%和1.1%,这也证明了使用亚像素卷积替换反卷积可以得到更精细、质量更高的边缘特征图,边缘特征图融合之后可以得到“清晰”和“准确”的边缘.
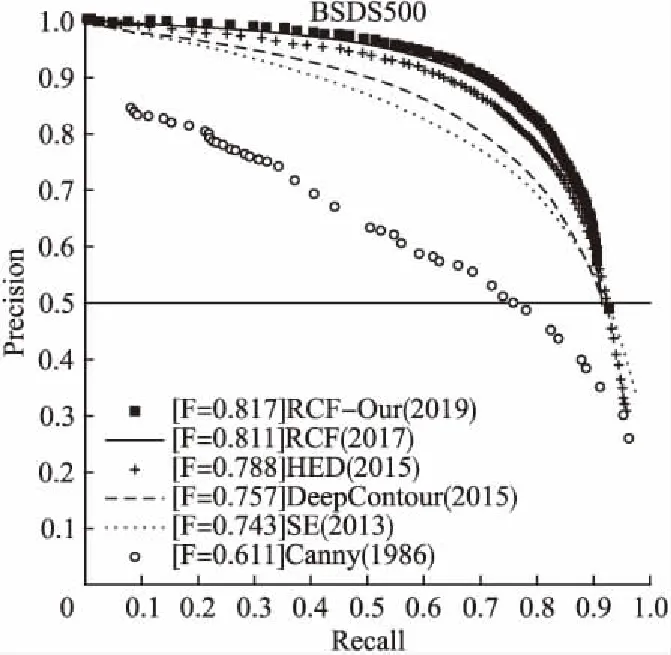
图9 各算法P-R曲线对比图Fig.9 P-R curve comparison chart
4.2 相机标定BP网络评估实验
本文在自己采集的数据集分割出来的测试集上进行网络测试实验,样本实际值与网络所得预测值样例如表2所示.
测试实验最终所得均方误差为0.431,也就是说误差在0.5mm之内,已经完全可以满足本视觉系统的实际应用.
表2 BP神经网络预测样例表
Table 2 Prediction examples of BP neural network
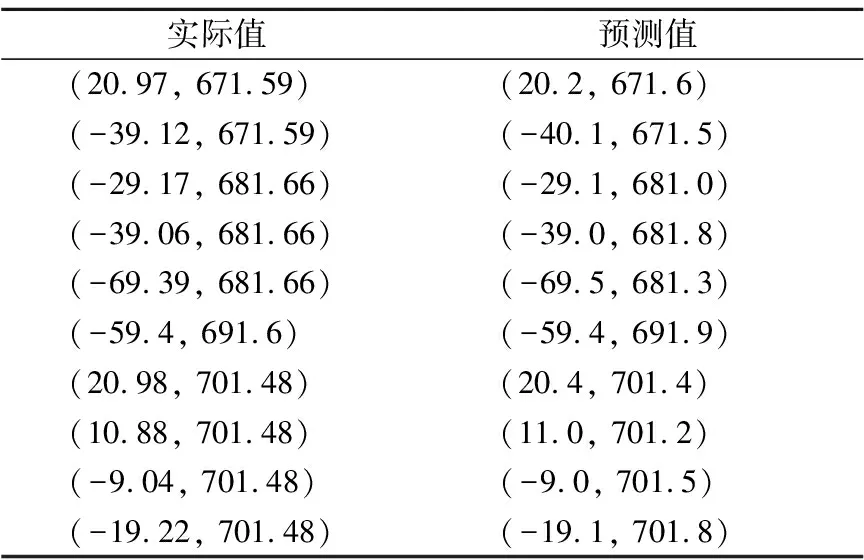
实际值预测值(20.97, 671.59)(20.2, 671.6)(-39.12, 671.59)(-40.1, 671.5)(-29.17, 681.66)(-29.1, 681.0)(-39.06, 681.66)(-39.0, 681.8)(-69.39, 681.66)(-69.5, 681.3)(-59.4, 691.6)(-59.4, 691.9)(20.98, 701.48)(20.4, 701.4)(10.88, 701.48)(11.0, 701.2)(-9.04, 701.48)(-9.0, 701.5)(-19.22, 701.48)(-19.1, 701.8)
5 结束语
本文以ABB IRB1200 六关节机器人和映美精 DFK33GP-006工业相机为基础搭建了机器人视觉系统.采用边缘检测和最小外接矩形的方式对工件进行定位,对执行端到端边缘检测的RCF网络通过亚像素卷积核和数据增强的方式对网络进行了优化,实验验证了在每一阶段可以产生精细、准确的边缘,并且在标准数据集上通过实验验证了算法的有效性.接下来分析了相机成像模型,并以此为基本思想,设计了基于BP神经网络的坐标映射方法,并通过实验验证了算法的可行性.综上所述,本视觉系统具有很好的实际应用价值.
