面向对象的通用数据库访问接口泛化方法研究*
2020-03-26雷明涛施荣荣
雷明涛,李 琼,施荣荣,周 刚,王 磊
(1.中国电子科技集团公司第二十八研究所,江苏 南京 210007;2.武警江苏省总队,江苏 南京 210019)
0 引 言
面向对象作为一种软件开发方法,其概念和应用已经远远超越了软件设计和软件开发的范畴,扩展到如数据库系统、交互式解码、应用平台和分布式系统等领域[1]。面向对象数据库访问技术是支持将数据库的数据当做对象来模拟和创造的一种数据库访问技术,而面向对象数据模型是构成面向对象数据库访问技术的基础[2],面向对象的数据库访问接口设计的关键是其新型的数据模型对象设计,以及数据模型与数据库结构之间的对象匹配。
目前,常用的数据模型与数据库结构之间的对象匹配方法主要有基于OMG的CORBA、Sun的J2EE 和Microsoft DNA的对象关系映射(Object Relational Mapping,ORM)、基于数据字典的对象化匹配和模糊对象匹配。模糊对象匹配方法基于可能性理论和模糊数据的语义测度,通过计算两个模糊对象等价度和必要度实现模糊对象匹配[3],这种方法一般应用于异构数据的集成和清洗,不适用于通用数据库访问;基于CORBA/J2EE/DNA的ORM技术通过使用描述对象和数据库之间映射的元数据,将面向对象语言程序中的对象自动持久化到关系数据库中,从而实现了数据模型与数据库结构的自动匹配[4-8],但当数据库结构发生变化时需要重新构建描述对象,可扩展性较差;而基于数据字典的对象化匹配方法根据数据库元数据生成数据字典[9-12],由数据字典自动构建数据模型,特别是通过自适应数据字典技术在数据库结构和数据模型之间建立“动态耦合”的方法,实现了数据模型随数据库结构的变化而变化的自适应对象匹配[11]。
本文正是基于数据字典的自动对象匹配方法提出了一种面向对象的通用数据库访问接口泛化方法,通过基于数据字典的编解码技术实现数据库访问请求泛化、数据库访问处理泛化和数据库访问结果泛化。
1 数据字典技术
