基于BiLSTM-Attention唇语识别的研究
2020-04-09刘大运房国志骆天依魏华杰王倩李修政李骜
刘大运 房国志 骆天依 魏华杰 王倩 李修政 李骜

摘 要:為了解决唇语识别中唇部特征提取和时序关系识别存在的问题,提出了一种双向长短时记忆网络(BiLSTM)和注意力机制(Attention Mechanism)相结合的深度学习模型。首先将唇部20个关键点得到的唇部不同位置的高度和宽度作为唇部的特征,使用BiLSTM对唇部特征序列进行时序编码,然后利用注意力机制来发掘不同时刻唇部时序特征对于整体唇语识别的不同权重,最后利用Softmax进行分类。在公开的唇语识别数据集GRID和MIRACL-VC上与传统的唇语识别模型进行实验对比。在GRID数据集上准确率至少提高了13.4%,在MIRACL-VC单词数据集上准确率至少提高了15.3%,短语数据集上准确率至少提高了9.2%。同时还与其他编码模型进行了实验对比,实验结果表明该模型能有效地提高唇语识别的准确率。
关键词:唇语识别;双向长短时记忆网络;注意力机制;深度学习;时序编码
中图分类号:TP391 文献标识码:A
Research on Lip-reading Based on BiLSTM-Attention
LIU Da-yun1,FANG Guo-zhi2?覮,LUO Tian-yi3,WEI Hua-jie1,Wang Qian1,Li Xiu-zheng1,Li Ao1
(1. School of Computer Science and Technology,Harbin University of Science
and Technology,Harbin,Heilongjiang 150080,China;
2. School of Measurement and Control Technology and Communication Engineering,
Harbin University of Science and Technology,Harbin,Heilongjiang 150080,China;
3. School of Automation,Harbin University of Science and Technology,Harbin,Heilongjiang 150080,China)
Abstract:In order to solve the existing problems in lip feature extraction and temporal relation recognition during the research of lip-reading,a deep learning model based on bi-directional long short-term memory(BiLSTM) and attention mechanism(Attention) is proposed. Firstly,the height and width of the different positions of the lip obtained from the 20 key points of the lip are taken as the characteristics of the lip. Secondly,the BiLSTM model is utilized to encode temporal information. Thirdly,the attention mechanism is used to explore different weights of lip sequential features at different times toward the overall lip language recognition. Finally,we use Softmax classifier to classify. Compared with the conventional lip-learning models at the current lip language recognition database GRID and MIRACL-VC,we find the recognition accuracy rate is more than 13.4% higher than that on GRID. In the MIRACL-VC word database,the accuracy rate increased by at least 15.3%,and the accuracy rate in the phrase database increased by at least 9.2%. At the same time,compared with other coding models,the experimental results show that this model can effectively improve the accuracy of lip-reading.
