基于卷积神经网络的多场景道路坑洼图像检测
2020-04-09陈鹏,应骏
陈 鹏,应 骏
(上海师范大学信息与机电工程学院,上海201418)
0 引 言
道路检测是汽车辅助驾驶、移动机器人、智慧交通等领域最基础、最重要的研究内容之一[1].对不同坑洼进行分类,依据分类信息给车辆驾驶人员发出警告信号,使其可以提前采取应急的措施,避免交通安全事故的发生.
YU等[2]提出利用激光图像检测,评估坑洼的严重性,但该算法在现实环境下的适应性较弱.ZHANG等[3]提出了基于卷积神经网络检测道路裂缝的方法,但其数据集缺乏多样性,有一定的局限性.SUONG等[4]对道路坑洼进行检测,但其对所有坑洼进行识别,没有对场景进行有效划分.
本文作者采用卷积神经网络方法对坑洼图像进行多场景识别,建立多样性的数据集,用卷积神经网络模型inception_v1[5]对坑洼图像进行多场景分类,分别构建数据集进行训练,检测相应的坑洼.实验结果表明:本算法比不划分场景方式得到的检测效果更好.
1 算法原理及优化
将卷积神经网络模型inception_v1 作为坑洼多场景分类的依据,提高了网络中的计算资源,克服了由于参数过多而出现的过拟合及梯度弥散问题,将坑洼分为了强光下的坑洼、弱光下的坑洼,以及无坑洼的场景.根据强光下的坑洼和弱光下的坑洼的场景,利用算法faster_rcnn[6]进行相应的检测,算法结构如图1所示.
由图1可知:将多场景分类后的图片输入到卷积神经网络模型inception_v2中,提取坑洼的特征,得到坑洼的特征图(conv feature map),前向传播进入区域建议网络(RPN)分支与Fast R-CNN 分支.RPN分支得到的是坑洼的候选区域,得到判别物体的得分(scores),并利用计算得到候选框的位置(coordinates),通过非极大值抑制(NMS)方法得到N 个得分较高的坑洼特征子图(ROIs),将ROIs送入到Rol pooling 层(Rol pooling layer),经过全连接层,计算每个区域坑洼的得分以及第二次回归后候选框的精确坐标.
深度神经网络的训练过程是分批次进行的,要使训练结果达到最优点,既不能因为学习率过低造成其收敛太慢,同时也不能因为学习率过高造成其摆动幅度过大,本算法采用动量优化方法Momentum 对其进行优化:

其中'vw和vb分别代表前一轮迭代过程中累积的权重和偏置的梯度动量;β 是梯度累积指数;w 和b 分别是损失函数反向传播得到的权重梯度和偏置梯度;α是学习率.
2 仿真实验
2.1 数据集的建立以及数据增广
通过互联网的图片查找以及线下手机拍摄获取相应数据,将坑洼分为3种不同的场景:无坑洼的道路、强光下的坑洼道路及弱光下的坑洼道路.无坑洼的数据包括雨天、雪天、强光、弱光及有阴影的情况;强光下的坑洼数据包括雨天、雪天、多坑洼、无阴影及有阴影的情况;弱光下的坑洼数据包括水渍、多坑洼及单坑洼的情况.
对数据进行预处理,统一将采集到的坑洼图片调整为600×600 pixels,同时将一部分数据进行数据增广,增广操作采取图像逆时针旋转90°,180°,270°,以及裁剪的方式.
2.2 数据集划分与标注
本实验的数据集分为两部分:一部分数据集用于多场景的分类;另一部分数据集用于坑洼的检测,80%的数据集作为训练集,其余作为测试集.选取10 032张预处理后的图像(数据集1),其中训练集有8 026张图像,测试集有2 006张图像,包括:无坑洼、强光下坑洼及弱光下坑洼各3 344张图像.
另选取3 513张图像(数据集2),其中训练集有2 811张图像,测试集有702张图像,包括:混合坑洼、强光下坑洼及弱光下坑洼各1 171张图像.数据标注采用LabelImg标注工具,记录数据的坐标信息.
