科研论文基金项目“一文多注”和不实标注研究
2020-04-06叶文豪洪磊唐梦嘉张逸勤
叶文豪 洪磊 唐梦嘉 张逸勤


摘 要:学术期刊数据库的建设为科研论文标注基金的深入研究提供了条件。文章以国家社科基金项目为例,从CNKI数据库获取了基金项目的论文成果,对这些论文的基金标注情况进行了统计分析。采用Word2vec模型计算了论文与标注基金研究内容的相关性,并结合人工,识别出基金不实标注的现象。结果表明,论文一文多注的情况较为常见;在基金不实标注的数据中,重大项目和重点项目作为高学术影响力的项目被不实标注的比例较高。
关键词:科研论文;国家社科基金;一文多注;基金不实标注
Abstract The construction of the academic journal database provides possibility for in-depth research on the labeling of fund projects in scientific papers. In this research, the National Social Science Fund projects and the papers which labeled these fund projects were obtained from the CNKI database, and a statistical analysis was carried out on the fund labeling of these papers. Word2vec model was used to calculate the similarity of the research content between the paper and its labeled funds. Two human annotate teams were organized to make further identification of the false labeling of funds. The results show that it is common for papers to label multiple funds. Among the false labeling examples, the proportion of major projects and key projects are considerably higher.
Key words scientific paper; National Social Science Fund Projects; multiple labeling; false labeling
1 引言
自我国科学基金制度建立以来,国家不断完善资助体系,逐年提高资助经费,大力资助高等院校和科研机构科研工作者开展研究。目前已形成包括国家自然科学基金、国家哲学社科基金及其他省部级基金资助的基金资助体系,对學术理论创新起着支撑性作用,对推动经济、社会发展的实践应用也具有指导意义。基金资助课题通常代表了某学科领域内的研究热点或研究前沿,基金项目立项需要经过较为严格的程序,要求产出较高水准的论著。因此,各类基金成果论文凭借自身较高的学术价值和较大的影响力赢得学术期刊的青睐。2008年《中文核心期刊要目总览》将“基金论文比”引入期刊评价中。然而一旦被作为评价指标,就会存在被人为操纵的情况。许多期刊纷纷为基金论文开辟绿色通道,以吸引基金论文投稿。
“基金论文比”这项指标是考察期刊所刊载论文得到基金项目资助的比例,许多期刊评价体系将其作为考察期刊学术影响的重要指标之一。另一方面,各基金项目管理机构要求项目成果必须标注基金资助信息。所以,学术期刊重视基金资助论文,有的期刊甚至歧视非基金资助论文。同样,基金项目承担者为了完成项目,只要完成了论文,不论是否与项目主题关联,均标注上自己承担的项目,有的甚至把同事间的非相关基金项目都标注上,使得论文基金标注的真实性难以考证,由此带来了论文基金项目不实标注的不正之风。一些学者为提高论文录用几率,在其论文成果中不实标注基金项目。韩磊和邱源[1]在研究中发现除了论文作者主动的基金不实标注行为,还存在期刊为了自身评比的需要,暗示作者为论文用其他不相关基金项目挂名的行为。基金项目不实标注严重影响了发表论文的真实性与公平性,极度不利于学术的发展。
