一种基于深度强化学习的室内声学行为识别方法
2020-04-09黄继风
刘 明,黄继风,高 海
(上海师范大学信息与机电工程学院,上海201418)
0 引 言
实践证明,人类行为识别技术在智能家居领域起着至关重要的作用.例如,更准确地识别用户的行为及其变化,使智能家居系统更好地为用户提供相关帮助[1].传统的行为识别方法侧重于使用可穿戴式运动传感器,如加速度计和陀螺仪来获取用户数据.大量的已有研究[2-4]证明,加速度计与陀螺仪等运动传感器能够很好地识别单独个体的动作,但无法获取个体之外的其他信息,难以识别个体与整体环境之间的复杂交互行为.因此,研究人员开始尝试使用图像传感器或声音传感器[5-10]来获取用户数据,并对其行为进行识别.
虽然基于图像或声音传感器的方法均可以获取个体与整体环境间交互的信息,能够识别更复杂的交互行为,但是价格较高,且容易受到安装位置、灯光、死角、像素等诸多限制.基于声音传感器的行为识别方法价格低廉,容易部署,不会受到灯光及死角等问题的影响,更适合于家庭环境应用.研究人员提出了多种基于声学的行为识别方法,从单一的可穿戴设备[6]到整体传感器系统[7-8].然而,这些方法都需要对训练数据进行逐帧标注,标注过程繁琐,且容易受主观因素影响,训练数据较少.此外,由于每个人的行为声音存在一定差异,导致这些方法的准确率依然较差.为了使模型能够更准确地识别特定用户的行为,研究人员尝试将特定用户的行为作为训练数据来调整模型[9-10],这些方法需要用户多次重复相同的行为,严重依赖于特定用户的数据,且只能保证对特定用户的行为进行准确识别,泛化能力较差.
本文作者提出一种基于整体环境的声音识别方法,能够识别11 种常见的室内行为,不需要人工收集训练数据或逐帧标注,也不需要通过获取特定用户提供数据来调整模型.用数据集以及Google AudioSet数据集[11]中的YouTube 视频声音片段,提取embedding 特征及原始数据的梅尔频谱图特征作为训练集.由于数据集的量级较大,分类间严重不平衡.采用了深度强化学习方法来动态地控制每一批次数据的分布,用以解决数据不平衡问题.将数据批次作为强化学习中的环境的状态,将识别结果作为智能体的动作,把对各个行为的识别错误率函数作为执行动作后获取的奖励信号,最终实现用户的行为识别.
1 相关研究
1.1 传统行为识别方法
传统的行为识别方法使用可穿戴运动传感器,此类设备可以在智能手机[3-4]、智能手表[12-14]及可穿戴传感器板[2]上灵活实施.KWAPISZ 等[3]的方法仅要求对象携带智能手机,可识别用户步行、慢跑、上下楼、坐姿和站姿.THOMAZ 等[12]提出使用智能手表中的3 轴加速度计来检测对象是否正在进餐.RAVI等[2]将传感器板安装在人体内,实现简单的运动行为识别.这些工作的重点均对非常简单的行为动作进行识别,可以通过增加传感器的数量,识别更复杂的行为.然而,基于多传感器的训练数据集数量较少,且识别过程需要占用大量计算资源,基于复杂传感器阵列的识别方法难以实现.
1.2 声学行为识别方法
由于传统方法的局限性,研究人员提出声学行为识别方法.YATANI 等[15]提出使用蓝牙麦克风,从人类咽喉中收集声学数据,识别进食、说话和咳嗽等与咽喉运动相关的行为.THOMAZ 等[6]通过使用腕式声学传感器识别人类的进食行为.随着智能手机的发展,智能手机的声学传感器也越来越多地被用于行为识别任务.一款名为AmbientSense 的Android 应用[7],可对23 种简单的生活环境的进行分类.CHEN等[8]提供一种基于声学传感器的行为识别方法,从原始声音数据中提取出梅尔频率倒谱系数(MFCC)特征,并对6 种浴室中的常见行为进行识别.这些工作都需要收集用于训练的数据,并对原始声音数据进行逐帧标注,部分模型需要特定用户多次重复相同的行为后,才能获取足够的数据进行准确识别.
