Mesh Shading实时渲染中Meshlet的生成实现
2020-03-15余德民
余德民
(四川大学计算机学院,成都 610065)
0 引言
2018年9月,NVIDIA推出了RTX Turing架构显卡【1】,其中一大特性便是 Mesh Shading 技术【2】。Mesh Shading技术主要内容是通过在Mesh Shading Pipeline上执行渲染,从而实现高质量、高效率渲染。Mesh Shading Pipeline是一种新的可编程几何渲染管线。它有着与现代可编程渲染管线(下文简称现代管线)完全不同的图元生成流程。众所周知,常规操作下,现代管线的输入是一组能够代表一个网格的Vertex Buffer和Index Buffer,顶点处理阶段通过图元分配器读取Index Buffer产生指定图元任务,之后渲染管线单个线程的处理对象都是该图元【3】。而 Mesh Shading Pipeline中,输入是一组能够代表一系列网格簇,即meshlet的内存结构,meshlet和网格层次关系如图1所示。网格由多个meshlet组成,meshlet可以从网格中生成。Mesh Shading Pipeline不通过图元分配器产生图元任务,而是在Task Shader阶段决定Mesh Shader工作组个数,之后在Mesh Shader阶段根据内存数据动态组装meshlet。整个过程中,meshlet内存结构和其组装方法都由用户自定义。
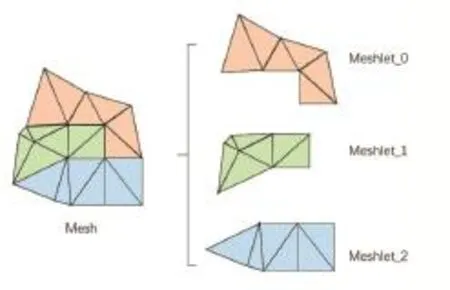
图1 Mesh和Meshlet关系示意图
Meshlet需要从网格生成,但并不能随意生成。Mesh Shading Pipeline是为了执行高质量、高效率渲染而产生。我们需要利用Mesh Shading Pipeline独有的特性执行高效渲染。而meshlet生成质量和Mesh Shading Pipeline渲染效率息息相关,所以如何从网格生成meshlet对于Mesh Shading Pipeline实时渲染来说是一个非常值得研究的问题。
1 相关技术介绍
本文提出的算法所生成的meshlet是为Mesh Shading Pipeline高效实时渲染提供支持。所以需要对Mesh Shading技术进行研究,以确定 meshlet生成标准。
本文在Task Shader阶段通过执行剔除,减少之后
1.1 Mesh Shading技术
作为本课题的基础技术,我们有必要对Mesh Shading Pipeline进行深入研究,在实现Mesh Shading Pipeline高效实时渲染的同时,讨论对Mesh Shading Pipeline友好的meshlet结构。本节分为着色器、内存结构和网格生成共三部分对其进行介绍。
(1)着色器概述
Mesh Shading Pipeline中两种新的着色器Task Shader和Mesh Shader都以一种类似于计算着色器(Compute Shader,CS)的工作方式进行协同并行工作。
两种新的着色器中,Task Shader阶段主要功能是动态分配Mesh Shader工作组数量,为其提供网格组装、后续渲染所需信息。在应用中,这一信息通常可能是,当前Task Shader产生的Mesh Shader总数、需要进行渲染的Meshlet ID等。
Mesh Shading Pipeline中,Task Shader阶段不产生任何顶点,所以输出网格的任务完全交给Mesh Shader阶段。Mesh Shader阶段的主要功能是动态组装网格并将其输出到光栅化阶段。