2.3 性能评价
2.3.1 交叉熵损失采用损失函数衡量收敛稳定性.交叉熵损失函数为:

其中,yi表示期望的输出;yi'表示原始的实际输出.交叉熵损失值变化的程度代表了训练模型的稳定.
2.3.2 准确率
准确率公式如下:

其中,TP代表实际为正例且被分类器划分为正例的样本;TN代表的是实际为负例且被分类器划分为负例的样本;P代表所有的正样本;N代表所有的负样本.
2.3.3 平均精度

其中,PA为类别A 的精确率;NTRA为类别A 中正确预测的坑洼数量;NTOA为类别A 中坑洼总数为类别A的平均精度;NTIA为类别A中图像总数.
3 训练与结果
本实验硬件环境为:E5-2630 v4 处理器,64G 内存,Quadro M4000 显卡;软件配置为:Ubuntu 17.10,Python 3.6和Tensorflow 1.5.0.
3.1 坑洼多场景分类
本实验的batch_size 设置为24,即每一次迭代输入24 张图像进行训练,总共训练了12 000 步,学习率采用指数衰减的方式,初始的学习率设置为0.000 1.
坑洼的多场景的分类损失采用交叉损失的方式,其损失的变化曲线如图2所示,损失随着迭代次数的增加而减小,迭代过程从0~9 600步时,损失从1.35减少为0.48,之后的损失稳定在0.48.