Key words:lip-reading;bi-directional long short-term memory;attention mechanism;deep learning;sequential coding
唇语识别集自然语言处理与机器视觉于一体,其研究的主要内容是从视频图像中识别出讲话人所说的内容。近年来,唇语作为人类表达信息的重要载体,唇语识别技术获得了广泛的关注,已经被广泛应用到案件侦破、安检、辅助语音识别等[1.2.3]领域。
同语音识别相比,唇语识别存在更多困难。不同说话人在不同时刻和不同环境下,即使说话内容完全相同,其唇动信息也存在巨大差异。视觉特征的提取对于唇语识别来说尤为关键,明显的特征应该具有类内一致性和类间差异性,一定程度上简化后续的识别过程以及提升识别准确率。Petajan等人[4]在1984年首先提出了唇语识别系统,将提取到的唇语特征序列与数据集中全部特征模板进行相似度检验,相似度最高的词作为预测输出。Goldschen等人[5]在Petajian的唇语识别系统之上结合了语音识别中的建模方法对唇部特征进行了建模分析。Lan[6]等人用主动外观模型的外表参数和形状参数作为特征,从唇语视频每帧图像的嘴唇区域提取特征。Song[7]考虑到隐马尔科夫模型(Hidden Markov Model,HMM)的双向随机过程和唇语序列识别过程的相似性,发现当HMM模型隐藏状态数为5时效果最佳。徐铭辉等人[8]将唇动序列的形状特征和图形特征做为唇部特征,最后使用半连续HMM模型实现了唇语识别。Zhao等人[9]提出了一种基于时空局部二值的特征表示方法,采用支持向量机(Support Vector Machine,SVM)对短语进行分类识别。Pei等人[10]通过对无监督随机森林流形对齐的研究,提出了新的节点分裂标准,以避免学习过程中森林等级不足。近期马宁等人[11]将Schmidhuber和Hochreiter[12]提出长短时记忆单元(Long Short-Term Memory,LSTM)应用到唇语识别中,解决了唇语信息多样性的问题。
上述模型虽然在唇语识别上取得了一定的效果,但是依旧存在一些问题。传统的特征提取方法,特别是主动形状模型,只是用了4个点来描述唇部特征,并没有抓住唇部的更多细节,因此使用唇部的20个关键点计算出唇部不同位置的高度和宽度。LSTM虽然解决了HMM存在的问题,但是在唇语识别中未来信息对当前信息也存在一定影响,LSTM并没有考虑这些,因此使用了双向长短时记忆网络(Bidirectional Long Short-Term Memory,BiLSTM),充分考虑到过去信息和未来信息对当前信息的影响。由于不同时刻的唇部时序特征对于识别的贡献程度不同,在BiLSTM层后加入注意力机制(Attention Mechanism)。
1 基于BiLSTM-Attention的唇语识别模
型
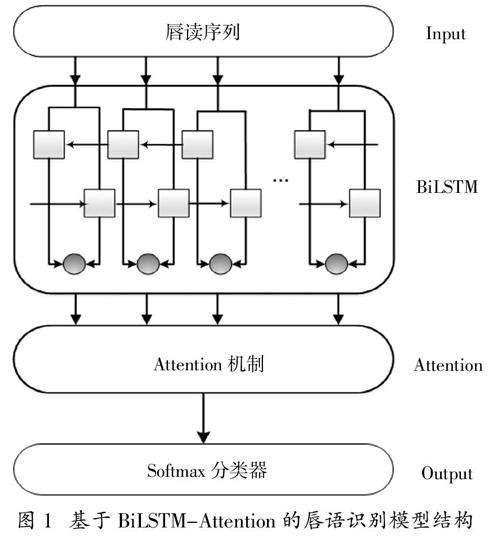
基于BiLSTM-Attention的唇语识别模型如图1所示。该模型主要由四个部分组成:
(1)利用改进的主动形状模型提取唇部特征;
(2)利用BiLSTM模型对唇部特征序列进行时序编码;
(3)引入Attention机制发掘不同时刻唇部时序特征的重要程度;
(4)利用分类器进行特征分类。
图 1 基于BiLSTM-Attention的唇语识别模型结构
1.1 输入层
传统的唇部特征提取方式是提取出唇部的4个关键点来模拟唇部的形状,然而其提取的关键点太少导致其不能很细腻地刻画出唇部的特征从而影响识别的准确率,因此在此基础之上我们做了改进。首先使用dlib库提取出唇部的20个关键点,然后根据这20个关键点计算出唇部不同位置的高度和宽度,将得到的高度和宽度作为唇部的特征。
通过对每一个视频的每一帧进行如上的处理,可以得到每一个视频的唇部特征序列S:
S = [w1,w2,…,wi,…,wn] (1)
其中n为特征序列的长度,wi代表第i帧的唇部特征。
然后将唇部特征序列S送入到BiLSTM中进行时序编码。
图2 唇部的20个关键点
1.2 BiLSTM
为了解决传统循环神经网络(RNN)梯度消失的问题,1997年Hochreiter和Schmidhuber等人[8]提出长短期记忆模型(Long Short-Term Memory,LSTM)。LSTM模型由一系列相同的时序模块单元连接而成,每个模块包括:遗忘门ft、输入门it、输出门ot和记忆单元Ct。LSTM中重要公式如下:
ft = σ[wf·(ht-1,xt) + bf ] (2)
it = σ[wi·(ht-1,xt) + bi ] (3)
■t = tanh(wc·[ht-1,xt + bc) (4)
■t = tanh(wc·[ht-1,xt + bc) (5)
ot = σ[wo·(ht-1,xt) + bo ] (6)
ht = ot* tanh(Ct) (7)
其中wf、wi、wo、wc為LSTM模型的权重矩阵,bf、bi 、bo 、bc 为LSTM模型的偏移量,ht为t时刻的隐藏状态。
LSTM已经广泛地运用在唇语识别领域,然而LSTM仅考虑到过去信息对当前信息的影响,在实际的唇语识别过程中,同样需要充分考虑未来信息对当前信息的影响。例如在唇读数据集中句子“Nice to meet you.”时,仅凭借单词“Nice”判断出下文单词“to”的准确率很低。只有同时兼顾“to”的上下文信息“Nice”和“meet”,才能全面捕获对唇语识别有价值的唇部特征序列,提高唇语识别准确率,因此采用BiLSTM对上下文信息进行处理更为恰当。
BiLSTM是将时序相反的两个LSTM网络连接到同一个输出,运用前向隐含层结点和后向隐含层结点,分别捕获上下文信息。两个隐含层的结果共同作用,输出最终结果。
图3 双向长短时记忆网络结构
BiLSTM通过引入第二层LSTM网络来扩展单向的网络结构,在应用到唇语识别时,两层LSTM网络在相反的时间顺序上连接相同的唇部特征序列输入。其中一层神经网络编码当前时刻和之前时刻的唇部特征信息,另一层神经网络则编码该时刻的下文信息,得到一组相反方向的隐含层结点信息。向前和向后的隐含层之间并不存在信息流,但它们都连接到同一个输出层,使得输出层输入序列的每个点都包含完整的过去和未来的上下文信息。这种相互独立的双向LSTM网络结构,保证了我们更加充分地利用唇动序列的特征信息对当前信息进行准确判断,识别的准确率相比于单向的LSTM网络显著提高。
本部分将改进的主动形状模型提取到的唇部特征序列利用BiLSTM进行时序编码,得到唇部的时序特征向量,送入到Attention机制。
1.3 Attention机制
人类在观察某一个物体时,往往着重于观察物体的某个特定区域,并适当忽略一些不重要的区域,以此来快速准确的获得当前目标的主要信息。赵富等[13]将这种Attention机制运用在文本情感分类中,更多地关注对情感分析有价值的部分,提高了情感分类的准确度;冯兴杰等[14]在研究句子相似度的过程中引入了Attention机制,将更多的精力集中在句子中的关键单词上,有效的提高了智能客服系统的辨识能力。
在唇语识别过程中,同样面临着唇读上下文不规则停顿、读音相似等原因造成的识别准确率低的问题。实验时,提取到的唇部特征序列对于唇语识别准确率的影响程度往往有所差异,一个单词的关键信息往往隐含在某一段连续帧中,因此有必要引入Attention机制将这些重要信息进行提取。
例如一个人在唇读“She sells sea shells on the seashore.”这句话时,不同单词在很多帧上有相同的唇型。这些相同的唇部特征往往不能良好的区分单词之间的差异,能够区分他们的特征信息集中在那些唇型不相同的帧上。因此将Attention机制引入其中,对不同单词的特征帧分配更多的注意力,提高了唇语识别准确率。与此同时,位于句中停顿处的帧对于唇语识别准确率同样存在一定程度的影响。将这些停顿时产生的帧分配较少的注意力,优化了识别过程。
Attention机制通常分为时间注意力机制和空间注意力机制,本文用到的是时间注意力机制。Attention机制的基本结构如图4所示。
图4 注意力机制网络结构
在Attention机制中,根据不同时刻的唇部时序特征的重要程度设计注意力机制:
ut = tanh(ww Ht + b) (11)
at = softmax(utT,uw) (12)
vt = ■at Ht (13)
其中,ut為隐藏层单元,at为注意力向量,Ht为BiLSTM的输出,vt为Attention机制的输出向量。
通过概率权重分配的方式,对唇语视频中不同时刻的唇部时序特征分配不同概率权重,使得一些更重要时刻的唇部特征能够得到更多的关注,从而进一步提高唇语识别的准确率。
1.4 分类层
将Attention机制的输出Ci送入Softmax分类器进行分类,输出为:
y = softmax(wiCi + b) (14)
本实验中每个输入序列对应输出是一种条件概率:
p(b|a1,a1,…,an) = p(b|An) (15)
p(b|An) = ■ (16)
p(b|An)是用于计算An属于每一类输出结果的条件概率,R是数据集,包含训练的单词和短语的全部视频。
2 实验结果分析
2.1 数据集介绍