论文是基金项目的主要成果形式,因此论文产出情况是量化评价基金项目实施情况的主要指标之一。科学项目成果中存在填报不实成果的做法(如用其他论文或他人论文充数、随意拔高研究成果水平或成果多头交账的情况)。成果多头交账可能导致科学基金重复资助问题,不利于科学基金发展规划总体布局和目标实现。
针对存在问题,本文以国家社科基金项目为例,结合计算基金标题与资助论文题录信息的文本相似度与人工判别方法,判断论文与其标注的基金在研究内容上是否大致相同。识别科研论文基金标注过程中出现的问题,鉴别学术不端行为,旨在让我国科研环境更加公平公正;使我国科学基金的投向更趋合理,取得更好的实际使用效益,为我国未来社会和经济发展提供动力。
2 相关文献
在国家对科研投入不断增长的背景下,设立不同层次和类型的科学研究基金已成为国家推动科技事业发展的重要方式。科技论文是科研基金项目重要的研究成果产出,而论文科学基金的标注可以反映科技投入、分配与产出关系等重要信息[2]。基金论文代表着研究领域发展的动向,同时也反映学科的科技基金资助情况。因此,科学基金标注在一定程度上可以体现论文的学术水平。针对以科学基金评价学者、以科学基金表现论文水平的现象,众多学者从标注不端行为产生的原因和解决方法两方面对科学基金规范化标注进行了详细研究。
2.1 科学基金项目标注问题产生的原因
针对科学基金项目标注问题产生的原因,学者从编辑部、论文作者和科学基金三个层面进行探索。在编辑部层面,期刊质量评价体系中强调发表基金项目尤其是国家级基金项目论文,“基金论文比”这一重要指标引导了编辑在初审时对基金资助项目稿件的盲目追求[3];同时编辑部对基金项目信息的审核不严也导致虚假标注的现象层出不穷,如编造、挂靠、牵强等情况[4]。在论文作者层面,科技论文作者数量多、所属科研单位复杂等署名与基金存在的问题无形中使需要标注的基金数目增多,将科学基金项目标注复杂化,容易出现署名学术不端、问题推诿、重复资助等情况[5];部分作者自律意识淡薄,还存在编造虚假基金项目、挂名发表等不实标注的行为来提高科研论文的分量、增加录取的可能性[6]。在基金层面,由于基金资助存在马太效应,科研项目的高度集中带来了科研垄断的隐患,造成了论文中科研基金扎堆的现象[7]。同一项目接受不同科研基金的重复赞助也导致科技资源分配不公、利用效率低下,严重影响了科研人员工作积极性[8]。
2.2 解决科学基金标注问题的方法
在上述研究的基础上,学者从数据库的完善、标注规范思想的建立和人工智能方法三个层面来探索解决科学基金标注问题的方法。在数据库层面,众多数据库的构建和完善促进了科技论文的数字化,增加了论文发表的透明度,使作者对科学基金标注更加谨慎。近年来,Web of Science哲社核心数据库[9]、超星数据[10]、CNKI数据库[11]、CSSCI数据库[12]的不断更新和完善为学者对科技论文相关信息进行深度挖掘、归纳和分析提供便利,使得学者对科学基金标注问题的深入研究有了新的思路。苗亚静[13]提出通过加强各类基金资助机构之间的信息共享来强化对科技论文和科学基金标注的审核。在标注规范思想层面,陈沙沙和刘春平[14]通过规范化科学基金项目著录标准,提高了标注的科学性。白雪娜等[15]通过人工查询核实了209个国家基金项目的178篇论文,发现同一项目在多篇论文中随意挂靠的现象较为普遍,提出了编辑人员应严格审查项目、提高对基金项目编号的甄别能力等要求。同时在人工智能方法层面,随着自然语言处理技术的不断发展,苏新宁和王东波[16]提出通过数据驱动探究学术研究的规律,运用人工智能方法对科技论文进行信息抽取、深入而精确地挖掘学术文献的多维度信息。叶文豪等[17]通过计算余弦相似度发现存在科学基金与论文主题不符的现象,基于孪生网络模型构建了科学基金与论文相关性判别模型来抑制基金不实标注行为。
