一种改进的多维度并行匹配发布与订阅算法
2020-03-15张澧枫殷铭袁平
张澧枫,殷铭,袁平
(1.四川大学计算机学院,成都 610061;2.东华大学信息科学与技术学院,上海 201620;3.重庆第二师范学院数学与信息工程学院,重庆 400067)
0 引言
物联网时代伴随5G技术的发展,不同领域的数据被联系在一起,使得数据采集和传输过程生成的数据成指数级增长[5]。与十年前相比,以往的数据采集系统和工具已经很难满足现有的场景性能要求。发布订阅是指通过一个中间件将通信的两端从时间和空间上解耦,是一种常见的通信方式。发布订阅有三种常见的类型:基于主题、基于频道和基于内容[2],基于主题和基于频道虽然实现简单且使用普遍,但是表达能力远远不及基于内容的模式,而一个高效的匹配算法是基于内容的发布订阅最关键的部分。
提升匹配算法的关键是设计高效的索引结构和快速的匹配过程[3]。REIN算法以一种流水线式的方式将不同维度匹配的结果串联起来,上一个维度匹配的结果是下一个维度的输入,减少了不必要的搜索空间。但是整个过程是单维度串行匹配,在还没有得到上一个维度的匹配结果时当前维度不会开始匹配。另外,REIN算法在做订阅划分的时候,为了匹配的方便订阅需要有序的插入到订阅表中,然而链表有序插入的时间复杂度为O(n),当数据规模很大时订阅的插入和匹配速度会很慢。本文提出了一种多维度并行匹配算法,充分利用CPU资源提高匹配算法的速度,并且改进了REIN算法中索引结构的设计,利用跳跃表在匹配和插入上的高效,提升了插入和匹配的效率。
实验结果表明,本文提出的多维度并行搜索机制和跳跃表索引结构在匹配速度上有提升,并且插入和删除的速度也有提升,这对于频繁订阅和取关的场景有很大的意义。整个算法的提出使得在面对大规模发布订阅场景时,仍然能够具有不错的性能。
1 算法分析与系统设计
1.1 MP-REIN数据模型
MP-REIN是一个基于内容的多维度范围匹配模型,维度定义为,m是维度数目。订阅集合表示为,n是当前订阅空间的大小。订阅是由Si包含的所有属性的区间组成的集合,表示在属性am上Si的区间约束。约束具有不同的值包括(<,≪,>,≫,=,≠)。事件表示为E={v1,…,vm}。
事件匹配结果分为部分匹配和全部匹配,如果Si上某几个维度上的区间包含了事件E中vm的值,称之为事件E与Si部分匹配,如果Si和E在全维度上匹配则称之为全维度匹配,只有全维度匹配的订阅才会收到对应的事件通知。
1.2 跳跃表索引结构
REIN算法的核心思想是尽早的标记不匹配的订阅,减少后续维度的事件匹配订阅空间大小,其索引结构是由多个桶链表组成,这种索引结构在遇到大量订阅落到某个独立的桶时,因为链表查找和插入效率速度有限,事件匹配的效率就会大大降低。同时,REIN算法对每个维度建立两条桶链,一条是对指定属性的下边界范围约束,另一条是对指定属性的上边界范围约束。桶链的建立是通过划分属性值域为多个单元,每个桶内存储值域在该区间的订阅。REIN的索引结构如图所示。这种存储方式带来了额外的匹配,且增加了额外的内存开销,MP-REIN针对REIN的不足对索引结构进行了改进。
