基于FSM的物联网大数据清洗算法*
2020-03-26郭雷勇
郭雷勇,李 宇
(广东药科大学 医药信息工程学院,广东 广州 510006)
0 引 言
目前,物联网技术在物流管理、供应链管理、产品的跟踪等领域[1]得到了越来越广泛的应用。与传统的数据不同,RFID标签数据不仅包含产品信息和厂商信息,还记录了该标签读取的时间和位置信息。物联网技术本身固有的对环境的敏感性、标签冲突现象以及标签数据存在多读、漏读、冗余读等问题,降低了数据的可靠性。因此,在中间件中需要对数据进行清洗。而这些应用能否取得成功,很大程度取决于RFID数据的可靠性。本文主要对如何清洗标签中的多读及重复读的数据进行深入研究。
RFID数据清洗算法主要是针对标签数据存在的漏读、多读、冗余读等现象进行过滤清洗,提高数据的可靠性。目前,大多数的RFID清洗算法中,很多工作均只针对标签的漏读问题进行研究,往往忽视了数据清洗的效率问题。实际应用中,可能同时面临多台阅读器海量的标签数据,而物联网技术应用本身需要对数据进行实时处理,因此希望在保证数据的清洗准确率的前提下,以较低的时间代价处理更多的数据。
1 当前RFID清洗算法存在的主要问题
近些年,RFID标签的识别率得到了提高,但是无论是标签的识别率还是抗干扰性都远远没有达到理想水平。面对海量的数据,存在各式各样的错误来源,如何高效地对数据进行清洗是一项极具挑战性的任务。
文献[2]提出了一种定长的滑动窗口,在窗口中统计新来标签数据的读取次数,如果次数超过阈值,则视为干净数据,同时解决了标签输出顺序的问题。文献[3]则提供了一个数据的清洗框架ESP,针对RFID数据流,使用类似于查询语言的方式对数据进行清洗,提供了5层管道查询框架,并提供了一系列过滤方法。文献[4]提出了一种考虑成本的清洗框架,使用贝叶斯网络对数据进行清洗,利用决策树选择最优的过滤方法,也取得了较好的结果。文献[5]利用类似查询的语句对RFID数据进行过滤,并预先通过定义好的标签动作产生相应的规则,保证了清洗的准确率,但其与实际应用的场景关联过于紧密,不具有通用性。文献[7]通过使用AVL树的数据结构存储标签流,解决了滑动窗口清洗算法中存在的重复窗口问题,一定程度上提高了处理效率。
为了解决定长滑动窗口需要预先设定窗口大小的问题,文献[6]提出了一种基于统计模型动态更新滑动窗口的方法SMURF,把标签读写过程看成一个随机采样模型进行建模,针对单个标签和多个标签两种情况,假设了伯努利二项分布和π估计的统计模型。SMURF算法虽然克服了提前设置窗口大小的问题,但其基于概率分布模型,实现较为复杂,处理效率不高,且只适应于一个阅读器的场景,没有考虑多阅读器的情况。在实际的RFID业务应用中,为了提高标签的识别率,一般会部署多台阅读器。另外,SMURF算法主要针对数据的漏读,现实应用中则希望有更全面的数据清洗功能。
传统基于定长的滑动窗口清洗算法中,设置窗口的大小是一件极富挑战性的工作。如果窗口设置太小,将无法保证标签数据流的完整性,但窗口太大又会丢失标签的动态性,如图1所示[6]。

图1 滑动窗口的问题
