基于预训练BERT模型的客服工单自动分类研究
2020-03-27任莹
任莹
(昆明能讯科技有限责任公司,昆明 650217)
0 前言
电网企业业务复杂,企业生产经营中有大量的半结构、非结构化的文本数据,电网企业生产经营过程中有大量的文本数据,涉及到电子、化学、机械、信息等多种专业领域,例如电力中的检修报告中包含了专业设备有关机械、化学、物理、电子等多个专业领域,涉及到多种专业的知识。此类文本数据属于低密度价值数据,存在数据量大、结构复杂、缺乏规范等特点,是目前数据分析和挖掘的难点区域之一。
电力客服95598 工单就属于这种典型数据,这类文本数据中主要采用口语化的描述形式,记录了大量的电力业务特性,但同时文本中也包含了很多电力专业术语,这类文本数据的格式不统一,内容差异较大,目前主要通过坐席人员的判断对工单内容进行处理和分类,由于依靠人工的经验,导致处理及时性较低,分类规则不一致,不能有效发现客户的真实诉求。因此急需一种有效的文本数据挖掘方法,能够自动对工单进行自动分类,并进一步挖掘客户的潜在诉求,对营销客服水平的提升具有重要的意义。
人工智能、文本挖掘技术逐渐被应用到电力的各种场景中,马润泽[1]等采用基于KNN算法对缺陷文本进行归类计算,构建断路器状态综合评价模型。刘兴平[2]等通过引人LDA 主题生成模型,结合工单内容构建工单文本挖掘模型对工单进行筛选、判断和归类。邹云峰[3]等通过建立95598 工单自动分类模型,实现工单快速分类,挖掘其中的重要信息,为分析用户的诉求提供依据。总体而言,目前对于电力文本数据的研究大多基于传统机器学习分类模型,由于缺乏大量的电力业务样本数据,电力文本分类的准确性都不高,适用范围较窄。
本文针对电力客服工单数据的特点,围绕自然语言处理应用中的关键技术和核心算法[4],利用预训练BERT 模型分析工单文本内容,挖掘工单内容上下文规则,将通过大量中文预训练的模型进行二次训练,减少电力训练样本数量,提高工单自动分类的准确性,为自然语言预训练模型在电力行业中的应用实践提供参考建议。
1 工单文本分类理论
自然语言处理是当今大数据、人工智能重点关注的关键技术之一,主要的研究内容有词法分析、语法分析、文本分类、语言翻译等。目前在互联网领域,如国外的谷歌、脸书、亚马逊,国内的百度、阿里、腾讯等公司都把自然语言处理作为重点研究内容,在用户意图分析、情绪判定、广告推送、机器翻译等方面均取得了很好的应用效果。
文本挖掘的理论研究方面,主要研究方向有文本结构分析、文本语义分析、文本摘要分析、文本自动分类、文本多语言翻译等。文本挖掘的应用方面,研究成果和应用都比较成熟,文本挖掘已成熟应用微博热点话题监测[5]、情感分析[6]、用户评论语义分析[7]、垃圾邮件分类等应用场景中。
1.1 工单自动分类
所谓的工单分类,既是对工单文本内容进行挖掘分析,借助人工智能、自然语言处理技术,在文本中找出字、词、句的特征、上下文关系、变化规律等,理解文本内容的目的、意义及要素,对文本进行分类,实现工单的自动分类。