数据集1的准确率变化曲线如图3所示,迭代过程从0~4 000步时,准确率增长较快,从0.30增长为0.90;迭代过程从4 000~7 000步时,准确率保持在0.90;之后的准确率保持在0.91.
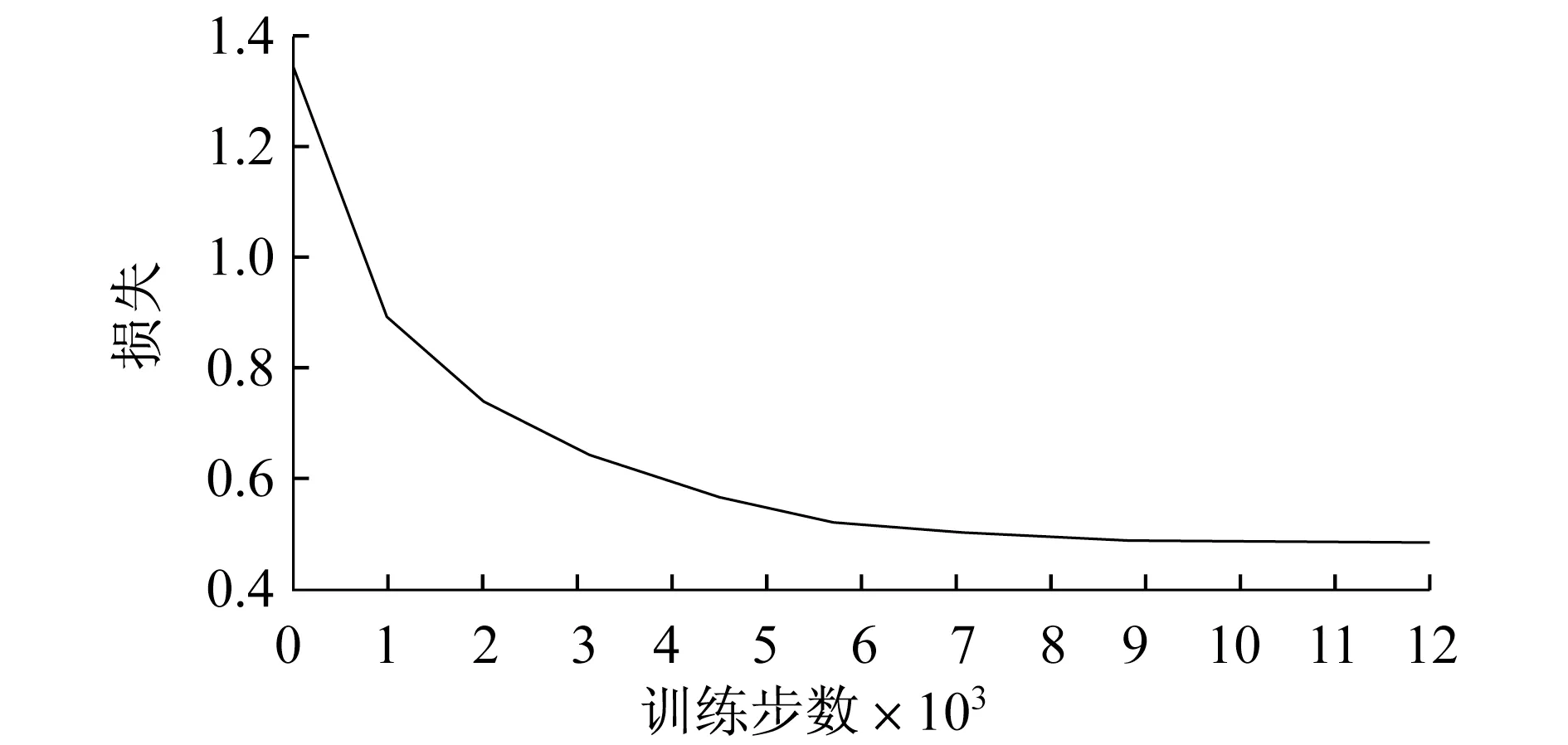
图2 多场景分类损失随训练步数的变化趋势
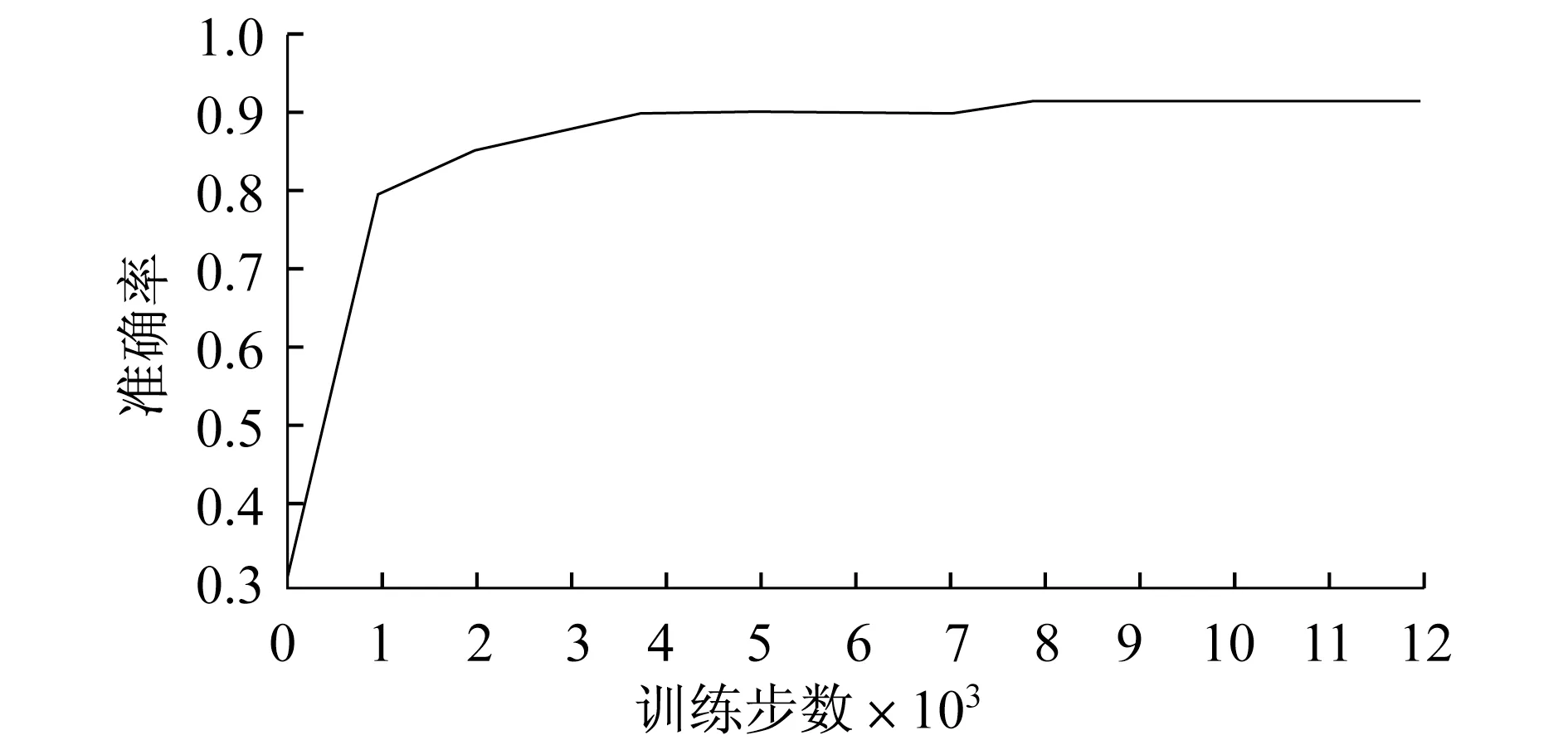
图3 准确率随训练步数的变化趋势
3.2 坑洼检测
