基于神经网络的NDN入侵检测方法*
2020-03-26王枫皓
王 鑫,王枫皓
(1.解放军91404部队,河北 秦皇岛 066000;2.陆军装甲兵学院 信息通信系,北京 100072)
0 引 言
互联网已经发展成为现代社会的重要基础设施之一,渗透到包括军事、文化、政治、社会以及经济等领域。根据中国互联网络信息中心(China Internet Network Information Center,CNNIC) 发 布的第43次《中国互联网络发展状况统计报告》显示,截至2018年12月,网民规模达到8.29亿,全年新增网民5 623万,互联网普及率59.6%[1]。伴随着互联网用户规模的不断增加、业务领域的不断拓展以及各类新兴技术的不断崛起,传统的基于TCP/IP架构的互联网络已经远远不能满足需求。为了解决当前互联网中存在的问题,学术界提出了一种以信息为中心的网络架构。由UCLA的张丽霞和Van Jacobson等提出的命名数据网络(Named Data Networking,NDN)[2],具备多样、灵活、可配置的路由缓存策略以及对数据内容加密的源生支持,现已取令人瞩目的发展,俨然成为以信息为中心的主流网络架构。
尽管NDN网络架构从根本上解决了TCP/IP网络存在的诸多问题,但也带来了新的安全隐患[3]。其中,缓存污染攻击、兴趣泛洪攻击和内容污染攻击导致的网络拥塞、拒绝服务、资源耗尽等问题,对NDN网络架构影响很大。
与此同时,近年来计算机性能得到了大幅提升,再次引发了机器学习热潮,而越来越多的人也开始将BP神经网络用于入侵检测方法,识别包括DoS攻击在内的各种类型的攻击[4],从而提高对各典型攻击类型的检测率和检测效率。随着命名数据网络受到越来越多的重视,必然需要一个可以对典型NDN入侵攻击行为进行检测的方法,才能使ISP在实际部署NDN时能够有效维护网络的安全。
本文主要面向命名数据网络,设计并实现基于BP神经网络的入侵检测方法。该方法搜集命名数据网络的基本性能数据,经过处理后作为入侵检测方法的原始输入。利用神经网络对网络行为做出检测,提高了命名数据网络的网络防范能力。目前尚没有其他方法解决NDN中的入侵检测问题,本文工作在入侵检测方面达到了很高的检测率,且证明了方法的可行性。
1 BP神经网络
