基于LightGBM 模型的二手房房价预测研究
2020-03-15慕钢张宏烈党佳俊李广峰
慕钢,张宏烈,党佳俊,李广峰
(1.齐齐哈尔大学 计算机与控制工程学院,黑龙江 齐齐哈尔 161006;2.齐齐哈尔克东县第一中学,黑龙江 齐齐哈尔 164800)
当前房地产业发展迅速,成为了国民经济的重要支柱产业.随着国家对房地产业的调控,二手房在市场上所占比重也在不断增长.无论新房还是二手房,其房屋价格的未来走势越来越受到人们的普遍关注,因此采用机器学习算法开展房屋价格预测研究非常有必要.它不仅能为群体大众买卖房屋提供建设性的引导意见,还会对当地政府合理地规范房地产市场提供重要的数据支持.
目前,存在众多的因素对房价的发展趋势造成影响,包括房屋地理位置,周围环境配套设施,该地区的房屋销售价格,人均GDP等.在房屋预测的方法上,许多学者选择机器学习算法建立了不同的房价预测模型.如2009年Onurözsoy[1]使用分类和回归树(CART)等方法分析了房价的主要影响因素,结果表明房屋大小、有无电梯等是房价的重要影响变量.Runeson[2]等比较人工神经网络(Artificial Neural Network,ANN)和对数线性回归模型(Log-linear regression,LR),实验证明LR效果更佳.魏云云[3]等通过采用灰色模型(Grey Model,简称GM模型)与BP神经网络结合建立模型对房屋价格进行预测等.这些方法存在着共同的缺点:拟合优度欠佳,运行效率慢.本文应用LightGBM算法,面对房价波动影响较大的30多个特征,进行数据分析和处理,通过模型统计推出房屋价格.
1 数据处理
1.1 数据获取
为了能够对房屋价格未来运行趋势做出合理的预测,大量以及准确的基础数据是不可或缺的,本次研究通过爬虫方法,从链家网上爬取了2018年上海市二手房房价的数据以及信息[4],获得61 609条数据,每个数据共有30多个属性.
1.2 缺失值处理
从网上爬取的基础数据中难免会不完整,某些数据存在着偏差或者缺失,本实验使用随机森林算法对Unknown值进行推测,处理后的数据写入数据所在的data_r.csv文件中.
2 房屋数据分析
使用Pycharm软件对爬取的数据进行统计分析,发现很多因素影响着房屋的价格.如房屋的年龄一定程度上决定着房屋的价格,所以对房屋的年龄进行了统计[5](见图1).由图1可以看出,在售的二手房中新房只有少数,大部分的房屋年龄超过5年.此外房屋面积也是房屋价格的重要参考因素(见图2).此外对于房屋来说,地理位置很大程度上决定着房屋的数量,如发达的区域,人口密度就会相对较大,住房的需求也就随之提升,房屋数量相对比较多(见图3).当然地理位置与房屋价格也密切相关(见图4),而房屋地理位置分布情况见图5.
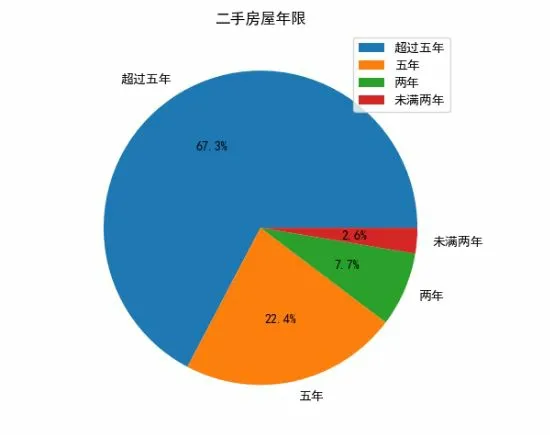
图1 房屋年龄

图2 住房面积与价格之间的关系

图3 各地区房屋数量示意图

图4 地理位置与价格之间的关系
3 LightGBM 模型
3.1 GBDT 模型和XGBoost 模型
GBDT(Gradient Boosting Decision Tree,梯度提升决策树),是最好的机器学习算法之一,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点.