跳跃表在工程中使用广泛,是一种随机化数据结构,大多数操作如查找和插入的平均时间复杂度都为O(logn)。跳跃表是由多层有序链表关联的数据结构,层级越高元素个数越少,每次查找或者插入时会随机选择一层开始,向链表末尾移动,如果在本层并没有找到元素,就会在下一层向前查找,直到找到符合要求的元素为止。图MP-REIN的索引结构由数组和跳跃表组成,每个桶用跳跃表将订阅有序的联系起来。面对大规模发布订阅时,跳跃表带来的插入时间和匹配时间上的收益会大幅度提高事件匹配的效率。
自适应索引结构的订阅划分过程使用一个例子来说明,假设现有某订阅集合S={S1,S2,S3,S4,S5,S6,S7,S8,S9,S10},属性空间A={a1,a2,a3},S在属性空间上的约束如图2所示,系统根据属性空间大小生成3条桶链,其中属性a1,a2,a3值域为[0,30],属性a1,a2,a3的值域都被划分为7个单元。一次事件匹配中,在a1属性上,S1到S8的约束下边界均在[10,15]区间,REIN在该区间上形成一个桶链,MP-REIN在该区间上形成一个跳跃表。S9和S10落入[20,25]区间,a1属性上的订阅划分结束。限于篇幅,省去在a2和a3上的详细匹配过程描述。订阅划分结束后,会得到所有属性上整个订阅集合划分的结果。
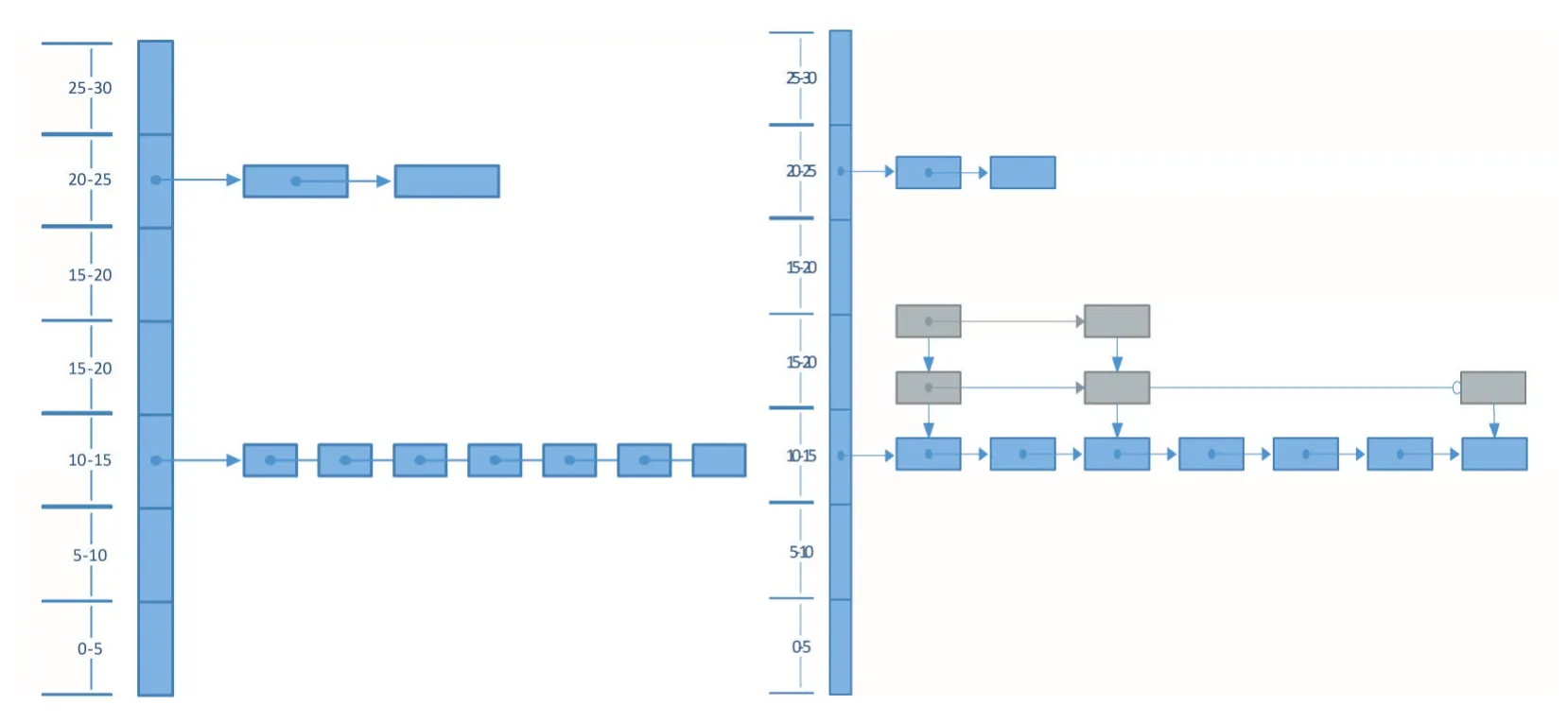
图1 REIN和MP-REIN索引结构(左图为REIN,右图为MP-REIN,灰色节点是跳跃表为了提高速度而建立的辅助节点)

表1 10个订阅列表
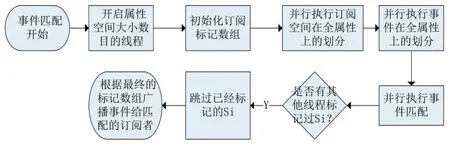
图2 MP-REIN事件匹配流程图
1.3 多维度事件匹配
REIN算法采用流水线式的单维度匹配算法,在前一个属性上过滤掉一些不匹配的订阅,缩减搜索空间的大小。然而,REIN单维度匹配算法的局限性限制了事件匹配的过程只能是单线程的,并没有充分利用CPU的性能给事件匹配的速度带来提升。MP-REIN使用多线程同时对订阅集合的所有属性展开搜索,当某个线程在某一属性上过滤掉某个订阅Si时,会在辅助bit数组中标记这个订阅,其余线程在匹配到该订阅的时候就会跳过,避免冗余的匹配。这种内存标记法不用维护额外的计数器,并得到了并行搜索带来的时间收益,以较低的代价在事件匹配速度上得到了很大的提升。
图2 展示了MP-REIN事件匹配的全部过程,在一次事件匹配中,会经过如下步骤:
(1)开启属性空间大小数目的线程(线程的创建使用线程池,线程池创建线程减少了频繁创建线程的开销)。