误差逆传播(Back Propagation)是迄今为止最成功的神经网络算法。现实任务在使用神经网络时,大多使用BP算法进行训练[5]。BP神经网络的原理分为两个阶段。第一阶段是输入层接收到输入数据后网络进行逐步计算,得出整个网络的输出数据。第二阶段的主要思想是误差逆传播,期望的输出不变,输出层根据现有输出计算误差,并根据现有的误差反向传播,将误差在整个网络之内分摊,以此为依据调节神经元之间的连接权值与阈值,从而达到对网络进行优化的目的,提高网络输出的准确程度。
应用最广泛的三层神经网络结构模型,如图1所示。图1中,Ii(i=1,2,…,m)表示输入,即输入层的输出。对于隐含层,隐层数过多,那么神经网络的泛化能力会变差,产生过度拟合情况,无法准确预测;隐含层的数目过少,则连接权值组合数不足,易导致神经网络预测精度达不到要求。根据长期应用经验,隐层单元数可用确定,其中m为输入神经元数,n为输出神经元数,a为1~10的常数,yi(i=1,2,…,n)表示隐含层的输出,激活函数f(·)采用Sigmoid函数,即S函数。

图1 典型BP网络
2 命名数据网络入侵检测原理
2.1 NDN原理
命名数据网络中存在两种数据报文,分别为兴趣包和数据包。
兴趣包和数据包都是通过内容名称进行标识。兴趣包负责携带用户(Comsumer)的请求信息;数据包则由信息的生产者(Provider)提供,负责携带用户想要获取的数据内容,同时Provider对信息进行签名[6]。
路由节点则维护了3种重要的数据结构,负责对这两种数据包进行处理[7],分别是转发信息表(Forwarding Information Base,FIB)、未决兴趣表(Pending Interest Table,PIT)和内容缓存(Content Store,CS)。FIB记录了兴趣请求到达数据提供者的下一跳接口的路由信息,PIT则记录了没有被满足的兴趣包的源消费者接口信息,而CS则类似于IP架构中Quic协议中的网页缓存。
一个搭载了NDN网络的节点,网络处理流程如图2所示。

图2 NDN路由节点网络处理流程
当NDN的路由节点接收到Interest后,首先在内容缓存CS寻找是否已经缓存相应名称前缀的Data,如果结果显示存在,则直接向Comsumer交付该Interest,否则查找PIT。在PIT中,对于相同的内容请求,仅仅需要在来源端口列表中添加相应的端口信息,否则继续查找FIB。在FIB中,如果存在相同名称的路由,那么直接进行Interest转发,并在PIT中记下该Interest的内容信息,否则直接丢弃该Interest或者向Comsumer交付NACK。