1.2 工单情绪分类
工单的情感分析是指通过对文本中的服务、产品、对象等内容进行归类,对文本中的人物、事件、评价等内容进行归类,采用情感分类策略,对该文本的意见与该对象的喜好态度进行关联挖掘分析,从而得到工单文本的情绪分类。工单的情绪分类在电力应用中比较典型的场景是对95598 客服工单内容,结合文本情感分析与文本分类技术,将建议、投诉类工单优先级进行类型划分,其中优先级较高的工单应当进行优先处理。
1.3 工单文本聚类
文本聚类作为自然语言处理技术中的一个重要技术,在文本挖掘技术的领域占据了不可代替的地位,由于不需要手工标记的样本数据,不需要人工处理文档内容,实现的代价较小,能够快速应用到各类场景,特别是对于像电力这类行业,普遍存在样本少、数据量大的特点,采用文本聚类可以作为对文本数据分类的预处理技术。
对于电力客服工单的分类,由于客户的诉求不断在改变,应对此类变化的最好方式就是采用文本聚类技术,可实时对所有工单进行分析,将同类工单进行归并,辅助下一步的文本挖掘分析。
2 工单分类方法研究
工单分类算法模型的构建过程即通过相关算法,根据文本处理后的样本数据进行训练生成分类模型,并利用该分类模型对新的工单文本数据进行自动分类,常见的文本自动分类算法包括条件随机场、梯度提升决策树、卷积神经网络算法等。
2.1 电力分词算法
中文句子中的每个词语之间无类似英文空格类的天然的分隔符,开展中文文本的挖掘分析,中文分词是开展文本挖掘的基础工作,自动分词是建立文本表示模型的首要问题。常用的分词算法有最大匹配算法、HMM、CRF 等[8]。其中CRF 算法适应性更好、准确度更高,是目前比较成熟的分词算法。
条件随机场CRF(Conditional random f ield)分词算法是一种基于概率图模型的标注算法,是马尔科夫随机场的条件概率约束的一种特殊情况。如果存在随机变量X、Y,其中随机变量Y 构成了一个无向图G=(V,E) 表示的马尔科夫随机场,即:
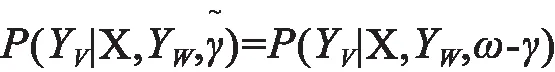
对任意节点γ成立,则称条件概率分布P(Y|X) 为条件随机场。式中“ω-γ”表示在图G=(V,E)中与节点v 有边连接的所有节点w,“γ~”表示节点v 外的所有节点,YV和YW为节点v、w 对应的随机变量。
CRF 分词中所采用的条件随机场是马尔科夫随机场的一种特例,是一种X、Y 具有相同图结构的线性链条件随机场(linear chain conditional random field)。
设X={X1,X2,X3,…,Xn}、Y={Y1,Y2,Y3,…,Yn}均为线性链表示的随机变量序列,在给定随机变量序列X 的条件下,随机变量序列Y 的条件概率P(Y|X)构成了随机场,i代表序列位置,n代表了序列的长度,即:

在中文分词标注处理中,X 表示着等待处理的输入序列,Y 表示着输出的标记序列。通过对电力文本训练语料的学习,可得出分词的随机场模型的参数,从而得到分词训练模型。