二者之间存在着树状结构,如图2所示。Mesh Shader工作组的生成个数由作为其父节点的Task Shader工作组决定。正是由于这一树状结构,Mesh Shader的工作可以由Task Shader动态分配。而Mesh Shader阶段恰好是Mesh Shading Pipeline中光栅化前性能开销最大的阶段。且由于Mesh Shader工作组会组装并输出meshlet,需要缓冲区保存meshlet。所以Mesh Shader工作组数量越多,整个管线并行度越低,效率越低。所以在Task Shader阶段执行剔除、Level of Detail(LoD)等操作会带来非常明显的效率提升。
(2)Meshlet生成概述
一个Mesh Shader工作组通过gl_MeshVerticesNV[]、gl_PrimitiveCountNV 和 gl_PrimitiveIndicesNV[]这三个内建变量定义一个输出的meshlet。我们需要在Mesh Shader编程,填充内建变量以输出正确meshlet。现对上述内建变量进行简要说明。Mesh Shader阶段所需的工作组数量,以实现渲染效率的提高。所以需要对剔除技术进行研究,以生成有助于提高剔除效率的meshlet。
本节将分为Mesh Shading技术和剔除技术共两部分进行简要介绍。

图2 Task Shader和Mesh Shader树状结构
gl_MeshVerticesNV[]用于存放当前Meshlet的顶点位置及剔除裁剪相关信息,包括了gl_Position、gl_PointSize、gl_ClipDistance[]和 gl_CullDistance[],数据结构如下:

gl_PrimitiveCountNV表示Mesh Shader将要输出的三角形面片数,由一个无符号整型表示。
gl_PrimitiveIndicesNV[]中存放图元索引,由一个无符号整形数组表示。
(3)内存结构说明
NVIDIA推荐的内存结构如图3所示。其中包括网格簇描述信息缓冲(Meshlet Desc(ribe)Buffer)、顶点索引缓冲(Vertex Index Buffer)和图元索引缓冲(Primitive Index Buffer)共三部分。在组装meshlet的过程中需要根据其中信息进行。现对各个内存结构作出简要说明。
Meshlet Desc Buffer:存放每个 meshlet的 Meshlet Desc。Meshlet Desc是一种结构体,在Nvidia推荐的内存结构中,其主要存放用于辅助组装meshlet的信息,包括顶点起始偏移值(Vertex Begin)、顶点个数(Vertex Count)、图元索引偏移值(Primitive Index Begin)和图元索引个数(Primitive Index Count)。当然,Meshlet Desc中还可以存放一些用于辅助meshlet进行剔除计算的信息,例如:包围盒顶点,包围锥方向、中心点等,用于Task Shader阶段的剔除。
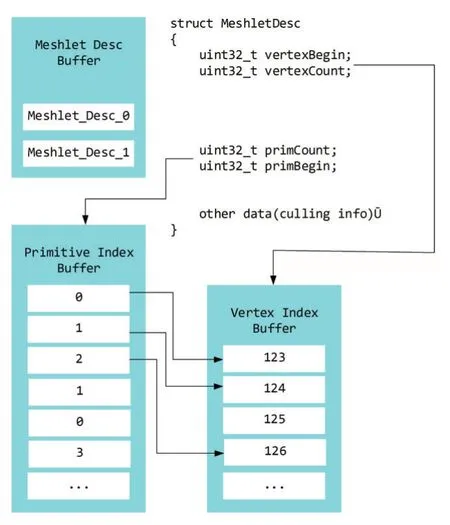
图3 Meshlet内存结构
Vertex Index Buffer:连续存放着顶点索引。根据当前Mesh Shader工作组的MeshletDesc中的vertexBegin和vertexCount在其中进行取值。通过这些索引,可以在Vertex Buffer中找到对应顶点,写入gl_MeshVerticesNV[]。