路由节点收到相应Data后,查找PIT中是否存在满足该Data的PIT项,如果没有则丢弃,否则查找PIT表项中添加的接口信息,将此Data向所有接口进行转发,同时根据节点的缓存规则判断是否需要将此Data添加至CS中。
2.2 NDN入侵检测思想
基于结构化的思想构建NDN的入侵检测模型,如图3所示。在NDN网络的消费者和数据生产者之间的NDN路由器节点上构建一个Tracer服务,所有的服务产生的信息以Tracer命名,搭载入侵检测的节点周期性请求其余节点的Tracer信息。利用NDN网络中核心节点的神经网络算法分析网络数据,检测出网络中的异常数据流量,智能识别存在的网络攻击,从而达到提升网络安全性能的效果。
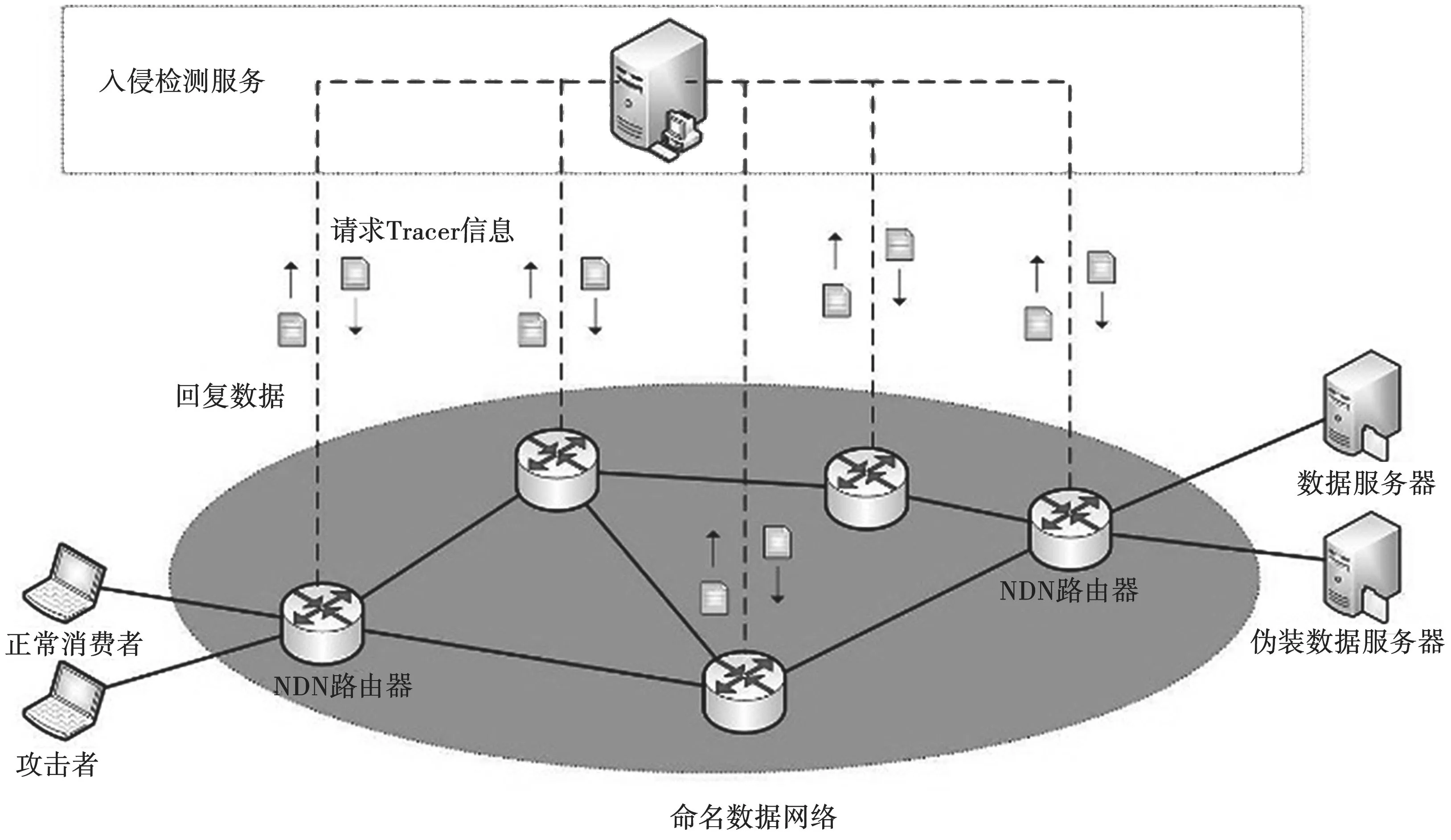
图3 NDN网络入侵检测架构
2.3 命名数据网络安全特征的选择
NDN网络攻击的主要方式分为命名攻击、路由攻击、缓存攻击和其他类型的攻击4类。在这4类攻击中有两类最具代表的攻击方式已经受到NDN团队的认可,分别是IFA和CPA[8-9]。
兴趣泛洪攻击(Interest Flooding Attack,IFA)主的要方式是由攻击节点不断发送大量特定的名称前缀的兴趣包[10],由于该兴趣包请求的数据不存在,所以导致NDN的PIT表项被严重占满,但是请求的Interest并没有被满足,同时由于节点的数据处理能力以及链路的带宽、传输时延等因素的影响,生产者难以满足如此巨大的请求量,会出现巨大的丢包现象。
缓存污染攻击(Cache Pollution Attack,CPA)的主要方式则是通过大量请求流行度较小或者无用的内容甚至是恶意的内容,从而使沿途节点中的CS条目充满对于主体Comsumer来说并不需要的Data,但是由于NDN路由器的CS条目已经被占满,其他的主体Comsumer想要请求相同的高流行度的内容时,节点查找缓存的过程就会出现缓存丢失情况,从而不能实现就近获取,破坏了NDN设计的优势,降低了整个命名数据网络的QoS。
2.4 基于BP神经网络的NDN入侵检测机制
入侵检测方法的主要功能是从互联网络中的路由节点或者关键用户节点收集网络信息,针对这些信息进行专门分析,以此检查网络中是否有违反安全策略的不正当行为或受到黑客攻击的现象。模型的主要动作包括数据采集、数据预处理、数据传输、样本建立、神经网络构建以及入侵检测等。入侵检测的机制如图4所示。
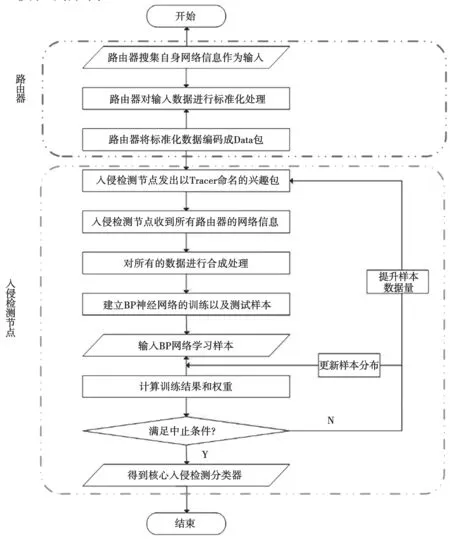