2.2 机器学习算法
梯度提升决策树GBDT 算法是机器学习中应用较广泛的一类算法,它是基于决策树的一类分类算法[9],GBDT 对于分类树的每一次的计算是为了减少上一次的残差,在残差减少的梯度方向上建立一个新的模型,从而实现残差的消除,设F(x,P) 是分类函数,P 是参数集,将加法函数延伸成如下格式:
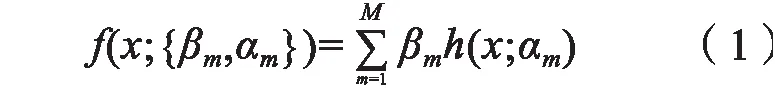
上式中的h(x;αm)是基函数,h(x;αm)是对输入变量x 的单参数化函数,其中α={α1,α2,α3,…,αn},对于上式(1)中的两个参数求解,可通过优化损失函数{βm,αm}来求解,计算公式如下:

针对以上损失函数的求解,可利用Greedy Stagew ise 方法,结果如下:
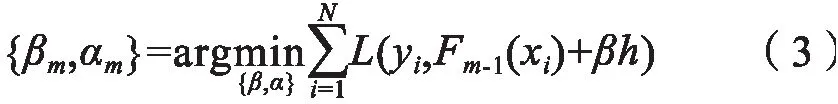
最后得到最终分类函数:

2.3 深度学习算法
目前深度学习已成为人工智能在行业应用中的主流算法,其中的卷积神经网络模型是典型代表,它由Lecun 在1989 年提出[10],卷积神经网络CNN 模型如图1 所示,模型是具有深度结构的前馈神经网络,在神经网络的至少有一层使用卷积计算层代替一般矩阵乘法网络层。卷积神经网络具有表征学习、局部感知、权值共享等特点,这样可极大减少训练参数的数目,提高网络计算效率,近年被广泛应用到计算机视觉、自然语言处理等领域。
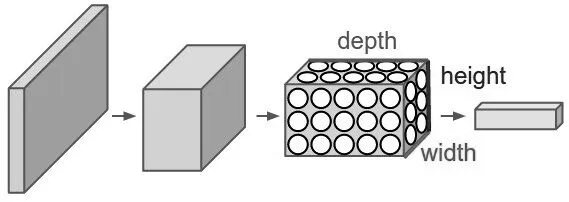
图1 卷积神经网络模型结构图
卷积神经网络CNN 由很多层组成,输入层可以处理多维数据,其后包含卷积层、池化层和全连接层,其中输出层的上游通常是全连接层,其结构和原理与前馈神经网络的输出层相同,模型各层的结构如下:
输入层(Input layer):输入层接收多维数组,用梯度下降算法进行学习,一般输入特征需要进行标准化处理。
卷积层(Convolutional layer):卷积层包含多个卷积核,其结构类似于一个前馈神经网络的神经元,每个卷积核的参数都是通过反向传播算法优化得到,卷积层的目的是提取输入的多种特征。
池化层(Pooling layer):通常在卷积层之后会得到维度很大的特征,在池化层进行特征选择和信息过滤,通过最大、最小、平均等计算,得到新的、维度较小的特征。
全连接层(Fully-Connected layer): 全连接层等价于前馈神经网络中的隐含层,通过把所有局部特征结合变成全局特征,是隐含层的最后部分。
输出层(Output layer):输出层使用逻辑函数或归一化指数函数将结果转换为分类标签。
3 自动分类模型构建
谷歌于2018 年发布了基于双向Transformer大规模预训练BERT 语言模型,凭借基于预训练的fine-turning 模型刷新了11 项NLP 任务的最优性能记录,引起了国内研究热潮。
3.1 预训练BERT算法模型