batch_size 设置为8,即每一次迭代输入8 张图像进行训练,总共训练了20 000 步,初始的学习率设置为0.000 1.对数据集2中的混合坑洼、强光下的坑洼、弱光下的坑洼分别进行训练.
图4~6 分别为混合坑洼数据集,以及经本算法分类处理后的强光下坑洼数据集和弱光下坑洼数据集在训练过程中的损失值变化情况.混合坑洼、强光下的坑洼数据集的损失最后均稳定在0.10,弱光下的坑洼数据集的损失稳定在0.09.
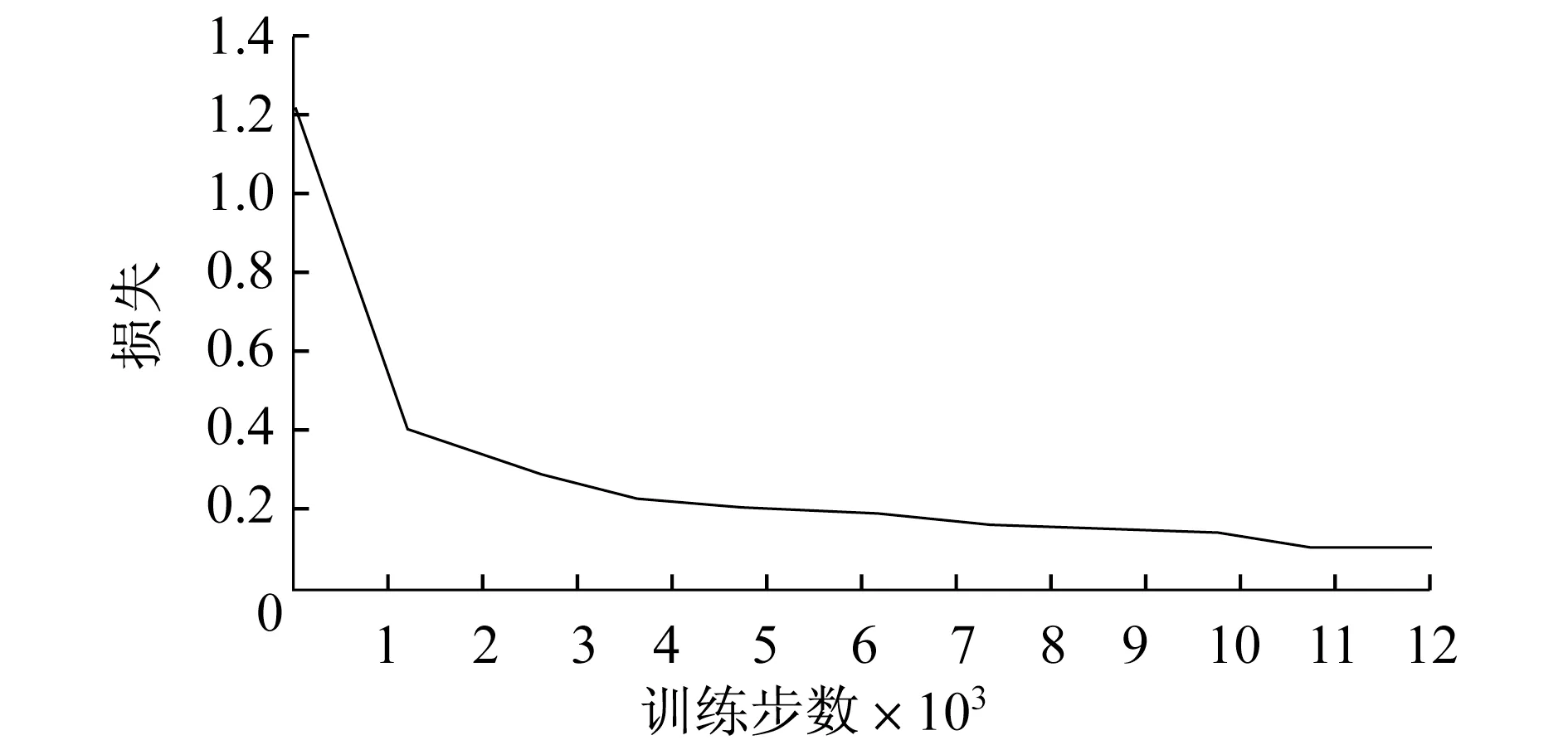
图4 混合坑洼损失随训练步数的变化趋势
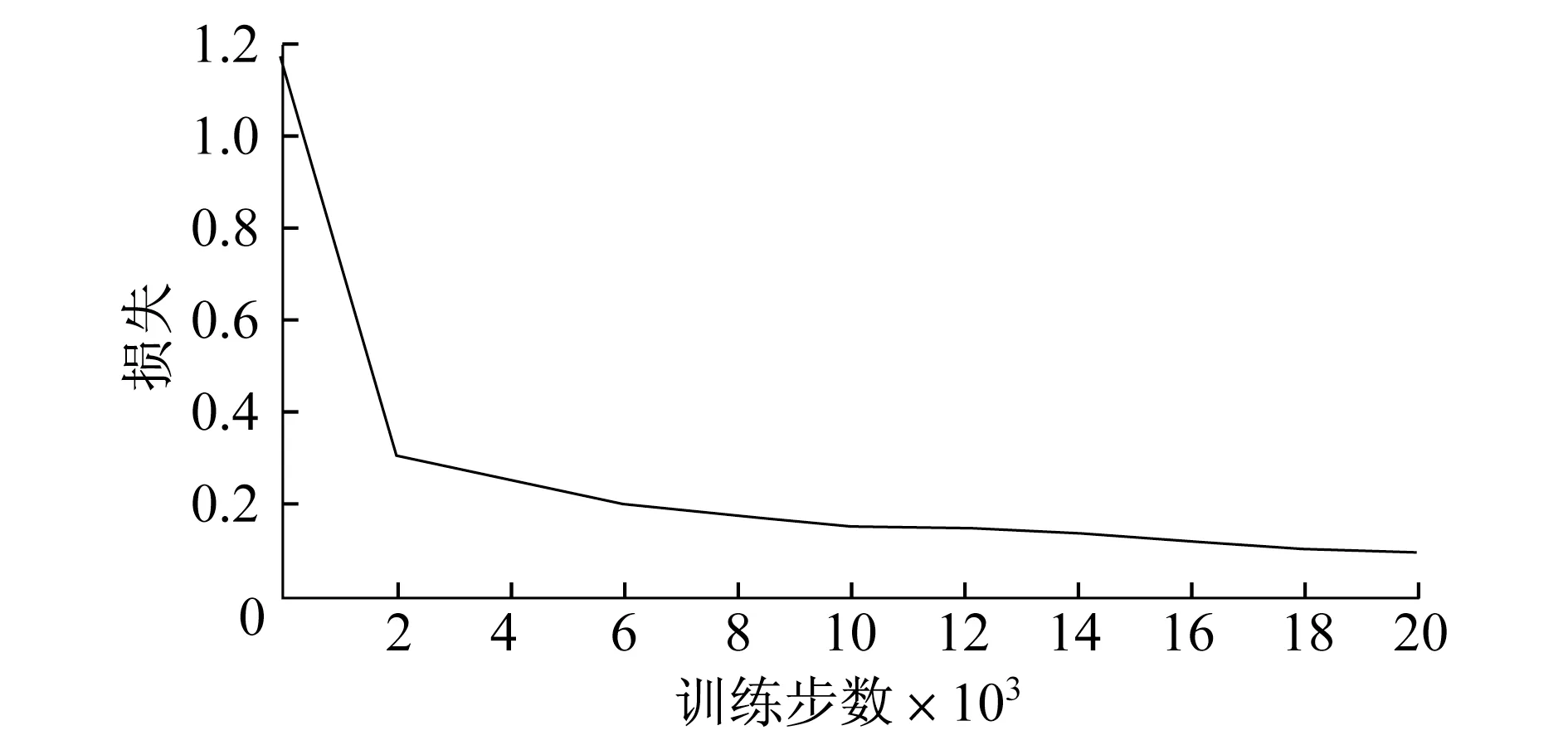