第五,要大力发展高效节水灌溉技术。农业是用水大户,现在9.05亿亩(0.60亿hm2)的有效灌溉面积中节水灌溉面积只占到4.3亿亩(0.29亿hm2),还不到一半。另外,节水灌溉面积中的高效节水灌溉技术,像喷灌、微灌、管道输水灌溉还不到2亿亩(0.13亿hm2),所以说,这方面节水的潜力非常大。
(2)初始化一个bit数组用来标记不匹配的订阅,所有任务线程并行标记数组元素,基于最终的标记数组向匹配的订阅者广播事件通知。
(3)预先创建的线程在此处用来并行划分订阅空间到按照各个属性值域构建的索引结构中,用于后续的事件匹配和订阅标记。
(4)同样使用预先创建的线程对到来的事件作并行划分,落到(3)中已经划分过订阅空间的索引结构中
(5)并行执行事件与订阅匹配,对标记数组中不匹配的订阅作标记。如果其他线程标记过某个订阅,则跳过。
(6)根据最终标记的数组,筛选出匹配的订阅并转发事件给相关订阅者。
1.4 匹配过程示例
在1.2小节中用一个例子展示了订阅集合划分的过程,并得到了最终划分的结果。此时,发布者发布了一个事件,MP-REIN 算法根据事件中的属性确定要在a1和a2对应的属性链上进行匹配。
MP-REIN算法此时唤醒线程池中两个线程T1和T2分别用来处理a1和a2两个属性链上的事件匹配,同时初始化一个大小为10的标记数组B={0,0,0,0,0,0,0,0,0,0},0表示S1到S10的初始匹配状态。当有线程判断某个订阅不匹配的时候就在标记数组中将这个订阅的状态标记为1。假设T1和T2同时开始事件匹配,但由于不同属性中订阅集合大小的差异,线程的执行速度是有快慢的。
假设T2根据a2=7将B中下标为2,4的元素标记为1,表示不匹配。原本根据a1=12落在[10,15]区间,T1还需要将Ea1和S4的约束区间[10,12]的上边界比较一次,但T2通过内存数组感知到S4已经被标记,于是跳过此次比较。
2 实验评估
为了综合评估MP-REIN的性能,通过大量实验对比了MP-REIN在三个指标上的优越性:匹配时间、插入时间和删除时间。所有的实验在三台8G内存,Windows7操作系统,处理器为Inter酷睿i5-4460的台式机上进行。语言上选择Java编程语言,所有的实验结果在本节展示。
MP-REIN将和REIN算法在性能上做全方位的比较,匹配算法的性能受到多个因素的影响,如表2所示,实验过程中将调整这些参数的取值,测量匹配时间、插入时间和删除时间。为了简化实验复杂性,将属性的值域都设置为[0,1]。
实验过程中使用A、B、C三台PC,分别用作发布者、代理器和订阅者。测量匹配时间时,定义匹配时间为订阅划分和一次事件匹配的平均时间,为了测量代理器匹配时间,开启一个Daemon线程用于在后台记录订阅划分的初始时间和事件匹配完成的结束时间;匹配算法的插入时间定义为全属性订阅插入桶中的平均时间,为了测量代理器插入时间,用同样的Daemon线程在后台记录第一个订阅插入的时间作为起始时间,在一组订阅插入完毕后记录当前时刻用作结束时间。为了实验的准确性,每一组实验进行5次,结果取每一次的平均值。