对于预训练模型的选择,本文使用基于多头自注意力机制的预训练分类模型,模型使用的是预训练模型中的典型编码器加解码器结构,如图2 所示,其中左边部分为编码器,用于将源序列的编码;右边部分为解码器,用于输出目标序列的解码。

图2 预训练BERT模型基本结构图
其中,编码器部分由N 个层堆叠在一起构成,每一层的结构都是相同的,每一层包含了两个支层:第一个支层由一个多头自注意力子层(M ulti-Head-A ttention)和一个前馈神经网络子层(Feed Forw ard)构成;第二个支层由一个简单的全连接前馈网络组成。另外,第一个支层和第二个支层的外面都采用残差进行连接,并对结果进行了层规范化(Add& Normalize)的处理。
模型的解码器部分也由N 个相同的层堆叠而成。每一层除了沿用编码器中的两个支层结构,还加入了第三个支层编码- 解码注意力子层(Encode-Decoder A ttention),用于计算编码器中输出结果对当前结果的影响。另外,第一个多头自注意力子层也和编码器部分的子层不完全一样,在编码器基础上添加了掩码结构,处理训练阶段屏蔽的词,解码器中同样进行了残差连接以及层规范化(Add& Normalize)的处理。
3.2 客服工单自动分类流程
电力客服工单中存在较多的标点符号,以及助词、副词、介词、连词等非功能性的停用词,模型训练前需要对文本数据进行预处理,图3 给出了基于预训练BERT 算法模型的自动分类流程,分类流程包含文本预处理、模型构建、效果评估三大环节,分类的详细流程步骤如下:
1)数据输入:一个工单文本描述作为一条数据,标识为一个数据集Y,得到待训练向量集合Zy={zy1,zy2,zy3,…,zym};
2)中文分词:工单文本中词与词之间没有空格的自然分界,本文采用上述所述的CRF 分词算法,并借助自行编纂的电力专业词典,对电力文本进行分词Aij={A11,A12,A13,…,A1m},其中一个工单文本为i,工单文本中的一个分词为j;
3)数据预处理:剔除无意义的标点符号、表情符号,剔除非功能性的助词、副词、介词、连词等停用词;
4)文本表示:采用分布式文本表示,将文本分词后的每一个词转换为向量化的数值,如“变压器”的向量化表示为[0.50451,0.68607,-0.59517,-0.022801,0.60046,…,0.68229,0.81722];
5)特征构建:构建工单文本分类的特征词库矩阵,完成特征提取,可有效降低特征空间维数,提高运行效率、降低复杂度、提高分类准确率,特征矩阵如下:
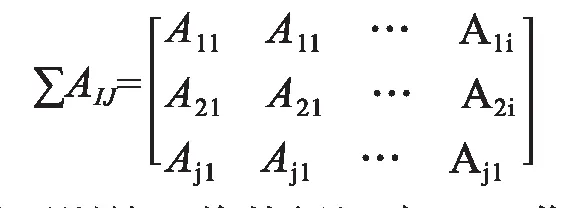
6)模型训练:将特征矩阵∑AIJ作为算法模型输入,其中70%数据训练集,30%数据测试集,对分类模型进行训练;
7)效果评估:本文采用准确率、召回率、精度、F1 值四个指标对分类效果进行综合评价,逐步调整模型参数,指标符合预期为止。
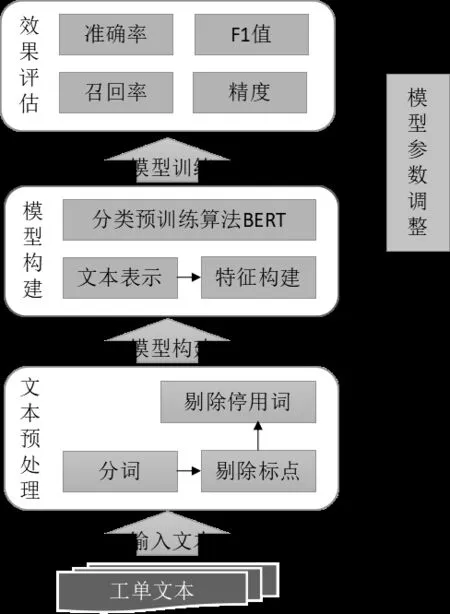
图3 工单自动分类流程图