图4 基于BP神经网络的入侵检测机制
机制中,由于NDN是完成不同于TCP/IP架构的网络,所以路由器在进行信息收集时需要选取完全不同于原有网络架构中的信息。选取的信息如表1所示,基本涵盖了所有命名数据网络的要素信息。

表1 NDN路由节点特征要素总结
与此同时,将数据标准化处理的步骤置于路由器节点,以分担网络中的计算处理资源,加快入侵检测分类器初始数据集的生成。为了减少数据间的相关,使用PCA方法对数据信息进行预处理,处理公式如下:
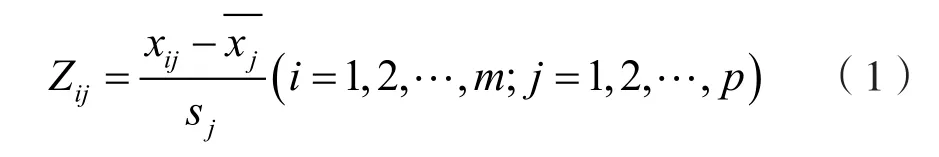
其中是X矩阵每一列的均值,sj为每一列的标准化值,公式为:

数据传输阶段利用NDN固有的传输原理,将数据以协商好的名字进行标识。入侵检测节点发送以此名字命名的兴趣包到整个网络,相应路由器经过标准化处理完成的数据包,自然通过整个网络发送到此节点。采用层次化的命名方式构建一个命名树,数据包和兴趣包命名结构如图5所示。
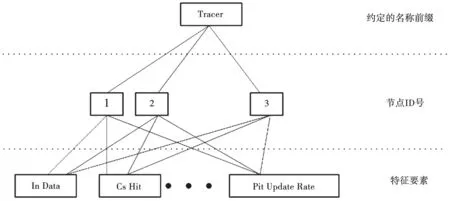
图5 数据包以及兴趣包命名结构
例如,节点3的未决兴趣表更新频率信息命名方式为Tracer/3/Pit Update Rate。这样的命名方式既体现了数据的实际含义,又可以灵活实现数据的聚合。假设现在想要获取所有节点的缓存未命中数目,那么入侵检测节点发送的兴趣包采用的命名方式可以是Tracer/*/Cs Miss。所有的路由节点收到兴趣包后会原路返回包含各自缓存未命中信息的数据包。
在入侵检测节点收到所有信息后进行BP神经网络的训练,将满足条件的入侵检测分类器作为节点的核心处理部分,从而进行入侵检测。
3 实验结果与分析
NDN网络目前仍旧处于研究阶段,并没有进行大规模部署。ndnSIM作为NDN的仿真平台得到了学术界的认可。本文在本地计算机上采用ndnSIM进行仿真。计算机的配置如下:Ubuntu 18.04,内核版本 4.15,Intel Core i5 CPU,DDR3 1866 16GB内存,1 TB硬盘。NDN网络仿真拓扑结构采用如图3所示的网络拓扑。其中,4个NDN路由器节点,1个正常数据服务器节点,1个伪装数据服务器节点,1个正常的消费者,1个攻击者,1个入侵检测节点。每个源服务器提供50种内容,则整个拓扑结构中共有80种内容,其中伪装数据服务器节点提供与正常服务器相同名称前缀的20个内容,但这20个内容的数据错误,已被污染。用户请求数据的模式服从Zipf-Mandelbrot分布,其中α=0.8。节点缓存空间设置为100,缓存替换策略设置为LFU替换策略。每个节点缓存容量为C,C设置为50。链路的带宽设置为1 Mb/s,时延设置为10 ms。