本文提出的这种通用数据库访问接口泛化方法基于自建的数据字典技术,数据字典可以从数据库系统的数据目录中自动化提取,数据字典分为用户数据字典、表/视图数据字典和字段数据字典三类[11],三类数据字典生成后以文件的形式存储,并在数据库访问接口初始化时加载到内存中。数据字典结构及其关联关系示意图如图1所示。
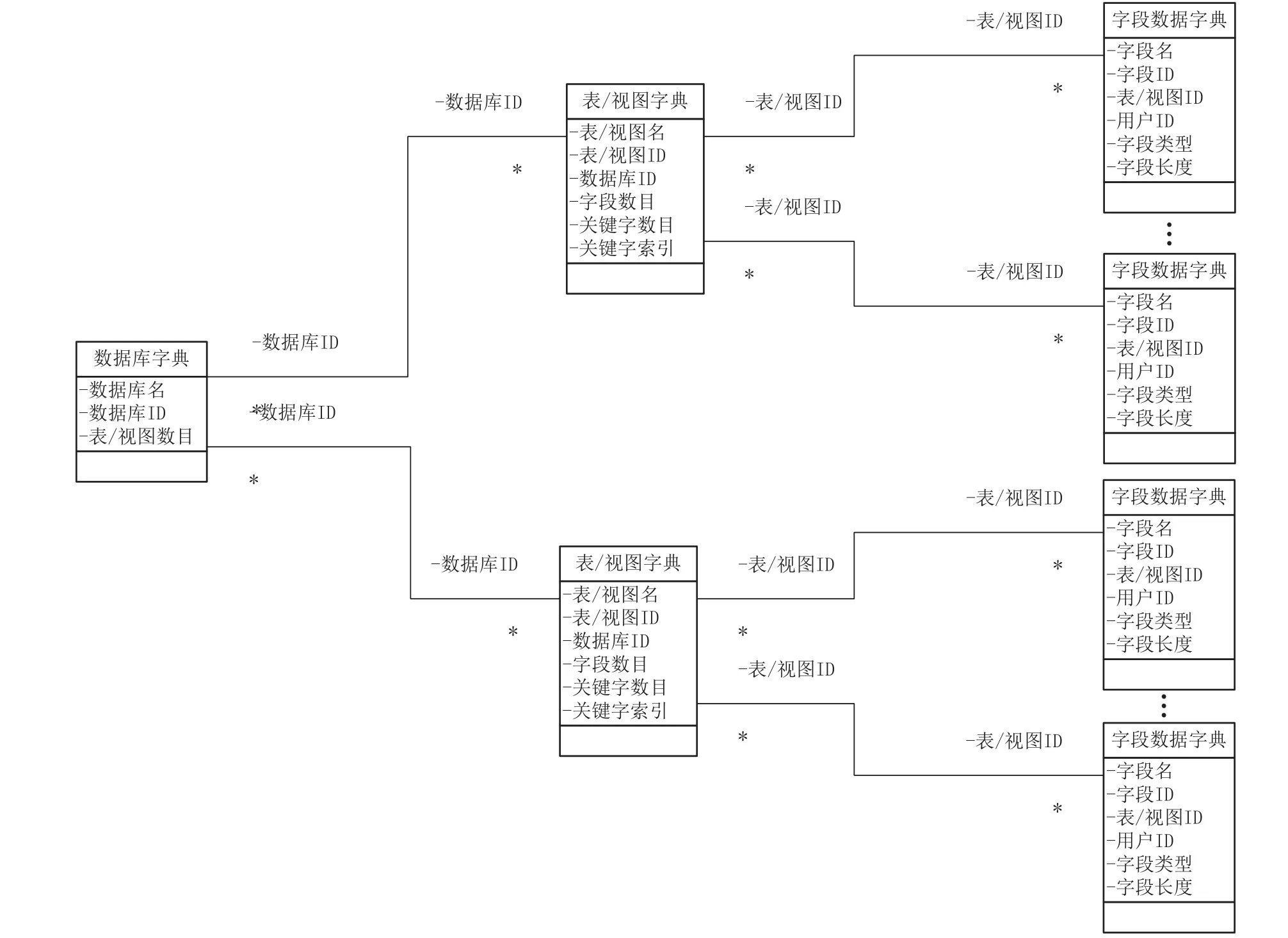
图1 数据字典结构及其关联关系
数据字典文件分为文件头和数据字典内容两部分,文件头的格式相同,文件头和数据字典内容如下:
(1)数据字典文件头:包括文件名、文件长度、记录个数、单个记录的长度,校验码和记录起始位置的偏移量;
(2)用户数据字典:包括用户名、用户ID和用户下的表/视图数目;
(3)表数据字典:包括表名、用户的ID、表ID、表的字段数目、表的主键字段数目和表的主键字段ID;
(4)字段数据字典:包括字段名、用户ID、表ID、字段ID、字段类型和字段长度。
数据字典中的字段类型是与数据库字段类型对应的编程语言中的类型,比如:数据库的整数对应编程语言的整数类型,浮点数对应浮点数,字符串对应字符数组,时间对应时间结构体,字段长度为编程语言中的类型长度。这样根据数据字典就可以自动生成编程语言的数据结构。
2 技术原理
2.1 数据库访问请求自动适配对象
假设用户U有一张数据库表T,表T有m个字段,分别为(T1,T2,…,Tm),根据数据字典生成的编程语言数据结构为S,S的m个数据成员分别为(S1,S2,…,Sm)。表T和数据结构S的对象关系映射示意图如图2所示。
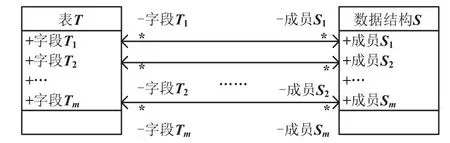
图2 表T和数据结构S的对象关系映射
用户U的数据字典为Du,表T的表数据字典为DT,则字段(T1,T2,…,Tm)的字段数据字典分别为,字段数据字典中字段(T1,T2,…,Tm)的字段长度为(L1,L2,…,Lm),数据结构S的长度为L。
数据结构S的内存存储示意图如图3所示。
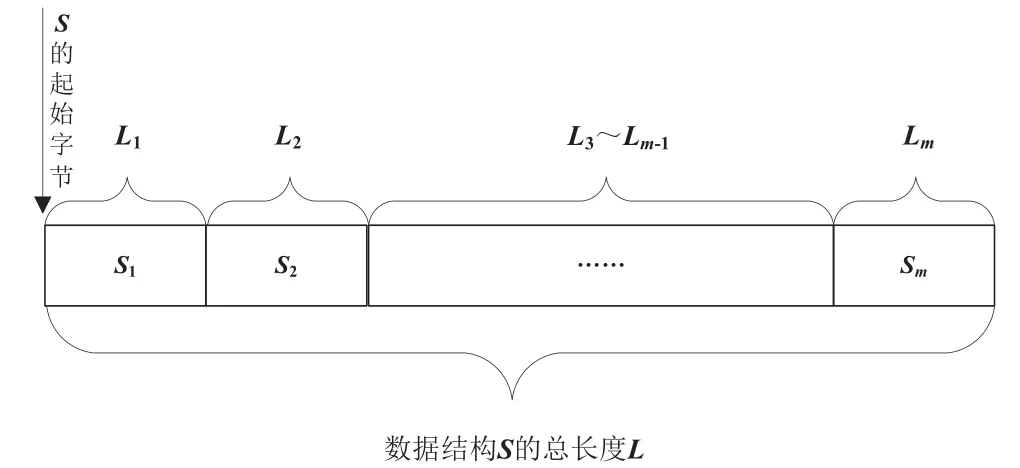
图3 数据结构S的内存存储示意
由图3可知:

数据库访问请求的入参中含数据访问的用户U、表T和泛化后的S的对象指针PS,将数据库访问请求自适应对象的方法为:先通过用户名U找到该用户的数据字典Du,然后根据用户名查到用户U的数据字典Du,再根据表名在Du中找到表T的数据字典DT,进而可以获取表T的字段(T1,T2,…,Tm)的字段字典(DT1,DT2,…,DTm),从字段数据字典中即可获取(S1,S2,…,Sm)在数据结构S中的存储长度(L1,L2,…,Lm)。由公式(1)可知数据结构S的长度L,从指针PS起始的L个字节存储的即为数据结构S的对象。
设(B1,B2,…,Bm)为(S1,S2,…,Sm)在PS中存储的起始字节,则:

则从PS的起始地址,根据数据结构S的成员(S1,S2,…,Sm)的长度(L1,L2,…,Lm)按位读取,即可获取PS指向的类型为S的对象的成员(S1,S2,…,Sm)的值。
设f(x,y)(x<y)表示起始地址为x、结束地址为y的一段内存的存储值,当1≤i≤m时有:

将根据公式(3)获取的数据结构S的成员(S1,S2,…,Sm)与数据库用户U的表T的字段(T1,T2,…,Tm)一一对应匹配,即可实现数据库访问请求中编程语言数据结构与数据库表结构自动适配。
2.2 数据库查询结果自动适配对象
当数据库请求为查询请求时,需要将从数据库中查询到的每条记录转换成编程语言的数据结构的格式。假设:查询所有字段的内容,泛化的指针Po为查询结果起始地址,将查询结果转化为编程语言的数据对象的过程即为将查询到的字段(T1,T2,…,Tm)的值转换成指针Po指向的数据对象S的数据成员(S1,S2,…,Sm)的过程。
使用同2.1中方法同样获取到表T的字段(T1,T2,…,Tm)的字段字典(DT1,DT2,…,DTm)和输出结果的数据类型S,以及其对应的编程语言数据结构S的成员(S1,S2,…,Sm)及其数据长度(L1,L2,…,Lm),依次提取数据库中字段(T1,T2,…,Tm)的值,并将其赋给(S1,S2,…,Sm),然后将Si(1≤i≤m)按位赋给起始地址为Po的地址,即:

根据公式(4)将Po起始的内存地址分为了m份,每份的长度依次为(L1,L2,…,Lm),将Si(1≤i≤m)的值存在第i个单元即可实现数据库查询结果自动适配编程语言数据结构对象。
当查询数据表T的部分字段时,将查询结果自动适配对象的方法与查询全部时类似,假设表T的某个成员Tn(1≤n≤m)没有被查询,则只需要进行查询结果对象化时跳过Sn字段长度为Ln的内存地址,即在1≤i≤n和n<i≤m两个区间分别按照公式(4)为指针Po指向的内存地址赋值,即可实现将查询数据库表部分字段的结果进行自动适配对象。
3 实现方法
3.1 数据库访问请求泛化
为实现数据库访问请求的统一,采用数据字典技术对数据库访问请求进行重新编码的方法进行泛化,这种方法将数据库访问请求泛化为根据数据字典打包后的一段内存指针。数据访问请求要素主要有数据库名称、数据库表/视图名称,数据库操作类型(插入、删除、修改和查询)、表记录数据和查询条件(删除、修改和查询)。数据库请求泛化后的数据请求由数据库请求数据头、数据库表记录数据头、数据库表字段数据头和字段数据值组成。
数据库请求数据头如表1所示。

