基于TF-IDF与word2vec的台词文本分类研究
2020-04-09但宇豪黄继风
但宇豪,黄继风,杨 琳,高 海
(1.上海师范大学信息与机电工程学院,上海201418;2.上海计算机软件技术开发中心,上海201112;3.上海高创电脑技术工程有限公司,上海200030)
1 相关研究
文本分类就是构造分类方法,并使用该方法将待分类文本分到预定类别中的某一类.假设待分类文本集合D 中有j个待分类文本,D={d1'd2'…'dj},预定类别集合C 中有m 个待分类别,C={C1'C2'…'Cm}.分类器为D中的每个文本文件从C中选取一个可能性最大的分类作为其类别.
在文本分类问题中,常用的特征提取方法包括:词频-逆文本频率(TF-IDF)、信息增益、χ2统计、互信息以及one-hot编码等方法.由于与其他方法相比,词频-逆文本频率(TF-IDF)算法分类效果较好,其还具有实现便捷且易于改进的优点,本研究将其选作文本的特征提取方法.
考虑到待分类的健康节目台词文本包含一些长度较短的文本,为解决特征稀疏问题,需对这些文本进行特征扩展.胡朝举等[1]使用Latent Dirichlet Allocation(LDA)模型提取文本主题,并将其作为扩展信息加入文本特征,实现特征扩展.但健康节目台词文本数据的语义信息较为分散,且部分样本数据较为稀疏,因此LDA模型并不能很好地表达其特征.赵旭等[2]和苏小康[3]通过引入外部语料库的语义信息进行特征扩展.其中,苏小康[3]所使用的维基百科中文语料库中包含大量医学及生活方面的语料内容,与健康节目台词文本的主题一致.薛炜明等[4]采用word2vec 模型进行语义扩展,该方法将词语映射到“紧凑”的向量空间中,不仅同时适用于长文本与短文本,还有助于缓解文本特征向量的稀疏性问题.
本文作者提出运用改进的词频-逆文本频率(TF-IDF)算法及word2vec模型进行文本文件表示,并采用维基百科中文语料库引入扩展的语义信息,实现对健康节目台词文本的有效分类.
2 相关算法及模型
文中所提到的词语ti是某文本文件dj中的第i个词,特征词wi是语料库中所有词语ti所组成的并集中的第i个词.特征词wi之间互不相同,与某特征词wi所对应的相同词语可能在语料库中多次出现.
2.1 word2vec模型
word2vec 模型是现阶段自然语言处理领域中用于生成词向量的首选模型.MIKOLOV 等[5]简化神经网络语言模型(NNLM)[6]结构后,提出了更高效的word2vec模型.该模型将词语映射到一个实数向量空间,每个词向量的长度为100~200维,克服了由词袋模型生成的向量过长而造成的稀疏问题.此外,使用word2vec模型产生的词向量不仅蕴含词语本身的信息,其在向量空间中的位置还蕴含了相关词语间的语义关系信息.词偏移技术可通过对词向量做相加减的方式实现对其语义的加减操作.由于采用word2vec 生成的两个词向量在向量空间中的距离越相近,所代表的词语在语义上就越相似,可以通过计算余弦相似度或欧几里得距离的方式计算两个词语的语义相似程度.本文作者采用Continuous Bagof-Words(CBOW)模型,将维基百科中文语料库放入模型训练,扩充模型的语义信息,从而获得特定语义环境下各词语的词向量.
2.2 词频-逆文本频率(TF-IDF)算法
TF-IDF 算法是一种统计方法,常被用来确定文本特征词权重,已被广泛用于文本分类领域.TF 代表词频,表示某特征词在某文本文件中的出现次数,其定义为:

其中,nw是特征词w在文本文件中的出现次数;N为该文本文件中特征词的数量;TF为衡量特征词在文本中重要程度的指标.
IDF代表逆向文件概率,其定义为:

其中,D 是所有文本文件的总数;Q 是包含特征词的文本文件数量;IDF为衡量特征词在所有文本文件中重要程度的指标.
将式(1),(2)相乘,可得文本特征词权重

2.3 word2vec均值模型
word2vec均值模型是一种文本文件表示方法,用以表征文本文件内容.word2vec均值模型将某文本文件中每一个词语所对应的词向量求和平均后,以此来表征文本文件内容.假设词t 的词向量为fwtv(t),则

其中,Vec(d)表示用以表征文本文件d的向量;n为d中所包含的词语数量.
2.4 支持向量机(SVM)分类器
SVM 分类器是线性分类器中的一种,具有简单高效的优点.SVM 分类器将线性不可分的样本通过核函数映射到高维空间,并最小化损失函数,找到最优的分割平面,完成对样本的分类.采用scikitlearn算法实现SVM分类器功能,采用高斯核作为核函数,采用hinge loss[7]作为损失函数.
3 改进算法
TF-IDF 算法是常用的确定特征词权重的方法,然而,对于监督学习下的文本分类问题,已标记的语料库中包含特征词的重要程度信息,TF-IDF 算法并没有将这些信息考虑在内,因此,需要对原TFIDF算法进行改进.
3.1 含有信息熵的TF-IDF(TF-IDFE)算法
“信息熵”是量化衡量信息量的指标,用以衡量各特征词的重要性,其表达式如下:

其中,pci是特征词wi在属于c 类的语料中出现的概率,可通过特征词wi在某类语料中的出现次数c(wci)与其在所有类别语料中出现的总次数c(wi)的比值表示:

采用归一化的方法得到特征词wi的正则化信息熵项

其中,Emax=max(E(wi));Emin=min(E(wi)).带有信息熵的TF-IDF算法计算公式为:


3.2 含有信息熵及修正因子的TF-IDF(TF-IDFRE)算法
考虑到使用式(6)计算词语信息熵时,算法倾向于“忽略”对样本数较小的类别重要的特征词,因此引入一个修正因子,平衡各类别中特征词的重要性.引入的修正因子的表达式如下:

其中,c(wc)表示c 类样本中的总词语数;λ 是可调系数.将此修正因子乘以原信息熵公式E(wi)可得修正后的信息熵公式:

将式(11)代入式(7),并在计算式(8)和(9)后将得到的向量再次置于SVM分类器训练.
3.3 算法流程图
从台词文本的分类角度考虑,根据健康节目内容主题相关的人体器官部位对采集到的台词文本进行分类.所提出的方法先对维基百科中文语料库、训练集数据及测试集数据进行预处理,然后运用维基百科中文语料库生成词向量模型CBOW,并使用改进的TF-IDF 算法确定训练集及测试集中的特征词权重,通过相乘调整各词向量在word2vec均值模型中所占有的权重,采用SVM分类器训练数据,达到分类目的.算法流程图如图1所示.

图1 算法流程图
4 实验及结果分析
4.1 模型性能评价指标
评价分类模型性能的通用指标为准确率(Precision)、召回率(Recall)及F值(F-Measure).
准确率为被正确分类的样本数(TP)与总样本数的比值,其计算公式为:

其中,FP为实际不属于该类却被错误分入该类的样本数.
召回率为被正确分类的样本数与实际属于该类的样本总数的比值,其计算公式为:

其中,FN为实际属于该类却未被正确分类的样本数.
F值是一种综合考虑了上述两种评价指标的混合评价指标,其计算公式为:

4.2 实验设置
实验部分所使用的计算机操作系统为Mac OS 10.14.6,处理器为Intel Core i7,内存16 GB,编程环境为Python 3.7.3.
实验所采用的数据集由网络爬虫软件收集,对视频进行录音,并采用线上开源的语音转换工具将录音转换为台词文本保存在本地.
实验数据集共包含4 635期健康节目的台词文本,原始健康节目视频的时长为5~50 min,转换后,每个文本文件包含80~5 000 bit的台词文本.由于采用SVM 分类器的分类方法属于监督学习,通过人工标记的方法对采集得到的健康节目视频所对应的台词文本进行标注.选取了5 个常见人体部位作为分类类别,并将不属于这5个类别及包含多个类别的样本作为“其他”类标记,如表1所示.