首先进行20 min的正常网络的数据仿真,然后通过攻击者进行兴趣泛洪攻击20 min,再进行缓存污染攻击20 min,之后各进行5 min的3种网络行为的数据仿真。其中,将前60 min收集到的数据作为训练样本,将后15 min的数据作为测试样本,以检测入侵检测的效果。
由于样本是以时间为单位周期性统计生成的,所以训练样本1 200个,测试样本900个。在Ubuntu环境下,利用Python编写3层BP神经网络,其中输入神经元为13个,输入分别为路由节点不同的要素信息,输出神经元的个数为3个,分别为IFA攻击、CPA攻击和Normal数据。根据上述应用经验,设置隐含层神经元个数为9个。神经网络模型如图6所示。

图6 神经网络模型
根据TCP/IP中衡量入侵检测的标准,对本文模型在不同的路由策略下的检测率和误报率进行对比。其中:

检测效果如图7所示。可见,随着IFA攻击者攻击频率的增加,两种路由策略下检测率都呈现上升趋势,且均保持了较低的误报率。这是由于在攻击者的攻击频率增加的条件前提下,IFA攻击的直接影响是路由器节点收到大量的兴趣包请求报文,但是由于洪泛攻击会造成节点带宽耗尽,整个网络特征变化较为明显,所以整体会呈现检测率上升的趋势。
其中,Multicast策略下由于多节点分担了攻击者的报文数量,且在FIB上存在数据请求聚合的机制,所以导致网络特征变化幅度较Bestroute不明显,以致于相同攻击频率下的检测效果始终低于Bestroute。
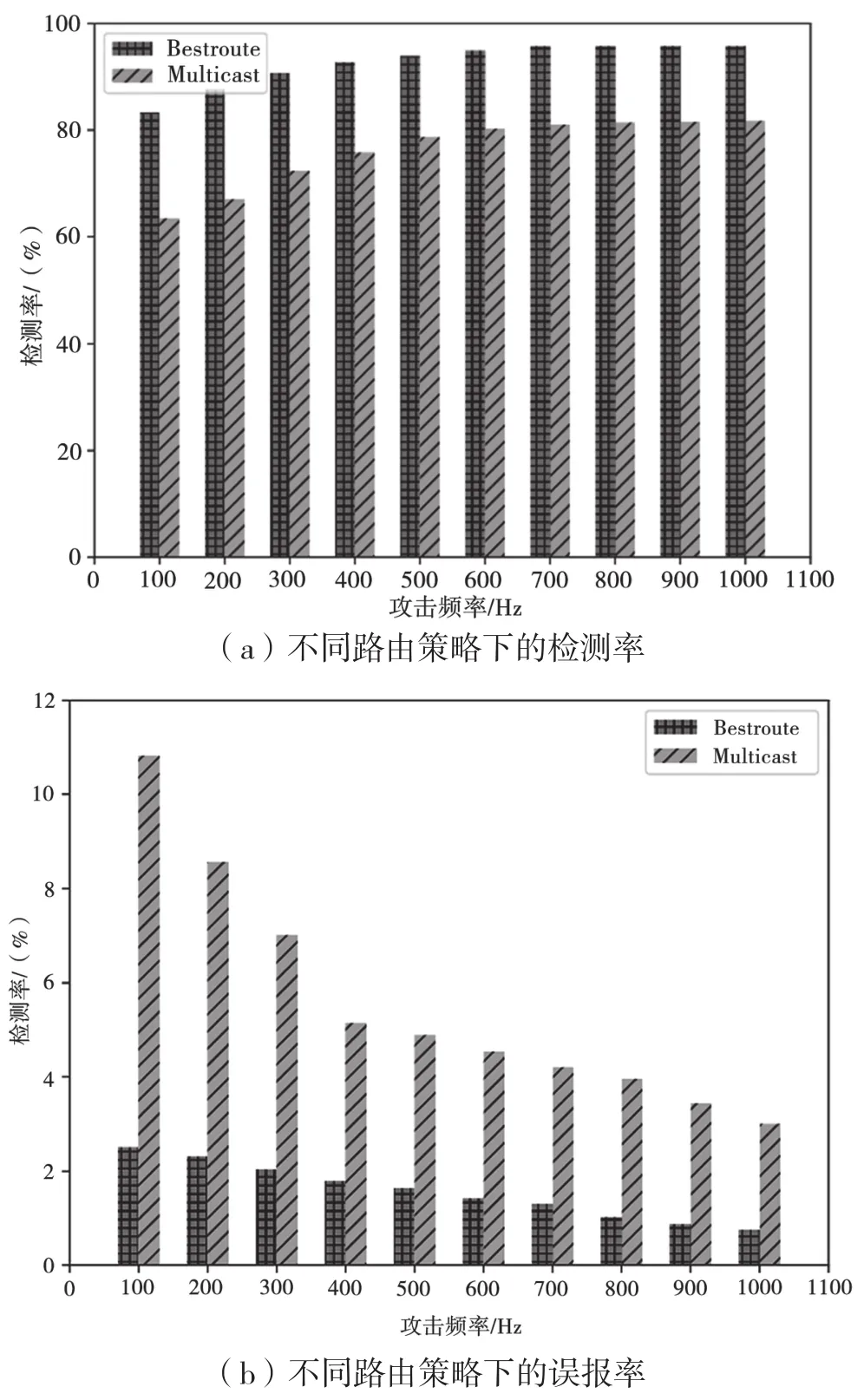
图7 不同路由策略下检测率以及误报率对比
相反,Multicast策略下由于多节点对网络的流量和特征数据进行了分散,导致BP网络会产生许多模糊判别,相较Bestroute误报率较高。
通过分析发现,基于BP神经网络的入侵检测模型在命名数据网络进行应用能达到较好的效果,具备实际部署的可行性。
4 结 语
本文主要设计了一种应用于命名数据网络的入侵检测方法。该方法收集网络节点的数据,总结5种特征要素作为核心检测模块的输入,并基于BP神经网络构建核心检测模块。利用神经网络进行网络入侵检测行为的判断,通过仿真研究验证了本方法的可行性,并表现出了良好的性能,可以在实际部署NDN时作为一种参考。
