一种空气污染物浓度预测深度学习平台
2020-04-09卢淑怡张旱文高浩然
卢淑怡,张 波*,张旱文,俞 豪,高浩然,刘 波
(1.上海师范大学信息与机电工程学院,上海201418;2.上海超算科技有限公司,上海201203)
0 引 言
随着深度学习技术的兴起,空气污染预测成为信息科学和环境科学的交叉融合课题.国内外各研究学者通过大量的传统数值分析和机器学习手段等方法已取得了一定的成果.雷源等[1]为对流层内的多种气体污染物的时空分布及演变过程进行预测,建立了对流层高分辨率化学预报模型;朱亚杰等[2]通过建立贝叶斯时空模型对京津翼区域进行空气污染预测,考虑了PM2.5污染物的时间变异和空间分布特性,进行预测的过程中还引入气象数据作为协变量;尹琪等[3]通过支持向量机(SVM)结合改进的粒子群(IPSO)算法和遗传算法(GA),使用参数寻优的方法建立新模型,从而对空气质量指数做预测;陈伟等[4]使用支持向量机(SVM)结合小波分解建立了城市大气污染物浓度预测模型,通过对于小波分解重构,得到由分解序列合成的最终预测结果.
深度学习作为人工智能前沿技术,国内外在研究污染物浓度的序列建模和变化趋势预测方面已获得很多良好的效果.尹文君等[5]针对当前热点的环境问题,提出基于深度学习的大数据空气污染预报,通过模拟人脑的神经连接结构[6],实现大数据集成,有效克服现有方法的缺陷,提高预报性能,在应用层面上更加灵活和可操作.
尽管空气污染预测在深度学习领域取得了较大的发展,但仍存在不足.例如:1)当下的预测方法仅提供了较为优质的模型,无法直观地展现预测结果,不同的模型也无法在一个平台上统一应用;2)各个模型的集成度较差,对于跨专业领域的应用存在困难.因此,本文作者提出一种基于深度学习的空气污染物浓度预测平台,利用网络爬虫技术获取众多的污染物数据,考虑到传统数值分析和机器学习手段的局限性[7],采用长短期记忆(LSTM)网络模型的深度学习[8]框架进行空气污染物浓度的预测,充分结合气象数据对污染物浓度预测的影响,将基于深度学习的空气污染预测技术设计为一个交互式平台,提出了一种具有3个层次的深度学习交互式平台架构.该平台可通过对用户的个性化模型参数进行设置,具有灵活、可扩展等优点.
1 总体技术框架
平台一共有3个层次组成,分别为:数据采集层、模型层以及可视化界面层.由数据采集层自动更新气象数据和空气污染数据,数据经清洗和筛选后上传至模型层,经过LSTM 网络模型,将产生的预测结果上传至可视化界面,并展示给用户,如图1所示.

图1 总体技术框架图
1.1 数据采集层
数据采集层主要负责采集空气污染的数值数据.该层接收来自网络爬虫采集到的数据.数据内容包括:时间、监测站、湿度、降雨量、风向、风速、温度、PM2.5值、PM10值、SO2、NO2、CO 及O3的13 个数据项.整合成为以小时为时间跨度单位,整体长度为2015—2018年的实时数据,接着对其进行数据清洗及筛选,最后上传至模型层进行训练.
针对大量气象数据的收集、获取及筛选处理,数据采集层利用网络爬虫程序,从2345天气网站对上海市近3 年及实时数据进行采集.网络爬虫程序通过统一资源定位符(URL)地址和超文本传输协议(HTTP),模拟客户端向访问的网站发送请求,封装必要的参数信息,自动获取网站内容信息并解析数据,如图2所示.