3 数据来源与分析
3.1 数据源简介
由于基金在文章中没有统一的著录标准,基金字段存在多种不同格式,大多数没有标注出“基金类型‘基金名称[基金号]”的完整信息。在数据抓取过程中为保证检索结果可靠性,本文以基金批准号作为唯一检索条件进行基金成果论文检索。首先,通过编写网络爬虫抓取了“国家社科基金项目数据库”中自2014年开始,截至到2018年的23个学科的社科基金重大項目、重点项目、一般项目和青年项目,共计20325项。基金项目信息主要包括项目批准号、项目负责人、项目类别、学科分类、项目名称、立项与结项时间等。利用获取到的基金项目批准号在《中国学术期刊(网络版)》(中国学术期刊全文数据库)中,通过“支持基金”字段,选择精确匹配检索模式进行论文信息检索,获取由社科基金项目资助的论文的题录信息。时间跨度为 2014年至 2019 年 7月。对检索结果中被多个基金重复资助的论文去重后得到文献80762篇,对应的资助基金项目共14894项。本文统计了2014-2018年23个学科的国家社科基金项目立项数和已发表论文成果的项目数量(见图1),汇总了各个学科国家社科基金资助的论文成果数量(见表1)。
3.2 论文标注基金项目现状分析
中国知网的学术期刊全文数据库中提供了论文的基金信息,为研究论文的基金不实标注情况提供了条件。首先归纳不同类型基金项目批准号的编码规范。如以国家社科基金为例:国家社科基金项目批准号的规范为:“两位数字+一位项目类型代码+两位学科代码+三位数字序号”。前两位数字表示项目立项年份,项目类型代码为[ A, B, C, X, F, W, K ],分别代表重点项目、一般项目、青年项目、西部项目、后期资助项目、中华学术外译项目和成果文库。此外重大项目采用“ZD”代码表示(**ZDA***),存在部分没标明学科的重点项目采用“ZD”代码替代学科类别代码(**AZD***)。
在对数据的观察过程中发现,江苏省社科基金项目批准号采用与国家社科基金项目批准号一致的学科代码,项目批准号也采用“两位数字+三位字母+三位数字”的编码规范,用三位字母中的前两位表示学科代码以区分国家社科基金项目批准号。并且部分地方社科基金项目批准号与国家社科基金项目批准号存在冲突的情况,包括湖南省社科基金项目,广西哲学社会科学规划项目,山东省社科基金项目,新疆维吾尔自治区社科项目,辽宁省社科规划基金项目,西藏自治区哲学社会科学,河南省哲学社会科学规划项目等。由于目前各大期刊数据库建设日益健全,项目批准号冲突的情况会导致科研人员在检索论文或进行学术评价时发生误检,影响了检索效果。
然后采用正则表达式从获取的成果论文的基金字段中抽取出基金项目批准号,基金项目批准号抽取过程如下:
步骤1:去除中文及标点,仅保留数字、字母与部分符号;
步骤2:去除连续字母和5位以下连续数字,得到所有类型的项目批准号,并统计数量;
步骤3:获取“两位数字+三位字母+三位数字”格式的项目批准号;
步骤4:根据项目类型代码和学科代码删除江苏省社科基金,并统计剩余项目批准号数量;
步骤5:统计基金详情中“国家社*|国家哲学|全国哲学”等Patten的出现次数,与步骤4统计的项目批准号数量进行校对;
步骤6:步骤5中数量不一致的条目,通过人工校对的方式筛选出国家社科基金项目批准号。
对论文标注基金项目的数量进行统计(见表2),可以看到经济与管理科学的论文成果倾向于标注多个基金,管理学标注一个基金的论文占该学科全部论文成果的比重为38%,应用经济与统计学占比均为39%,理论经济占比42%。其中应用经济与管理学标注6个以上基金项目的论文数量也达到200篇以上。
国家社科基金的“一文多注”现象所占比例相较所有基金类型有大幅度降低,因为国家社科基金项目代表着各学科最新兴的研究方向,基金项目的立项需要经过严格的专家评审,即使在同一学科所申请的项目,其两两之间的研究主题差别也较大,因此部分学术期刊在投稿要求中明确表示不允许同时标注两个及以上国家社科基金项目号。在统计的标准国家社科基金论文中仍有6129篇论文(去除学科之間重复项)标注了两个以上国家社科基金,标注基金项目数量最多达到5项。针对这些“一文多注”的论文,笔者统计了所标注国家社科基金之间立项时间的最大年份间隔(见图2)。其中标注的基金间隔一年的最多,有2130篇;其次为间隔两年,有1374篇;标注同一年立项的国家社科基金项目的论文数量排第三,为1113篇。标注基金批准号“98ASH001”的4篇论文是年份间隔最大的论文,通过查询基金字段的详情得出,其原因是该项目为国家社科基金重大滚动项目。