Primitive Index Buffer:连续存放着三角面片顶点索引。这些索引用8位无符号整形保存。根据当前Mesh Shader工作组的MeshletDesc中的primBegin和primCount在其中进行取值,顺序写入gl_PrimitiveIndicesNV[]。这些索引作为当前Mesh Shader的局部索引,Mesh Shader工作组在组建meshlet时,可以在当前Mesh Shader工作组的gl_MeshVerticesNV[]中通过上述索引找到对应顶点。
上述内存结构使Mesh Shader工作组内顶点信息共享成为可能,提高了顶点复用率,降低了索引内存空间大小,提高了带宽使用率,从而改善效率。我们可以通过提高顶点复用率,减少meshlet数量,从而减少Mesh Shader工作组数量,以达到提升效率的目的。
虽然本文主要内容是Meshlet生成算法,但后文也会对内存的生成进行简要叙述。
1.2 剔除技术
如上文所述,在Task Shader阶段对meshlet进行剔除、Lod等操作会是一个十分高效的选择。然而,高效的剔除算法也需要高效的剔除辅助信息,如:包围盒、包围锥等。本小节将会简述各剔除算法原理,并根据其算法特性讨论其对meshlet的要求。
(1)视锥体剔除
视锥体剔除算法由于其易实现、效率收益高的特性,成为了当今渲染引擎中最常用的一种可见性剔除算法。其基本思想是对物体和视锥体进行空间关系判断,对包围体完全在视锥体外的物体进行保守剔除。
由于是保守剔除,我们就需要尽可能使不可见网格被剔除,以达到较高的剔除效率。因此,生成的meshlet需要尽可能紧凑。
(2)网格簇朝向剔除
网格簇朝向剔除算法【4】利用网格簇法线包围锥【5】信息及视点朝向,在网格簇包围盒各顶点对网格簇朝向进行保守判断,从而对完全背向的网格簇进行剔除。判断公式如下:
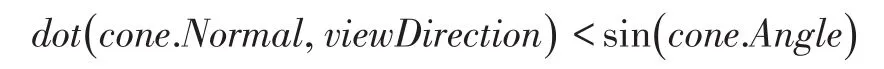
该剔除方法及其原理较为复杂,本文中不进行展开叙述。我们只需要知道,该方法中法线包围锥夹角越小,剔除效率就越高。这就要求Mehslet尽可能是连续凸平面,使其中法线变化尽可能小。
2Meshlet生成算法
2.1 算法需求分析
本算法在离线计算中使用,不会影响到实时渲染效率。所以,本文中算法并不着重考虑效率。本算法主要目的是为Mesh Shading Pipeline的实时渲染提供支持,以使其达到更高的渲染效率。所以生成所得meshlet的质量才是是本算法最为重视之处。
如上文所述,在此总结,生成的meshlet需要满足三个条件:
●高网格紧凑度。使视锥体剔除达到较高的效率。
●高顶点复用率。降低Mesh Shader工作组数量,降低顶点计算量。
●网格连续。使网格簇朝向剔除达到较好效率。
通过K-means等传统聚类方法,根据顶点和图元的空间信息,如:顶点坐标等,进行聚类,能够获得最为紧凑的meshlet,对视锥体剔除极为友好。但是基于空间信息的聚类方法极有可能将顶点距离相近但并不连续的三角形划分成一类,常见的错误就是将薄网格的正反面划分到一个meshlet。这种错误会使网格簇朝向剔除完全失效,且降低顶点复用率,从而降低渲染效率。这是我们不能接受的。
因此,我们不应该基于网格空间信息,而应该基于网格几何拓扑信息进行meshlet生成,即生成几何连续的meshlet。在一些模型处理软件中,如:CAD、MAYA等,生成并输出的模型网格,其索引以连续三角形条带形式组织并保存。对于以这种形式保存的索引,无需进行额外处理,仅对其按序读取图元就能得到连续的三角形条带作为meshlet。这样生成的meshlet能确保网格连续,对网格簇朝向剔除友好。但由于其索引缓冲的组装基于顶点缓冲线性优化策略【6】,所以在填充索引缓冲时,该方法总是会在剩余三角形中找到与最近插入三角形共用点最多的三角形,并将其添加到索引缓冲,然后重复上述步骤。因此通过该方法生成的大多是狭长的且扭曲的三角形条带,导致其网格紧凑度极差,且顶点复用率不高。所以,该方法不是最优方案。