效率上,基于定长的滑动窗口数据清洗的时间复杂度为O(KN),K是滑动窗口的长度,N为数据的规模。当有新的标签到来的时候,需要遍历整个滑动窗口以统计该标签的读写次数,查看该读写次数是否到达阈值,从而确定是否输出数据。研究发现,清洗效率不高的原因在于如图2所示的重复窗口区域会被反复计算,严重影响了数据清洗的效率。

图2 滑动窗口的重复窗口
本文根据实际应用的场景,针对标签数据存在的多读和大量冗余现象,提出了一种基于有限状态机(Finite-State Machine,FSM)的清洗框架,提高了数据的处理效率。
2 基于FSM的数据清洗算法模型实现
本文在定长的滑动窗口算法基础上进行改进,抛弃了传统清洗算法设置滑动窗口的方式[7-8],通过记录标签首次进入滑动窗口的时间、最近一次的读取时间、读取的次数等作为标签的状态记录,按照标签的状态对数据进行清洗。算法使用基于有限状态机的方式作为清洗策略,解决了重复窗口的问题,通过创建多阶哈希表存储标签读写记录,提高了数据的处理效率。
2.1 模型的主要思想
一个确定的有限状态机FSM是由A=(Q,∑,δ,S,F)五元组[9]构成的。本文中五元组的实际意义如下:Q表示非空的状态集合,由标签的各个状态组成;∑表示输入,即携带信息的标签流;δ表示转移函数δ:Q×∑→Q,根据输入和标签的状态确定状态的转换;S表示标签的初始状态,其中S∈Q;F表示最终的标签状态集合,其中F ⊆Q。下面按照有限自动机的五元组阐述本文的清洗算法的思想。
2.1.1 确定标签的状态集合Q和初始状态S
通过对标签流的研究,提出将标签的整个读写过程定为unknown状态、captured状态和observed状态3种状态,即标签的状态集合Q={unknown,captured,observed}。其中,unknown表示标签不在读取区域之内,无法知道标签的信息,处于未知状态中;captured表示标签首次被捕捉后的状态,意味着标签已经进入读取区域,但根据当前的信息无法确定该标签属于正常还是异常数据;observed则表示标签在读取区域中,已经确认被读取到,是可靠数据。标签的初始状态是指该标签还未被捕捉的时候,处于未知状态,即S={unknown}。
2.1.2 确定标签流的组成∑
从阅读器传输到中间件的RFID原始数据,一般可认为每个标签记录都是由一个三元组<EPC,Location,Time>组成[10]。其中,EPC代表标签独一无二的ID;Location表示阅读器放置的地方,即标签被捕获的位置;Time则表示阅读器检测到该标签的时间。
本文的数据清洗算法中并没有针对标签的位置信息Location作任何处理,因此并不需要该特性。本课题在研究标签的读取过程的数据后,提出在这个三元组中用标签的读取信号强度(Signal Strength)代替标签的位置信息,作为标签的读写特征,用SS表示,取值范围0~100。值越大,表明信号越强。由于物联网技术本身的内在敏感性,信号强度往往与货物的性质(金属非金属、液体等)、标签所贴的商品位置及与阅读器所处的位置相关。越贴近阅读器信号越强,而与阅读器距离越远,信号越弱。标签的读取信号强度可以更加贴切反映标签读取过程的特征,因此本文的标签数据均可以认为是以<EPC,Time,SS>三元组形式存在的。