4 实例分析
本文从某供电局营销部门收集了共35900 条与停电有关的工单。通过数据预处理,除去冗余、重复等意义不大的文本数据,由于本文所采用的分类方法为有监督学习机制,又去除了停复电咨询、催缴费等无关的数据,取剩余14000 条文本作为实验样本。该停电故障集涉及的类别如表1 所示。
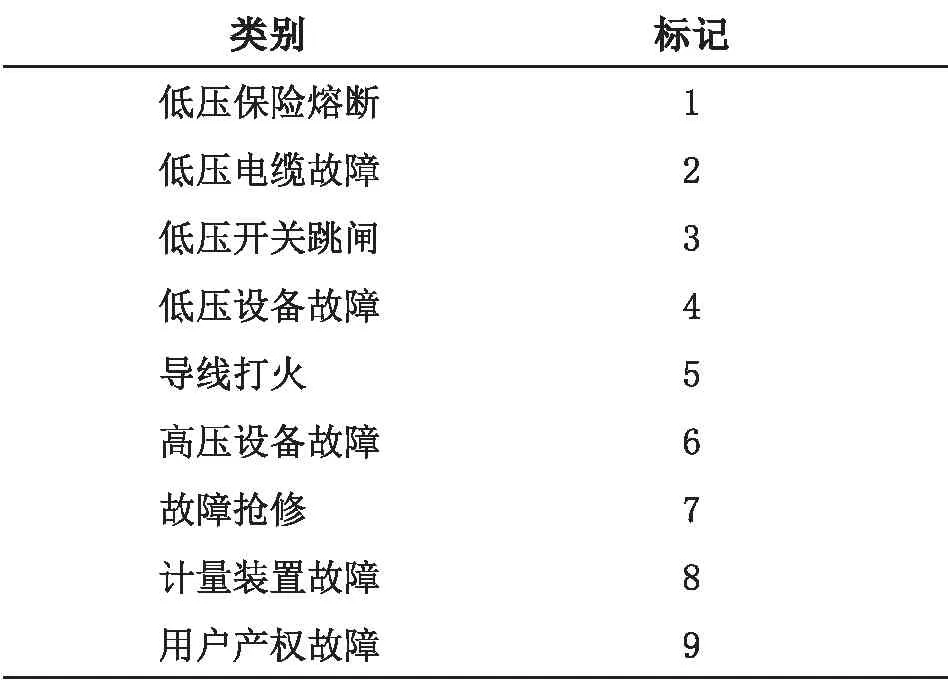
表1 停电故障类别
4.1 分布式文本表示
文本的分布式表示最早由Hinton 提出,本文采用的思路是以Bengio 等人提出的NNLM模型为基础,在对大量客服工单文本数据进行预处理的基础上,将这些客服工单数据作为语料库训练词的分布式词向量。通过NNLM 处理后,可得到不同维度的词的语义,如图4 表示一个三维的词向量示例:
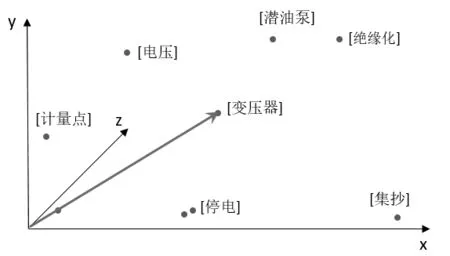
图4 词向量的分布式表示
图4 中每一个圆点表示一个词向量,x、y、z 轴分别表示词向量的3 个语义维度。采用分布式表示词向量时,词义相近的词对应的词向量在特征空间中距离也比较接近,而词义相差较大的词对应的向量距离也比较远,例如“潜油泵”和“绝缘化”两词的相关性较大,在图4词向量分布空间中,也可看出两词的特征空间距离比较接近。在电力实际应用中,词向量维度大小可根据语料库的大小来进行选定,通常取100~300 维,每个维度代表机器自动学习到的一个词特征。
4.2 输入文本的处理
输入的文本转换为词向量后,就可以输入预训练BERT 算法模型中,在进行模型的预训练时,将输入的词向量中融入电力客服工单场景的上下文特征,如图5 是工单文本“进户线三相电表关闭空开后有电”的预训练模型中的标准输入形式。

图5 电力文本输入结构图
文本序列的每个句子首位和末尾都打上特殊标记,首位标记[cls],末尾标记[sep],对于句子分类任务,中间字依此进行标记,最终完成整个句子的表征描述。针对一个段落,算法模型使用两种手段来使模型区分多个句子:1)用标记[SEP]分隔两个句子。2)添加段向量到输入中,段向量采用A 型、B 型、C 型来分别表示多个句子。
针对模型的每一步训练,例如输入句子A,有50%的概率选择句子B 作为下一个连续的输出,有50%的概率从语料中选择不连续的句子C 取而代之。图6 给出了替换的前后对比。

图6 句子屏蔽前后对比
采用遮蔽词策略的预测训练过程,模型输入序列中的任何一个元素都会被随机标记[mask] 代替,通过随机遮蔽词策略来避免模型学习中的过拟合问题。经过模型的屏蔽编码后,标记[mask]的最终输出结果会用来预测被遮蔽词。另外,在此模型训练时的输出除了保证句子本身的完整外,还采用是或否的标签来判断多个句子的连续性。
4.3 算法训练参数
标准的预训练BERT 模型给出了两个版本,一个是base 版本,另一个是large 版本,考虑到实验数据量相对较少,分类结果不是太多的情况,本文选择的是large 版本,虽然训练过程相对速度较慢,但能够从工单文本中学到的特征较多,拟合程度也会更好,分类模型采用的参数如表2 所示:
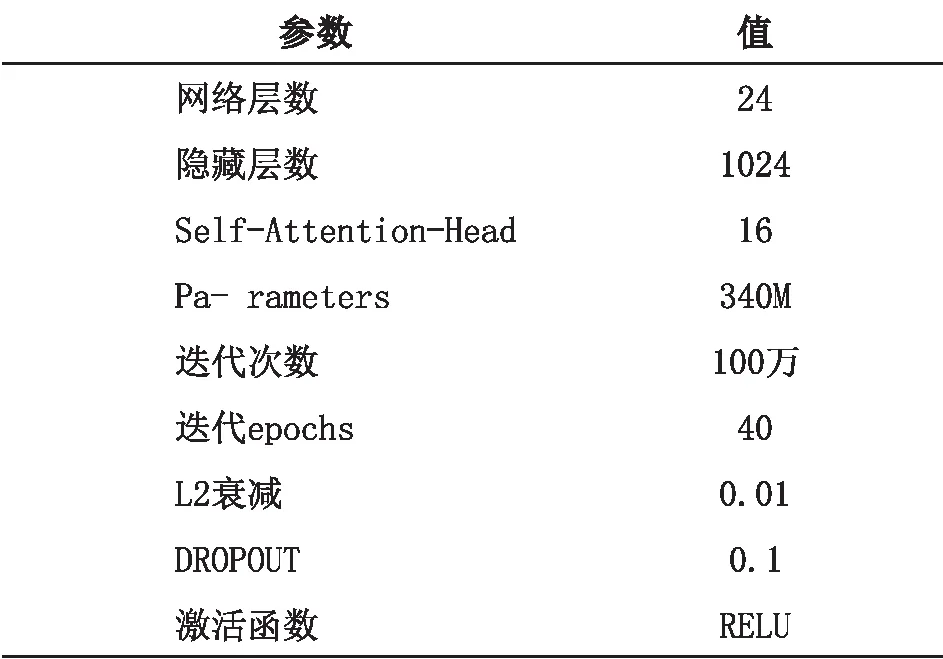
表2 分类模型参数
4.4 算法模型训练
算法模型的学习训练采用有放回重复抽样的方式来构建训练集和测试集,其中训练集和测试集按照70%和30%的比例来划分。训练过程中为了训练出有深度双向语言向量,需要遮住句子里某些单词,采用的屏蔽策略为1)80%概率保持这个词不变;2)10%概率用随机的一个词来替换;3)10%概率用mask token 来代替。
本文采用的屏蔽词策略能够提升编码器的泛化能力,由于编码器不知道哪些词是需要预测的,哪些词是被屏蔽为错误的,因此编码器将被迫学习每一个token 的分布向量,由于每个句子中只有20%的词会被屏蔽标记[mask]遮盖,保证了模型的泛化能力,为此多付出的性能开销也不大。
4.5 实验结果与分析
为合理评价电力客服工单文档的自动分类效果,我们重点关注分类模型的准确率、召回率、精度、F1 值四个评价指标,指标的定义如下:
■ 准确率(accuracy):

■ 召回率(recall):

■ 精度(precision):
■ F1 值(F1-score):
另外,为了对比预训练BERT 分类模型与传统机器学习分类模型的效果差异,本文选取几种典型的传统机器学习方法进行对比实验。文本表示采用分布式向量表示,分类算法采用GBDT 梯度提升决策树、LSTM 长短期记忆网络、RNN 循环神经网络。
采用上述4 种算法模型进行分类训练,得到的结果按照准确率、召回率、精度、F1 值、耗时进行对比,统计结果如表3 所示。
从表3 的对比可看出,采用GBDT 的模型训练耗时最小,原因在于GBDT 模型是由多颗决策树构成,复杂度小,可并行程度高,计算性能要优于其他模型。不过准确率、召回率、精度等其他评价指标都是最低的,整体指标偏低,说明模型对于数据的拟合度不够,也从侧面说明客服工单文本上下文关系、隐含语义较复杂,常用的机器学习模型效果不理想。
预训练BERT 模型除计算性能低于GBDT模型,其他三个评价指标都是最优的,其中准确率和召回率都明显要高于其他模型,深度学习类的RNN、LSTM 模型对于样本量少的电力工单训练的效果不够好,预训练类BERT 模型可以将其他领域训练的文本特征带入电力业务场景,能够显著提升电力工单文本自动分类的准确度。
5 结束语
在电力客服工单的自动分类处理上通过引入基于预训练的BERT 模型,并将预训练模型与常用的机器学习、深度学习模型进行全面对比,通过对各类算法模型的准确率、召回率、精度、F1 值、耗时进行了综合对比,给出了在电力95598 客服工单文本分类的一种优选方案。
预训练模型中除了较成熟BERT 模型,目前基于预训练策略还发展出MASS、XLNET 等一系列更复杂的预训练模型,可以预计,随着人工智能、自然语言处理技术的成熟,电力业务中更专业、更复杂的场景必将迎来巨大变更。