图5 强光下的坑洼损失随训练步数的变化趋势
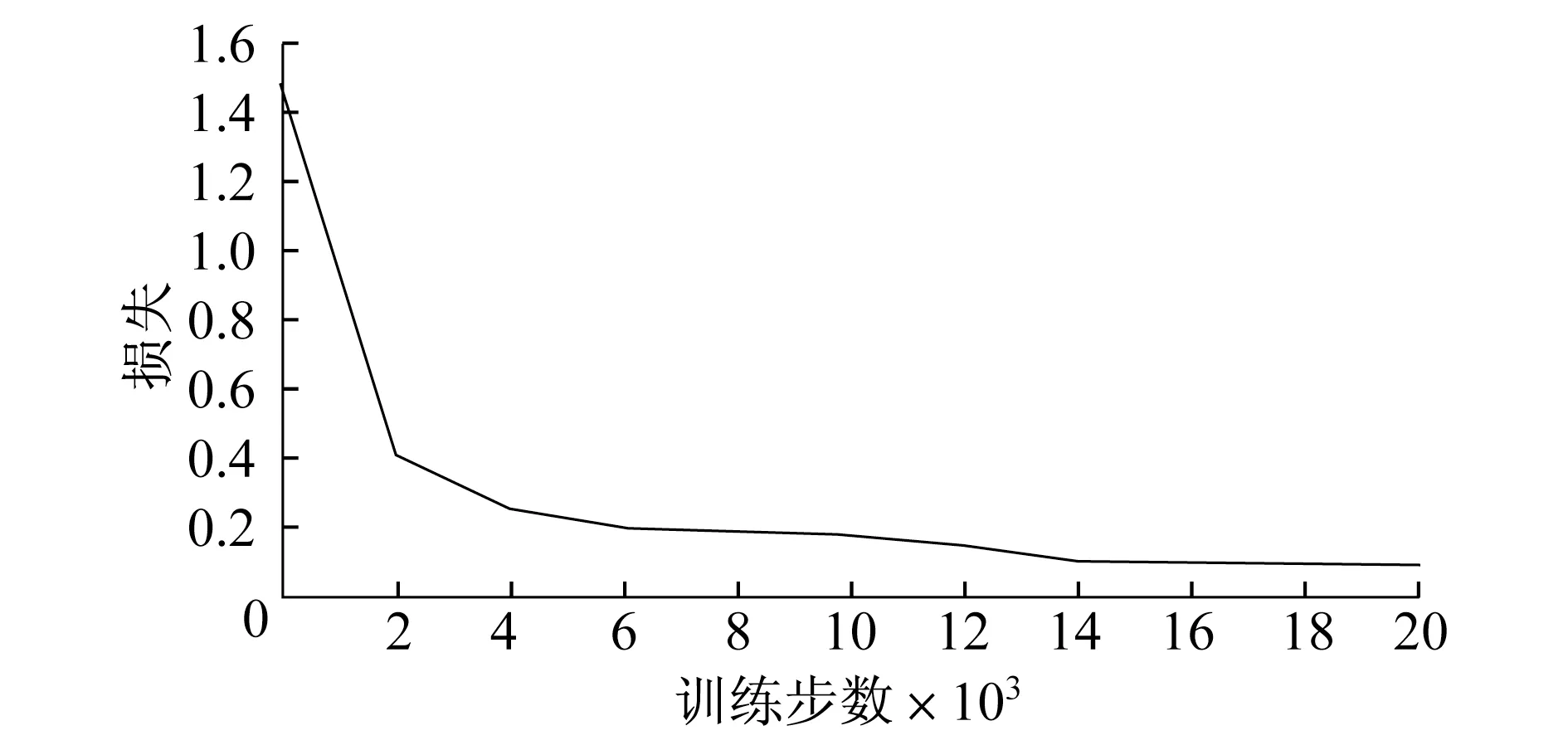
图6 弱光下的坑洼损失随训练步数的变化趋势
图7 ~9 分别为混合坑洼数据集,以及经本算法分类处理后的强光下坑洼数据集和弱光下坑洼数据集在训练过程中的平均精度变化情况.混合坑洼模型的平均精度最后稳定在0.717,本算法在强光下测试集的平均精度最后稳定在0.756,本算法在弱光测试集下的坑洼的平均精度最后稳定在0.881.由此可见,本算法的训练结果平均精度均高于混合坑洼..