表1 数据库请求数据头
数据库表记录数据头如表2所示。

表2 数据库表记录数据头
数据库表字段数据头如表3所示。

表3 数据库表字段数据头
数据库请求泛化首先根据数据库名称和表/视图名称获取数据字典中的数据库数据字典、表/视图数据字典和字段数据字典,根据这些数据字典打包请求数据包头和表记录数据包头,然后根据字段数据字典的顺序依次打包字段数据包头和字段值,字段值为按照字段数据字典和图2描述的数据结构S读取的S的成员值,泛化后的数据库请求内存存储示意图如图4所示。

图4 泛化后的数据库请求内存存储示意
3.2 数据库访问处理泛化
数据库访问处理泛化是数据库访问请求泛化的反过程,首先解析数据库请求包头,获取请求中携带的数据请求数目,然后根据数据字典获取数据请求记录操作的数据库、数据表/视图、操作类型、字段名、字段值,然后根据这些要素构建数据库方法访问数据库。数据库访问处理泛化的流程图如图5所示。

图5 数据库访问处理泛化的流程
由于采用了基于数据字典的访问处理机制,对数据访问的处理流程不依赖于数据库和数据库表,可以实现一个数据库访问接口、一个处理流程处理所有数据库表的访问,真正实现了数据库访问处理的泛化。数据库访问处理泛化的具体流程如下:
(1)数据库访问接口收到泛化后的数据库访问请求;
(2)根据请求中携带的数据库ID和表/视图ID查询数据字典;
(3)获取到指定数据库的数据字典、指定表/视图的数据字典以及表/视图下的所有字段的数据字典;
(4)基于数据字典根据图2和图3构造请求对象的数据结构;
(5)根据图3将泛化后的数据访问请求中的数据结构S还原,获取到每个成员的值;
(6)根据图2将还原后的数据结构S的数据成员与数据库表的字段自动适配;
(7)根据请求中的数据库操作类型构造数据库方法并访问数据库。
3.3 数据库访问结果泛化
当数据库访问请求为插入、更新和删除等数据操纵语言(Data Manipulation Language,DML)操作时,直接返回数据库访问成功与否即可,此处不再赘述;当为数据查询语言(Data Query Language,DQL)查询操作时,数据库访问接口除返回成功与否外,还需要提供查询结果的提取功能,基于数据字典的数据库访问处理机制,同样可以实现一个数据库查询结果提取接口、一个查询结果提取流程适用于所有数据库表的查询结果提取,将查询结果转化为编程语言数据对象的格式,可以供编程语言以该数据对象的形式直接访问,从而实现了数据库查询结果的泛化。数据库查询结果泛化的处理流程图如图6所示。

图6 数据库查询结果泛化处理流程
数据库查询结果泛化的具体流程如下:
(1)根据数据库用户名和表/视图名查询数据字典;
(2)获取到指定数据库的数据字典、指定表/视图的数据字典以及表/视图下的所有字段的数据字典;
(3)基于数据字典根据图2和图3构造查询结果在编程语言中对象的数据结构;
(4)逐个提取查询结果的字段值;
(5)根据图2和图3中所建立的数据库表字段与编程语言数据结构成员的对象化关系,实现数据库查询结果与编程语言数据结构的自动适配,将查询结果转化为编程语言数据对象的格式;
(6)将所有字段提取完毕后,数据访问接口以编程语言对象的形式向应用返回查询结果。
4 结 语
本文基于数据字典技术,提出了一种通用数据库访问接口的泛化方法,通过数据库请求的泛化实现对数据库访问接口的标准化,通过对数据库访问处理的泛化实现了数据库访问处理流程的标准化,通过数据库查询结果的泛化实现了查询结果提取接口的标准化,通过对数据库访问处理的泛化和数据库查询结果的泛化实现了对所有数据库表处理的标准化,从而实现了同一套数据库接口对数据库所有表的DML和DQL操作。经实践验证,基于数据字典的通用数据库访问接口泛化方法能够实现面向对象的数据库访问中间件与数据库结构的“解耦和”,具有良好的通用性。