为了验证本文模型的有效性,选取了在国际上稍具影响力的唇语识别公开数据集GRID[15]和MIRACL-VC[16]进行实验。
GRID数据集由34人录制而成,视频质量分为普通画质和高质量画质。图像分辨率360 × 288,时长约 3s,帧率约 25 fps。该数据集包括每人唇读1000条英文句子的视频。
MIRACL-V数据集由5男10女通过微软Kinect录制而成。图像为分辨率640 × 640的深度图和彩色图,语料包含10个单词和10个短语。该数据集总共包含每人唇读所有单词和短语各10遍的视频图像,总共包含3000个样本。
2.2 实验设置
为了和前人的实验形成对比,在GRID数据集和MIRACL-VC数据集的设置上和马宁[7]的一样,在GRID数据集上我们随机选取15人的唇读视频,GRID数据集将说话者所说的每个单词的开始时间和结束时间进行了标记,只选取数字部分进行识别。在15人的唇读视频中,选取14人的样本进行训练,1人进行验证。在MIRACL-VC数据集上,同样将15人的唇读视频进行如上处理。
在神经网络搭建上,由于使用的Keras深度学习框架进行搭建模型,该深度学习框架在搭建LSTM和BiLSTM时要求其长度固定,因此在GRID数据集和MIRACL-VC的单词数据集中分别选取最大帧数19和21作为其固定长度,在MIRACL-VC短语数据集上选取最大帧数27作为其固定长度。经过多次调参测试,将BiLSTM的参数设为128。为了加快训练速度,在注意力机制层后加入BatchNormalization层。
2.3 实验结果
在GRID数据集上,将本文的实验结果同Lan等人[6]和马宁等人[11]的实验结果进行对比。Lan等人[6]分别使用主动外观模型的外表参数(app),形状参数(shape)以及采用主成分分析将外表参数和形状参数相融合(aam_pca)做为唇部特征,然后使用HMM对唇部特征进行训练。马宁等人[11]提取了唇部18个关键点的坐标然后利用LSTM进行时序编码。
表1 在GRID的实验结果
可以看到,在GRID数据集上,本文模型的识别准确率比Lan等人的识别准确率至少提高了33.3%。比马宁等人的识别准确率提高了13.4%。
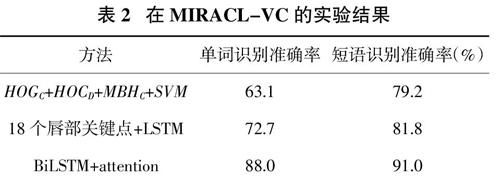
在MIRACL-VC数据集上,我们将本文的实验结果同Rekik等人[16]和马宁等人[11]的实验结果进行对比。Rekik等人[16]同时考虑了RGB图像序列特征(HOGC)、深度图像序列特征(HOGD)以及传统的运动特征(MBHC),然后使用SVM进行训练。
表2 在MIRACL-VC的实验结果
在MIRACL-VC数据集上,本文模型比Rekik等人和马宁等人的单词识别准确率分别提高了24.9%和15.3%,短语识别准确率分别提高了11.8%和9.2%。
2.4 和其他编码模型进行实验对比
为了进一步验证我们编码模型的有效性,在唇部特征提取方面依旧使用改进的主动形状模型,在时序编码方面我们将BiLSTM-Attention分别换成LSTM和BiLSTM進行对比试验。
表3 不同编码模型在GRID的实验结果
表4 不同编码模型在MIRACL-VC的实验结果
从表3和表4中可以看出采用BiLSTM-Attention方法在GRID数据集上比LSTM时序编码的方式提高了6.3%,比BiLSTM时序编码的方式提高了3.6%。在MIRACL-VC数据集上单词部分比LSTM时序编码的方式提高了9.7%,比BiLSTM时序编码的方式提高了5.9%,短语部分比LSTM提高了8.8%,比BiLSTM提高了7.0%。
step
图5 三种模型在MIRACL-VC短语数据集的loss图
图5是MIRACL-VC 数据集短语部分三种模型的训练loss图,横坐标为迭代次数,纵坐标为损失函数的输出。从图中看出BiLSTM-Attention方式的loss下降的最快,同时在近100次迭代时BiLSTM-Attention最先收敛,其loss值接近于0,收敛效果最好。
由上述实验可以看出,模型更好地提取了唇部的特征、既考虑了唇语识别中过去信息对当前信息的影响和未来信息对当前信息的影响,同时考虑不同时刻唇部时序特征对唇部识别的影响程度不同,极大地提高了唇语识别的准确率。
3 结 论
提出了一种BiLSTM-Attention的唇语识别模型。该模型提取了20个唇部关键点,能够细腻地刻画出唇部特征,同时利用BiLSTM对唇部特征进行时序编码,BiLSTM相比现有唇部识别模型既考虑了过去信息对当前信息的影响也考虑未来信息对当前信息的影响,最后利用时空上的注意力机制对BiLSTM的输出分配不同的权重进一步提高了识别的准确率。这种方法在公开的唇语数据集GRID和MIRACL-VC上比现有的唇语识别方法准确率提高了10%左右。结果表明BiLSTM-Attention模型对唇语识别准确率的提高有显著的作用。同时在实验部分还有一些需要完善的地方,例如本文使用的语料库只是英文数据集,未对中文数据集进行实验,下一步将针对这些问题进行进一步改进。