2.1.3 确定标签在状态机转换机制δ:Q×∑→Q
标签的状态转换机制是清洗算法的核心,标签的转换即数据清洗的过程。为了实现快速查询标签的读取记录,将使用多阶哈希表作为存储标签读取记录的数据结构。
本文算法主要根据在有效的时间内以标签的读取次数和读取信号强度确定标签的状态转换。标签的读写次数是表明标签读取过程的一个重要特征,如果读取次数较多,那么有理由相信该数据不是偶然读到,属于正常数据的可能性非常高。
在RFID数据分析中发现,无论应用的场景怎样变化,无论是快速通道还是库存盘点,大部分的RFID标签数据的读取信号强度都趋近于高斯分布。而标签多读现象产生的原因多是标签刚好经过阅读器的区域,具有与阅读器距离较远、读取强度较低等特点。因此,本文使用标签读取信号强度的目的在于增加一个特征确定数据是否是可靠数据,减少单一特征可能造成的清洗误差。
同时,为了适应更多的应用场景,避免提前预设信号强度阈值,本文在清洗过程中记录所有标签的平均读取强度SSavg:

其中totalCnt表示标签的总的读取数。根据中心极限定理,当某标签的功率超过当前的平均值,便有理由相信该标签是正常数据,从而可以确保即使在标签的读写次数达不到阈值烦人情况下,仍然可以判定该数据是正常数据,减少了数据清洗的错误率。
下面讲述具体的标签状态的转换机制。本文将标签状态定义为unknown状态、captured状态和observed状态。在有效的时间内,在不考虑标签读取强度的情况下,当标签未读到之前处于unknown状态;当标签首次读到后进入captured状态,处于可疑状态;当读取的次数超过设定的阈值后,进入observed状态,表明该数据是可靠数据,将作为干净数据输出;若以后再读到该标签,则会被视为冗余数据过滤掉。其中,如果任意一次的标签读取过程中,读取信号强度超过了当前所有标签的平均读取强度,则无论其处于unknown或captured状态下,均会直接跃迁到observed状态,无需考虑其读写次数。若某个标签连续读取时间间隔超过了有效的时间间隔,则会被认为读取记录已经过时失效,需要清空记录。
2.2 多阶哈希表的创建过程
哈希表[11]也叫散列表,将某个key值映射到哈希表中的存储位置,实现数据的快速查询访问。哈希表结合了链表及数组的优点,在软件设计领域有着极为重要的应用。如果哈希表设计合理,可以在O(1)的时间复杂度内实现数据的快速查找。哈希表设计的关键在于找到一个好的散列函数,使散射地址足够分散,最大程度上避免碰撞的发生。
本文针对标签数据独一无二的特点,设计了多阶哈希表,利用均匀散射函数使得各个标签得到了一个随机地址。该方法独立于各个平台,实现简单,最大程度降低了标签之间的冲突,可移植性高。下面讲述多节哈希表的创建过程。
(1)首先定义在哈希表中的存储标签数据的节点。

(2)根据实际业务中货物中的标签的数据规模DataSize,确定多阶哈希表的最大桶个数M。一般为了避免较多的冲突,可设置M=2*DataSize;再设置哈希表阶数N,该值不能太大,否则多阶哈希可能退化成多链表。