图5 房屋地理位置分布
XGBoost是一个优化的分布式梯度增强库,它在Gradient Boosting框架下实现机器学习算法.XGBoost提供了并行树提升,可以快速准确地解决许多数据科学问题.XGBoost的可扩展性归功于几个重要的系统和算法优化.这些创新包括:一种新颖的用于处理稀疏数据的树学习算法,理论上合理的weighted quantile sketch过程能够在近似树学习中处理实例权重,引入一个新颖的稀疏感(sparsity-aware)算法用于并行树学习,一种有效地缓存感知块结构用于核外树学习.
但是这2个模型的缺点也非常明显,(1)在每轮迭代时,都需要遍历整个训练数据多次.如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间.(2)预排序方法的时间和空间的消耗都很大.所以本文基于LightGBM模型对数据进行处理和优化.
3.2 LightGBM 模型原理
LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练.LightGBM模型包含很多实现优化功能的部分:如基于Histogram的决策树算法,带深度限制的Leaf-wise叶子生长策略,直方图做差加速,直接支持类别特征,Cache命中率优化,基于直方图的稀疏特征优化,多线程优化等.
其中Histogram算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图.在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点,其优化过程见图6.

图6 Histogram算法优化过程
使用Histogram算法有很多优点,最明显就是内存消耗的降低.Histogram算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8,从而解决了GBDT模型和XGboost模型的弱点.不仅如此,在Histogram算法基础上,LightGBM又进一步优化.它摒弃了大多数GBDT工具使用的按层生长(level-wise)的决策树生长策略,而使用了带有深度限制的按叶子生长(leaf-wise)算法.Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环.Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合.因此,同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度(见图7~8).

图7 按层生长的决策树策略

图8 按叶生长的决策树策略
4 不同算法对比
本研究针对2018年上海市二手房数据集,分别使用线性回归、KNN、神经网络、XGBoost[6]和LightGBM算法进行预测并且对比.在测试集中计算模型的拟合优度R2作为算法的评判依据,也是预测结果,R2的计算公式
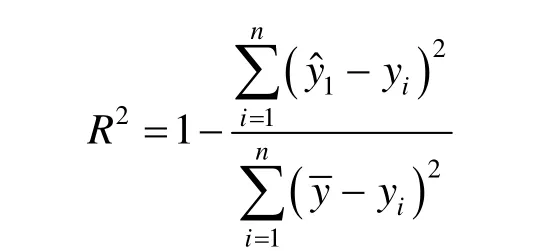
对数据集来说,训练集与测试集按照8∶2的比例进行随机抽样,通过参数优化以及特征选择之后,在训练集上对模型进行训练,最后得到各算法的训练拟合优度.本研究使用Python语言编写算法,运行结果见图9~13,各类算法拟合优度对比见表1.
在测试中,LightGBM效果最佳,R2达到0.883 078 131 800 733 6,其次是XGBoost[7],而KNN效果最差.可见,在拟合优度方面,LightGBM[8]模型优于XGBoost模型0.829 926 118 494 329 3的拟合优度值.
图9 线性回归

图10 KNN回归
图11 神经网络回归

图12 XGBoost模型
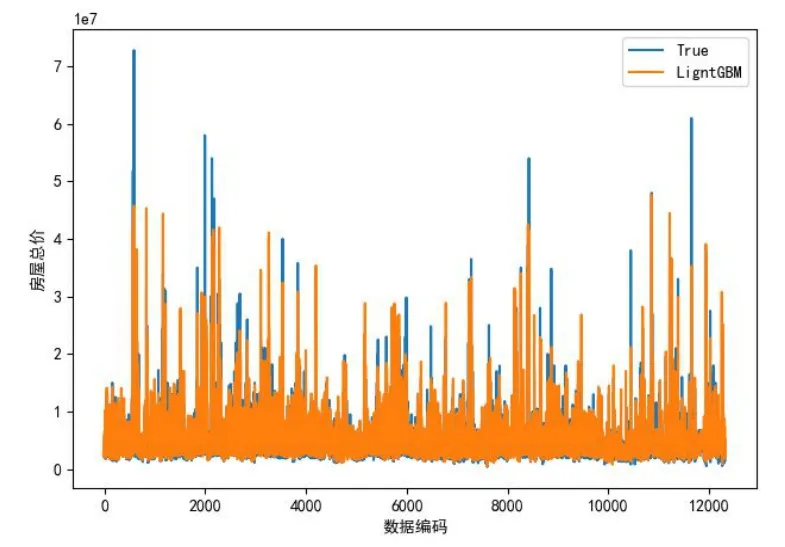
图13 LightGBM模型

表1 各类算法拟合优度对比
5 结语
本文对网上爬取获得的数据集进行了多元分析,从数据处理策略和数据训练形式等方面对常用的机器学习算法进行了对比,提出了基于LightGBM算法的房价预测模型.通过对数据集的随机抽样分割为训练集和测试集,并在测试中对几种模型进行了评估.评估结果表明,LightGBM模型的预测效果最好,有相当稳定的鲁棒性,该房价预测模型具有一定的实用性.