笔者采用Vosviewer软件将国家社科基金项目共同资助情况以关系图的形式呈现出来(见图3),图中用节点大小表示各个学科的共同资助数量(包括同一学科项目之间共同资助),不同学科之间的共同资助数量用边的粗细表征,节点采用不同颜色表明学科之间的聚类情况。由图可以看出各个学科根据共同资助的情况主要聚成4个类,应用经济、管理学和理论经济项目共同资助的情况最为常见,同一学科内的项目共同资助数量分别达到390次、281次和155次,应用经济与理论经济、管理学之间的共同资助数量为203次和200次。此外,语言学、社会学、马列·科社、体育学等学科,学科内共同资助数量较多,从总体上看,学科内的共同资助比学科间的共同资助多。
使用热力图呈现出不同类型基金项目之间共同资助一篇论文的情况(见图4),可以发现,学者发表论文时倾向于将重大项目与其他项目共同标注,这可能是因为重大项目研究内容是各学科的基础,意义重大,影响深远。同时,与其他类型项目相比,重大项目规模更大,涵盖的研究内容更广,容易与其他类型项目研究内容产生重叠。
4 研究论文与标注的基金情况分析
为探究研究论文与其标注的基金项目研究内容之间的相关性,判别科研论文发表过程中是否存在基金不实标注的问题,笔者探索了文本相似度方法在本研究中的应用。根据抓取的数据源,基金项目的大致研究内容只能通过项目标题呈现,论文成果的研究内容可以通过标题、摘要和关键词体现。
4.1 word2vec 模型
Word2vec[18]是Mikolov于2013年提出的一种神经语言模型,使用Skip-Gram模型或Continuous Bag of Words(CBOW)模型预测上下文和中心词是否共现,能够充分捕获词的上下文语义、语法信息。传统的词袋模型假设特征词两两之间独立,在面对数据稀疏问题时不能很好地判定句子之间语义相关性。Word2vec模型将词汇表示为定长分布式向量的形式,词汇之间的语义相似度可以通过向量之间的距离或夹角余弦值衡量。本文以腾讯AI Lab提供的开源中文词向量作为预训练词向量[19],将获取到的国家社科基金项目标题与受资助论文标题、摘要、关键词等题录信息作为训练语料,采用结巴分词工具进行分词,并使用Skip-Gram模型将本文获取的语料在腾讯词向量的基础上进行fine-tune训练,得到进一步研究的领域词向量。
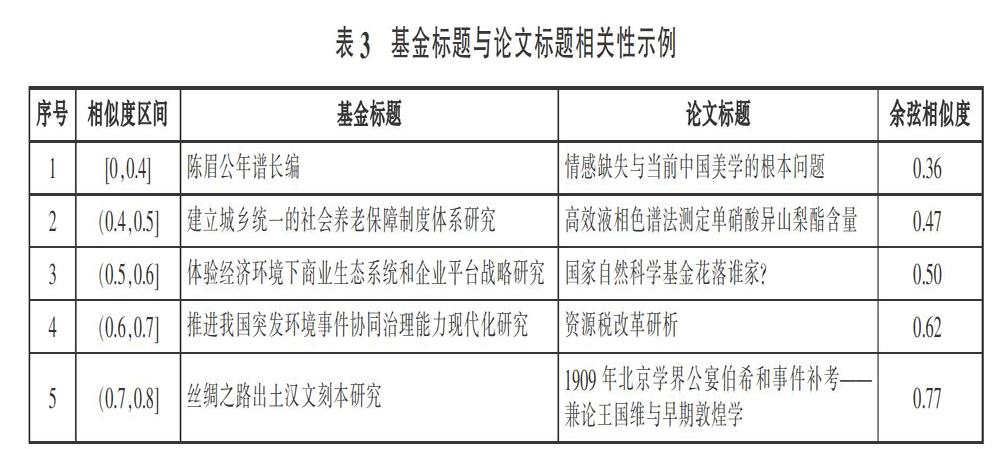
本文进一步将基金项目标题与受资助论文标题、摘要、关键词等信息通过词向量表示为分布式向量形式,利用余弦相似度公式计算向量之间的相似度,得到了受资助论文与社科基金之间的相关性,并展示了不同相似度区间中基金标题与论文标题的相关性示例(见表3)。
从表3各个相似度区间的示例可以看出,分布式词向量对语义的理解较为充分,从第5行的结果来看,分布式词向量规避了传统词袋模型的独立性假设,能够可靠地表达句子之间的语义相似度。从第2行中的论文标题来看,这篇论文属于自然科学研究范畴,与本文的数据来源——国家社科基金资助的社会科学论文成果差异明显。为确保数据获取过程中不存在错误,笔者追溯原始数据发现这篇论文的基金字段注明“国家自然科学基金资助项目(17BSH044)”。然而该项目批准号与国家自然科学基金编码格式不相符,且笔者通过该项目批准号在“国家自然科学基金管理信息系统”中检索不到项目信息,初步判定该论文基金项目标注错误,致使本研究在数据抓取过程中,根据项目批准号匹配到了2017年社会学国家社科基金一般项目“建立城乡统一的社会养老保障制度体系研究”。实验结果表明,借助Word2vec文本相似度方法能够计算出论文与所标注基金项目的相关性,进而为判断基金不实标注的情况提供依据。