(3)在内存中申请M×N个TagNode节点空间,以二维数组Hash[M][N]表示,作为存储标签数据的哈希矩阵,其中N表示哈希表的阶数,M表示哈希表的最大桶数。
(4)计算每阶哈希表的桶数,哈希表的各阶桶数由比最大桶数M小的最大的n个素数组成,存储在数组primeTable中,primeTable[n]代表第n阶的哈希表的桶数,n=1,2,3,…,N。实际上,在哈希表的实现上,直接使用最大桶数作为每阶哈希表的桶数也是可行的。但是,使用素数作为每阶哈希表的桶数可以降低冲突的概率。它的数学依据在于一个随机数对质数取余得到的Hash值,比对合数取余的结果散列得多,从而可以最大程度避免哈希冲突,实现如图3所示。

图3 多阶哈希表的结构
(5)由于RFID标签的值是唯一的,本文以标签tagId作为key建立映射函数:f(tagId)=(tagId+M)%primeTable[n]。primeTable[n]表示第n阶哈希表的桶数,n=1,2,3,…,N;M为哈希表最大桶数;f(tagId)是在该阶哈希表中的存储地址。如果该位置已经存在其他标签,则继续计算尝试下一阶的哈希桶。
(6)以步骤(5)的哈希映射函数为基础,为多阶哈希表提供标签节点的查询、修改、增加等方法,而这些方法均是以标签查找为基础。当标签的状态发生变化时需要更新时间、读写次数等状态。
(7)创建队列Queue,储存冗余标签数据过滤后的对象,此队列的数据是经清洗后确认读到的可靠数据。该队列的数据可以直接被上级应用如业务系统所使用,也可以储存到数据库中做下一步处理。
2.3 模型初始值的确定
在确定标签处于Q={unknown,captured,observed}状态转换前,首先需要配置模型的初始值——有效读取时间阈值Tthreshold和读取次数阈值TagCntthreshold。
(1)有效读取时间阈值Tthreshold,表征标签的有效读取时段。如果连续两次读取到的时间差值超出该时间阈值,则认为是不同的事件,需要清空旧的标签读取记录。本课题中,该值是根据业务的实际应用场景确定,通过对仓储管理中出入库流程时间统计,可以确定一批货从仓库到通过阅读器的通道所花费的时间。每批货物出入库所花费时间20~600 s不等,时间阈值需要动态更新,以适应实际的场景。该值需要根据实际的业务情况进行调整,如果是获取静态的数据如扫描库存,可以相应增大其阈值;若是获取动态的数据如传输带的标签数据,则需要调小该阈值。
(2)读取次数阈值TagCntthreshold,是标签状态变化的临界值。在有效的时间内,标签读到的次数超过该阈值才可认为是可靠数据,若低于该阈值则认为是可疑数据。该值可通过统计历史经验值得到。在实际应用中,该值同样需要根据实际业务进行调整。
2.4 清洗算法流程
本算法针对RFID数据存在的大量冗余及其多读现象,使用基于确定有限状态机对数据进行清洗,通过创建多阶哈希表作为过滤通道,快速有效地过滤海量RFID数据,减少网络的传输量,降低业务的数据处理规模,提高数据清洗的效率。清洗算法的实现流程如下。
(1)根据业务应用场景确定模型的初始值,依照上述方法创建多阶哈希表,并定义好存储在哈希表的标签节点数的数据结构。