表2 实验参数
2.1 匹配时间
所有的参数都会对算法产生性能上的影响,一般来说订阅个数越多,匹配算法执行的时间就越长。在匹配时间的性能评估中,设置实验参数:m=10,j=30,c=15,k=10,订阅数目设置多组值:100、1000、10000、20000、40000、60000、80000、100000。订阅个数对匹配时间的影响结果如图3所示。MP-REIN在100、1000、10000组和REIN的匹配时间相差并不大,但是MPREIN在订阅个数增加的过程中表现出了很明显的优势,且差距越来越大,MP-REIN匹配速度快于REIN的原因在于:第一,订阅个数较少(低于10000)的时候,MP-REIN的优势不是很明显,因为建立跳跃表需要占用了一些时间,但当订阅个数逐渐增多的时候,构建跳跃表的代价和其带来的查找和插入速度上的收益来比就显得很有意义了,跳跃表索引结构优势体现,匹配速度提升明显。第二,多维度匹配充分的利用了CPU的性能,带来了匹配速度的提升。
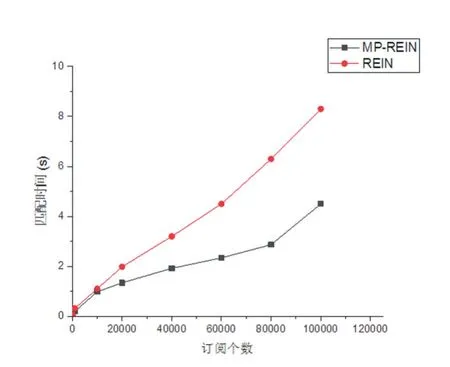
图3 订阅个数对匹配时间的影响
2.2 插入时间
每当有新的订阅时就会有插入操作,发布者发布新的事件时也会有插入操作,评估一个发布订阅算法,插入时间也是一个重要的衡量标准。设置实验参数同2.1节:m=10,j=30,c=15,k=10,记录每一次的订阅插入时间。观察订阅个数增长的过程中,MP-REIN和REIN插入时间的变化。订阅个数对插入时间的影响如图4所示。可以看到在插入时间上,MP-REIN优势明显,可能的原因:第一,MP-REIN只需要插入一条链中,但是REIN需要插入两条链。第二,MP-REIN索引结构的插入时间复杂度是O(logn)低于链表的插入时间复杂度O(n),这个优势在数据量大的时候更加明显,而受限于链表,REIN的插入速度难以提升。
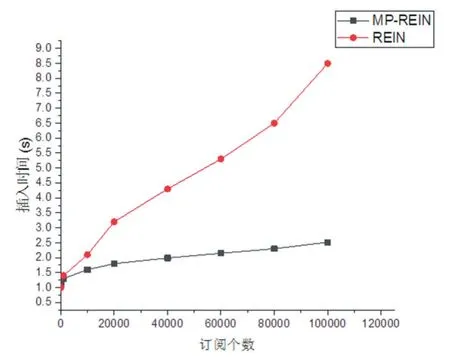
图4 订阅个数对插入时间的影响
3 结语
本文提出了一种多维度并行匹配的匹配算法,一改传统的单维度流水线匹配算法,充分利用CPU资源,事件匹配初始阶段就在全属性空间上匹配所有订阅,一旦发现某个订阅在某属性上不符合约束,任意包含该订阅的搜索都会跳跃这个订阅,这一机制大大地提高了事件匹配的效率。另外,跳跃表索引结构在面对大规模发布订阅时,能够依赖数据结构在查找、插入和删除上的优势,提高了整个事件匹配流程的效率。
实验结果表明,MP-REIN较传统的算法在匹配时间和插入时间上都有一定的优势。