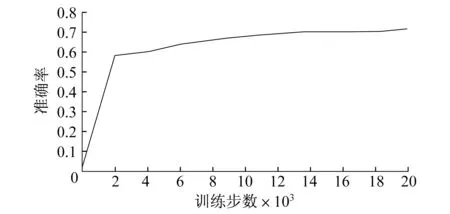
图7 混合坑洼的平均精度随训练步数的变化趋势
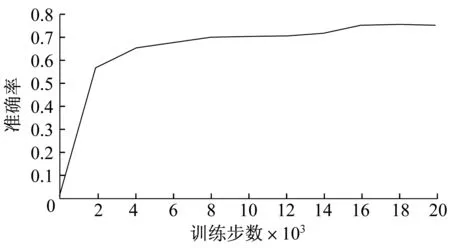
图8 强光下坑洼的平均精度随训练步数的变化趋势
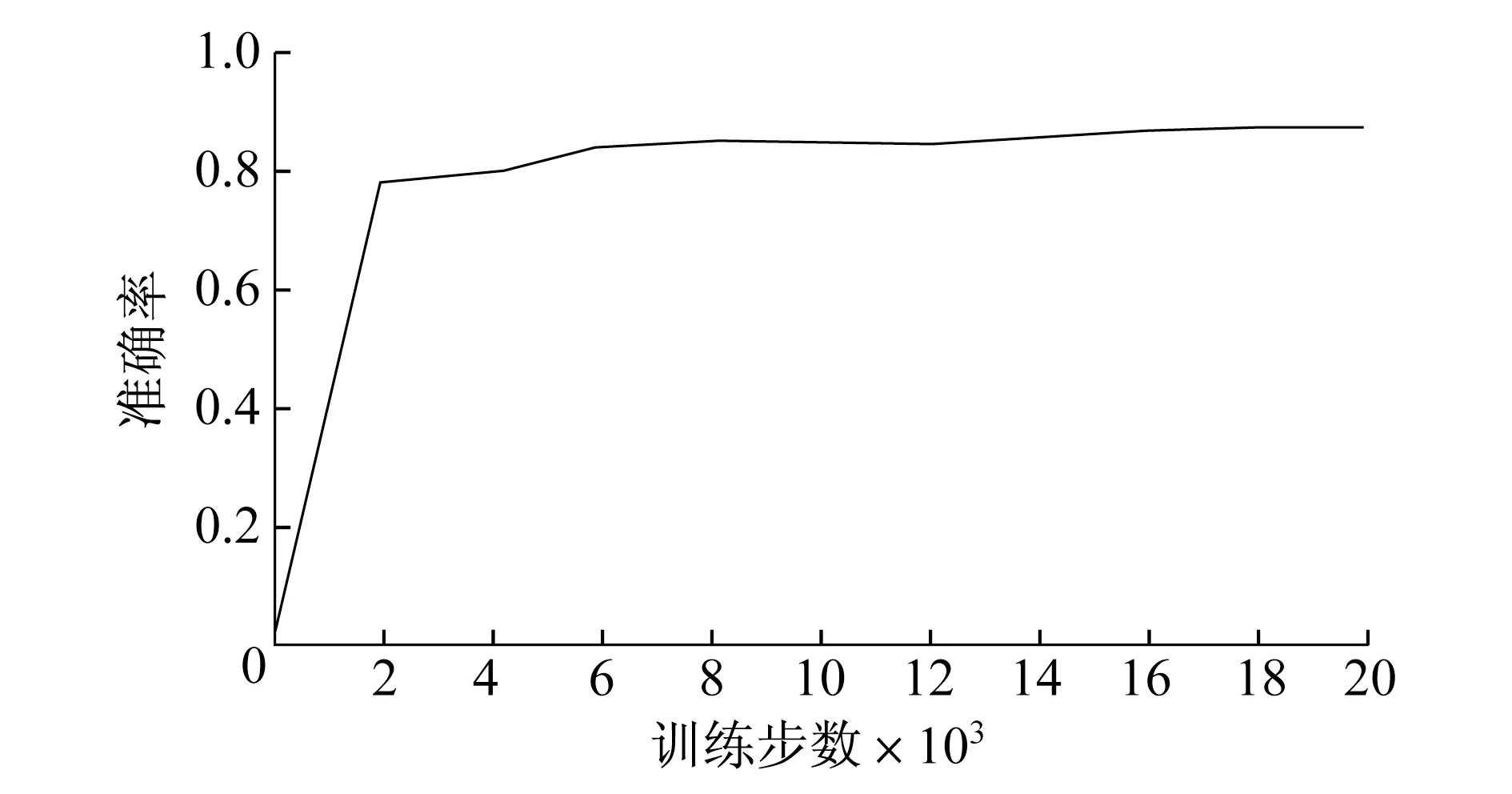
图9 弱光下坑洼的平均精度随训练步数的变化趋势
图10 为混合坑洼模型预测强光下坑洼图片的样例,图11 为本算法强光下坑洼预测的单张图片样例.与本算法相比,在混合坑洼训练结果中存在误检.图12 为混合坑洼模型预测弱光下坑洼图片的样例,图13 为本算法预测弱光下坑洼图片的样例.相比本算法,混合坑洼模型在此情景下无法检测出坑洼,而本算法能够检测出坑洼的具体位置.

图10 混合坑洼模型预测强光坑洼

图11 本算法模型预测强光坑洼

图12 混合坑洼模型预测弱光坑洼

图13 本算法模型预测弱光坑洼
4 结 论
本文作者建立了坑洼的多场景分类数据集,同时建立了坑洼检测的数据集.利用inception_v1 算法架构对数据进行训练,得到了多场景的分类模型,并经过坑洼检测模型,检测出坑洼的具体位置.从实验结果可以看出,本算法对坑洼检测的效果好于直接混合坑洼模型的检测结果.