HWANG 等[16]开发了一个平台用于收集用户的声音数据,使用基于MFCC 特征的高斯直方图生成全局K近邻分类器,以识别基本的声音场景.但是,该方案仍然需要收集用户数据,且识别性能很大程度上取决于已有训练集的大小和质量.NGUYEN 等[9]利用半监督学习方法将在线FreeSound 数据与用户自己的录音结合起来,在手动过滤离群值之后,从123 个FreeSound 声音片段提取MFCC 特征,并进行半监督高斯混合模型(GMM)训练.
1.3 FreeSound数据库
FreeSound 是一个声音数据样本存储库,有超过4.0×105声音片段.SALAMON 等[17]从FreeSound 数据库中选择的18.5 h的城市声音片段,建立了UrbanSound数据库.SÄGER等[18]在声音的标签中添加形容词和动词,改进了FreeSound 数据库,并建立了AudioPairBank 数据集.ROSSI 等[10]基于高斯混合模型从FreeSound 数据库提取MFCC 特征,并进行环境识别,然而,由于训练集的大小有限(23 个行为分类仅有4 678 个声音样本),分类准确率仅为38%,在手动过滤38%的样本作为异常值后,分类准确率达到了57%.
1.4 Google AudioSet数据库
Google发布的声音数据集AudioSet[11]共分为527类,所有声音片段长度均为10 s,其标签为10 s内该声音片段中发生的所有事件,而非逐帧标注.AudioSet数据集还提供VGGish 模型[19]提取的embedding 特征.VGGish模型将原始声音数据按秒转换为特征,并使用主成分分析(PCA),仅保留前128个PCA 系数.一个128 维的embedding 特征向量代表1 s 的声音片段,因此数据集内的每个声音片段为10 个128 维的embedding特征向量.
1.5 强化学习
强化学习是近年来机器学习领域的研究热点之一,是一种用自主学习的数学模型,在很多算法中起着重要的作用[20].它无需标签,仅仅需要执行动作后的奖励信号决定如何与一个动态且未知的环境进行交互,以期将累计奖励最大化[21].深度学习与强化学习结合,构成了深度强化学习,比如:基于深度强化学习方法的Atari2600 游戏[22]、战胜了人类世界冠军的围棋程序AlphaGo[23]等.
2 设计与实现
2.1 标签关联
在对模型进行训练之前,需要先考虑如何从AudioSet数据集中选择可以用于行为识别的标签,并将其与预测的行为进行关联.FreeSound 数据库以及AudioSet数据集中并不能同时找到所有典型的室内行为.此外,将识别目标限制在常见行为,且声音容易获取并识别的范围内,某些标签未被选中,比如“睡觉”、“坐卧”、“站立”及“房间里没有人”等.鉴于并非所有家庭都饲养宠物,没有选择任何宠物相关的类别.由于两大数据库对标签的分类设计无法与我们要识别的目标行为绝对匹配,则采用间接匹配方法,确定与目标行为密切相关的对象及其整体环境,并选择这些对象和环境代表需要识别的目标行为.例如,使用“water tap(水龙头声)”和“sink(水槽流水声)”分别代表“洗手”和“洗脸”,因为这2个特征都与使用洗手池有关,且非常相似.
基于上述考虑,确定了11 项常见室内行为,将它们与13 个标签相关联.表1 展示了目标行为与AudioSet标签之间的关联.
2.2 深度强化学习方法设计
类别不平衡是机器学习领域中的一个常见的问题,具体表现为:数据集中某一个或几个分类样本的数量远低于其他分类,AudioSet类别间的分布严重不平衡.图1 展示了数据集中每个类别样本的原始数量之比例.由图1 可以看出,演奏音乐的样本占了近50%,这将导致预测结果严重倾向于量级高的分类,严重影响模型的识别性能,因此针对该问题,使用深度强化学习方法控制每一数据批次的分布,避免模型的训练受到数据分布不平衡的影响.