为了便于理解,我们认为顶点缓冲线性优化策略是基于深度优先生成的三角形条带。与之相对,我们可以尝试基于广度优先思想生成三角形条带。与顶点缓冲线性优化策略相同,我们可以根据三角形的三条边进行广度优先遍历生成meshlet。同时,本文提出,可以尝试根据三角形的三个顶点进行广度优先遍历生成meshlet。为了确定两个方法的优劣,在此做出简单推导演示,如图4所示。

图4 三角形条带迭代生成示意图
图4 中,从上至下分别为第0-3次迭代生成三角形条带的结果。绿色三角形为上一次迭代生成的三角形,红色三角形为这次迭代生成的三角形。左列为基于共用边的结果,右侧为基于共用点的结果。我们将网格面积与二维网格包围盒面积之比作为网格紧凑程度评判标准,该值越高,代表网格越紧凑。观察推导后,我们可以发现,在第n次迭代时。
基于共用边生成的网格紧凑程度为:
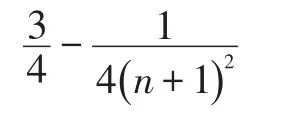
基于共用点生成的网格紧凑成都为:
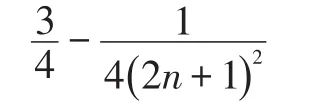
可以发现相同迭代次数下,基于公用边生成的meshlet紧凑程度不如基于共用顶点生成的meshlet,且生成相同数量的meshlet图元,基于共用点需要更少的迭代次数,效率更高。所以本文决定,实现基于共用顶点的meshlet生成算法。
2.2 输入与输出

本算法输入为待处理的模型网格数据、生成meshlet的最大顶点个数和最大图元个数。如今模型网格数据通常由一个顶点缓冲和一个索引缓冲表示。所以本算法中,输入的网格数据包括顶点数据和索引数据。其中顶点数据为指定数据结构的数组。该数据结构中包括顶点坐标、纹理坐标、顶点法线等。索引数据为32位无符号整型数组。网格数据结构和顶点数据结构如下:
输出为代表meshlet的数据结构数组。数据结构中存放组成meshlet的三角形顶点索引。这些索引由32位无符号整型表示。meshlet对应数据结构如下:

2.3 算法描述
我们对存放原始网格索引的待处理队列进行遍历,将待处理队列命名为MeshIndexSet,找到与当前meshlet中任意三角形有共用顶点的三角形,将该三角形的索引值从待处理队列中移除并添加到meshlet.index中。直到达到meshlet最大顶点数或最大图元个数,输出当前meshlet,重复上述步骤,开始新meshlet的生成。当MeshIndexSet为空,输出当前meshlet,退出循环。详细流程如下:
(1)选取MeshIndexSet队首的三个顶点索引组成三角形,加入当前meshlet,作为初始三角形,该meshlet即为这次循环将要生成的meshlet。
(2)循环遍历 meshlet.index,遍历 MeshIndexSet,找出有坐标相同的顶点,得到其所属三角形。将该三角形的索引值加入meshlet,并将对应索引从待处理队列中移除。
(3)在第(2)步的执行过程中,可能出现如下情况:
●meshlet达到其所能容纳的最大顶点数和最大图元数。输出当前meshlet,结束对当前meshlet.index的遍历。若MeshIndexSet不为空,回到步骤1;否则,退出算法。