参考文献
[1] PETAJAN E,GRAF H P. Automatic lipreading research:historic overview and current work[J]. Multimedia Communications and Video Coding,1995:265—275.
[2] 任玉强,田国栋,等. 高安全性人脸识别系统中的唇语识别算法研究[J]. 计算机应用研究.2017,34(4):1221—1225.
[3] WECHSLER H,PHILLIPS J P,BRUCE V,et al. Face recognition:from theory to applications[M]. Washington DC:Springer Science & Business Media,2012:16—17.
[4] PETAJAN E D. Automatic lipreading to enhance speech recognition (SpeechReading)[M]. University of Illinois at Urbana-Champaign,1984.
[5] GOLDSCHEN A J,GARCIA O N,PETAJAN E D. Continuous automatic speech recognition by lipreading[M]//Motion-Based Recognition Springer Netherlands,1997:321—343.
[6] LAN Y,HARVEY R,THEOBALD B J,et al. Comparing visual features for lipreading[C]. Proceeding of International Conference on Auditory-Visual Speech Processing,2009:102—106.
[7] 宋文明. 基于HMM與深度学习的唇语识别研究[D]. 大连:大连理工大学,2017.
[8] 徐铭辉,姚鸿勋. 基于句子级的唇语识别技术[J]. 计算机工程与应用,2005(08):86—88.
[9] ZHAO G,PIETIKAINEN M,HADID A. Local spatiotemporal descriptors for visual recognition of spoken phrases[C]// Hcm 07 International Workshop on Human-centered Multimedia,2007.
[10] PEI Y,KIM T,ZHA H. Unsupervised random forest manifold alignment for lipreading[C]. ICCV,Sydney,Australia,2013,129—136.
[11] 马宁,田国栋,周曦. 一种基于long short-term memory的唇语识别方法[J]. 中国科学院大学学报,2018,35(1):109—117.
[12] SCHMIDHUBER J,HOCHREITER S. Long short term memory[J]. Neural Computation,1997,9(8):1735—1780.
[13] 赵富,杨洋,蒋瑞,等. 融合词性的双注意力Bi-LSTM情感分析[J].计算机应用,2018,38(S2):103—106,147.
[14] 冯兴杰,张乐,曾云泽. 基于多注意力CNN的问题相似度计算[J]. 计算机工程,2019,45(09):284—290.
[15] COOKE M,BARKER J,CUNNINGHAM S,et al. An audio-visualcorpus for speech perception and automatic speech recognition[J].The Journal of the Acoustical Society of America,2006,120:2 421—2424.
[16] REKIK A,BEN-HAMADOU A,MAHDI W. A new visual speech recognition approach for RGB-D cameras[C]. International Conference Image Analysis and Recognition.Springer International Publishing,2014:21—28.