图2 网络爬虫工作流程图
1.2 模型层
模型层作为该平台架构的核心,集成了多种深度学习的神经网络模型.用户可根据不同的需求选择相应的网络模型,设置自定义参数进行训练.1.2.1 LSTM模型介绍
1)遗忘门层.遗忘门层决定细胞状态中信息的保留和丢弃.
2)输入门层.输入门层判断细胞状态中信息是否需要更新.
3)更新门层.更新门层负责更新细胞状态.
4)输出层.输出层负责确定输出的内容.采用LSTM 网络模型的记忆门和遗忘门机制,记忆门决定保留过往有用的信息,遗忘门用于过滤掉无用的信息,从而突出重点属性,降低非相关属性的影响,对PM2.5空气污染物进行回归预测.
1.2.2 基于LSTM网络模型的空气污染物浓度预测
在模型层设计一个符合空气污染物浓度预测的LSTM 网络模型,LSTM 网络模型和数据集的相关参数可由用户自行设定.该模型主要包括3个部分:输入层、隐藏层、输出层.
1)输入层接收数据采集层处理的数据,再将数据进行归一化处理,形成符合网络输入格式的规范数据.
减译法是指在不影响原文思想和内容的情况下,把重复多余的文字省去,或在不影响译语读者理解的情况下,用更加简明的语言形式代替原文繁琐语言的一种翻译方法,比如:
2)隐藏层包括LSTM 网络模型和全连接层.依据不同粒度的时间窗口,对模型进行分析,综合验证时间长度依赖所取得的最佳窗口值.调节LSTM 网络模型隐藏层中各处理器之间的传播机制,优化处理器内部的参数设置,实现对时间序列预测的优化.通过网络训练,LSTM 网络模型将分析所得的污染物特征传给全连接层,全连接层将该特征转译为预测的污染物数值.
3)输出层输出下一时段PM2.5的预测值,同时记录训练过程当中的均方误差、损失函数等相关系数.
1.3 可视化界面层
用户在可视化界面输入相关参数,LSTM 网络模型接受参数后开始训练,数据经训练之后,以图表的形式,将预测到的PM2.5空气污染物及其他相关数据呈现给用户.除此之外,模型训练过程中的均方误差、损失值和数据集的特征分布也会以图表的形式展现给用户,方便用户评估模型性能,观察数据集分布特征.
2 仿真实验验证
本平台以MySQL为数据库,Vue.js文件为前端,融合了数据源处理、深度学习模型、数据可视化等技术,并具有可扩展性,兼容多类人工智能模型,如图3所示.
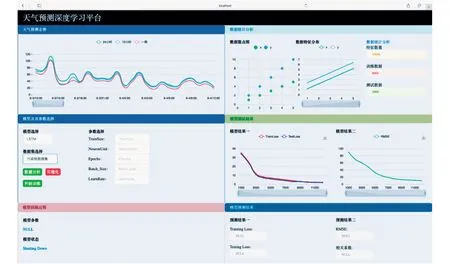
图3 空气污染物浓度预测平台界面
本平台主要由6个模块组成:
1)天气预测走势.通过将数据库中已经拥有的天气数据输入LSTM 网络模型进行训练,对未来的PM2.5情况进行预测.以折线图的形式展示24 h,72 h 和一周这3 个不同时间跨度的PM2.5污染物质量浓度,如图4所示.

图4 天气预测走势图
2)数据统计分析.结合历史污染物质量浓度数据,对CO,PM10,PM2.5等污染物进行统计分析,生成数据散点图(图5)和数据特征分布图(图6).

图5 数据散点图

图6 数据统计分析图
其中,数据散点图展示了PM10,PM2.5两种污染物的数值情况,根据散点图的聚集程度,用户可判断一段时间内的空气质量情况.
数据特征分布图则显示了CO,NO2等六类污染物数据,用户可选择自己所需要查看的污染物种类.通过折线图的方式,用户可以清晰地了解一段时间内污染物的变化情况.
3)模型及其参数选择.选择数据集与相应的训练模型,并为训练模型设置相应的参数.该板块具备兼容性和可扩展性,用户可自行添加其他模型进行训练,也可添加不同的数据,根据用户的不同需求进行预测,如图7 所示.其中,TrainSize 代表训练集的大小,NeuronUnit 代表输出维度,Epochs 代表训练轮数,Batch_Size代表批处理的大小,LearnRate代表学习率.

图7 模型参数选择图
4)模型测试结果.生成模型损失值和模型周期的函数关系图,并生成预测的天气数据和时间的关系图.
模型损失函数变化曲线图(图8)展现了现有模型与理想回归模型的差距,其变化规律与数值给用户直观地展现了模型的收敛过程与最终性能.
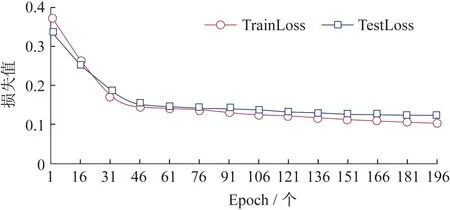
图8 模型损失函数变化曲线图
模型预测结果图(图9)则展示了用户自定义模型对污染物浓度预测的准确度,通过观测值和预测值曲线的重合性,用户可判断未来污染物数值(即天气预测走势图)的准确性.

图9 模型预测结果图
5)模型训练过程.模型训练过程显示模型训练时候的参数与训练的状态:Shutting Down(关闭)、Training(训练中)、Finished(完成).
6)模型预测结果.计算最后模型的损失值,并计算模型预测相应的误差,生成对模型的性能评估指标.
采用经典的数据切分方式,即80%的数据作为训练集,20%的数据作为测试集.用户通过输入神经元个数(NeuronUnit)、训练轮数(Epochs)、一次训练所选取的样本数(Batch_Size)、学习率(LearnRate)4个参数进行训练,得到相应的预测结果,如表1 所示.实验证明,随着神经元个数及训练轮数,预测值基本可以逐步拟合测试值.

表1 实验结果
3 结 论
采用LSTM 网络模型深度学习框架进行空气污染物浓度的预测,同时提出了基于深度学习的三层架构预测平台,给深度学习的可视化技术提供了一种新的方法.该平台分为数据采集层、模型层和可视化界面层三个层次,集成了多种深度学习模型,可以直观地展示数据,并具备兼容性和可扩展性,用户可以在平台上自定义不同的数据集、深度学习模型以及训练参数.