表1 分类名称及样本数量
数据预处理步骤如下:
(1)采用gensim 工具的wikicorpus 库从原始格式为XML 的维基百科中文语料库中提取语料文本,采用opencc软件将语料库中的繁体字转换为简体字.
(2)采用jieba 工具的“精确模式”对数据集及维基百科中文语料库进行分词,并去除其中的标点符号与停用词.(3)利用维基百科中文语料库训练word2vec下的CBOW模型,词向量维度设置为200.(4)按照4 ∶1的比例将数据集划分为训练集与测试集.
4.3 模型性能评估
模型性能评估部分展示了使用word2vec的均值、TF-IDF、TF-IDFE及TF-IDFRE算法的分类结果.表2展示了四个模型的平均结果,表3~6分别展示了各分类器在各类别上的详细结果.

表2 采用各方法分类后的平均结果
从表2 可看出:使用TF-IDF 算法与均值算法相比,准确率提高了2.7%;采用TF-IDFE算法,准确率提升5%;采用TF-IDFRE算法,相比使用TF-IDF与均值算法,准确率分别提高了4.6%及7.3%.

表3 均值算法分类的实验结果
观察表3 可发现,在使用均值算法分类的情况下,C5类的准确率及召回率都远低于其他类别,这是由于在没有进行加权操作的情况下,样本数小的类易被分类器“忽略”.

表4 TF-IDF算法分类的结果
通过对比表3,4可以发现,引入TF-IDF算法进行加权后,C5类的分类准确率提高了11.9%,召回率提高了3.7%,这表明加权操作对于抑制数据不平衡造成的不良影响有一定抑制效果.

表5 TF-IDFE算法分类的结果
通过对比表4,5可以发现,使用TF-IDFE算法与使用原始的TF-IDF算法相比,C5类的分类准确率提升了6%,召回率提升了4.9%.虽然两项指标都有一定提升,但召回率为32.6%,依然较低,这说明具有小样本数量的类别依然易被分类器“忽略”.

表6 TF-IDFRE算法分类的结果(λ=3)
比较表5,6 可以发现,与加入修正因子前比较,C5类的召回率提升了34.1%,总召回率提升了7.7%.这说明通过TF-IDFRE算法加权的word2vec 均值模型,可有效缓解各类别之间样本数量及样本间词数的不平衡对分类准确率及召回率的不良影响.
实验表明,TF-IDFRE算法的各项指标都优于其他算法,可实现对健康节目台词文本的有效分类.
4.4 参数调节
通过改变λ 的取值,探究其与准确率之间的关系,如图2 所示.随着λ 取值的增大,平均准确率呈现先上升后下降的趋势.当λ=3时,平均准确率为88.5%,达到最好.
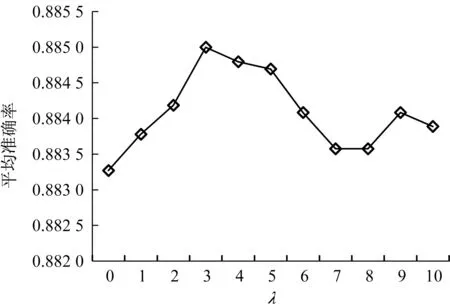
图2 取值与准确率关系图
5 结 论
本文作者探索了健康节目台词文本的分类问题,在采用TF-IDF加权算法的word2vec均值模型上进行优化,通过引入信息熵,提出了采用TF-IDFE加权算法的word2vec 均值模型,提高了分类准确性.在此基础上加入修正因子,提出采用TF-IDFRE加权算法的word2vec均值模型,缓解各类别间样本数量及样本间词数的不平衡对分类准确率及召回率所造成的不良影响.实验表明,所提出的算法能实现对健康节目台词文本的有效分类.