4.2 国家社科基金“一文多注”研究
很多学者在基金标注规范研究中探讨过“一文多注”现象,目前论文发表普遍存在“一文多注”的现象,即大多数论文在投稿时标注了多个基金资助项目。分析这一现象的成因,一方面体现了科研合作与交流普遍存在,另一方面,也反映出可能存在基金重复资助或基金项目号不实标注的情况。针对国家社科基金项目“一文多注”的情况,笔者筛选出标注了两个以上国家社科基金资助的论文。考虑到检测出基金不实标注可能造成的社会影响,本研究首先根据分布式词向量计算论文题录信息与基金标题的语义相似度,再通过人工校验确保结果的可靠性。
本文选择6129篇标注了两个以上国家社科基金的论文,这些论文共形成了12750条论文与基金项目的标注关系。存在部分项目信息没有收录在国家社科基金项目数据库中,因此能查阅到项目批准号对应项目标题的数据有12188条,选择其中出现两次以上的论文数据进行人工判别,共11660条。为避免人工判别的主观性,本研究组织了两名博士研究生和两名本科生分成两组独立进行评判工作,然后比对两组评判结果,只保留意见一致的结果。
人工评判遵循以下三条标准:
(1)论文内容与标注的基金项目研究内容是否存在差异;
(2)一篇论文标注的几个基金项目之间研究内容是否存在差异;
(3)标注了同一个基金项目的不同论文之间研究内容是否存在差异。
最终得到410条论文-基金数据存在研究内容不一致的情況,涉及到278篇论文和283个基金项目,存在部分论文与标注的多个基金项目在研究内容上不相关,部分基金项目被多篇不相关的论文标注。
本文节选了部分论文与标注的基金项目研究内容不相关数据示例(见表4)。在278篇论文中,有120篇论文与标注的基金项目研究内容都存在差异,称为集合A;有158篇论文与标注的部分基金项目在研究内容上相近,部分基金项目研究内容有差异,称为集合B。
在集合A的论文中笔者发现一篇文章的基金字段标注了“国家哲学社会科学课题青年项目“边疆民族地区基层社会治理创新实践与规范化建设研究”(15CJL049)”,而“15CJL049”实际是项目“垂直专业化背景下中国制造业国内技术含量的动态变化及影响因素研究”的批准号,呼吁作者投稿和编辑部审稿过程中需要仔细检查这类书写错误。并且在这120篇论文中绝大多数在基金字段都只标注了项目类型和项目批准号,没有标注项目名称,笔者无法根据作者提供的信息判断是否为书写错误。
集合B中的论文标注了研究内容相近的基金项目,同时标注了存在差异的基金项目,笔者认为这充分说明作者存在标注不实基金的主观意图。对这部分存在差异的基金项目类型统计得到:一般项目67项,青年项目37项,重点项目28项,重大项目27项。考虑到每年的一般项目和青年项目立项数远高于重点项目和重大项目,证明了学者在投稿时为了提高录用概率,标注重点和重大项目等有影响力的项目以拔高论文水平的现象确实存在。
5 总结与讨论
本文以2014-2018年的国家社科基金项目为例,采用网络爬虫抓取了基金项目的论文成果,通过实证研究探索了论文中基金项目的“一文多注”和不实标注情况。“一文多注”的情况目前较为常见,主要体现在标注不同等级的基金项目,同时标注多项国家社科基金项目的论文比例相对减少,占比7.6%。“一文多注”情况呈现出明显的学科差异,经济与管理学科较为常见。从国家社科基金项目类型来看,重大项目与其他类型项目共同标注较多。随着人工智能技术的进展,深度学习模型已经能够较好的识别语义。Word2vec模型的实验结果表明,仅通过自动化模型已经能识别论文与所标注基金项目研究内容存在的差异。但基金不实标注与其他学术不端行为相比更具隐蔽性,基金标注的真实性需要付出大量精力进行考证,呼吁学者在投稿时不要出现这类投机行为。期刊编辑部在审稿过程中应重视基金项目的审核,确保作者填写完整的基金信息。同时,相关部门应加大力度建设、完善相应基金项目数据库,国家与地方各级基金项目统筹管理,项目批准号作为基金项目的唯一标识符不应出现不同项目共用的现象。
参考文献:
[1] 韩磊,邱源.学术期刊须警惕基金论文中基金项目不实标注现象[J].编辑学报,2017,29(2):151-154.