表1 AudioSet标签与行为的对照表

图1 AudioSet中各分类样本的大致分布
在强化学习中,对于当前输入状态s,机器在某种策略π的指引下选择动作a=π(s),采用状态-动作值函数(Q值函数)评估策略,其数学模型为:
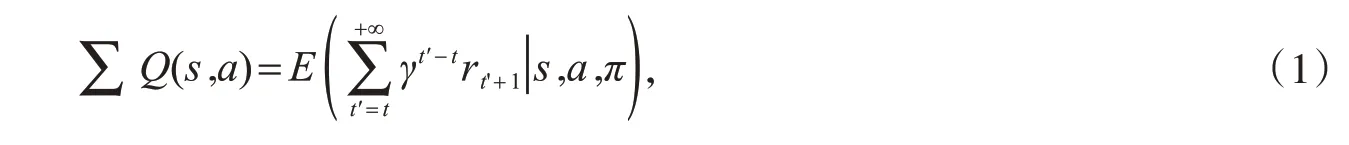
其中,r为奖励值;t为当前行动的步数;γ为衰减系数,取值范围为[0,1],是用来保证长期累积奖励能够趋于收敛.对式(1)进一步推导可得Bellman方程:

其中,s'为状态s下执行动作a后转移到的新状态;r为状态s执行动作a后转移至s'时获取的奖励;a'为根据新的状态所作出的新动作强化,学习任务中策略的改进与值函数的改进是一致的.根据式(2)求得Q(s,a)后,以策略替换π,Bellman方程变换为:

其中'Q'(s''a')为使用最优策略π'时,所产生的期望累积奖励.
每一轮中迭代的损失函数为:
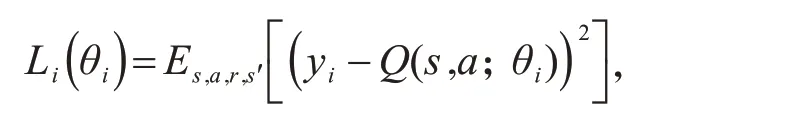
其中,目标值为:

由于在实际应用中,对于值函数的估计太过乐观,将yi其中的目标改为:
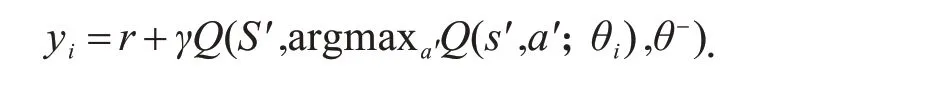
本研究的深度强化学习方法总体框架如图2 所示.该方法主要由2 个部分构成:环境和智能体.其中,环境每次提供一定批次的数据作为状态,智能体根据状态,识别其中包括的行为,并执行动作;环境结合样本真实分类及智能体发出的动作进行评价,将评价信号作为智能体奖励信号,更新参数.同时,环境如继续提供下一批次数据,则根据智能体对当前批次样本的识别错误率的比例,决定下一批次提供数据的比例.

图2 深度强化学习流程图
具体流程如下:
1)训练开始时,环境将包含多个数据样本的批次作为状态提供给智能体,其中各个行为的分类比例相同.
2)智能体接收到状态后,对其中的每个数据样本进行识别,得出其包含的行为类别,作为动作提交给环境.
3)当环境接收到智能体提交的动作后,计算各行为类别的识别错误率,并将其作为奖励值.假设行为共分K 个类,智能体对各行为的识别错误率分别为C1'C2'…'CK.奖励函数共分为两个部分,第一个部分为对各个分类的错误率平方和的负值;第二部分为最低与最高分类错误率的差值,差值越大,说明模型的分类不平衡情况越严重.由此,

如果智能体连续对多个批次的预测识别错误率均低于预先设定的阈值,则停止训练;否则,决定下一批次提供的数据样本的分类比例.假设每批次提供N 个样本,则下一批次提供的第k个分类的样本数