(2)确定标签的状态。当有标签数据<EPC,Time,SS>到来时,首先查询该标签在哈希表中是否存在其历史读取记录。若该标签不在哈希表中,则表示该标签处于unknown状态;如若标签在哈希表中,则在进一步确认标签的状态之前,需要先判断该标签是否处于有效的读取间隔内。若最近读取时间与最后一次的读取间隔超过有效时间阈值,则表示该标签之前的读取记录已失效,需要清空其读取记录,并将其视为首次读取的标签进行处理;若读取间隔仍然在有效的时间阈值之内,则可以根据哈希表该节点的state字段确定标签的状态。
(3)如图4所示,定义标签状态转换的状态机,确定标签过滤的准则。
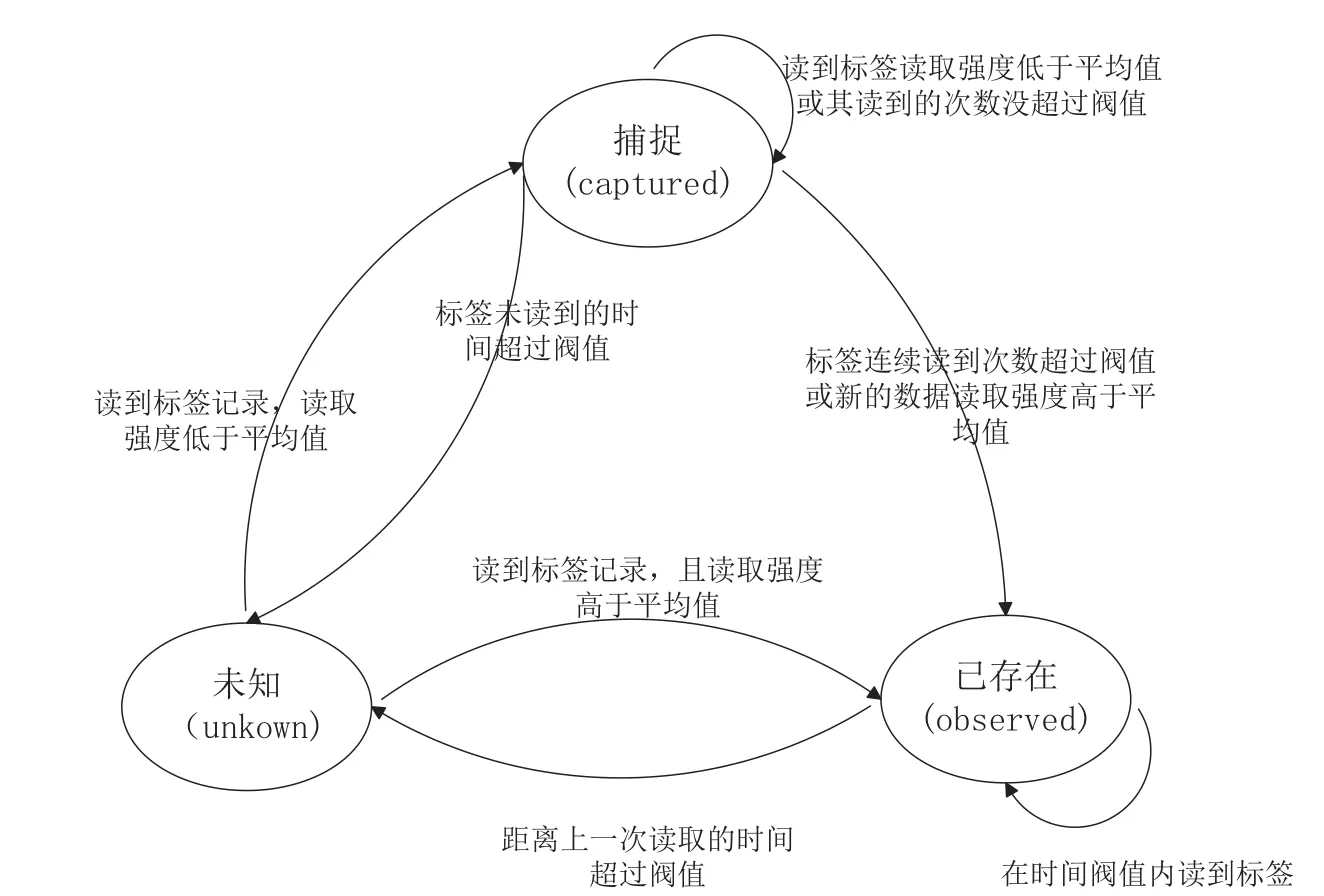
图4 标签的状态转换
①当标签处于unknown状态时,将其加入多阶哈希表中,设定其读取次数、读取时间。此时,考虑其信号读取强度是否超过当前的标签记录的平均读取强度SSavg。若超过,则直接设置状态为observed状态,作为干净数据加入队列Queue中,供上层业务系统调用;若其读取的信号强度小于平均值,则转入captured状态。
②当标签处于captured状态时,更新其节点数据,考虑其读取次数和其信号读取强度是否超过当前的标签记录的平均读取强度SSavg,若超过平均值或其读取次数刚好到达有效读取的阈值,标签将转为observed状态,标签值则作为过滤后的干净数据加入队列Queue中;否则,该标签仍然处于captured态。
③当标签处于observed状态时,新的读取记录作为冗余数据过滤掉。在实际应用中,绝大多数标签均处于该状态。
(4)更新当前所有标签记录的平均读取信号强度,按照SSavg=(SSlastavg*tagCnt+SS)/(tagCnt+1)
方式进行计算,更新哈希表中该节点的最新读取时间和读取次数。
2.5 清洗算法步骤
清洗算法的流程,如图5所示。
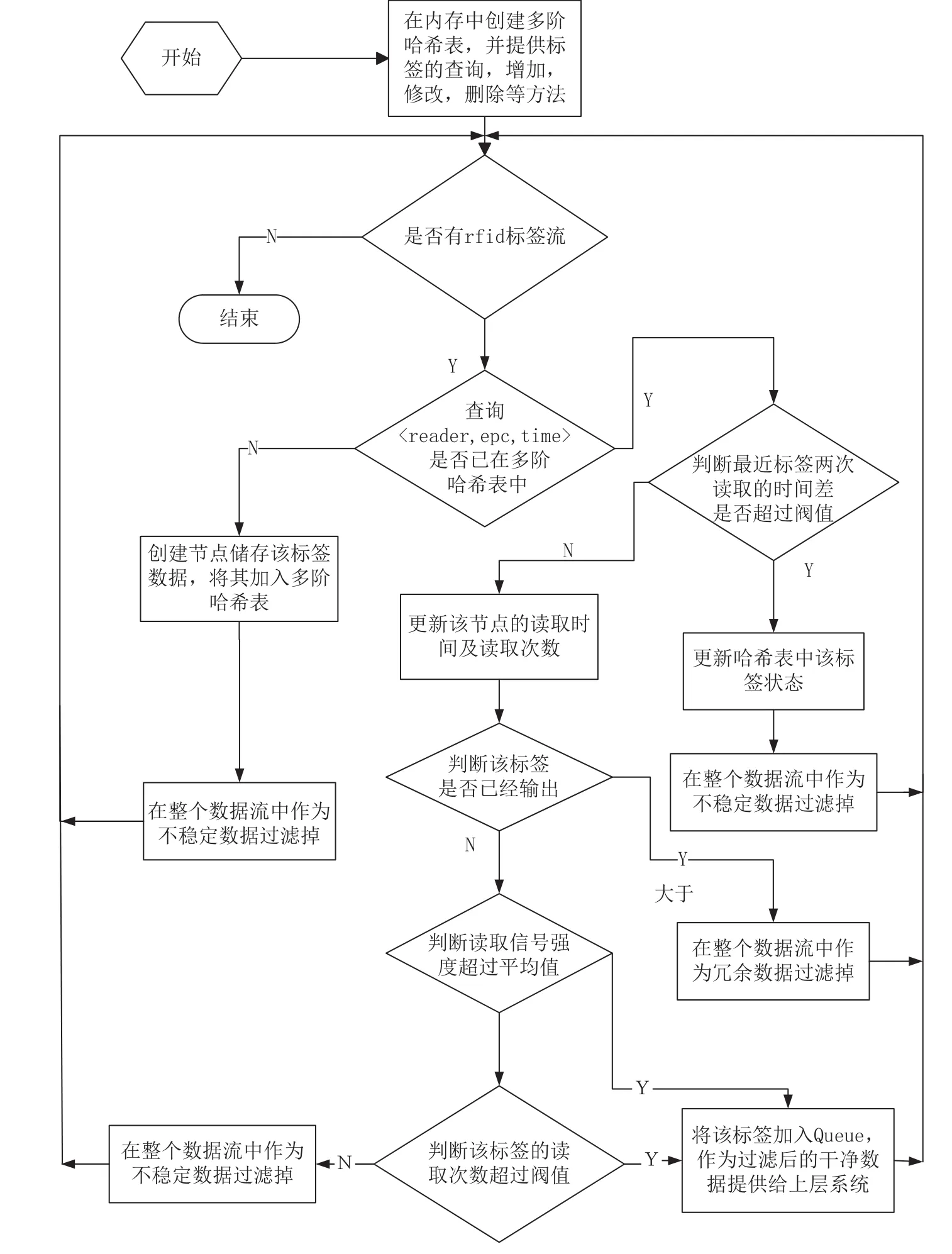
图5 清洗算法流程
第一步,根据项目的应用场景,将有效读取时间阈值Tthreshold设置为100 s,有效读取次数阈值TagCntthreshold设置为5,哈希表的阶数设为10。假定标签的数据规模DataSize为10 000,则可设最大的哈希表桶数M为20 000,以二维数组HashTable[10][20 000]表示多阶哈希表。
第二步,计算每阶的桶数。本实例中,以20 000作为最大的桶数,从第1阶到第10阶,哈希表的各阶桶数依次设定为19 997、19 993、19 991、19 979、19 973、19 963、19 961、19 949、19 937、19 927,存储在数组primeTable中。
第三步,假若在10 s同时有一批标签到来,如表1所示。

表1 标签读取记录表