[2] 陈晓文,屈宝强,刘蔚,等.基于论文著录信息的基金类别共现分析[J].中华医学图书情报杂志,2018,27(12):50-57.
[3] 金伟.科技期刊论文基金项目标注的混乱性、真实性问题[J].辽宁师范大学学报(自然科学版),2014,37(4):547-550.
[4] 王楚鸿.科技论文“一文多注(标注)”现象分析[J].科学学研究,2009,27(5):711-715.
[5] 蓝永洪.科技论文中成果所属作者、单位、基金和作者贡献标注的探讨[J].科技视界,2018(36):53-54.
[6] 王小艳.科技论文基金项目标注不实分析及对策[J].中国科技期刊研究,2014,25(7):954-957,974.
[7] 赵丽莹,杨波,张荣丽,等.关于科技论文多项基金标注的几点建议[J].中国科技期刊研究,2009,20(4):729-731.
[8] 古继宝,周捷,梁樑.科技论文资助重复率统计分析与形成机制研究[J].科学学与科学技术管理,2008(9):24-28.
[9] 杨敏敏,Gretchen McAllister.国际学界“一带一路”研究的热词与最前沿——基于Web of Science(2014-2018)的文本计量与细读[J].西南民族大学学报(人文社科版),2020,41(5):234-240.
[10] 李宗刚,谢慧聪.70年来《鲁迅全集》注释研究热点与前沿动态分析——基于1949-2018年超星数据的分析[J].西南民族大学学报(人文社科版),2020,41(4):229-235.
[11] 洪磊,王昊.公安情报研究现状及热点分析——基于CNKI期刊论文的计量学和关键词聚类研究[J].西南民族大学学报(人文社科版),2019,40(7):234-240.
[12] 贾文龙.新世纪以来国内高校图书馆研究领域的全景回顾及未来展望——基于CSSCI来源期刊(2000-2017)的知识图谱分析[J].西南民族大学学报(人文社科版),2019,40(8):233-240.
[13] 苗亚静.科技论文中基金项目多重标注归因分析及对策研究[J].宝鸡文理学院学报(社会科学版),2013,33(4):109-112.
[14] 陈沙沙,刘春平.关于学术期刊论文基金项目著录的编辑问题[J].编辑学报,2008(3):231-232.
[15] 白雪娜,张辉玲,黄修杰.科技论文基金项目标注的不端行为及防范对策研究——基于178篇论文标注209个国家自然科学基金项目的实证分析[J].编辑学报,2017,29(3):260-264.
[16] 苏新宁,王东波.学术评价相关问题与思考[J].信息资源管理学报,2018,8(3):4-11.
[17] 叶文豪,王东波,沈思,等.基于孪生网络的基金与受资助论文相关性判别模型构建研究[J].情报学报,2020,39(6):609-618.
[18] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].arXiv preprint arXiv:1301.3781,2013.
[19] Song Y,Shi S,Li J,et al.Directional Skip-Gram: Explicitly Distinguishing Left and Right Context for Word Embeddings[C].Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2018:175-180.
作者簡介:叶文豪(1994-),男,南京大学信息管理学院、江苏省数据工程与知识服务重点实验室博士研究生,研究方向:文本挖掘;洪磊(1988-),男,南京大学信息管理学院博士研究生,讲师,研究方向:安全情报和数据挖掘;唐梦嘉(1997-),女,南京农业大学信息管理学院本科生;张逸勤(2000-),女,南京农业大学信息管理学院本科生。