●meshlet没有达到其所能容纳的最大顶点数和最大图元数,但meshlet.index已经完成遍历。这表明,在输入网格中已经没有与当前meshlet相邻的三角形。根据前文,三角形过少的meshlet对于mesh shader中meshlet的组装是不利的。所以在这种情况下,我们会在MeshIndexSet中寻找与当前meshlet距离最近的三角形,将其添加到meshlet.index,继续遍历。因为在分配的Mesh Shader工作组时,会有执行单元处于空闲状态,从而造成资源的浪费。所以为了减少面片数少的cluster的数量
●meshlet没有达到其所能容纳的最大顶点数和最大图元数,但MeshIndexSet为空,即没有剩余三角形。这种情况下,我们将该meshlet输出,退出循环。
流程图如图5所示。
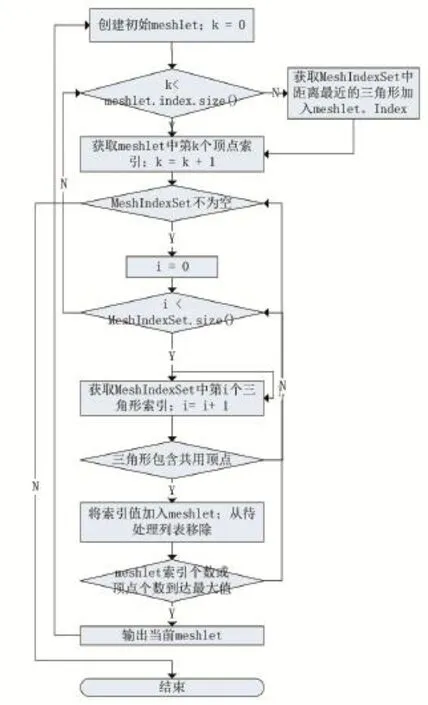
图5 Meshlet生成算法流程图
3 Meshlet内存结构生成
如上文“内存结构说明”所述,我们需要根据Vertex Index Buffer、Primitive Index Buffer和 Meshlet Desc Buffer在Mesh Shading Pipeline中动态组装网格。本节将其生成方式简述如下:
①为当前网格创建用于存放Primitive Index的集合 Primitive Index Set,用于存放 Vertex Index的集合Vertex Index Set和用于存放Meshlet Desc的Meshlet Desc Set。
②遍历每个meshlet。
③为每个meshlet创建一个用于存放当前meshlet的Vertex Index-Primitive Index键值对的空映射表M,以及一个用来代表当前meshlet属性的Meshlet Desc。
④Meshlet Desc中起始顶点索引偏移值等于Ver-tex Index Set当前元素个数。起始图元索引偏移值等于Primitive Index Set当前元素个数。
⑤遍历当前meshlet的meshlet.index。
⑥若M中不存在键值等于当前顶点索引i,则向Vertex Index Set加入i。映射表中进行如下操作,M[i]=M.size()。
⑦向Primitive Index Set加入M[i]。
⑧每次遍历完成后,根据遍历结果,填充Meshlet Desc中的数据,加入Meshlet Desc Set。其中顶点索引个数等于M元素个数;图元索引个数等于Primitive Index Set当前元素个数减Meshlet Desc起始图元索引偏移值。
⑨Vertex Index Set、Primitive Index Set和 Meshlet Desc Set中数据即为对应内存数据。
4 算法效果
根据本文算法生成的meshlet在Mesh Shading Pipeline 中对 Stanford Bunny【8】渲染效果如图 6 所示。其中不同的颜色即代表不同的网格簇。从图中可以观察到,大部分生成的meshlet满足前文所说的三个条件。在显卡为RTX 2070实验环境下,开启视锥体剔除和网格簇朝向剔除,Mesh Shading Pipeline平均实时渲染帧率为3700fps,现代管线平均渲染帧率为3200fps。

图6 Meshlet渲染效果
5 结语
本文对相关技术进行了全面概括,对算法进行了简要分析,给出了生成meshlet的基本思想和基础算法流程,并简述了如何生成meshlet内存结构。通过本文算法生成的meshlet在Mesh Shading Piepline中进行实时渲染具有良好效率。该算法具有实际意义。