第四步,对于标签值0000000100,按照f(tagId)=(tagId+M)%primeTable[n]哈希函数计算其在第一阶哈希桶的索引位置index=(100+20000)%19997=103,即是第一阶哈希桶位置103。同理,0000000099在位置102,0000000098在位置101,……,0000000001在位置4。因为设定读取有效次数的阈值为5次,则5次以上读取记录000000005~0000000100无论其读取信号强度最大值与平均值大小如何,其状态均处于observed态,都可将其作为可靠数据输出。值得注意的是,对于标签记录0000000001,虽然其总的次数没有达到阈值,但其读取信号强度最大值超过平均值,所以也认为该标签是稳定数据,直接转入observed状态。通过清洗后,这些标签记录只保留(0000000100,000000099……000000005,000000001)共97个标签值,大大降低了数据规模。这些标签此时均处observed状态,而000000002~000000004标签值则处于captured状态,这些值均作为可疑数据保留在哈希表中而不输出。
第五步,假若在100 s有效读取时间阈值内均没有值为0000000100的标签读取记录,101 s以后,当值为0000000100标签再次被读取到时,由于超过有效的读取时间阈值,所以该标签读取记录实际已经失效处于unknown状态,此时再读到则按照首次读到的标签数据进行处理。
第六步,若此时有标签000020097到来,从第一阶哈希表开始计算,其index1=(20097+20000)%19997=103,因为在该桶已有标签0000000100,产生哈希冲突;接着计算第2阶,其index2=(20097+20000)%19993=111,所以该标签存储在第二阶的索引位置为位置111。多阶哈希数据结构如图6所示。

图6 哈希表数据实例结构
2.6 算法实现
下面给出基于有限状态机的清洗算法实现的伪代码。


3 实验仿真与分析
本实验对本文提出的基于有限状态机的清洗算法,在清洗准确率、清洗的效率以及数据的冗余清洗等方面进行仿真测试。实验使用的对比算法是文献[10]中提到的基于定长的滑动窗口的数据清洗方法,记为fix_size,其中size是滑动窗口的大小。需要说明的是,实验主要使用Visual Studio 2005和Matlab 7.70工具。
3.1 实验数据集来源
实验数据采用IBM的RFID数据生成器,可以按照设置的分布模型生成数据集。该生成器可以通过改变标签的类型、标签与阅读器的距离、标签的移动速率、标签的密集等方式,模拟标签的实际移动过程。
实验中,按<EPC,Time,SS>三元组生成数据集。标签有3个向量特征,数据集每个特征按不同的分布函数生成。其中,RFID数据标签EPC采用随机函数生成,标签的到达时间Time则服从泊松分布,读取信号强度满足均值为0.5、方差为0.05的高斯分布。依照上述方法重复生成数据,根据实验需要调节噪声的比例。
3.2 阈值对准确率影响实验
算法在实验前需要提前设定有效读取时间阈值Tthreshold和读取次数阈值TagCntthreshold。有效读取时间阈值与实际应用场景有着重要联系,目的在于检测到标签的动态性,即判断标签在这个过程有无移动。实验中主要取决于标签的到达时间和生产数据的间隔。为了简单起见,算法中的实验均认为数据是在有效的时间内。