2.3 网络结构
深度学习网络是卷积神经网络(CNN)与长短期记忆(LSTM)网络的结合,其输入共分为两个部分:1)原始数据的梅尔频谱图,统一截取为1 024×512 的格式;2)embedding 特征,格式为10×128,第一个维度代表时间,第二个维度代表特征.为了方便使用2维卷积神经网络,将数据样本的格式转换为3维,并使用卷积神经网络进一步提取与时间及特征均相关的更抽象的关系.为了防止梯度爆炸的同时,保留更加精细的特征,网络结构中未使用池化层,仅在卷积层后进行批量归一化,使用LSTM 网络提取时序相关的信息,网络结构如图3 所示,输出层参考KONG 等[24]提出的attention model 层,以实现网络的多分类预测功能.
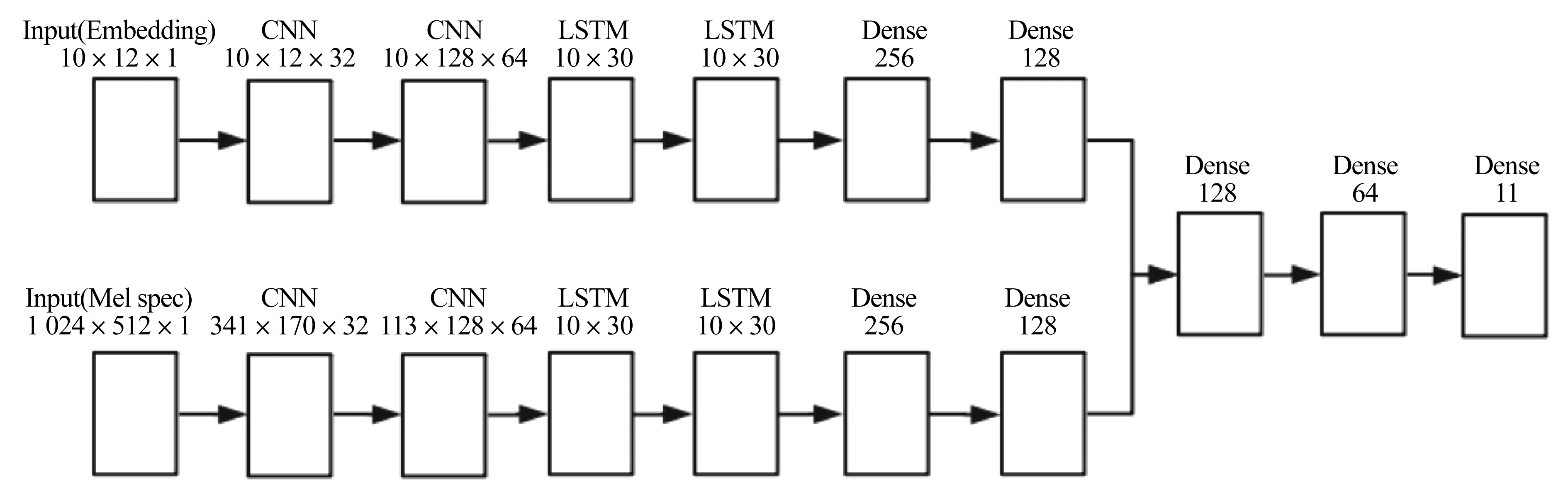
图3 智能体内部神经网络结构图
3 实验与分析
该深度强化学习模型在Ubuntu 16.04 系统平台上训练和测试,基于Google 的TensorFlow 框架,使用Keras深度学习程序包与Python 3.6开发软件,使用NVDIA GTX 1070加速实验.
选取样本51 360 条,其中训练集样本数量为45 310 条,测试集样本数量为6 050 条.数据的原始形式为以10 s 为单位的声音片段,训练数据集为音频的梅尔频谱图,以及使用VGGish 模型从原始数据集中提取的embedding 特征,embedding 特征数据的信号采样统一为128 Hz.模型训练参数如下:学习率为0.000 1,mini-batch 大小为64,迭代次数为1 000,衰减系数γ 为0.9,采用Adam 算法训练网络,损失函数为分类交叉熵.
在训练集上进行10 次交叉验证,将其取平均值作为最终测试结果,验证模型的泛化能力.本方法与传统的合成少数类过采样技术(SMOTE)方法在相同网络结构下,总体分类准确率如表2所示.
从表2 可以看出,在解决分类不均衡问题上,本方法比SMOTE 方法效果更好.采用不同结构及过采样解决方法在分类准确率上相差较大,说明神经网络在训练过程中,学习到了一些特征,有助于降低数据不平衡对模型带来的影响.
实验结果如图4 所示,本方法的总体识别准确率达到了87.5%,对每个行为的识别准确率均超过了83%.

表2 本方法与过采样方法的分类准确率结果对比
4 结 论
由于AudioSet 数据集本身存在的分类严重不平衡问题,本文作者设计了基于深度强化学习思想的训练方法,对于每一批次的预测结果,动态地调整下一批次的数据分类占比,避免了由数据集的分类不平衡问题对模型分类效果造成的影响.通过大量交叉实验证明,本方法的总体分类准确度达到87.5%,对所有分类的准确度都在83%以上.相较于SMOTE 方法,本方法准确率达到预期效果,且不需要采集用户数据,能够达到对声学行为进行分类的目的.
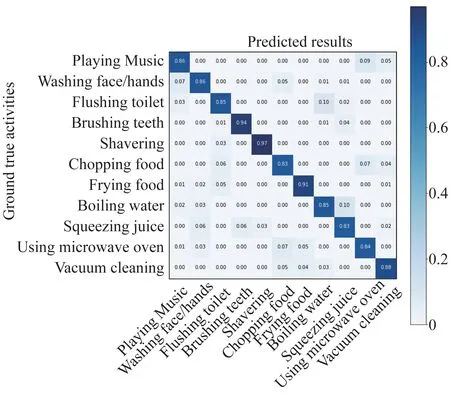
图4 在测试集上的识别结果