本实验主要用于测试不同的读取次数阈值对准确率的影响。首先按照上述方法产生标签读取记录,间隔200 ms,重复该生成过程10次,标签到达率设置为10 tags/s,设置噪声比例为5%,效读取时间阈值Tthreshold设置为100 s。实验效果如图7所示。
从图7的实验结果可以看出,读取次数阈值设置为3和4的情况下,识别准确率最高,达到96%;当增大其值后,其识别的准确率呈不断下降趋势。这是因为实验的数据只重复生成了10次,数据重复次数不高。但是,读取次数阈值设置太高会将一些正常数据当成多读数据数据,而设置太低则会将一些多读数据当成正常数据,因此需合理设置。

图7 不同读取次数阈值下的数据清洗的准确率
3.3 数据清洗的准确率实验
为了衡量数据清洗的效果,考虑在不同噪声的情况下考察算法的数据清洗准确率。本文算法记为FSM,对比算法则按照窗口的大小依次选择20、50和100,分别记为fix20、fix50和fix100。
数据的准确率是指在清洗后输出的真实数据占总数据的比例。首先上述方法产生标签读取记录,每隔200 ms,重复该生成过程10次,标签到达率设置为10 tags/s,有效读取时间阈值Tthreshold设为100 s,读取次数阈值TagCntthreshold设为3次。这个过程按照0%、10%、20%、40%、60%、80%的比例在读取记录中添加噪声,运行效果如图8所示。

图8 在各种噪声比例下数据清洗的准确率
从图8可以看出,提出的FSM方法准确率整体上优于其他3种基于固定滑动窗口的数据清洗算法,但差距小,与预想的情况一致,即4种算法均随着噪声的比例的增加,准确率呈下降趋势。在噪声比例为0的情况下,可以100%准确识别标签;当噪声比例增加到10%,FSM与fix100识别的准确率在96%,优于其他两种情况;当噪声比例增加到20%时,此时fix100的准确率最高为94%,FSM算法为93%,此后当噪声比例持续增多后,FSM算法因为增加了读取信号强度作为特征,因此比其他3种固定滑动窗口算法表现得更优异。可见,本文提出的基于有限状态机的方法在数据清洗的识别准确率方面是有效的。
3.4 标签到达率对数据清洗的性能影响
本实验考虑到RFID的数据处理有实时性的要求,查看在标签不同到达率情况下各个算法的性能对比。在本文中以每个标签的平均时延作为衡量数据清洗的性能。平均时延,是指每个标签平均清洗的花费时间,其值按照总的数据的清洗时间除以标签的数据量计算。
以项目的实际运行场景为基础,本实验设置噪声比例为5%,有效读取时间阈值Tthreshold设为100 s,读取次数阈值TagCntthreshold设为3次,依次设置标签到达率为10 tags/sec、100 tags/sec,1 000 tags/sec、10 000 tags/sec。按照上述的方法产生标签读取记录,每隔200 ms重复一次,重复10次。
从图9的运行结果分析,FSM在性能表现要大大优于基于固定式滑动窗口的算法。当标签以10 tags/s到达时,各个算法的标签平均时延几乎一致,值为8 ms,此时因为数据规模较小,时间的花费主要用于等待标签的到来。而随着标签到达率的提高,增加到5 000 tags/s,此时FSM算法因为采用了多阶哈希表,其数据的访问效率仍然可以维持在O(1)的时间复杂度,因此当数据增加时,其平均时延始终维持在0.8 ms左右,而固定滑动窗口算法则明显的随着窗口尺寸的增长,其性能呈线性下降趋势。

图9 标签在不同到达率情况下的平均时延
值得注意是,当数据到达率超过5 000 tags/s,此时FSM的性能下降比较厉害,这是因为当数据的规模超过了哈希桶的预设范围以后,数据冲突较为严重,哈希表便退化成为链表,因此根据标签的规模设置哈希桶的大小就非常重要。
3.5 噪声对数据清洗的性能影响
本实验接着查看在不同噪声对数据清洗算法性能影响,同样以每个标签的平均时延作为衡量数据清洗的性能表现。
以项目的实际运行场景为基础,设置标签到达率为100 tags/s,有效读取时间阈值Tthreshold设为100 s,读取次数阈值TagCntthreshold设为3次。按照上述的方法产生标签读取记录,每隔200 ms,重复该生成过程10次,在这过程中按照0%、10%、20%、40%、60%、80%的比例添加噪声,其运行结果如图10所示。

图10 在各种噪声比例下数据清洗的平均时延
从结果来分析,本算法在各种噪声的情况下性能表现优于基于定长滑动窗口的清洗算法,基于定长的滑动窗口的算法性能随着窗口的增加线性下降。整体上看,各个清洗算法对噪声不是很敏感,随着噪声的增加,平均时延缓慢增加。这是因为噪声的增加使得各个正确标签数据在缓冲区停留了较长时间,导致了时延的增加,但总的处理时间变化不大。
3.6 数据的冗余清洗实验
本实验主要考察该算法对标签的冗余数据的清洗结果,并对清洗前和清洗后的数据规模作对比。
按照上述方法产生标签读取记录,将标签到达率设置为10 tags/s,有效读取时间阈值Tthreshold设为100 s,读取次数阈值TagCntthreshold设为3次,依次按照100、1 000、5 000、10 000、50 000、100 000的规模生成原始数据集。考虑到噪声对数据处理的效率影响相当小,因此本实验设置噪声比例为5%,运行结果如图11和图12所示。
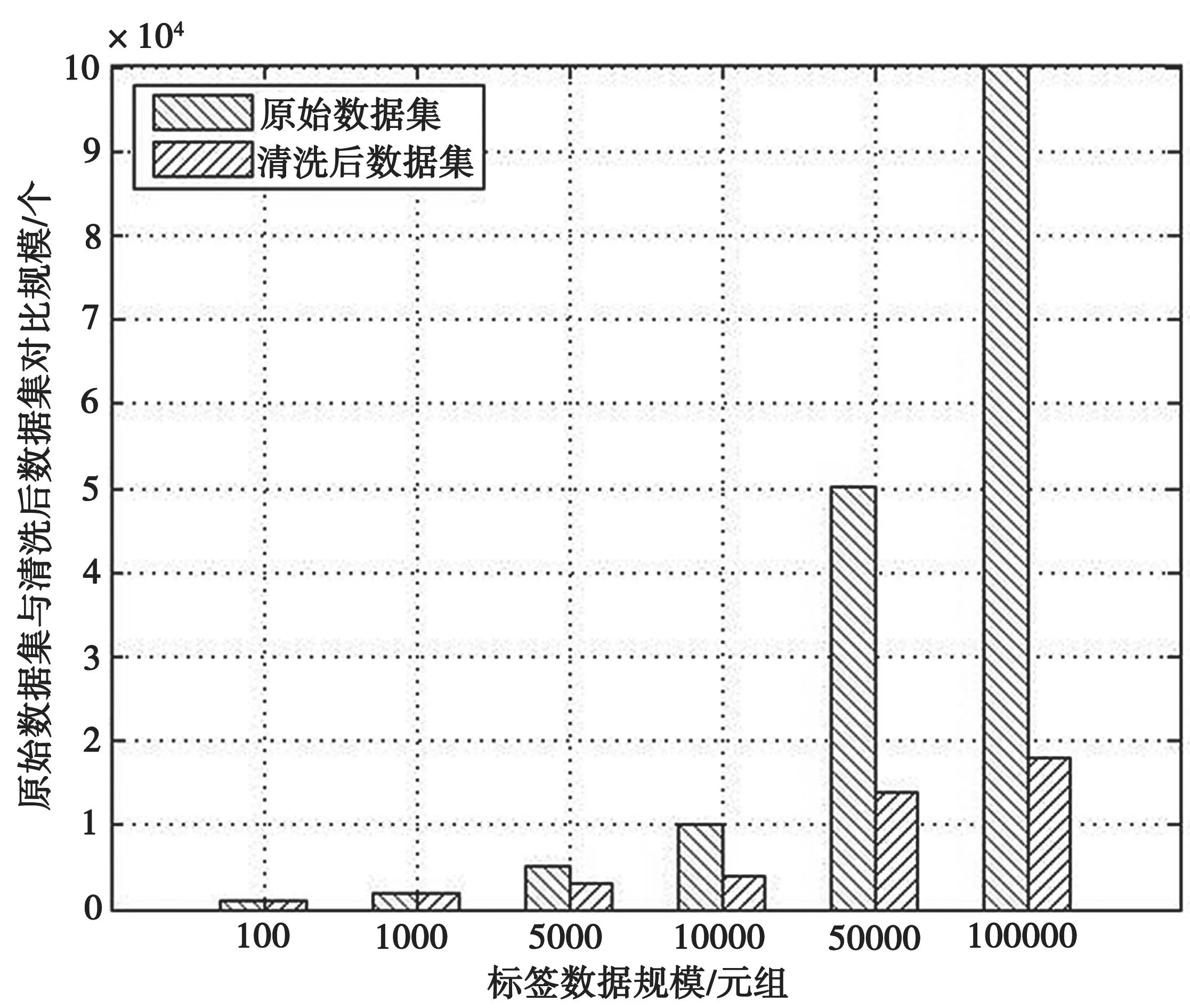
图11 清洗后数据集与原始数据集的规模对比

图12 清洗后数据集与原始数据集的压缩比
从实验结果看,提出的数据清洗算法大大减少了原始数据中存在的冗余数据。当标签数据规模只有100个元组时,清洗后数据仍然有93个元组,压缩比仅为93%;随着数据规模的增长,当数据规模达到10 000时,清洗后数据为4 320个,压缩比为43.2%;当数据规模达到100 000时,清洗后的数据为19 001,压缩比为19%。因此,可以得出结论:随着规模的增长,数据的压缩效果越来越好。实验仿真结果符合预想效果。值得注意的是,具体数据压缩比率取决于数据中冗余的比例,因此本实验的结果只反映了平均情况下的实验结果。
4 结 语
本文通过分析RFID数据特征,针对在海量标签数据中存在的多读、冗余读现象,通过改进滑动窗口的数据清洗方法在处理效率方面的不足,提出了一种基于有限状态机的清洗框架,设计了多阶哈希表存储历史数据,大大提高了数据清洗的效率。
